






 本文全面回顾了深度学习在图像超分辨率领域的最新进展,包括监督和无监督SR技术,特定领域的SR应用,以及面临的挑战和未来方向。文章探讨了模型框架、上采样方法、网络设计和学习策略,分析了不同技术的优势和局限性。
本文全面回顾了深度学习在图像超分辨率领域的最新进展,包括监督和无监督SR技术,特定领域的SR应用,以及面临的挑战和未来方向。文章探讨了模型框架、上采样方法、网络设计和学习策略,分析了不同技术的优势和局限性。
论文地址:Deep Learning for Image Super-resolution: A Survey
摘要——图像超分辨率(SR)是一类重要的图像处理技术,旨在提高计算机视觉中图像和视频的分辨率。 近年来,目睹了使用深度学习技术的图像超分辨率的显着进步。 本文旨在对使用深度学习方法的图像超分辨率的最新进展提供全面的调查。 通常,我们可以将现有的SR技术研究大致分为三大类:监督SR,无监督SR和特定领域的SR。 此外,我们还涵盖了其他一些重要问题,例如公开可用的基准数据集和性能评估指标。 最后,我们通过重点介绍未来的一些方向和未解决应在将来进一步解决的问题来结束本调查。
关键字——图像超分辨,深度学习,卷积神经网络,生成对抗网络
1 介绍
图像超分辨是指从低分辨率(SR)中恢复高分辨率(HR)图像是计算机视觉和图像处理中一类重要的图像处理技术。 它享有广泛的实际应用,例如医学成像,监视和安全。 除了改善图像感知质量外,它还有助于改善其他计算机视觉任务。 由于有多个HR图像对应于单个LR图像,此问题变得非常具有挑战性,并且固有地存在难适应性。现如今已经提出了多种经典的SR方法,包括基于预测的方法,基于边缘的方法,统计方法,基于补丁的方法和稀疏表示方法等。
随着近年来深度学习技术的飞速发展,基于深度学习的SR模型已得到积极探索,并经常在各种SR基准上达到最先进的性能。 从基于早期卷积神经网络(CNN)的方法(例如SRCNN)到最近使用生成对抗网络(GAN)的有前途的SR方法,各种各样的深度学习方法已应用于解决SR任务(例如SRGAN)。 通常,使用深度学习技术的SR算法族在以下主要方面彼此不同:不同类型的网络体系结构,不同类型的损失函数,不同类型的学习原理和策略等。
在本文中,我们全面概述了深度学习中图像超分辨率的最新进展。尽管现有文献中已有一些SR调查,但我们的工作有所不同,我们专注于基于深度学习的SR技术,而大多数早期的研究旨在调查传统 SR算法或一些研究主要集中在基于全参考指标或人类视觉感知的定量评估上。 与现有调查不同,我们的调查采用了独特的基于深度学习的观点,以系统,全面的方式回顾了SR技术的最新进展。
该调查的主要贡献是三方面:
- 我们对基于深度学习的图像超分辨率技术进行了全面回顾,包括问题设置,基准数据集,性能指标,具有深度学习的SR方法系列,特定领域SR应用程序等;
- 我们以分层和结构方式对基于深度学习的SR技术的最新进展进行了系统的概述,并总结了有效SR解决方案的每个组件的优点和局限性;
- 我们讨论挑战和未解决的问题,并确定新趋势和未来方向,提供有见地的指导。
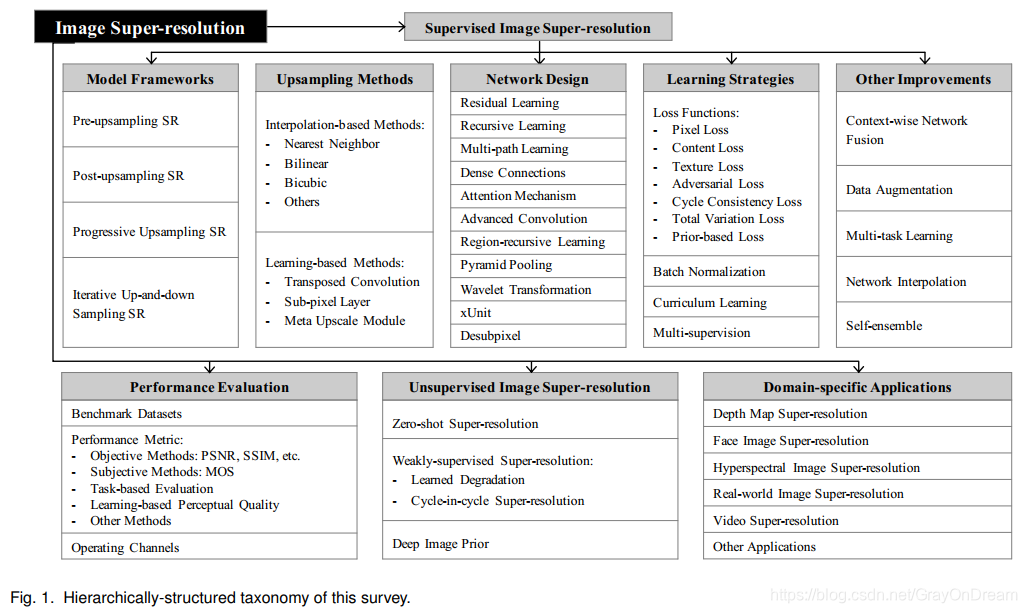
在以下各节中,我们将介绍深度学习中图像超分辨率的最新进展的各个方面。 图1以分层结构的方式显示了本次调查要涵盖的图像SR的分类法。第2节给出了问题的定义,并回顾了主流数据集和评估指标。 第三部分模块化地分析了监督SR的主要组成部分。 第4节简要介绍了无监督SR方法。第5节介绍一些流行的特定于域的SR应用,第6节讨论未来的方向和未解决的问题。
2 问题设置和术语
2.1 问题定义
图像超分辨率旨在从LR图像中恢复相应的HR图像。 通常LR图像
I
x
I_x
Ix被建模为以下degradation的输出:
I
x
=
D
(
I
y
,
σ
)
(1)
I_x=\mathcal{D}(I_y, σ) \tag{1}
Ix=D(Iy,σ)(1)
其中
D
\mathcal{D}
D表示降级映射函数,
I
y
I_y
Iy是相应的HR图像,而δ是降级过程的参数(例如缩放因子或噪声)。通常,degradation过程(即
D
\mathcal{D}
D和δ)是未知的,仅提供LR图像。 在这种情况下,也称为盲态SR,要求研究人员从LR图像
I
x
I_x
Ix中恢复地面真实HR图像
I
y
I_y
Iy的HR近似值
I
^
y
\hat{I}_y
I^y,如下所示:
I
^
y
=
F
(
I
x
;
θ
)
(2)
\hat{I}_y=\mathcal{F}(I_x;θ)\tag{2}
I^y=F(Ix;θ)(2)
其中
F
\mathcal{F}
F是超分辨率模型,θ表示
F
\mathcal{F}
F的参数。
尽管degradation过程未知,并且可能受多种因素(例如压缩伪影,各向异性degradation,传感器噪声和斑点噪声)的影响,但研究人员正在尝试对degradation映射进行建模。大多数工作将degradation建模为单个下采样操作,如下所示:
D
(
I
y
;
σ
)
=
(
I
y
)
↓
s
,
s
⊂
σ
(3)
\mathcal{D}(I_y;σ)=(I_y)\downarrow_s,{s}⊂σ\tag{3}
D(Iy;σ)=(Iy)↓s,s⊂σ(3)
↓
s
\downarrow_s
↓s是比例因子为
s
s
s的下采样操作。事实上,大多数通用SR的数据集都是基于此模式构建的,最常用的下采样操作是具有抗锯齿的三次双线性插值插值。 但是,还有其他工作[39]将degradation建模为几种操作的组合:
D
(
I
y
;
σ
)
=
(
I
y
⊗
κ
)
↓
s
+
n
ζ
,
κ
,
s
,
ζ
⊂
σ
(4)
\mathcal{D}(I_y;σ)=(I_y⊗κ)\downarrow_s+n_{ζ},{κ,s,ζ}⊂σ\tag{4}
D(Iy;σ)=(Iy⊗κ)↓s+nζ,κ,s,ζ⊂σ(4)
其中
I
y
⊗
κ
I_y⊗κ
Iy⊗κ代表模糊核κ与HR图像
I
y
I_y
Iy之间的卷积,
n
ζ
n_ζ
nζ为标准偏差ζ的一些加性高斯白噪声。 相对于公式3的定义等式4的组合degradation模式更接近于现实世界的情况,并已被证明对SR更有益。
最终SR的目标是:
θ
^
=
a
r
g
m
i
n
θ
L
(
I
^
y
,
I
y
)
+
λ
Φ
(
θ
)
\hat{θ} = argmin_{θ} \mathbb{L}(\hat{I}_y,I_y)+λΦ(θ)
θ^=argminθL(I^y,Iy)+λΦ(θ)
其中 L ( I ^ y , I y ) \mathbb{L}(\hat{I}_y,I_y) L(I^y,Iy)表明HR图像 I ^ y \hat{I}_y I^y和ground truth图像 I y I_y Iy之间的损失, Φ ( θ ) Φ(θ) Φ(θ)是正则化项,λ为权衡参数。尽管SR最受欢迎的损失函数是逐像素均方误差(即像素损失),但功能更强大的模型倾向于使用多个损失函数的组合,这将在本教程中介绍。
2.2 超分辨的数据集
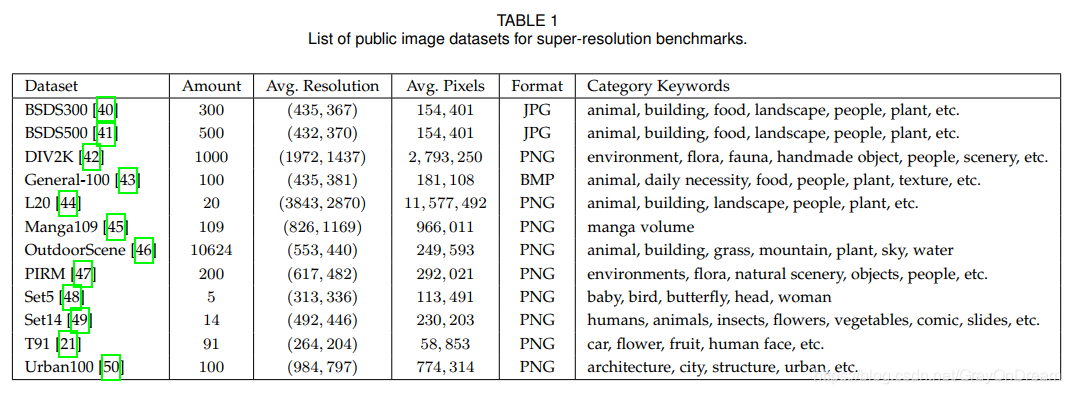
如今,有许多可用的图像超分辨率数据集,它们在图像数量,质量,分辨率和多样性等方面有很大差异。其中一些提供LR-HR图像对,而另一些仅提供HR图像。 通常通过在MATLAB中使用默认设置的imresize函数获得LR图像(即带抗锯齿的三次双线性插值)。 在表1中,我们列出了SR社区常用的许多图像数据集,并特别指出了它们的HR图像数量,平均分辨率,平均像素数,图像格式和类别关键字。
除了这些数据集,一些广泛用于其他视觉任务的数据集也用于SR,例如ImageNet,MS-COCO,VOC2012,CelebA。 此外,结合多个数据集进行训练也很流行,例如结合T91和BSDS300,结合DIV2K和Flickr2K。
2.3 图像质量评估
图像质量是指图像的视觉属性,并着重于查看者的感知评估。 通常,图像质量评估(IQA)方法包括基于人类感知的主观方法(即图像的真实感)和客观计算方法。前者更符合我们的需求,但通常既耗时又昂贵,因此后者目前是主流。 但是,这些方法不一定彼此一致,因为客观方法通常无法非常准确地捕获人类的视觉感知,这可能会导致IQA结果差异很大。
另外,客观IQA方法又分为三种类型[58]:使用参考图像进行评估的全参考方法,基于提取特征比较的简化参考方法以及不使用参考图片的无参考方法(即盲IQA)。 接下来,我们将介绍几种最常用的IQA方法,涵盖主观方法和客观方法。
2.3.1 峰值信噪比
峰值信噪比(PSNR)是有损变换(例如图像压缩,图像修复)最受欢迎的重建质量度量之一。 对于图像超分辨率,通过最大像素值(表示为L)和图像之间的均方误差(MSE)定义PSNR。 给定具有N个像素的地面真实图像
I
I
I和重建
I
^
\hat{I}
I^,则
I
I
I和
I
^
\hat{I}
I^之间的PSNR定义如下:
P
S
N
R
=
10
⋅
l
o
g
10
(
L
2
1
N
∑
i
=
1
N
(
I
(
i
)
−
I
^
(
i
)
)
2
)
PSNR=10⋅log_{10}(\frac{L^2}{\frac{1}{N}∑_{i=1}^N (I(i)-\hat{I}(i))^2})
PSNR=10⋅log10(N1∑i=1N(I(i)−I^(i))2L2)
通常情况下,使用8位表示法,L等于255。 由于PSNR仅与像素级MSE有关,因此仅关注相应像素之间的差异而不是视觉感知,因此在表示真实场景中的重建质量时,由于我们通常更关注人类知觉通常会导致性能下降。 但是,由于有必要与文献著作进行比较,并且缺乏完全准确的感知指标,因此PSNR仍然是目前最广泛用于SR模型的评估标准。
2.3.2 结构相似
考虑到人类视觉系统(HVS)非常适合提取图像结构,基于亮度,对比度的独立比较,提出了结构相似性指标(SSIM)用于测量图像之间的结构相似性。对于具有N个像素的图像
I
I
I,分别将亮度
µ
I
µ_I
µI和对比度
σ
I
σ_I
σI估计为图像强度的平均值和标准偏差,即
µ
I
=
1
N
∑
i
=
1
N
I
(
i
)
µ_I=\frac{1}{N}∑_{i=1}^NI(i)
µI=N1∑i=1NI(i)和
σ
I
=
(
1
N
−
1
∑
i
=
1
N
(
I
(
i
)
−
μ
I
)
2
)
1
2
σ_I=(\frac{1}{N-1}∑_{i=1}^N(I(i)-μ_I)^2)^{\frac{1}{2}}
σI=(N−11∑i=1N(I(i)−μI)2)21,其中
I
(
i
)
I(i)
I(i)代表图像
I
I
I的第
i
i
i个像素的强度。亮度和对比度的比较表示为
C
l
(
I
;
I
^
)
\mathbb{C}_l(I;\hat{I})
Cl(I;I^)和
C
c
(
I
,
I
^
)
\mathbb{C}_c(I,\hat{I})
Cc(I,I^)分别由下式给出:
C
l
(
I
,
I
^
)
=
2
μ
I
μ
I
^
+
C
1
μ
I
2
+
μ
I
^
2
+
C
1
\mathbb{C}_l(I,\hat{I})=\frac{2μ_Iμ_{\hat{I}} + C_1}{μ_I^2+μ_{\hat{I}}^2+C_1}
Cl(I,I^)=μI2+μI^2+C12μIμI^+C1
C
c
(
I
,
I
^
)
=
2
σ
I
σ
I
^
+
C
2
σ
I
2
+
σ
I
^
2
+
C
2
\mathbb{C}_c(I,\hat{I})=\frac{2σ_Iσ_{\hat{I}} + C_2}{σ_I^2+σ_{\hat{I}}^2+C_2}
Cc(I,I^)=σI2+σI^2+C22σIσI^+C2
其中
C
1
=
(
k
1
L
)
2
,
C
2
=
(
k
2
L
)
2
C_1=(k_1L)^2,C_2=(k_2L)^2
C1=(k1L)2,C2=(k2L)2是为了避免不稳定性的常数
k
1
≪
1
,
k
2
≪
1
k_1≪1,k_2≪1
k1≪1,k2≪1。
此外,图像结构由归一化的像素值(即
(
I
−
μ
I
)
/
σ
I
(I-μ_I)/σ_I
(I−μI)/σI)表示,其相关性(即内积)测量结构相似性,等效于
I
I
I与
I
^
\hat{I}
I^之间的相关系数。 因此,结构比较函数
C
s
(
I
;
I
^
)
\mathbb{C}_s(I;\hat{I})
Cs(I;I^)定义为:
σ
I
I
^
=
1
N
−
1
∑
i
=
1
N
(
I
(
i
)
−
μ
I
)
(
I
^
(
i
)
−
μ
I
^
)
σ_{I\hat{I}}=\frac{1}{N-1}\sum_{i=1}^N(I(i)-μ_I)(\hat{I}(i) - μ_{\hat{I}})
σII^=N−11i=1∑N(I(i)−μI)(I^(i)−μI^)
C
s
(
I
,
I
^
)
=
σ
I
I
^
+
C
3
σ
I
σ
I
^
+
C
3
\mathbb{C}_s(I,\hat{I})=\frac{σ_{I\hat{I}}+C_3}{σ_{I}σ_{\hat{I}}+C_3}
Cs(I,I^)=σIσI^+C3σII^+C3
σ
I
I
^
σ_{I\hat{I}}
σII^是二者的协方差,
C
3
C_3
C3是为了维护稳定性的常数。
S
S
I
M
(
I
,
I
^
)
=
[
C
l
(
I
,
I
^
)
]
α
[
C
c
(
I
,
I
^
)
]
β
[
C
s
(
I
,
I
^
)
]
γ
SSIM(I,\hat{I})=[\mathbb{C}_l(I,\hat{I})]^α[\mathbb{C}_c(I,\hat{I})]^β[\mathbb{C}_s(I,\hat{I})]^γ
SSIM(I,I^)=[Cl(I,I^)]α[Cc(I,I^)]β[Cs(I,I^)]γ
其中α,β,γ是调节相关重要性的参数。
由于SSIM从HVS的角度评估重建质量,因此它更好地满足了感知评估的要求,并且也被广泛使用。
2.3.3 平均意见分数
平均意见得分(MOS)测试是一种常用的主观IQA方法,要求人类评估者为测试的图像分配感知质量得分。 通常,分数从1(差)到5(好)。 最终的MOS计算为所有额定值的算术平均值。
尽管MOS测试似乎是一种忠实的IQA方法,但它具有一些固有的缺陷,例如非线性感知的比例,偏差和评级标准的偏差。 实际上,有些SR模型在通用IQA指标(例如PSNR)中表现较差,但在感知质量方面远远超过其他模型,在这种情况下,MOS测试是准确测量感知质量的最可靠的IQA方法。
2.3.4 基于学习的知觉质量
为了在减少人工干预的同时更好地评估图像的感知质量,研究人员尝试通过在大型数据集上学习来评估感知质量。 具体来说,Ma等和Talebi等分别提出了无参考的Ma和NIMA,它们是从视觉知觉得分中学到的,并且可以直接预测质量得分而无需地面真相图像。 相反,Kim等提出了DeepQA,它通过训练三重畸变图像,客观误差图和主观得分来预测图像的视觉相似性。 张等收集大规模的感知相似性数据集,通过训练有素的深度网络根据深度特征的差异评估感知图像斑块相似度(LPIPS),并表明CNN所学习的深度特征比没有CNN的测度更好。
尽管这些方法在捕获人类视觉感知方面表现出更好的性能,但是我们需要什么样的感知质量(例如,更逼真的图像或与原始图像的一致性)仍然是一个有待探索的问题,因此,客观的IQA方法(例如,PSNR)(SSIM)仍然是当前的主流。
2.3.5 基于任务的评估
根据SR模型通常可以帮助其他视觉任务的事实,通过其他任务评估重建性能是另一种有效的方法。具体来说,研究人员将原始和重建的HR图像输入经过训练的模型中,并通过比较对预测性能的影响来评估重建质量。 用于评估的视觉任务包括对象识别,面部识别,面部对齐和解析等。
2.3.6 其他IQA方法
除了上述IQA方法外,还有其他不太受欢迎的SR指标。 多尺度结构相似性(MS-SSIM)在结合观看条件变化方面比单尺度SSIM提供了更大的灵活性。特征相似度(FSIM)基于相位一致性和图像梯度幅度提取人类感兴趣的特征点,以评估图像质量。 自然图像质量评估器(NIQE)利用与自然图像中观察到的统计规律性的可测量偏差,而不会暴露于失真图像。
最近,布劳等从数学上证明失真(例如PSNR,SSIM)和感知质量(例如MOS)彼此矛盾,并且表明随着失真的降低,感知质量必定会更差。因此,如何准确地测量SR质量仍然是一个亟待解决的问题。
2.4 处理通道
除了常用的RGB颜色空间外,YCbCr颜色空间还广泛用于SR。 在此空间中,图像分别由Y,Cb,Cr通道表示,分别表示亮度,蓝差和红差色度分量。 尽管目前尚无公认的最佳实践来在哪个空间上执行或评估超分辨率,但较早的模型倾向于在YCbCr空间的Y通道上进行操作,而较新的模型则倾向于 在RGB通道上操作。 值得注意的是,在不同的色彩空间或通道上进行操作(训练或评估)可能会使评估结果相差很大(最高4 dB)。
2.5 超分辨率挑战
在本节中,我们将简要介绍图像SR的两个最受欢迎的挑战,即NTIRE和PIRM。
- NTIRE挑战:图像恢复和增强的新趋势(NTIRE)挑战与CVPR结合使用,并且包括SR,降噪和着色等多项任务。 对于图像SR,NTIRE挑战建立在DIV2K 数据集上,包括双三次缩径轨道和具有实际未知降级的盲赛道。这些赛道在退化和缩放因子方面有所不同,旨在在理想条件和现实世界的不利情况下促进SR研究。
- PIRM挑战。 感知图像恢复和操纵(PIRM)挑战与ECCV结合在一起,并且还包含多个任务。 与NTIRE相比,PIRM的一个子挑战专注于发电精度和感知质量之间的权衡,另一个专注于智能手机的SR。 众所周知,以失真为目标的模型经常会产生视觉上令人不愉快的结果,而以感知质量为目标的模型在信息保真度上表现不佳。具体而言,PIRM根据均方根误差(RMSE)的阈值将感知失真平面分为三个区域。 在每个区域,获胜的算法都是获得最佳感知质量的算法,由NIQE 和Ma 进行了评估。 在其他子挑战中,智能手机上的SR要求参与者使用有限的智能手机硬件(包括CPU,GPU,RAM等)执行SR,评估指标包括PSNR,MS-SSIM和MOS测试 。 这样,PIRM鼓励在感知失真权衡方面进行高级研究,并在智能手机上推动轻巧高效的图像增强。
3 监督超分辨
如今,研究人员已经提出了各种带有深度学习的超分辨率模型。 这些模型专注于监督SR,即使用LR图像和相应的HR图像进行训练。 尽管这些模型之间的差异非常大,但它们实质上是一组组件(例如模型框架,上采样方法,网络设计和学习策略)的某种组合。 从这个角度出发,研究人员将这些组件结合起来,以构建适合特定目的的集成SR模型。 在本节中,我们集中于模块化分析基本组件(如图2所示)不是孤立地介绍每个模型,而是总结它们的优点和局限性。
3.1 超分辨框架
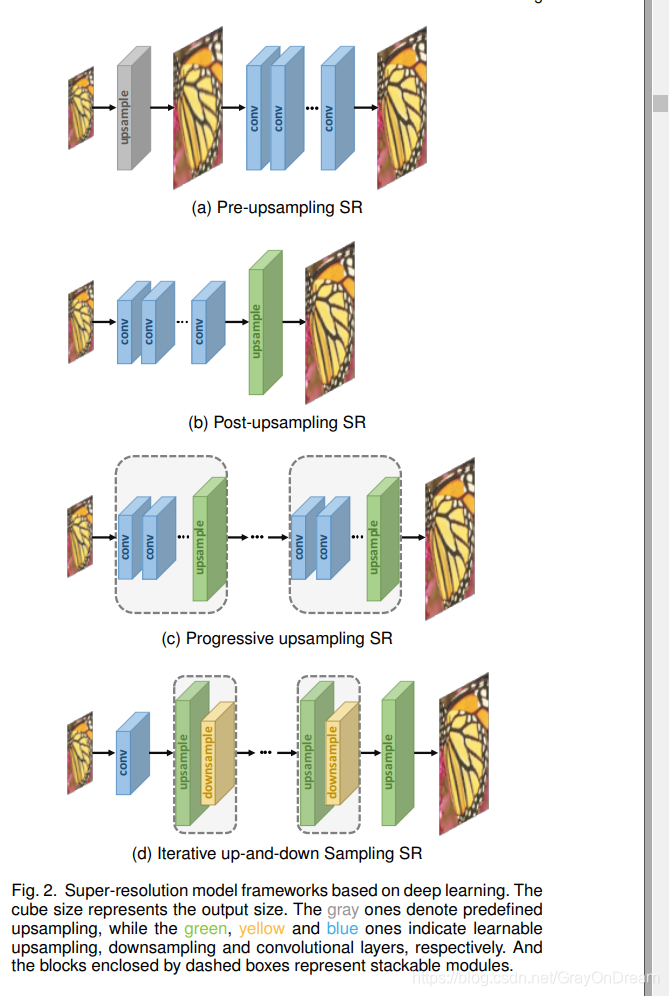
由于图像超分辨率是一个ill-posed的问题,因此关键的问题是如何执行上采样(即从LR输入生成HR输出)。 尽管现有模型的体系结构千差万别,但根据所采用的上采样操作及其在模型中的位置,它们可以归因于四个模型框架(如图2所示)。
3.1.1 预上采样超分辨
考虑到直接学习从低维空间到高维空间的映射的困难,利用传统的上采样算法来获得更高分辨率的图像,然后使用深度神经网络对其进行细化是一个简单的解决方案。 因此,董等人首先采用预上采样的SR框架(如图2a所示),并提出SRCNN以学习从内插LR图像到HR图像的端到端映射。具体而言,使用传统方法(例如,双三次插值)将LR图像上采样为具有所需大小的粗略HR图像,然后将深CNN应用于这些图像以重建高质量的细节。
由于完成了最困难的上采样操作,因此CNN仅需要细化粗图像,从而大大降低了学习难度。 另外,这些模型可以将具有任意大小和比例因子的插值图像作为输入,并以与单尺度SR模型相当的性能提供精确的结果。 因此,它逐渐成为最受欢迎的框架之一,这些模型之间的主要区别在于后验模型设计(第3.3节)和学习策略(第3.4节)。但是,预定义的上采样通常会带来副作用(例如,噪声放大和模糊),并且由于大多数操作是在高维空间中执行的,因此时间和空间的成本比其他框架要高得多。
3.1.2 后上采样超分辨
为了提高计算效率并充分利用深度学习技术来自动提高分辨率,研究人员建议在低维空间中执行大多数计算,方法是将预定义的上采样替换为在端部集成的端到端可学习层。 在该框架的开创性工作中,即图2b所示的后上采样SR,LR输入图像被馈送到深度CNN中而不增加分辨率,并应用了端到端可学习的上采样层 在网络的末端。
由于具有巨大计算成本的特征提取过程仅在低维空间中发生,并且分辨率仅在最后增加,因此大大降低了计算和空间复杂度。 因此,该框架也已成为最主流的框架之一。 这些模型的主要区别在于可学习的上采样层(第3.2节),前CNN结构(第3.3节)和学习策略(第3.4节)等。
3.1.3 渐进式上采样超分辨率
尽管上采样后SR框架极大地降低了计算成本,但仍存在一些不足。 一方面,仅在一个步骤中执行上采样,这极大地增加了大比例因子(例如4、8)的学习难度。 另一方面,每个比例因子都需要训练一个单独的SR模型,这无法满足对多比例SR的需求。 为了解决这些缺点,拉普拉斯金字塔SR网络(LapSRN)采用了渐进式上采样框架,如图2c所示。 具体来说,在此框架下的模型基于CNN的级联,并逐步重建更高分辨率的图像。 在每个阶段,图像都会被上采样到更高的分辨率,并由CNN进行精炼。 MS-LapSRN和渐进式SR(ProSR)等其他作品也采用了这种框架,并获得了较高的性能。 与使用中间重构图像作为后续模块的“基础图像”的LapSRN和MS-LapSRN相比,ProSR保留了主要信息流,并通过单个磁头重构了中分辨率图像。
通过将困难的任务分解为简单的任务,该框架下的模型极大地降低了学习难度,尤其是在具有较大因素的情况下,并且在不引入过多空间和时间成本的情况下也可以应对多尺度SR。 此外,可以将某些特定的学习策略(例如课程学习(第3.4.3节)和多重监督(第3.4.4节))直接集成在一起,以进一步降低学习难度并提高最终成绩。但是,这些模型还遇到一些问题,例如多阶段的复杂模型设计和训练稳定性,因此需要更多的模型指导和更高级的训练策略。
3.1.4 上下迭代采样超分辨率
为了更好地捕获LRHR图像对的相互依赖性,将有效的迭代过程称为反投影并入SR。 这个SR框架,即迭代的上下采样SR(如图2d所示),试图迭代地应用反投影细化,即计算重建误差,然后将其融合以调整HR图像强度。 具体来说,Haris等利用迭代的上下采样层并提出DBPN,它交替连接上采样层和下采样层,并使用所有中间重构来重构最终的HR结果。 类似地,SRFBN采用了具有更密集的跳过连接的迭代式上下采样反馈块,并学习了更好的表示形式。 用于视频超分辨率的RBPN从连续的视频帧中提取上下文,并通过反投影模块将这些上下文组合起来以产生循环输出帧。
在此框架下的模型可以更好地挖掘LR-HR图像对之间的深层关系,从而提供更高质量的重建结果。 尽管如此,反投影模块的设计标准仍不清楚。 由于此机制刚刚被引入基于深度学习的SR中,因此该框架具有巨大的潜力,需要进一步探索。
3.2 上采样方法
除了模型中的上采样位置外,如何执行上采样也非常重要。 尽管有多种传统的上采样方法,但利用CNN来学习端到端的上采样已逐渐成为一种趋势。 在本部分中,我们将介绍一些传统的基于插值的算法和基于深度学习的上采样层。
3.2.1 基于插值的上采样
图像插值,也称为图像缩放,是指调整数字图像的大小,并被图像相关的应用程序广泛使用。 传统的插值方法包括最近邻插值,双线性和双三次插值,Sinc和Lanczos重采样等。由于这些方法可解释且易于实现,因此其中一些仍在基于CNN的SR模型中广泛使用。
- 最近邻插值。 最近邻插值是一种简单直观的算法。 它为每个要插值的位置选择最近的像素值,而不考虑其他任何像素。 因此,该方法非常快,但通常会产生质量低下的块状结果;
- 双线性插值。 双线性插值(BLI)首先在图像的一个轴上执行线性插值,然后在另一个轴上执行,如图3所示。 由于它会导致接收场大小为2×2的二次插值,因此在保持相对较快速度的同时,其性能比最近邻插值要好得多。
- 三次插值。 同样,三次插值(BCI)在两个轴的每个轴上执行三次插值,如图3所示。 与BLI相比,BCI考虑了4×4像素,因此结果更平滑,伪像更少,但速度却低得多。 实际上,具有抗锯齿功能的BCI是构建SR数据集的主流方法(即将HR图像降级为LR图像),并且还广泛用于预采样SR框架中(第3.1.1节)。
实际上,基于插值的上采样方法仅基于其自身的图像信号即可提高图像分辨率,而不会带来更多信息。相反,它们通常会带来一些副作用,例如计算复杂度,噪声放大,结果模糊。因此,当前的趋势是用可学习的上采样层替换基于插值的方法。
3.2.2 基于学习的上采样
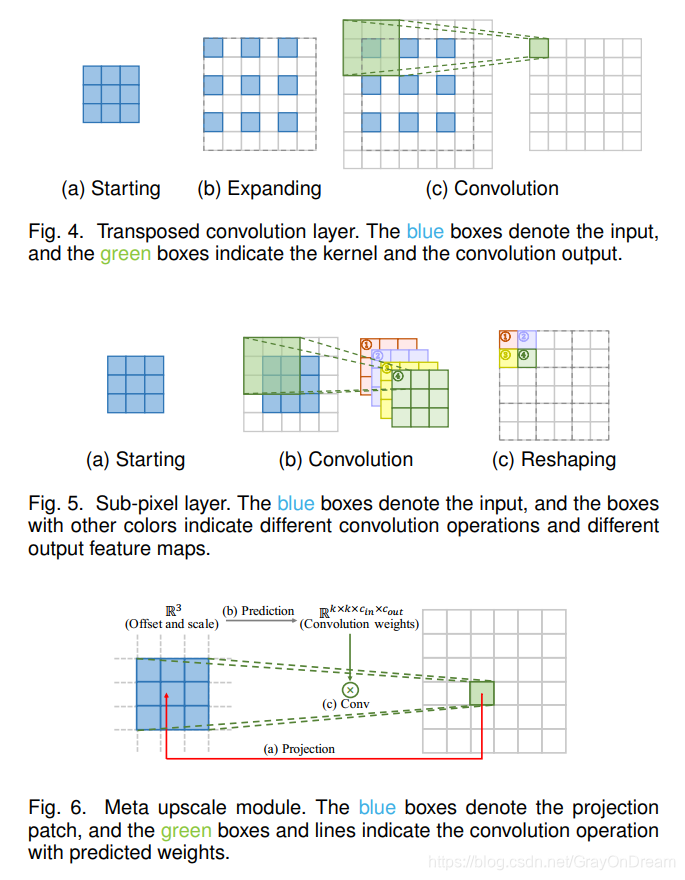
为了克服基于插值的方法的缺点并以端到端的方式学习上采样,已将转置的卷积层和子像素层引入了SR领域。
- 转置卷积层。 转置卷积层,也称为反卷积层,试图执行与正常卷积相反的变换,即基于大小类似于卷积输出的特征图预测可能的输入。 具体而言,它通过插入零并执行卷积来扩展图像,从而提高了图像分辨率。 以2×SR和3×3内核为例(如图4所示),首先将输入扩展为原始大小的两倍,然后将相加的像素值设置为0(图4b)。 然后应用内核大小为3×3,跨度为1和填充为1的卷积(图4c)。 这样,输入将以2的系数上采样,在这种情况下,接收场最多为2×2。因为转置的卷积以端到端的方式扩大了图像大小,同时保持与在SR模型中被广泛用作升采样层原始的卷积兼容的连接模式。 但是,该层很容易在每个轴上引起“不均匀的重叠” ,并且两个轴上的相乘结果进一步创建了大小变化的棋盘状图案,从而损害了SR性能。
- 亚像素层。 如图5所示,子像素层是另一个端到端可学习的上采样层,它通过卷积生成多个通道然后对其进行重塑来执行上采样。 在这一层中,首先应用卷积来产生具有 s 2 s^2 s2倍通道的输出,其中s是比例因子(图5b)。假设输入大小为h×w×c,则输出大小将为 h × w × s 2 c h×w×s^2c h×w×s2c。 之后,执行整形操作(也称为混洗)以生成大小为sh×sw×c的输出(图5c)。 在这种情况下,接收场可以达到3×3。由于端到端的上采样方式,该层也被SR模型广泛使用。 与转置的卷积层相比,子像素层具有更大的接收场,可提供更多的上下文信息以帮助生成更多逼真的细节。 但是,由于接收场的分布不均匀,并且块状区域实际上共享相同的接收场,因此可能会导致在不同块的边界附近出现一些伪像。 另一方面,独立预测块状区域中的相邻像素可能会导致输出不平滑。高等提出了PixelTCL,它将独立预测替换为相互依存的顺序预测,并产生更平滑,更一致的结果。
- 元升级模块。 先前的方法需要预先定义缩放因子,即针对不同的因子训练不同的上采样模块,这效率低下且与实际需求不符。 胡等提出了元高级模块(如图6所示),该模块首先基于元学习解决任意比例因子的SR。具体来说,对于HR图像上的每个目标位置,该模块将其投影到LR特征图上的一个小块(即
k
×
k
×
c
i
n
k×k×c_{in}
k×k×cin),根据以下公式预测卷积权重(即
k
×
k
×
c
i
n
×
c
o
u
t
)
k×k×c_{in}×c_{out})
k×k×cin×cout) 投影偏移和缩放系数通过密集层进行卷积。 这样,元高级模块可以通过单个模型以任意因子连续放大它。 并且由于大量的训练数据(同时对多个因素进行训练),该模块在固定因素上可以表现出相同甚至更好的性能。 尽管该模块需要在推理过程中预测权重,但上采样模块的执行时间仅约占特征提取时间的1%。 但是,该方法基于与图像内容无关的几个值来预测每个目标像素的大量卷积权重,因此当面对较大的放大倍数时,预测结果可能不稳定且效率较低。
如今,这些基于学习的层已成为使用最广泛的上采样方法。 尤其是在上采样后框架(第3.1.2节)中,这些层通常用于最终的上采样阶段,以基于在低维空间中提取的高级表示来重建HR图像,从而实现端到端的SR同时应当避免在高维空间中进行繁重的操作。
3.3 网络设计
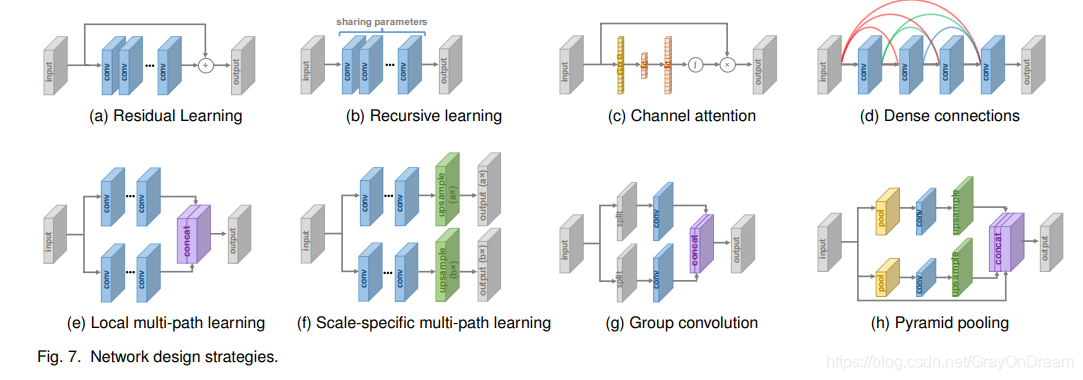
如今,网络设计已成为深度学习最重要的部分之一。 在超分辨率领域,研究人员在四个SR框架(第3.1节)的基础上应用各种网络设计策略来构建最终的网络。 在本节中,我们将这些网络分解为网络设计的基本原理或策略,对其进行介绍并逐一分析其优势和局限性。
3.3.1 残差学习
在He之前等提出ResNet用于学习残差而不是彻底的映射,残差学习已被SR模型广泛采用,如图7a所示。 其中,残差学习策略可以大致分为全局残差学习和局部残差学习。
- 全局残差学习。 由于图像SR是图像到图像的转换任务,其中输入图像与目标图像高度相关,因此研究人员尝试仅学习它们之间的残差,即全局残差学习。 在这种情况下,它避免了学习从完整图像到另一个图像的复杂转换,而只需要学习一个残差图即可恢复丢失的高频细节。 由于大多数区域的残差接近零,因此大大降低了模型的复杂性和学习难度。 因此,它被SR模型广泛使用。
- 本地残差学习。 局部残差学习与ResNet中的残差学习相似,用于缓解因网络深度不断增加而引起的退化问题,降低训练难度并提高学习能力。 它也广泛用于SR。
实际上,上述方法都是通过快捷方式连接(通常由一个小常数缩放)和逐元素加法来实现的,不同之处在于前者直接连接输入和输出图像,而后者通常在层之间添加多个快捷方式 在网络内部具有不同的深度。
3.3.2 递归学习
为了在不引入压倒性参数的情况下学习高级功能,将递归学习(即以递归方式多次应用相同的模块)引入SR领域,如图7b所示。
其中,16递归DRCN采用单个卷积层作为递归单元,并达到41×41的接收场,这比SRCNN的13×13大得多,而没有太多参数。 DRRN使用ResBlock作为25次递归的递归单元,并且比17-ResBlock基线获得更好的性能。 后来Tai等提出了基于存储块的MemNet,该存储块由6个递归ResBlock组成,其中每个递归的输出被级联,并通过额外的1×1卷积进行记忆和遗忘。 级联残差网络(CARN)也采用了类似的递归单元,其中包括多个ResBlock。 最近,李等人采用迭代式上下采样SR框架,并提出了一种基于递归学习的反馈网络,其中整个网络的权重在所有递归中共享。
此外,研究人员还在不同部分采用了不同的递归模块。 具体来说,Han等提出了双状态递归网络(DSRN)在LR和HR状态之间交换信号。 在每个时间步骤(即递归),每个分支的表示都进行更新和交换,以便更好地探索LR-HR关系。同样,赖等采用嵌入和上采样模块作为递归单元,因此以很小的性能损失为代价大大减小了模型尺寸。
通常,递归学习确实可以在不引入过多参数的情况下学习更高级的表示形式,但是仍然无法避免高昂的计算成本。而且它固有地带来了消失或爆炸的梯度问题,因此一些技术(例如残差学习(第3.3.1节)和多监督(第3.4.4节))通常与递归学习相集成,以缓解这些问题。
3.3.3 多路学习
多路径学习是指通过多条路径传递特征,这些特征会执行不同的操作,并将其融合以提供更好的建模功能。具体来说,可以将其分为全局,局部和规模特定的多路径学习。
- 全局多路径学习。 全局多路径学习是指利用多条路径来提取图像不同方面的特征。 这些路径在传播中可以相互交叉,从而大大增强了学习能力。 具体来说,LapSRN包括以粗略到精细的方式预测子带残差的特征提取路径,以及基于来自两条路径的信号重建HR图像的另一条路径。 类似地,DSRN利用两条路径分别提取低维和高维空间中的信息,并不断交换信息以进一步提高学习能力。 像素递归超分辨率采用条件路径来捕获图像的整体结构,并采用先验路径来捕获所生成像素的序列依赖性。 相反,Ren等采用具有不平衡结构的多条路径来执行上采样并在模型末尾融合它们。
- 本地多路径学习。 如图7e所示,在初始模块的推动下,MSRN采用了一个用于多尺度特征提取的新模块。 在此块中,采用两个内核大小分别为3×3和5×5的卷积层来同时提取特征,然后将输出级联并再次进行相同的操作,最后再应用额外的1×1卷积。 快捷方式通过逐元素加法连接输入和输出。通过这种局部多路径学习,SR模型可以更好地从多个尺度提取图像特征,并进一步提高性能。
- 量表特定的多路径学习。 考虑到不同规模的SR模型需要经过相似的特征提取,Lim等人提出了针对特定规模的多路径学习,以通过单个网络应对多尺度SR。 具体来说,它们共享模型的主要组成部分(即用于特征提取的中间层),并分别在网络的开头和结尾处附加特定于比例的预处理路径和上采样路径。(如图7f所示)。在训练期间,仅启用和更新与所选比例尺相对应的路径。 通过这种方式,建议的MDSR通过共享不同比例的大多数参数极大地减小了模型尺寸,并且表现出与单比例模型相当的性能。CARN和ProSR也采用了类似的针对特定尺度的多路径学习。
3.3.4 密集链接
由于黄等提出了基于密集块的DenseNet,密集连接在视觉任务中变得越来越流行。 对于密集块中的每一层,所有先前层的特征图都用作输入,而其自身的特征图则用作所有后续层的输入,因此,它导致
l
⋅
(
l
−
1
)
/
2
l·(l − 1)/ 2
l⋅(l−1)/2个连接$ l
层密集块(
层密集块(
层密集块(l$≥2)。 密集连接不仅有助于减轻梯度消失,增强信号传播并促进特征重用,而且还可以通过采用较小的增长率(即密集块中的通道数)并在连接所有输入特征图后压缩通道来显着减小模型尺寸。
为了融合低级和高级功能以提供更丰富的信息来重构高质量的细节,在SR字段中引入了密集连接,如图7d所示。 Tong等不仅采用密集块来构造一个69层的SRDenseNet,而且还在不同密集块之间插入密集连接,即对于每个密集块,所有先前块的特征图都用作输入,并使用其自己的特征图 用作所有后续块的输入。 这些层级和块级密集连接也被MemNet,Carn,RDN和ESRGAN 采用。 DBPN也广泛采用密集连接,但是它们的密集连接在所有上采样单元之间以及下采样单元之间。
3.3.5 注意力机制
- 通道注意。 考虑到不同通道之间特征表示的相互依存和相互作用,Hu等提出了一个“squueeze-and-excitation”模块,通过显式建模通道相互依赖关系来提高学习能力,如图7c所示。 在此块中,使用全局平均池(GAP)将每个输入通道压缩到一个通道描述器(即一个常数)中,然后将这些描述符馈送到两个密集层中以产生输入通道的按通道缩放比例因子。最近,张等人将通道注意机制与SR结合起来,提出了RCAN,从而显着提高了模型的表示能力和SR性能。 为了更好地学习特征相关性,戴等人。进一步提出了一个二阶信道注意(SOCA)模块。 SOCA通过使用二阶特征统计量而不是GAP来自适应地按比例缩放通道方式的特征,并能够提取更多信息性和区分性表示形式。
- Non-Local注意。 大多数现有的SR模型具有非常有限的本地接受域。 但是,某些远距离的对象或纹理对于局部补丁的生成可能非常重要。 这样张等提出了局部和非局部注意力块来提取捕获像素之间长期依赖关系的特征。 具体而言,他们提出了一个用于提取特征的主干分支,以及一个用于自适应地重新缩放主干分支特征的(非)本地掩码分支。 其中,局部分支采用编码器-解码器结构来学习局部注意,而非局部分支使用嵌入式高斯函数来评估特征图中每两个位置索引之间的成对关系以预测缩放权重。通过这种机制,提出的方法很好地抓住了空间的注意力,并进一步增强了表达能力。 同样,戴等人还结合了非本地注意力机制来捕获远程空间上下文信息。
3.3.6 高级卷积
由于卷积运算是深度神经网络的基础,因此研究人员还尝试改进卷积运算以提高性能或效率。
- 扩张卷积。 众所周知,性信息有助于生成SR的现实细节因此张等用SR模型中的扩张卷积代替了普通卷积,将接收场增加了两倍,并获得了更好的性能。
- 组卷积。 Hui等人受轻型CNN的最新进展的推动和Ahn等。分别通过用组卷积代替原始的卷积来提出IDN和CARN-M。 正如一些先前的工作所证明的,群卷积大大减少了参数和操作的数量,但损失了一些性能。
- 深度可分离卷积。Howard等提出了深度卷积可分离卷积以进行有效的卷积,它已扩展到各个领域。具体来说,它由一个因数分解的深度卷积和一个点状卷积(即1×1卷积)组成,因此减少了很多参数和运算,而精度却只有很小的降低。 最近,Nie等人。采用深度可分离卷积并大大加快了SR体系结构。
3.3.7 区域递归学习
大多数SR模型将SR视为独立于像素的任务,因此无法正确获取生成的像素之间的相互依赖性。 受PixelCNN的启发,Dahl等人首先提出了像素递归学习,通过采用两个网络分别捕获全局上下文信息和序列生成相关性来执行逐像素生成。 这样,所提出的方法可以在超高分辨率的超低分辨率人脸图像(例如8×8)上合成逼真的头发和皮肤细节,并且远远超过了MOS测试的先前方法(第2.3.3节)。
在人类注意力转移机制的推动下,Attention-FH 也采用了这种策略,即诉诸循环策略网络来顺序发现有人参与的补丁并进行本地增强。 通过这种方式,它能够根据每个图像的自身特性自适应地个性化最佳搜索路径,从而充分利用图像的全局内部依赖性。
尽管这些方法在某种程度上显示出更好的性能,但是需要较长传播路径的递归过程极大地增加了计算成本和训练难度,尤其是对于超分辨HR图像而言。
3.3.8 金字塔池化
受空间金字塔池化层的驱动Zhao等提出了金字塔池模块,以更好地利用全局和局部上下文信息。 具体来说,对于大小为h×w×c的特征图,将每个特征图划分为M×M个bin,并进行全局平均池化,从而得到M×M×c输出。 然后执行1×1卷积以将输出压缩到单个通道。之后,通过双线性插值将低维特征图上采样到与原始特征图相同的大小。 通过使用不同的M,该模块可以有效地集成全局和局部上下文信息。 通过合并该模块,提出的EDSR-PP模型进一步提高了超过基准的性能。
3.3.9 小波变换
众所周知,小波变换(WT),通过将图像信号分解为表示纹理细节和低频子带的高频子带来高效地表示图像 包含全球拓扑信息。 Bae等首先将WT与基于深度学习的SR模型结合,以内插LR小波的子带作为输入,并预测相应HR子带的残差。 WT和逆WT分别用于分解LR输入和重构HR输出。 同样,DWSR和Wavelet-SRNet在小波域中也执行SR,但结构更为复杂。 与上述独立处理每个子带的工作相反,MWCNN采用多级WT,并将级联子带作为单个CNN的输入,以更好地捕获它们之间的依赖性。 由于通过小波变换有效地表示,使用这种策略的模型通常会大大减少模型的大小和计算成本,同时保持竞争性。
3.3.10 去亚像素
为了加快推理速度,Vu等人提出在低维空间中执行耗时的特征提取,并提出去子像素,这与子像素层的混洗操作相反(第3.2.2节)。特别是,去亚像素操作会在空间上分割图像,将它们堆叠为额外的通道,从而避免信息丢失。 通过这种方式,他们在模型开始时通过去亚像素对输入图像进行下采样,在较低维度的空间中学习表示,最后在目标尺寸上进行上采样。 所提出的模型以极高的速度推断和良好的性能在智能手机上的PIRM挑战中获得了最佳分数。
3.3.11 xUnit
为了将空间特征处理和非线性激活相结合,以更有效地学习复杂特征,Kligvasser等人提出了xUnit用于学习空间激活函数。 具体而言,ReLU被视为确定权重图以对输入执行元素逐项乘法,而xUnit通过卷积和高斯门控直接学习权重图。 尽管xUnit对计算的要求更高,但由于其对性能的巨大影响,它可以在使性能与ReLU相匹配的同时大大减小模型尺寸。 通过这种方式,作者将模型大小减小了近50%,而性能没有任何下降。
3.4 学习策略
3.4.1 损失函数
在超分辨率领域,损失函数用于测量重建误差并指导模型优化。 早期,研究人员通常采用像素级L2损失,但后来发现它无法非常准确地测量重建质量。 因此,采用了多种损失函数(例如,内容损失,对抗性损失)来更好地测量重构误差并产生更现实,更高质量的结果。 如今,这些损失功能已经发挥了重要作用。 在本节中,我们将仔细研究广泛使用的损失函数。 本节中的符号遵循第2.1节,只是我们忽略了目标HR图像 I ^ y \hat{I}_y I^y的下标 y y y并为简洁起见生成了HR图像 I y I_y Iy。
- 像素损失。 像素损失测量两个图像之间的像素差异,主要包括L1损失(即平均绝对误差)和L2损失(即均方误差):
L p i x e l l 1 ( I ^ , I ) = 1 h w c ∑ i , j , k ∣ I ^ i , j , k − I i , j , k ∣ \mathbb{L}_{pixel_l1}(\hat{I},I)=\frac{1}{hwc}∑_{i,j,k}|\hat{I}_{i,j,k}-I_{i,j,k}| Lpixell1(I^,I)=hwc1i,j,k∑∣I^i,j,k−Ii,j,k∣
L
p
i
x
e
l
l
2
(
I
^
,
I
)
=
1
h
w
c
∑
i
,
j
,
k
(
I
^
i
,
j
,
k
−
I
i
,
j
,
k
)
2
\mathbb{L}_{pixel_l2}(\hat{I},I)=\frac{1}{hwc}∑_{i,j,k}(\hat{I}_{i,j,k}-I_{i,j,k})^2
Lpixell2(I^,I)=hwc1i,j,k∑(I^i,j,k−Ii,j,k)2
其中h,w和c分别是评估图像的高度,宽度和通道数。 此外,还有一个像素L1损耗的变体,即Charbonnier损耗:
L
p
i
x
e
l
C
h
a
(
I
^
,
I
)
=
1
h
w
c
∑
i
,
j
,
k
√
I
^
i
,
j
,
k
−
I
i
,
j
,
k
+
ε
2
\mathbb{L}_{pixel_Cha}(\hat{I},I)=\frac{1}{hwc}∑_{i,j,k}√{\hat{I}_{i,j,k}-I_{i,j,k}+ε^2}
LpixelCha(I^,I)=hwc1i,j,k∑√I^i,j,k−Ii,j,k+ε2
其中
ε
ε
ε是用了稳定性的常数(例如
1
0
−
3
10^{-3}
10−3)。
像素损失将生成的HR图像ˆ I限制为足够接近像素值上的地面真实I。与L1损耗相比,L2损耗会惩罚较大的误差,但更能容忍较小的误差,因此通常会导致结果过于平滑。 实际上,与L2损耗相比,L1损耗显示出更高的性能和收敛性。
由于PSNR的定义(第2.3.1节)与逐像素差异高度相关,并且使像素损失最小化直接使PSNR最大化,因此像素损失逐渐成为使用最广泛的损失函数。 但是,由于像素损失实际上并未考虑图像质量(例如,感知质量,纹理),因此结果通常缺少高频细节,并且在视觉上对过平滑的纹理不满意。
- 内容损失。 为了评估图像的感知质量,将内容损失引入SR。具体来说,它使用预先训练的图像分类网络来测量图像之间的语义差异。将该网络表示为
φ
φ
φ,将在第
l
l
l层上提取的高级表示表示为
φ
(
l
)
(
I
)
φ(l)(I)
φ(l)(I),内容损失表示为两个图像的高级表示之间的欧式距离,如下所示:
L c o n t e n t ( I ^ , I ) = 1 h l w l c l ∑ i , j , k √ ( φ ( l ) i , j , k ( I ^ ) − φ i , j , k ( l ) ( I ) ) 2 \mathbb{L}_{content}(\hat{I},I)=\frac{1}{h_lw_lc_l}∑_{i,j,k}√{(φ^{(l)_{i,j,k}(\hat{I})} - φ^{(l)}_{i,j,k}(I))^2} Lcontent(I^,I)=hlwlcl1i,j,k∑√(φ(l)i,j,k(I^)−φi,j,k(l)(I))2
其中 h l h_l hl, w l w_l wl和 c l c_l cl分别是第 l l l层上表示形式的高度,宽度和通道数。
从本质上讲,内容损失将学习到的分层图像特征知识从分类网络转移到SR网络。 与像素损失相反,内容损失促使输出图像ˆ I在感觉上与目标图像I相似,而不是强迫它们精确匹配像素。 因此,它产生的视觉效果更明显,并且还广泛用于此领域,其中VGG和ResNet是最常用的预训练CNN。 - 纹理损失。 考虑到重建的图像应与目标图像具有相同的样式(例如颜色,纹理,对比度),并受Gatys等人的样式表示的激励将纹理损失(也称为样式重建损失)引入SR。 根据图像纹理被视为不同特征通道之间的相关性,并定义为Gram矩阵
G
(
l
)
∈
R
c
l
×
c
l
G^{(l)}∈ℝ^{c_l×c_l}
G(l)∈Rcl×cl,其中
G
i
j
(
l
)
G^{(l)}_{ij}
Gij(l)是向量化之间的内积
l
l
l层上的特征映射
i
i
i和
j
j
j:
G i j ( l ) ( I ) = v e c ( φ i ( l ) ( I ) ) ⋅ v e c ( φ j ( l ) ( I ) ) G_{ij}^{(l)}(I)=vec(φ^{(l)}_i(I))⋅vec(φ^{(l)}_j(I)) Gij(l)(I)=vec(φi(l)(I))⋅vec(φj(l)(I))
其中 v e c ( ⋅ ) vec(·) vec(⋅)表示矢量化操作, φ i ( l ) ( I ) φ^{(l)}_i(I) φi(l)(I)表示图像 I I I的第 l l l层上特征图的第 i i i个通道。然后,纹理损失由下式给出:
L t e x t u r e ( I ^ , I ; φ , l ) = 1 c l 2 √ ∑ i , j ( G ( l ) i , j ( I ^ ) − G ( l ) i , j ( I ) ) 2 \mathbb{L}_{texture}(\hat{I},I;φ,l)=\frac{1}{c_l^2}√{∑_{i,j}( G^{(l)_{i,j}}(\hat{I}) - G^{(l)_{i,j}}(I) )^2} Ltexture(I^,I;φ,l)=cl21√i,j∑(G(l)i,j(I^)−G(l)i,j(I))2
通过使用纹理损失,由Sajjadi等人提出的EnhanceNet。 产生更逼真的纹理并产生视觉上更令人满意的结果。 尽管如此,确定贴片大小以匹配纹理仍然是凭经验的。斑块太小会导致纹理区域出现伪影,而斑块太大会导致整个图像出现伪影,因为纹理统计量是在纹理变化的区域内平均得出的。 - 对抗损失。 近年来,由于强大的学习能力,GAN 受到越来越多的关注,并被引入到各种视觉任务中。 具体来说,GAN由执行生成(例如,文本生成,图像转换)的生成器和将生成的结果和从目标分布中采样的实例作为输入并区分每个输入是否来自目标的判别器组成。 分配。 在训练过程中,交替执行两个步骤:(a)固定发生器并训练判别器以更好地进行鉴别,(b)固定判别器并训练发生器使判别器蒙骗。 通过充分的迭代对抗训练,生成的生成器可以产生与真实数据分布一致的输出,而判别器则无法区分生成的数据和真实数据。
在超分辨率方面,采用对抗学习很简单,在这种情况下,我们仅需要将SR模型视为生成器,并定义一个额外的判别器来判断是否生成了输入图像。 因此,Ledig等首先提出基于交叉熵的对抗损失的SRGAN,如下:
L g a n c e g ( I ^ ; D ) = − l o g D ( I ^ ) \mathbb{L}_{gan_ce_g}(\hat{I};D)=-logD(\hat{I}) Lganceg(I^;D)=−logD(I^)
L
g
a
n
c
e
d
(
I
^
;
D
)
=
−
l
o
g
D
(
I
s
)
−
l
o
g
(
1
−
D
(
I
^
)
)
\mathbb{L}_{gan_ce_d}(\hat{I};D)=-logD(I_s)-log(1-D(\hat{I}))
Lganced(I^;D)=−logD(Is)−log(1−D(I^))
其中
L
g
a
n
c
e
g
\mathbb{L}_{gan_ce_g}
Lganceg和
L
g
a
n
c
e
d
\mathbb{L}_{gan_ce_d}
Lganced分别表示生成器(即SR模型)和判别器D(即二元分类器)的对抗损失,而Is表示从地面真实情况中随机采样的图像。 此外,Enhancednet也采用了类似的对抗性损失。
此外,王等和袁等根据最小二乘误差使用对抗损失,以获得更稳定的训练过程和更高质量的结果,由以下公式得出:
L
g
a
n
l
s
g
(
I
^
;
D
)
=
(
D
(
I
^
)
−
1
)
2
\mathbb{L}_{gan_ls_g}(\hat{I};D)=(D(\hat{I}) - 1)^2
Lganlsg(I^;D)=(D(I^)−1)2
L
g
a
n
l
s
d
(
I
^
,
I
s
;
D
)
=
(
D
(
I
^
)
)
2
+
(
D
(
I
s
)
−
1
)
2
\mathbb{L}_{gan_ls_d}(\hat{I}, I_s;D)=(D(\hat{I}))^2 + (D(I_s) - 1)^2
Lganlsd(I^,Is;D)=(D(I^))2+(D(Is)−1)2
与上述专注于对抗损失的特定形式的工作相反,Park等人认为像素级判别器会产生无意义的高频噪声,并附加了另一个特征级判别器,以对经过预先训练的CNN提取的高层表示进行操作,该CNN捕获了更多有意义的属性。 真实的HR图像。 徐等结合了一个由生成器和多个特定于类的判别器组成的多类GAN。 ESRGAN 运用相对论GAN 来预测真实图像比伪图像相对真实的概率,而不是输入图像是真实或伪图像的概率,从而指导恢复更详细的纹理。
大量的MOS测试(第2.3.3节)显示,即使与对抗性和内容损失相比,经过对抗性损失和内容损失训练的SR模型实现的PSNR较低,但它们也会带来感知质量的显着提高。 事实上,判别器提取出一些难以学习的真实HR图像的潜像图案,并推动生成的HR图像符合要求,从而有助于生成更逼真的图像。 然而,目前GAN的训练过程仍然困难且不稳定。尽管已经有一些关于如何稳定GAN训练的研究,但是如何确保正确集成到SR模型中的GAN并发挥积极作用仍然是一个问题。
-
循环一致性损失。 由Zhu等人提出的CycleGAN激励。Yuan等提出了一种超分辨率的循环方法。 具体而言,它们不仅将LR图像 I I I解析为HR图像 ^ I \hat{}I ^I,而且还将 I ^ \hat{I} I^通过另一个CNN下采样回到另一个LR图像 I ˉ \bar{I} Iˉ。 再生的 I ˉ \bar{I} Iˉ必须与输入 I I I相同,因此引入了循环一致性损失以限制其像素级一致性:
L c y c l e ( I ˉ , I ) = 1 h w c √ ∑ i , j , k ( I ˉ i , j , k − I i , j , k ) 2 \mathbb{L}_{cycle}(\bar{I}, I)=\frac{1}{hwc}√{∑_{i,j,k}( \bar{I}_{i,j,k} - I_{i,j,k})^2} Lcycle(Iˉ,I)=hwc1√i,j,k∑(Iˉi,j,k−Ii,j,k)2 -
总变化损失。 为了抑制生成图像中的噪声,Aly等人将总变化(TV)损失引入了SR。 它定义为相邻像素之间的绝对差之和,并测量图像中的噪声量,如下所示:
L T V ( I ^ ) = 1 h w c ∑ i , j , k √ ( I ^ i , j + 1 , k − I ^ i , j , k ) 2 + ( I ^ i + 1 , j , k − I ^ i , j , k ) 2 \mathbb{L}_{TV}(\hat{I})=\frac{1}{hwc}∑_{i,j,k}√{(\hat{I}_{i,j+1,k} - \hat{I}_{i,j,k})^2 + (\hat{I}_{i+1,j,k} - \hat{I}_{i,j,k})^2} LTV(I^)=hwc1i,j,k∑√(I^i,j+1,k−I^i,j,k)2+(I^i+1,j,k−I^i,j,k)2
赖等和袁等也采用TV损耗来施加空间平滑度。 -
基于先验的损失。 除上述损失函数外,还引入了外部先验知识来约束生成。 具体而言,Bulat等专注于人脸图像SR并引入人脸对齐网络(FAN)来约束人脸标志的一致性。 预先对FAN进行培训和集成,以便事先提供面部对齐功能,然后与SR一起进行培训。 以此方式,提出的Super-FAN改善了LR面部对准和面部图像SR的性能。
实际上,内容丢失和纹理丢失(两者都引入了分类网络)本质上为SR提供了分层图像特征的先验知识。 通过引入更多的先验知识,可以进一步提高SR性能。
在本节中,我们介绍了SR的各种损失函数。 在实践中,研究人员通常通过加权平均值组合多个损失函数,以约束生成过程的各个方面,尤其是在失真感知权衡方面。 但是,不同损失函数的权重需要大量的经验探索,如何合理有效地结合仍然是一个问题。
3.4.2 批归一化
为了加速和稳定深层CNN的训练,Sergey等人提出了批量归一化(BN),以减少网络的内部协变量偏移。 具体来说,它们对每个微型批处理执行归一化,并为每个通道训练两个额外的转换参数以保留表示能力。 由于BN校准了中间特征分布并减轻了消失梯度,因此它允许使用较高的学习率,而对初始化的注意较少。 因此,该技术被SR模型广泛使用。
但是,Lim等认为BN会丢失每个图像的比例尺信息,并且会失去网络的距离灵活性。 因此,他们删除了BN并使用节省的内存成本(高达40%)来开发更大的模型,从而大幅提高了性能。 其他一些模型也采用了这种经验并实现了性能改进。
3.4.3 课程学习
课程学习是指从一项容易完成的任务开始,逐渐增加难度。 由于超分辨率是一个不适当地的问题,并且始终会遇到不利的情况,例如较大的缩放因子,噪声和模糊感,因此引入了课程培训以降低学习难度。
为了降低使用大比例因子的SR的难度,Wang等人贝等和Ahn等分别提出了ProSR,ADRSR和渐进式CARN,它们不仅在架构上是渐进式的(第3.1.3节),但也涉及训练程序。 训练从2倍上采样开始,并且在完成训练后,逐渐安装具有4倍或更大比例因子的部分,并将其与之前的部分混合。 具体而言,ProSR通过线性组合此级别的输出和遵循的先前级别的上采样输出进行混合,ADRSR将它们连接起来并附加另一个卷积层,而渐进式CARN用产生该值的前一个重建块代替 双重分辨率的图像。
另外,Park等将8x SR问题划分为三个子问题(即1x到2x,2x到4x,4x到8x),并为每个问题训练独立的网络。 然后将其中两个连接并进行微调,然后将第三个连接。 此外,他们还将困难条件下的4倍SR分解为1倍至2倍,2倍至4倍,并对子问题进行去噪或去模糊处理。 相反,SRFBN在不利条件下使用此策略进行SR,即从容易降解开始,逐渐增加降解复杂性。
与普通培训程序相比,课程学习大大降低了培训难度并缩短了总培训时间,尤其是对于大型因素而言。
3.4.4 多元监督
多监督是指在模型中添加多个监督信号,以增强梯度传播并避免梯度消失和爆炸。 为了防止递归学习(3.3.2节)引入的梯度问题,DRCN将多监督与递归单元结合在一起。 具体来说,他们将递归单元的每个输出馈送到重建模块中以生成HR图像,并通过合并所有中间重建来构建最终预测。 MemNet和DSRN也采用了类似的策略,它们也是基于递归学习的。
此外,由于在渐进式上采样框架(第3.1.3节)下的LapSRN,在传播过程中会产生不同规模的中间结果,因此采用多监督策略是很简单的。具体地,中间结果被迫与从地面真实HR图像下采样的中间图像相同。
在实践中,这种多监督技术通常是通过在损失函数中添加一些项来实现的,这样,监督信号就可以更有效地向后传播,从而减少了训练难度并增强了模型训练。
3.5 其他改进
除了网络设计和学习策略之外,还有其他技术可以进一步改善SR模型。
3.5.1 上下文网络融合
上下文网络融合(CNF)是指一种融合来自多个SR网络的预测的堆栈技术(即,第3.3.3节中的多路径学习的一种特殊情况)。 具体而言,他们分别训练具有不同体系结构的单个SR模型,将每个模型的预测输入到各个卷积层中,最后将输出加起来成为最终的预测结果。 在这个CNF框架内,由三个轻量级SRCNN构造的最终模型可以以可接受的效率获得与最新模型相当的性能。
3.5.2数据增强
数据增强是通过深度学习提升性能的最广泛使用的技术之一。 对于图像超分辨率,一些有用的增强选项包括裁切,翻转,缩放,旋转,颜色抖动等。。 此外,贝等也随机洗牌RGB通道,这不仅增加了数据,而且还减轻了由颜色不平衡的数据集引起的颜色偏差。
3.5.3 多任务学习
多任务学习是指通过利用相关任务的训练信号中包含的特定领域信息来提高泛化能力,例如对象检测和语义分割,头部姿势估计和面部属性推断。 在SR领域,Wang等人引入了语义分割网络,用于提供语义知识并生成特定于语义的细节。 具体而言,他们提出了空间特征变换,以将语义图作为输入并预测在中间特征图上执行的仿射变换的空间方向参数。 因此,提出的SFT-GAN在具有丰富语义区域的图像上生成了更逼真的视觉效果的纹理。 此外,考虑到直接超分辨噪点图像可能会导致噪声放大,DNSR提出分别训练去噪网络和SR网络,然后将它们连接起来并进行微调。 同样,循环周期GAN(CinCGAN)结合了循环周期降噪框架和循环周期SR模型,共同执行降噪和超分辨率。 由于不同的任务倾向于关注数据的不同方面,因此将相关任务与SR模型结合起来通常可以通过提供额外的信息和知识来提高SR性能。
3.5.4 网络插值
基于PSNR的模型产生的图像更接近真实情况,但引入了模糊问题,而基于GAN的模型带来了更好的感知质量,但引入了令人不快的伪影(例如,无意义的噪声使图像更加``逼真’')。 为了更好地平衡失真和感知,Wang等提出了一种网络插值策略。 具体来说,他们通过微调训练基于PSNR的模型并训练基于GAN的模型,然后对两个网络的所有相应参数进行插值以得出中间模型。 通过在不重新训练网络的情况下调整插值权重,它们可产生有意义的结果,且伪像少得多。
3.5.5 自我增强
自我增强又称为增强预测,是SR模型常用的一种推理技术。 具体来说,对LR图像应用不同角度(0°,90°,180°,270°)的旋转和水平翻转,以得到一组8个图像。 然后将这些图像输入到SR模型中,并将相应的逆变换应用于重构的HR图像以获得输出。 最终预测结果由这些输出的平均值或中位数进行。 这样,这些模型可以进一步提高性能。
3.6 State-of-the-art超分辨率模型
近年来,基于深度学习的图像超分辨率模型受到越来越多的关注,并获得了最先进的性能。 在前面的章节中,我们将SR模型分解为特定的组件,包括模型框架(第3.1节),上采样方法(3.2),网络设计(第3.3节)和学习策略(3.4),对这些组件进行分层分析,并确定其优势和局限性。 实际上,当今大多数最先进的SR模型基本上都可以归因于我们上面总结的多种策略的组合。 例如,RCAN 的最大贡献来自信道关注机制(第3.3.5节),它还采用了其他策略,例如亚像素上采样(第3.2.2节),残差学习(3.3.1),像素L1丢失(第3.4.1节)和自集成(第3.5.5节)。 如表2所示,我们以类似的方式总结了一些代表性的模型及其关键策略。
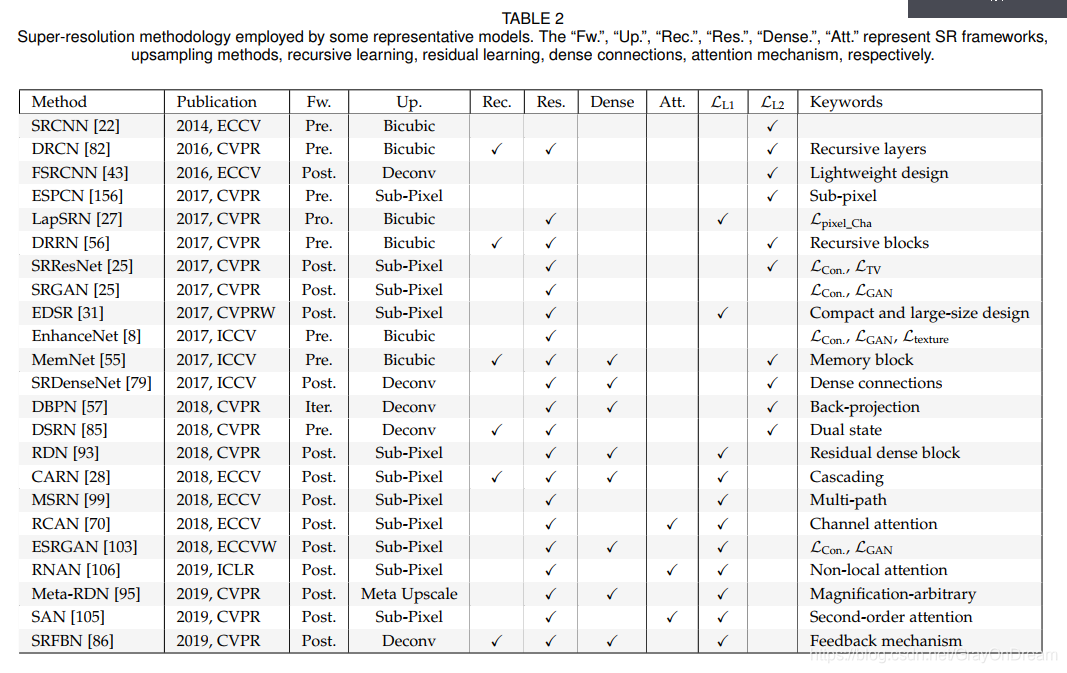
除SR精度外,效率是另一个非常重要的方面,不同的策略或多或少会对效率产生影响。 因此,在前面的部分中,我们不仅分析了所提出策略的准确性,而且还指出了对效率产生较大影响的策略的具体影响,例如后采样(第3.1.2节),递归 学习(第3.3.2节),密集连接(第3.3.4节),xUnit(第3.3.11节)。 我们还以SR精度(即PSNR),模型大小(即参数数量)和计算成本(即多次添加数量)为基准对一些代表性SR模型进行了基准测试,如图8所示,准确性是通过4个基准数据集(即Set5,Set14,B100和Urban100)上PSNR的平均值来衡量的。 然后使用PyTorch-OpCounter计算模型大小和计算成本,其中输出分辨率为720p(即1080×720)。 所有统计数据均来自原始论文或根据官方模型计算,比例系数为2。为便于查看和比较,我们还提供了交互式在线版本。
4 无监督超分辨
现有的超分辨率作品主要集中于有监督的学习,即用匹配的LR-HR图像对进行学习。但是,由于难以收集具有相同分辨率的相同场景的图像,因此通常通过对HR图像执行预定义的降级来获得SR数据集中的LR图像。 因此,训练有素的SR模型实际上学习了预定义退化的逆过程。 为了在不引入人工降级先验的情况下学习现实世界中的LR-HR映射,研究人员越来越多地关注无监督的SR,在这种情况下,仅提供未配对的LR-HR图像进行训练,因此生成的模型更有可能 以解决现实情况中的SR问题。 接下来,我们将简要介绍几种具有深度学习的无监督SR模型,还有待探索的更多方法。
4.1 Zero-shot超分辨
考虑到单个图像内部的内部图像统计信息已经为SR提供了足够的信息,Shocher等人提出了零镜头超分辨率(ZSSR)来通过在测试时训练图像特定的SR网络而不是在大型外部数据集上训练通用模型来应对无监督的SR。 具体而言,他们使用从单个图像估计退化内核,并使用该内核通过对图像使用不同缩放因子和增强进行退化来构建小型数据集。 然后,针对此数据集训练一个小的SR用CNN,并将其用于最终预测。
这样,ZSSR可以利用每个图像内部的跨尺度内部递归,因此在非理想条件下(在图像上,该图像在性能上大大优于以前的方法(估计内核为1 dB,已知内核为2 dB)) 例如,通过非双曲面退化获得的图像并遭受了诸如模糊,噪声,压缩伪影之类的影响,该图像更接近于真实世界的场景,同时在理想条件下给出了具有竞争力的结果(即,通过双三次退化获得的图像)。 但是,由于在测试过程中需要针对不同的图像训练不同的网络,因此推理时间要比其他时间长得多。
4.2 弱监督超分辨
为了在不引入预定义降级的情况下应对超分辨率,研究人员尝试通过弱监督学习来学习SR模型,即使用未配对的LRHR图像。 其中,一些研究人员首先学习了HR到LR的退化,并使用它来构建用于训练SR模型的数据集,而另一些研究人员则设计了周期循环网络以学习LR到HR和HR到LR的映射。 同时。 接下来,我们将详细介绍这些模型。
- 学会降级。 由于预定义的降级次优,因此从不成对的LR-HR数据集中学习降级是可行的方向。 Bulat等提出了一个分为两个阶段的过程,该过程首先训练HR-to-LR GAN以使用未配对的LR-HR图像学习降级,然后使用基于LR-HR的配对LR-HR图像训练用于SR的LR-to-HR GAN。 第一个GAN。 具体来说,对于HR到LR GAN,将HR图像馈送到生成器中以产生LR输出,不仅要匹配通过缩小HR图像(通过平均池化)获得的LR图像,而且还需要匹配真实图像的分布。 LR图像。 完成训练后,将生成器用作降级模型以生成LR-HR图像对。 然后对于LR-to-HR GAN,生成器(即SR模型)将生成的LR图像作为输入并预测HR输出,这不仅需要匹配相应的HR图像,而且还需要匹配HR图像的分布 。
通过应用这两个阶段的过程,所提出的未监督模型有效地提高了超分辨率现实世界LR图像的质量,并比以前的最新技术有了很大的改进。 - 周期内超分辨率。 无监督超分辨率的另一种方法是将LR空间和HR空间视为两个域,并使用循环周期结构来学习彼此之间的映射。 在这种情况下,训练目标包括推送映射结果以匹配目标域分布,并通过往返映射使图像可恢复。Yuan等人由CycleGAN提出了一个由4个生成器和2个判别器组成的周期循环SR网络(CinCGAN),分别组成两个CycleGAN,分别用于嘈杂的LR clean LR和clean LR clean HR映射。 具体来说,在第一个CycleGAN中,嘈杂的LR图像被馈送到生成器中,并且要求输出与真实的清晰LR图像的分布一致。然后将其馈入另一台生成器,并要求恢复原始输入。 为了保证周期一致性,分布一致性和映射有效性,采用了几种损失函数(例如对抗性损失,周期一致性损失,身份损失)。 除了映射域不同之外,其他CycleGAN的设计均类似。
由于避免了预定义的降级,因此不受监督的CinCGAN不仅可以实现与监督方法相当的性能,而且即使在非常恶劣的条件下也适用于各种情况。 然而,由于SR问题的本质不适以及CinCGAN的复杂体系结构,需要一些先进的策略来降低训练难度和不稳定性。
4.3 深度图像先验
Ulyanov等人考虑到CNN结构足以在逆问题之前捕获大量低级图像统计信息。在执行SR之前,采用手工初始化的随机初始化的CNN。 具体而言,他们定义了一个生成器网络,该生成器网络将随机向量z作为输入并尝试生成目标HR图像 I y I_y Iy。 目标是训练网络以找到下采样后的 I ^ y \hat{I}_y I^y与LR图像 I x I_x Ix相同的 I ^ y \hat{I}_y I^y。 由于网络是随机初始化的,并且从未接受过训练,因此唯一的先决条件是CNN结构本身。 尽管此方法的性能仍比监督方法(2 dB)差,但其性能却明显优于传统的双三次上采样(1 dB)。 此外,它显示了CNN架构本身的合理性,并促使我们通过将深度学习方法与诸如CNN结构或自相似性之类的手工先验相结合来改善SR。
5 特定领域的应用
5.1 深度图超分辨率
深度图记录了视点与场景中的对象之间的深度(即距离),并在许多任务中扮演重要角色,例如姿势估计和语义分割。 但是,由于经济和生产方面的限制,深度传感器生成的深度图通常分辨率较低,并且会受到噪声,量化和缺失值等退化影响。 因此引入了超分辨率以增加深度图的空间分辨率。
如今,深度图SR最受欢迎的做法之一是使用另一台经济的RGB相机获得相同场景的HR图像,以指导对LR深度图的超解析。 具体来说,宋等利用深度图统计数据和深度图与RGB图像之间的局部相关性来约束全局统计数据和局部结构。 Hui等利用两个CNN同时对LR深度图进行升采样和对HR RGB图像进行降采样,然后使用RGB特征作为具有相同分辨率的对深度图进行升采样的指导。 和Haefner等进一步利用色彩信息,并通过采用“从阴影开始成形”技术来指导SR。 相反,Riegler等将CNN与功能最小化模型形式的能量最小化模型结合起来,可以在没有其他参考图像的情况下恢复HR深度图。
5.2 人脸图像超分辨率
人脸图像超分辨率,又称为人脸幻觉(FH),通常可以帮助完成其他与人脸相关的任务。与普通图像相比,面部图像具有更多与面部相关的结构化信息,因此将面部先验知识(例如地标,解析地图,身份)整合到FH中是一种非常流行且有希望的方法。
最直接的方法之一是将生成的图像约束为具有与面部事实相同的面部相关属性。 具体而言,CBN通过交替优化FH和密集对应字段估计来利用面部优先。 Super-FAN和MTUN都引入了FAN,以通过端到端的多任务学习来保证面部标志的一致性。 FSRNet不仅使用面部地标热图,还使用面部解析图作为先验约束。SICNN旨在恢复真实身份,它采用了超级身份丧失功能和域集成训练方法来稳定联合训练。
除了显式地使用面部先验,隐式方法也得到了广泛的研究。 TDN 包含用于自动空间变换的空间变换器网络,从而解决了人脸未对准的问题。TDAE基于TDN,采用解码器-编码器-解码器框架,其中第一个解码器学习升采样和降噪,编码器将其投影回对齐且无噪声的LR面,最后一个解码器产生幻觉 HR图片。 相比之下,LCGE使用特定于组件的CNN对五个面部组件执行SR,对HR面部组件数据集使用k-NN搜索以找到相应的补丁,合成更细粒度的组件,最后将它们融合到FH 结果。同样,Yang等。将解块后的人脸图像分解为人脸成分和背景,使用成分界标在外部数据集中检索足够的HR样本,在背景上执行通用SR,最后融合它们以完成HR脸部。
此外,研究人员还从其他角度改善了跳频。 在人类注意力转移机制的推动下,Attention-FH诉诸于递归策略网络,该网络顺序发现有人参与的面部补丁并进行局部增强,从而充分利用了面部图像的全局依赖性。UR-DGN采用类似于SRGAN的具有对抗性学习的网络。 徐等提出了一种由通用生成器和特定类标识符组成的基于GAN的多类FH模型。 李等人和Yu等基于条件GAN利用附加的面部属性信息执行具有指定属性的FH。
5.3 高光谱图像超分辨率
与全色图像(PANs,即具有3个波段的RGB图像)相比,包含数百个波段的高光谱图像(HSI)提供了丰富的光谱特征并有助于各种视觉任务。 但是,由于硬件限制,收集高质量的HSI比PAN困难得多,而且分辨率也较低。因此,超分辨率被引入该领域,研究人员倾向于将HR PAN和LR HSI结合起来以预测HR HSI。 其中,Masi等使用SRCNN并合并了几个非线性辐射指标图以提高性能。 Qu等联合训练两个编码器-解码器网络分别在PAN和HSI上执行SR,并通过共享解码器并应用诸如角度相似度损失和重构损失之类的约束将SR知识从PAN转移到HSI。 最近,傅等人。评估相机光谱响应(CSR)功能对HSI SR的影响,并提出了一个CSR优化层,该层可以自动选择或设计最佳CSR,并胜过最新技术。
5.4 真实图像超分辨率
通常,用于训练SR模型的LR图像是通过手动对RGB图像进行降采样(例如,通过双三次降采样)生成的。 但是,现实世界中的相机实际上会捕获12位或14位RAW图像,并通过相机ISP(图像信号处理器)执行一系列操作(例如,去马赛克,去噪和压缩),最终产生8位RGB 图片。 通过此过程,RGB图像丢失了许多原始信号,并且与相机拍摄的原始图像有很大不同。因此,直接将手动下采样的RGB图像用于SR并不是最佳选择。为了解决这个问题,研究人员研究了如何使用真实世界图像进行SR。 其中,Chen等分析成像系统中图像分辨率(R)与视场(V)之间的关系(即RV降级),提出数据采集策略以进行真实世界的数据集City100,并通过实验证明其优越性 提出的图像合成模型。 张等通过相机的光学变焦建立了另一个真实世界的图像数据集SR-RAW(即,成对的HR RAW图像和LR RGB图像),并提出了上下文双向损失来解决错位问题。 相反,Xu等提出了一种通过模拟成像过程来生成现实训练数据的管道,并开发了双CNN以利用RAW图像中最初捕获的辐射信息。 他们还建议学习一种空间变化的颜色变换,以进行有效的颜色校正并推广到其他传感器。
5.5 视频超分辨
对于视频超分辨率,多个帧提供了更多的场景信息,不仅存在帧内空间依赖性,而且还存在帧间时间相关性(例如运动,亮度和颜色变化)。 因此,现有工作主要集中在更好地利用时空相关性,包括显式运动补偿(例如基于光流,基于学习的运动补偿)和递归方法等。在基于光流的方法中,廖等人使用光流方法来生成HR候选者,并由CNN将它们集成在一起。 VSRnet 和CVSRnet通过Druleas算法处理运动补偿,并使用CNN将连续帧作为输入并预测HR帧。 而刘等执行校正的光流对准,并提出一种时间自适应网络以生成各种时间尺度的HR帧并自适应地对其进行聚合。
此外,其他人也尝试直接学习运动补偿。 VESPCN利用可训练的空间变换器来学习基于相邻帧的运动补偿,并将多个帧输入到时空ESPCN 中进行端到端预测。 陶等从精确的LR成像模型出发,提出了一个亚像素样模块,以同时实现运动补偿和超分辨率,从而更有效地融合对齐的帧。
另一个趋势是使用递归方法来捕获时空相关性,而无需显式的运动补偿。 具体而言,BRCN 采用双向框架,并使用CNN,RNN和条件CNN分别对空间,时间和空间时间依赖性进行建模。 同样,STCN使用深层CNN和双向LSTM提取空间和时间信息。 FRVSR 使用先前推断的HR估计值以递归方式通过两个深CNN重建后续的HR帧。 最近,FSTRN采用了两个小得多的3D卷积滤波器来代替原始的大滤波器,因此通过更深的CNN增强了性能,同时保持了较低的计算成本。 RBPN通过循环编码器-解码器提取空间和时间上下文,并将其与基于反投影机制的迭代细化框架相结合(第3.1.4节)。
另外,FAST利用压缩算法提取的结构和像素相关性的紧凑描述,将SR结果从一帧传输到相邻帧,并以极少的速度加快了最新SR算法的发展。 性能损失。 和乔等基于每个像素的局部时空邻域生成动态上采样滤波器和HR残差图像,并且还避免了显式的运动补偿。
5.6 其他应用
基于深度学习的超分辨率也被其他特定领域的应用所采用,并表现出出色的性能。 具体而言,感知GAN通过将小对象的表示形式超分辨来解决小对象检测问题,使其具有与大对象相似的特征,并且对检测更具区分性。 同样,FSR-GAN可以在特征空间而不是像素空间中对小尺寸图像进行超级解析,从而将原始的不良特征转换为具有高度区分性的特征,从而极大地有利于图像检索。 此外,Jeon等利用立体图像中的视差先验来重建具有配准中亚像素精度的HR图像。 Wang等。提出了一种视差注意模型来解决立体图像的超分辨率问题。Li等结合了3D几何信息和超分辨3D对象纹理贴图。 张等将一个光场中的视图图像分为几组,学习每组的固有映射,最后将每组中的残差组合起来,以重建更高分辨率的光场。
总而言之,超分辨率技术可以在各种应用程序中发挥重要作用,尤其是当我们可以很好地处理大型物体而不能处理小型物体时。
6 结论和未来方向
在本文中,我们对深度学习中图像超分辨率的最新进展进行了广泛的调查。我们主要讨论了有监督和无监督SR的改进,并介绍了一些特定于域的应用程序。 尽管取得了巨大的成功,但仍然存在许多未解决的问题。 因此,在本节中,我们将明确指出这些问题,并为未来的发展介绍一些有希望的趋势。 我们希望这项调查不仅可以为研究人员提供对图像SR的更好理解,还可以促进该领域的未来研究活动和应用开发。
6.1 网络设计
良好的网络设计不仅可以确定具有较高性能上限的假设空间,而且还可以有效地学习表示,而不会产生过多的空间和计算冗余。 下面我们将介绍一些有希望的网络改进方向。
- 结合本地和全局信息。 较大的接收场可提供更多上下文信息,并有助于产生更真实的结果。 因此,有希望将本地和全局信息相结合,以提供图像SR的不同比例的上下文信息。
- 结合低级和高级信息。 CNN中的浅层倾向于提取诸如颜色和边缘之类的低级特征,而深层则学习诸如对象标识之类的高级表示。 因此,将低级细节与高级语义相结合可能对HR重建有很大帮助。
- 特定于上下文的注意。 在不同的上下文中,人们倾向于关心图像的不同方面。 例如,对于草地地区,人们可能更关注局部的颜色和纹理,而在动物体区域中,人们可能会更加关注物种和相应的头发细节。 因此,整合注意力机制以增强对关键特征的注意力有助于生成逼真的细节。
- 更高效的架构。 现有的SR模式往往追求最终性能,而忽略了模型大小和推理速度。 例如,在使用Titan GTX GPU 的DIV2K 上,EDSR 每幅图像需要20s,以获得4x SR,而对于8x SR,DBPN则需要35s。 如此长的预测时间在实际应用中是不可接受的,因此更有效的体系结构势在必行。 如何在保持性能的同时减小模型大小并加快预测速度仍然是一个问题。
- 升采样方法。 现有的上采样方法(第 3.2)具有或多或少的缺点:插值方法会导致计算成本高昂并且无法端到端学习,转置的卷积会产生棋盘状伪像,子像素层带来的接收场分布不均匀,并且元高级模块可能会导致 不稳定或效率低下,还有进一步改进的空间。 仍然需要研究如何执行有效和高效的上采样,尤其是在使用高比例因子的情况下。
- 近年来,用于深度学习的神经体系结构搜索(NAS)技术变得越来越流行,在几乎没有人工干预的情况下极大地提高了性能或效率。 对于SR领域,将上述方向的探索与NAS结合起来具有巨大的潜力。
6.2 学习策略
除了良好的假设空间外,还需要强大的学习策略来获得令人满意的结果。 接下来,我们将介绍一些有前途的学习策略方向。
- 损失函数。 现有的损失函数可被视为在LR / HR / SR图像之间建立约束,并基于是否满足这些约束来指导优化。 在实践中,这些损失函数通常是加权组合的,而SR的最佳损失函数仍不清楚。因此,最有前途的方向之一是探索这些图像之间的潜在相关性,并寻求更准确的损失函数。
- 归一化。 尽管BN在视觉任务中被广泛使用,可以极大地加快训练速度并提高性能,但事实证明,对于超分辨率而言,它是次优的。 因此,需要研究其他有效的SR归一化技术。
6.3 评价指标
评估指标是机器学习的最基本组成部分之一。 如果无法准确评估性能,研究人员将很难验证改进。 超分辨率的度量标准面临此类挑战,需要更多探索。
- 更准确的指标。 如今,PSNR和SSIM已成为SR中使用最广泛的指标。 但是,PSNR会导致过度的平滑度,并且结果在几乎无法区分的图像之间可能会发生巨大变化。 SSIM在亮度,对比度和结构方面进行评估,但仍无法准确测量感知质量。 此外,MOS是最接近人类视觉响应的MOS,但是需要付出很多努力并且不可复制。 尽管研究人员提出了各种指标(第2.3节),但目前尚无统一的公认的SR质量评估指标。因此,迫切需要用于评估重建质量的更准确的度量。
- 盲IQA方法。 如今,大多数用于SR的指标都是全参考方法,即假设我们已将LR-HR图像与完美质量配对。 但是,由于很难获得此类数据集,因此通常用于评估的常用数据集通常是通过人工降级进行的。 在这种情况下,我们执行评估的任务实际上是预定义降级的逆过程。 因此,开发盲目IQA方法也有很高的要求。
6.4 无监督的超分辨
如第二节所述。 如图4所示,通常很难收集同一场景的不同分辨率的图像,因此双三次插值被广泛用于构建SR数据集。但是,在这些数据集上训练的SR模型可能仅学习预定义降级的逆过程。因此,如何执行无监督的超分辨率(即在没有配对LR-HR图像的数据集上进行训练)是未来发展的有希望的方向。
6.5 走向现实场景
在现实世界中,图像的超分辨率受到极大限制,例如遭受未知的降级,缺少配对的LR-HR图像。 下面我们将介绍一些针对实际场景的指导。
- 处理各种退化。 现实世界中的图像往往会遭受诸如模糊,附加噪声和压缩伪影之类的退化。 因此,在手动执行的数据集上训练的模型在现实世界场景中通常表现不佳。已经提出了一些解决该问题的方法,但是这些方法具有一些固有的缺点,例如训练难度大和假设过于完善。 迫切需要解决此问题。
- 特定于域的应用程序。 超分辨率不仅可以直接用于特定领域的数据和场景,而且可以极大地帮助其他视觉任务(第5节)。 因此,将SR应用于更特定的领域也是一个有前途的方向,例如视频监视,对象跟踪,医学成像和场景渲染。

















 5341
5341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









