







在读完《C专家编程》之后收获良多就选择了继续读一些相关的书籍,本打算先看《算法导论》的,但是《算法导论》但是算法导论的篇幅实在太多,无意中在图书馆中发现了这本书就开始阅读,写下这边文档供以后回顾。
文中代码调试编译执行平台为window7,vs2013
文章目录
- 条款一:仔细区分pointers和references
- 条款二:最好使用C++转型操作符
- 条款三:绝对不要以多态的方式处理数组
- 条款四:非必要不提供默认构造函数
- 条款五:对自定义的类型转换保持警觉
- 条款六:区别++和--操作符前置和后置的区别
- 条款七:千万不要重载&&,||和,操作符
- 条款八:了解不同意义的new和delete
- 条款九:利用析构函数避免内存泄露
- 条款十:在构造函数中阻止资源泄露
- 条款十一:禁止异常流出析构函数之外
- 条款十二:了解“抛出一个异常”与“传递一个参数”之间的差异
- 条款十三:以by reference方式捕获异常
- 条款十四:明智使用execption specifications
- 条款十五:了解异常处理的成本
- 条款十六:谨记80-20法则
- 条款十七:考虑使用lazy evaluation(缓式评估)
- 条款十八:分期摊还预算的计算成本
- 条款十九:了解临时对象的来源
- 条款二十:协助完成“返回值优化”
- 条款二十一:利用重载技术避免隐式类型转换
- 条款二十二:考虑操作符复合形式(op=)取代其独身形式(op)
- 条款二十三:使用其他程序库
- 条款二十四:了解virtual functions、multiple inheritance、virtual base class、runtime type identification的成本
- `条款二十五:将constructer和nonmember function虚化`
- 条款二十六:限制某个class所能产生的对象的数量
- 条款二十七 要求或者禁止对象产生于heap中
- 条款二十八: 智能指针
- 条款二十九: Reference counting(引用计数)
- 条款三十: Proxy classes(替身类、代理类)
- 条款三十一:让函数根据一个以上的对象类型来决定如何虚化
- 条款三十二:在未来时态下发展的程序
- 条款三十三:将非尾端类(non-leaf classes)设计为抽象类(abstract classes)
- 条款三十四:如何在同一个程序中结合C++和C
条款一:仔细区分pointers和references
指针:用来指向一块内存空间的变量。
引用:一个对象的别名,用来对对象的直接操作
指针和引用都可以用来在作用域外对变量或者对象进行操作从而影响被操作的变量或者对象,但是引用必须进行初始化,而且并不存在空引用,而存在空指针。另外,引用一旦被初始化之后就不能修改
int num = 12;
int num_snd = 24;
int *ptr = nullptr;
//error:int& p = NULL;
int& p_num = num;
p_num = num_snd; //并不提示语法错误,只是因为p_num代表的是num,p_num
//所代表的对象并不被修改
ptr = #
ptr = &num_snd;
上述代码中虽然p_num = num_snd未报错,但是并不代表我们正确的修改了引用的所代表,这里因为p_num是num的引用所以修改的是num的值。
总结
当你知道你要使用什么样的变量并且绝对不会改变其他东西的时候,或者当使用指针无法或者很难完成相关操作的时候,就选择用引用(references),否则,选择使用指针
条款二:最好使用C++转型操作符
C语言支持的隐式和显式类型转换,存在很多安全隐患,而且到了C++语法繁多,之前的数据类型转换已经无法处理C++中的问题,于是C++提供了四种数据类型转换格式,分别为statci_cast<>,const_cast<>,reinterpret_cast<>,dynamic_cast<>,弥补了C语言的不足,但是C++兼容C语言的(type)parameter类型转换
1. static_cast<>
比较常用的类型转换,一般类型之间的转换,如double和int等数据之间的转换,也拥有C语言对数据类型转换的限制,比如无法将struct类型转换为int类型,将double转换为指针类型,也无法移除const性质(移除const C++有特定的关键字)
type_name expression = static_cast<type_name>(another_expression);
2. const_cast<>
用来去除const的属性(虽然功能只有这一个,但却很复杂)
C++语言中的const和C语言有很大的区别
(1). 不可修改,真正意义上的const
C语言中的const只是语法限制上的const,在C语言中下面的代码是错误的
const int buf_size = 12;
int buf[buf_size]; //some error will be reported
而上述代码在C++中运行良好,也表明了const的属性。另外说道不可修改,C语言中的const变量可以通过指针修改
const int num = 12;
int *p = # //just give a warning about the different type
//between the pointer and parameter
(*p) = 24;
printf("const:%d\n", num); //modify the value successfully
上述代码修改C语言中const很轻松
const int num = 12;
int* p = # //error C2440: “初始化”: 无法从“const int *”转换为“int *”
C++中不允许将一个const类型变量的地址传递给int类型的指针,但是C++和C语言一样允许对const数据类型取地址,尽管如此,但是无法通过其他方法来读取并修改内存。如果通过每次打印处地址之后指向内存块再修改内存是不可行的,因为const的内存有编译器自动分配每次分配不同,无法做到跟踪修改。
(2). 内存分布
在C++中const类型的和C语言中的const类型都存储在堆栈区,并不存储在常量区。(上面结论根据下面图片推论)
C语言中内存表现

C++中内存表现

注:但是我之前在某个地方看到说C++的cosnt类型内存存储在一个表中,这个表有C++编译器自动建立,当用户希望对const取内存时,C++编译器会拷贝一份到堆栈区并标注为const类型,来供用去使用内存。
(3). 作用域
C语言中const一旦定义在之后用到的文件中都是const,和定义的作用域无关,而C++中的const在类外和类定义之内不同。在C++中类外定义const就是C++中的const;但是在类内部定义const类型变量,这个类型变量遵循C语言中的const变量的规则。如下面简单的代码在C++环境中完全可以执行:
class fun
{
const int funa = 12;
public:
void fun_()
{
int* p = &(int)funa;
*p = 24;
std::cout << funa << std::endl; //打印结果24
}
};
const_cast<>的使用无法将const int类型转换为int类型,只能使用与指针的转换,如下代码
const int num = 12;
int p = const_cast<int>(num); //error C2440: “const_cast”:
//无法从“const int”转换为“int”
而且,如下代码中验证了上述C++中const的内存分配,图中可以看出内存中数值虽然改变,但是num的值并未受到影响
const int num = 12;
int *p = (const_cast<int*>(&num));
(*p) = 24;
std::cout << *p << std::endl; //打印结果24
std::cout << num << std::endl; //打印结果12

3. dynamic_cast<>
用于执行继承系中的类型转换,将基类对象指针转换为继承类指针。主要是提供父类向子类的安全检测因为子类转换为父类怎么无论如何都不会出错,但是即便用dynamic_cast<进行转换转换之后的指针仍然无法调用子类独有的函数(内存中本身就没有的东西)。
- 无法修改const类型指针
- 如果转换失败会返回一个null指针或者exception(bad_cast)
- 无法应用与缺乏虚函数的类型
4.reinterpret_cast<>
reinterpret_cast<>()提供的是将一个变量所代表的内存完全重新解析,所以使用reinterpret_cast<>()的时候要格外小心。
class man
{
public:
virtual void fun()
{
std::cout << "fun" << std::endl;
}
};
class person :public man
{
public:
virtual void fun()
{
std::cout << "man" << std::endl;
}
};
int main()
{
person* p = new person;
man* m = new man;
p = reinterpret_cast<person *>(m);
p->fun();
system("pause");
}
上述代码是一个reinterpret_cast<>的正常使用
class man
{
public:
virtual void fun()
{
std::cout << "fun" << std::endl;
}
};
class person :public man
{
int h;
int b;
public:
int a()
{
std::cout << "asd";
return 0;
}
virtual void fun()
{
std::cout << "man" << std::endl;
}
};
int main()
{
person* p = new person;
man* m = new man;
p = reinterpret_cast<person *>(m);
p->fun();
p->a(); //without error
system("pause");
// num = static_cast<int>(a);
}
上述代码不产生错误的原因大概是类共享函数,而函数在代码区,需要调用时只要到对应地址调用即可,当在函数中对子类独有的数据进行操作时就会报错。因为被转换的类型本身就不存在该数据。
条款三:绝对不要以多态的方式处理数组
1. 数组解析长度问题
数组解析的方式是根据数组的数据类型取偏移量再取出对应地址的数据,就像(*(p+i)),这在利用数组下标等使用数组中数据时会产生很多麻烦
- 调用问题
书上说,使用多态数组会因为数组指针步长的问题无法读取到相应的成员,但是在使用时这并不影响使用父类同样拥有的函数和数据。
person p1;
person p2;
man m1;
man p[3] = {p1,m1,p2};
p[1].fun();
- 删除问题
因为数组的解析问题,在删除通过new的数组时,无法确定到具体的数据成员而失败。和1同理,原因貌似不是这个
2.函数调用问题
在调用函数时,因为子类和父类同时拥有父类的函数和数据成员,所有用数组解析出来的对象使用父类的数据和函数不存在问题,但是当使用到子类的数据和成员时编译器会报错,此对象不存在该函数或该数据。
特别是在调用析构函数时,会造成严重的内存泄漏问题。这个因该是上述delete[]p所造成的错误原因,而不是步长。
条款四:非必要不提供默认构造函数
默认构造函数:在外界不提供任何信息的时候初始化类。
1、缺乏构造函数在生成数组时的缺陷
如果没有构造函数就意味着一定要向外界获取相关信息才能创建。但是在堆栈生成数组无法获取外界信息,除非一个一个分配内存。比如以下代码:
//下面代码使用到的类
class person
{
public:
person(int num)
{}
}
person p[5];
或者
person* p[5] = new[] person;
他们都存在上述所说的问题,当然可以通过一个一个的分配内存来使用也可以
person *p[5];
for(int i = 0;i < 5;i ++)
{
p[i] = new person(i);
}
但是这样存在两个问题:
1、使用到了动态内存分配,内存管理更加复杂,增加了内存泄漏的几率。
2、增加了内存空间使用,并且不方便,这里给出的只是简单地数据,当数据更加复杂时这种问题将变得严重
2、将很难适应模板类
这个原因和使用数组原因基本相同,模板会加大对内存的管理难度
3、总结
对于需不需要为类提供默认的构造函数,这个取决于所使用的环境,如果一味地不添加或者使用默认函数参数来代替从类的意义上发生了变化,这不是一种好的习惯;反之,全部添加默认构造函数又会增加系统的开销,也不算明智之举。
添不添加默认构造函数尽量根据当前使用的环境进行考虑,不要一味地认定某一种方法。
条款五:对自定义的类型转换保持警觉
C++的强大之一是它不同于C语言严格的数据类型检查,但是有些情况下C++编译器为了方便用户操作给用户带来的一些麻烦也不容忽视。
1. 隐式数据类型转换
这里说到的隐式类型转换和普通的隐式数据类型转换相同,但是直接操作符却不是来自系统而是用户,比如有一个类:
class fun
{
int deno;
int mole;
public:
fun(int d, int m) :mole(m), deno(d){}
operator double()const
{
return deno / static_cast<double>(mole);
}
};
如果我们执行代码打印一个fun类型的对象不会报错而是直接输出一个double,因为发生了隐式类型转换,这可能在这里影响不大,但是有些时候的确会造成错误。解决方法也很简单,自定义一个<<重载操作符即可。或者自定义一个成员函数来实现operator double()的功能。
2. 构造函数导致的隐式类型转换
在C++中隐式数据类型转换不仅仅来自于来源于C语言的数据类型转换,而且带有参数的构造函数也会触发隐式类型转换。比如有一个类
template<class T>
class Array
{
public:
Array(int size)
{
}
T& operator[](int index)
{
return 0;
}
};
//这个类只是简写,理解意思就行
bool operator==(Array<int> _rst, Array<int> _snd)
{
}
在对类Array执行if (_array_rst[2] == _array_snd[2])因为大意写成if (_array_rst == _array_snd[2]),这样编译器不会报错还会进行比较,因为_array_snd[2]是一个int数,而Array的拷贝构造函数需要一个int类型这就触发了隐式类型转换。这可能在工程中导致一些不可预见的错误。
解决的办法是使用explicit关键字对构造函数进行限制,这样编译器就不会触发因拷贝构造函数引起的饮食类型转换。
3、解决办法
- 添加explicit关键字,禁止拷贝构造函数的隐式类型转换
- 使用嵌套类。如将以上类修改为
template<class T>
class Array
{
public:
class ArraySize
{
private:
int _size;
public:
int size()
{
return _size;
}
ArraySize(int num) :_size(num){}
};
Array(ArraySize size)
{
}
T& operator[](int index)
{
return 0;
}
};
这就是一个代理类(proxy)可以解决隐式类型转换问题
4、总结
对于用户自定义类型转换,避免用它;而拷贝函数导致的隐式类型转换要考虑所做的具体项目的环境不能说那一种方法最好,深思熟虑。
条款六:区别++和–操作符前置和后置的区别
首先明确在操作符重载中前置++,–和后置++,–的语法如下:
class fun
{
int _num;
public:
fun(int num) :_num(num){}
fun& operator++() //前置
{
_num++;
return *this;
}
const fun operator++(int) //后置
{
fun fun_rst(_num);
_num++;
return fun_rst;
}
fun& operator--() //前置
{
_num--;
return *this;
}
const fun operator--(int) //后置
{
fun fun_rst(_num);
_num--;
return fun_rst;
}
//友元函数--类似
friend fun& operator++(fun f);
friend const fun operator++(fun f,int);
void run()
{
std::cout << _num << std::endl;
}
};
//这里重定义有语法错误,只是演示一下
fun& operator++(fun f)
{
f._num++;
return f;
}
const fun operator++(fun f, int)
{
fun tmp(f._num);
f._num++;
return tmp;
}
前置式返回一个const是为了防止出现f++++的情况,这种情况会产生误解。然而,应用时尽量使用前置++而不是用后置++就可以避免类似困扰,或者将后置++的实现依赖于前置++就不会导致两者行为不一致的情况发生。
条款七:千万不要重载&&,||和,操作符
C/C++逻辑判断采用“骤死式”判断,即逻辑语句中的短路。一旦语句的结果可以得到确定,就不会在执行语句之后的表达式,如num_rst || num_snd,如果num_rst是一个不为0的数则判断结束,编译器不会判断num_snd所代表的表达式是否有语法错误。
在使用操作符重载时有一个问题是,操作符重载的调用类似于调用一个函数operator&&(),这和语言中所拥有的操作符行为方式不同;语言中的操作符的解析方向是从左向右解析,而且拥有“骤死式”的特点,而在使用重载操作符的时候,你无法实现像编译器一样的解析行为,这就可能导致在阅读代码时产生的误解。所以非必要不要使用这些操作符重载,实在必须使用一定要小心。
重载逗号同理,无构建和编译器解析方式相同的函数。这会带来麻烦。
条款八:了解不同意义的new和delete
1. new operator和operator new
new operator:就是常用的动态内存分配;例如int* p = new int;当动态分配的是一个对象时,编译器会自动地为对象分配内存并且初始化对象。
operator new(size_t size)是对new操作符的重载,他所做的只是为对象分配内存,并不对对象初始化,当然也可以在自定义new函数中使用new operator完成某些额外的功能,但是用户不具有显示调用构造函数的权限,(感觉有问题,用户可以调用构造函数和析构函数)这就造成operator new()的局限。下面书上介绍的比较实用的一种方法:placement new
一般operator new代码
void* operator new(size_t size)
{
//TODO:add some codes here
}
Placement new
placement new可以实现在特定的内存块中初始化对象指针。
class widget
{
public:
widget(int num);
}
widget* construct_widget_in_buffer(void* buffer,int widget_size)
{
return new(buffer) widget(widget_size);
}
这和普通的operator new不同,他完成了对对象的初始化,而且将对象局限于指定的内存空间中,使得对象完全具有可操作性。
2. delete operator和operator delete
operator delete与delete operator和operator new与new operator之间的区别很相似,operator delete只是释放相应的未初始化的内存和operator new搭配使用很像C语言中的malloc和delete;而delete operator则是先调用析构函数销毁对象再释放对象所对应的内存。
条款九:利用析构函数避免内存泄露
在程序使用一个通过动态内存分配的指针时,函数调用的中途发生异常,C语言的做法一般是尽可能的考虑到所有可能发生异常的情况,并在函数执行的过程中通过if…else…语句判断某种情况的发生并对相应情况进行处理,这种做法很依赖程序员的思维严密性,如果程序员在处理异常时,少考虑几种情况,错误将无可避免的蔓延。而C++中提供了异常处理机制execption:
try
{
//the executable code
}
catch(...)
{
//handle the execption
}
这种处理方式相对于C语言来说,用户不用担心有考虑不到的错误被遗忘;和C语言相同的地方是处理方式由程序员决定,内存的释放等在代码量过大时,这种处理方式依然存在C语言存在的缺陷。
1. 使用auto_ptr
C++提供了auto_ptr智能指针来进行内存自动管理,当错误发生时,程序员不用在意内存的分配情况,只需处理其他事宜即可。然而,智能指针也存在很多局限,所以不要乱用。
std::auto_ptr<fun> p(new fun(1)) ; //即使不释放也不存在内存泄露的问题
auto_ptr的缺陷:
- auto_ptr不能共享所有权,即不要让两个auto_ptr指向同一个对象。当将两个auto_ptr指向同一个对象时,后指向对象的指针会保留,先指向对象的指针会失去所有权,不能再使用;
- auto_ptr不能指向数组,因为auto_ptr在析构的时候只是调用delete,而数组应该要调用delete[]。
- auto_ptr只是一种简单的智能指针,如有特殊需求,需要使用其他智能指针,比如share_ptr。
- auto_ptr不能作为容器对象,STL容器中的元素经常要支持拷贝,赋值等操作,在这过程中auto_ptr会传递所有权。
2. 利用auto_ptr的原理将资源封装于类中
设计一个class将资源封装于这个class中,用构造函数来为对象中的资源分配和获取资源,利用析构函数释放对象中的资源,并且向拷贝构造函数和赋值操作符声明为私有,这个资源的对象就是独一无二了。
class window_handle
{
private:
widget* w;
window_handle(const window_handle&);
window_handle& operator=(const window_handle&);
public:
window_handle(widget* handle):w(handle){}
void destroy_window();
~window_handle()
{
destroy_window(w); //释放资源
}
}
这样就将一个分配于堆中的数据对象交由编译器作为栈上的成员进行内存管理
条款十:在构造函数中阻止资源泄露
当创建一个类,这个类中包含多个类;假如在这个类进行初始化的时候构造函数抛出一个异常,此时按理说在处理的时候编译器调用析构函数来释放掉分配好的内存,无论是栈上的还是堆上的。但是事实是编译器不会这么做,因为要对一个构造失败的类进行对象的销毁要知道这个类的初始化进行到什么程度才能准确的释放内存,这就需要一个标识,但是加入标识就对于每一个类的创建都会增加开销;而且C++是基于对象的,这无疑是为编译器带来了很大的麻烦。另外,智能指针无法处理未完成的对象当然可以在上述代码中添加try…catch…异常处理。所以当在构造函数中初始化失败时编译器并不调用任何析构函数。
1. 普通类型指针
代码:
class widget
{
private:
Icon* _icon;
string* _name;
public:
widget(string& name,string& icon):(_icon)(0),_name(0)
{
if(name != "")
{
_name = new string(name);
}
if(icon != "")
{
_icon = new Icon(icon); //throw a exception
}
}
...
}
加入上述代码在构建icon时抛出一个异常,那么这个无论异常到底是谁抛出的widget的构造函数都会接回控制权,而已经构造好的name因为内存无法释放而造成资源泄露问题。修改后的构造函数是:
class widget
{
private:
Icon* _icon;
string* _name;
public:
widget(string& name,string& icon):(_icon)(0),_name(0)
{
try
{
if(name != "")
{
_name = new string(name);
}
if(icon != "")
{
_icon = new Icon(icon); //throw a exception
}
}
catch(...)
{
delete _icon; //C++delete空指针不会出问题
delete _name;
}
}
...
}
更完美的改进版是将清除函数封装为函数:
class widget
{
private:
Icon* _icon;
string* _name;
public:
void clean_up()
{
delete _icon; //C++delete空指针不会出问题
delete _name;
}
widget(string& name,string& icon):(_icon)(0),_name(0)
{
try
{
if(name != "")
{
_name = new string(name);
}
if(icon != "")
{
_icon = new Icon(icon); //throw a exception
}
}
catch(...)
{
clean_up();
}
}
~widget()
{
clean_up();
}
...
}
2. 常量类型指针
当对象中包含的指针是常量指针时就存在另一个问题,常量成员只能通过成员初始链表进行初始化,而利用这种初始化方式就无法使用try…catch()进行异常捕获。
class widget
{
private:
const Icon* _icon;
const string* _name;
public:
widget(const string& name,const string& icon):
_icon(icon != ""?new Icon(icon):0),
_name(name != ""?new string(name):0)
{}
...
}
这种情况由于在构造函数中无法使用try…catch()进行异常处理就无法捕获异常。但是可以将成员变量的初始化封装为函数这样就可以进行有效的管理。
class widget
{
private:
const Icon* _icon;
const string* _name;
public:
widget(const string& name,const string& icon):
_icon(init_icon(icon)),
_name(init_name(name))
{}
Icon* init_icon(const string& icon)
{
if("" != icon)
{
return new Icon(icon);
}
return 0;
}
string* init_name(const string& name)
{
try
{
if("" != name)
{
return new string(name);
}
return 0;
}
catch(...)
{
//_name初始化失败不用释放
delete _icon;
throw;
}
}
}
上述方法解决了这类问题,但是将对象的初始化分散于不同的空间对于管理来说极不方便。
还有一种方法是将成员变量封装于一个类似于指针的对象中,就类似前面讲到的智能指针和自定义的数据封装。
class widget
{
private:
const auto_ptr<Icon> _icon;
const auto_ptr<string> _name;
public:
widget(const string& name,const string& icon):
_icon(icon != ""?new Icon(icon):0),
_name(name != ""?new string(name):0)
{}
}
3、总结
解决在对象构造的时候抛出异常的方法:
- 使用异常处理机制捕获异常(普通指针类型);
- 将成员的初始化封装,但对于管理类不利(const 指针和普通指针);
- 将成员封装于一个类中,有该类来代理成员的管理(const 指针和普通指针)。
条款十一:禁止异常流出析构函数之外
了解析构函数中的异常之前先了解何种情况下析构函数会被调用
- 对象被正常销毁时;
- 当对象被异常处理机制进行栈展开进行销毁时。
当析构函数被调用可能是因为一个异常的产生,如果此时析构函数再抛出一个异常,编译器会调用terminate来终止程序即便对象销毁失败。
解决办法也很简单就是在析构函数中增加异常处理。
widget::~widget()
{
try
{
//executive codes
}
catch(...)
{}
}
上述代码中即便catch中任何事都不做但还是防止了异常跳出析构函数,控制权依然在析构函数中。使用异常的原因:
- 组织了编译器调用terminate,保证了程序的安全;
- 确保析构函数完成自己该完成的工作
条款十二:了解“抛出一个异常”与“传递一个参数”之间的差异
void fun(widget w);
void fun(widget& w);
void fun(const widget& w);
void fun(widget* w);
void fun(const widget* w);
void catch(widget w);
void catch(widget& w);
void catch(const widget& w);
void catch(widget* w);
void catch(const widget* w);
上述代码中前五种是函数调用,函数调用参数传递分为三种形式:传值,传引用,传地址,除了传值会发生对象或者数据的拷贝其他两种都不会触发拷贝动作;而异常处理不同,无论是通过传值还是传引用(传地址不允许,会造成类型不吻合)都会发生对象或者数据的拷贝动作,因为抛出异常意味着离开调用函数返回调用端,这样局部变量会被销毁,如果允许传引用,那么catch将收到的是被销毁的对象。(即使对象不会被销毁,拷贝动作也会发生)
catch(widget& w)
{
throw;
}
catch(widget& w)
{
throw w;
}
上面的两段代码执行效果不同,第一段代码throw会将异常重新抛出;而第二个代码会抛出一个widget的复本,传值的话会复制两次,会发生拷贝构造,产生的复本只是一个临时对象。
1. execption普通类型的匹配
在抛出异常时和调用函数有很大的不同是,调用函数如果函数参数类型不匹配,编译器会尝试进行隐式类型转换来匹配参数,而异常类型匹配时不会调用任何隐式类型转换的功能。
void fun(int value)
{
try
{
throw value;
}
catch(double d) //can get the int
{}
}
在上述代码中catch不可能捕获到value触发的异常,他只能捕捉double类型
2. 继承异常类型捕捉
下面是execption的继承图

继承类异常的捕获意味着父类异常可以兼容子类异常。
catch(runtime_error)
上面的代码可以捕获runtime_error的异常也可以捕获继承自runtime_error的异常。因此当写出两个以上的catch,并且catch的对象具有继承关系时,要考虑catch的顺序,将子类catch放在父类catch上面是好的选择,否则子类catch永远不会被执行。
try
{}
catch(range_error)
{}
catch(runtime_error)
{}
  
### 3. 任意类型指针捕获
```cpp
catch(const void*)
可以捕获任意类型的指针。
3、总结
- 异常对象总会被复制,通过值传递时会复制两次
- 捕获异常不会做过多的类型转换
- 继承类的捕获注意匹配次序,父类可以兼容子类
条款十三:以by reference方式捕获异常
1. 传址
异常处理时该如何选择使用传值,传址,传引用;传址不会发生对象的复制,这相对于传值来说性能方面要优越不少,但是传址又会衍生很多问题,比如传址不能传递一个局部的指针,这样离开作用域对象被销毁指针会失效,当然,可以使用传递全局变量或者静态变量来消除这些问题,但是全局变量和静态变量的销毁也是一个问题。可能你想使用throw new execption;来解决问题但是这样抛出的指针你什么时候销毁,该不该销毁又是一个很头疼的问题。
另外,语言中有一些惯例,比如:bad_alloc,bad_cast,bad_typeid,bad_exception诠释对象,不能用传址来捕获。
2. 传值
传值不存在传址中存在的诸多问题,不用考虑何时进行对象的销毁,但是传值有两个很严重的缺点:
- 传值会在发生异常时进行自动的拷贝对象,造成较高的资源耗费;
- 传值在面对继承类问题时比较尴尬,会发生对象的切片,子类对象会丢失对应的子类数据和成员函数,多态机制也会失效。比如:2.传值在面对继承类问题时比较尴尬,会发生对象的切片,子类对象会丢失对应的子类数据和成员函数,多态机制也会失效。比如:
class exception //这是一个标准的execption类
{
public:
virtual const char* what() throw();
};
class user_execption:public exexption
{
public:
virtual const char* what() throw();
};
void fun(void)
{
try
{
throw user_exception;
}
catch(execption w)
{
//TODO:
std::cout<<w.what()<<std::endl;
}
}
上述代码中用户catch可以接受用户创建的类的异常,但是user_exception会被切片,失去对应的成员函数和数据,只保留父类的成员;当调用what函数时多态不再适用,而是调用父类的what,这回导致异常类型处理的错误。
3. 传引用
当使用引用时以上问题都不存在,而且对象只会被复制一次,相对于使用传址的安全性和传值造成的对象切片相对来说要好得多。
在异常处理时尽量使用传引用,可以避免很多问题!
条款十四:明智使用execption specifications
使用异常规范可以让程序更加的清晰可读,但是程序中不移动按照用户所规定只抛出指定的异常,而且编译器对于异常规范并不进行严格的局部性检查。而且unexpected发生编译器会调用timinate来终止程序无法进行内存的释放。例如:
void fun(); //可以抛出任何东西
void fun_snd() throw(int);
void fun_snd() throw(int)
{
fun();
}
这样即便fun函数会抛出和int不相符合的异常编译器基本不会报错,会提出一些警告,这种弹性是为了在以后进行代码整合时方便使用。
避免unexpection的方法:
- 千万不要将异常规范和template混合使用。
- 当A函数调用B函数时,若B函数未使用异常规范A函数就不要使用异常规范。另外,回调函数是一个很难发现的点。
- 处理系统中可能抛出的异常。将非预期的异常转换为一个类型(继承)是一个比较不错的做法;另外,如果非预期的异常的复本被抛出,该异常会被标准异常bad_exception代替。
void convert_unexpected()
{
throw; //重新抛出异常,非预期异常被 //bad_exception替代
}
set_unexception(convert_unexpected); //安装convert_unexecped,作为 //unexpected的替代品
条款十五:了解异常处理的成本
异常处理在每个块语句都要进行大量的簿计工作,要对try语句的进入点和离开点进行记号,以及对应处理的exception类型这都会带来一定的开销,而且即便你的程序并未抛出异常,而只是提供了异常的支持这也会带来一定的开销,特别是你本打算不使用异常而你调用的库函数中使用了异常时,就意味着你支持了异常,这可能很头疼,但没办法,另外,当异常抛出时程序所遭受的成本是很大的,因此在不要使用异常的时候尽量不要使用异常,这会使你的代码更加高效。
条款十六:谨记80-20法则
80-20法则:一个程序的80%的资源用在20%的代码上,比如80%的内存,时间,磁盘访问,CPU使用等都用在20%的代码上。但是80-20法则并不拘泥于这一数字,可以理解为大部分系统资源花费在少量的代码上。但是对于程序中如何适当的把握这个80-20法则,大部分的选择是“猜”,但是“猜”这一做法并不可取。当项目的架构过于庞大时仅靠猜的话是无法确定程序中的低效率块的。
在程序分析时尽量使用适当的代码分析工具对你的代码进行分析来帮助你找到程序中比较耗费资源的代码段,因为依靠具体的数据比靠直觉更加可靠。
所以进行程序的优化时尽量不要靠你的直觉或者某些没有具体依据的方法进行估计,应该使用多种代码分析工具得到大量的关于你的代码的数据来分析代码。
条款十七:考虑使用lazy evaluation(缓式评估)
考虑到程序的效率问题,如果让程序员在程序完成时尽可能的进行代码的优化,这对于程序员来说并不是一件简单的事情。所以我们可以采用一种我们小时候经常干的一种方案:在父母要求我们整理房间时,我们一般都不喜欢立马去按照父母的要求进行整理,而是尽可能在父母在进行检查时才会尽快完成父母下达的命令,并且如果父母不进行检查我们可能就不进行相应的整理。这种思想可以应用在代码的编写中,可以使一个代码只在被需要时被创建,在不需要的时候就不创建。
1.引用计数
对于一个字符串类,我们一般会构造对应的拷贝构造函数来防止浅拷贝的发生完成深拷贝,防止两个对象拥有同一片内存,而缓式评估就是要利用浅拷贝在这种特性,浅拷是为了防止对两个中的一个数据进行修改的时候而导致另一个数据也别修改的现象发生,但是如果只是发生数据的拷贝和读取不存在数据的修改等操作,深拷贝就是在浪费系统资源。只需在需要对数据进行修改时发生深拷贝这就对系统资源进行了最大程度的节约。例如一个string类:
class String{};
如果我们知识进行对字符串的读取工作那么深拷贝工作就是多余的,比如
String str_rst("this");
String str_snd = str_rst;
std::cout<<str_snd;
std::cout<<str_rst + str_snd;
上面的两部操作并不需要完成深拷贝,当我们需要对数据进行修改时就需要考虑“收拾房间”了不能载拖延了。这就造成一个问题,不同的函数在使用该类成员时,都可能对数据进行修改所以这就需要程序员来判断如何组织程序中拖延的代码,当然也可以使用标志位来判断深拷贝是否进行(书中没有的部分,自己家加的),这样虽然多了判断但是相对于深拷贝的效率还是不错的。
2.区分读和写
对于类的成员数据的读写问题,读取数据的工作很是廉价,但是写数据的同时我们可能会对数据进程副本操作,从而效率方面可能不太好。当我们想要通过区分数据的读和写来在对应的代码中做正确的事情但是我们无能为力判断代码的读写操作,但是如果使用代理(proxy)类或许是一个不错的选择。
3.Lazy Fetching
现在想象你的程序拥有一个超大类,这个类包含了很多数据,因为类过大数据只能存储在数据库中,当你的程序需要使用这个类时,一般情况下是很难使用到所有的数据的,一般知识使用到一个或者几个字段
class data
{
public:
data(data_id id);
void get_whole_data(data_id id);
void operate_data(data_id id);
const String& get_data_rst();
const String& get_data_rst();
const String& get_data_rst();
}
如果对数据的处理只是对部分数据的处理。
void operate_data(data_id id)
{
data _data(id);
if(data.get_data_rst() == NULL)
//TODO:some operations
}
上面代码中我们只是对data的一个字段进行了操作但是我们却将整个数据加载到内存,这明显是对系统资源的浪费。
这种时候我们需要做的是就是产生一个数据外壳,这个外壳中没有任何数据只有数据的描述,知识高速使用者我这理由这个数据但是我没有取出来;将这个例子联系到生活就是当采购员去采购货物的时候总是浏览货物报表才开始验货,这样的效率不会太低。代码描述:
class data
{
private:
mutable string *data_rst;
mutable string *data_snd;
mutable string *data_thd;
public:
data(data_id id);
void get_whole_data(data_id id);
void operate_data(data_id id);
const String& get_data_rst();
const String& get_data_rst();
const String& get_data_rst();
}
现在类中的指针都指向对应的数据字段,当要使用数据时才对数据进行加载否则时高告诉用户我有这个数据但是暂时不在内存中,感觉有点像动态分配内存的用例一样,当然数据字段指针中的mutable(告诉编译器我知道我在干什么可以在const member函数中改变成员的值)可以通过在const member函数中用临时变量获取再进行相应的操作来兼容老版本的C++。
4.Lazy Expression Evaluation(表达式缓评估)
作者利用矩阵的例子来说明问题,不如我们需要一个1000×1000的矩阵的和或者乘积,但是如果真的执行这种操作对CPU来说其代价可想而知,但是生活中如果我们需要一个这么大的矩阵的值我们一般值要求输出或者操作其中少数的元素,因此我们可以构建一个两个矩阵的和比如:
class matrix{};
matrix m_rst(1000,1000);
matrix m_snd(1000,1000);
class matrix_add
{
private:
matrix* _m_rst;
matrix* _m_snd;
char _ch; //operation
public:
///TODO:
}
上述代码中我们用matrix_add来表示矩阵的和,但是实际上我们并未进行计算,只是构造了矩阵的和。虽然程序计算所有矩阵单元的数据的代价上升了,但是在实际应用中我们几乎用不到整个矩阵,因此这样代码的效率就被这样的小聪明给提高了。需要注意的是我们要保证类matrix_add和两个成员之间的实时性,当其成员中的一个数据被修改,matrix_add中的类就应该得到更新。
5、总结
上述的只是一种思想可以运用到很多的代码设计中而且上述思想使用应该仔细考虑你的类的工作环境不要一味的使用缓式评估。当你的类必须老老实实的做每一件事情时这种缓式评估明显就是一种累赘了。
条款十八:分期摊还预算的计算成本
函数实现总共有三种方式:
- 实时评估(eager evaluation);
- 缓式评估(Lazy evaluation);
- 急式评估(over-eager evaluation)。
三种方式都有实用的场景,之前我们讨论过缓式评估(Lazy evaluation),是尽可能的拖延做某件事,但是这种方法并不适应于任何环境如果你需要做一件经常要做的事情时,拖延可并不是一个比较好的方案。这里我们将说道急式评估,就是指尽可能的提前做某件事。
1. Caching
如果你需要经常取一个数据,那么事先将数据保存好不就很号吗。
比如你要经常取一个数据,我们可以将他保存在一个缓存中并且进行实时的更新这样就不会因为多次取同一个值而造成重复的操作(下面的例子是关于从数据库中取一些信息):
//get the number of a employee
int find_number(const string& employee_name)
{
typedef map<string,int> cache_map; //暂存
static cache_map _cache_map;
//find a memeber in the map
cache_map::iterator it = _cache_map.find(employee_name);
if(_cache_map.end() == it)
{
//TODO:get data from database
//TODO:add the data into the map
}
else
{
return (*it).second;
}
}
上面的例子是从数据库中取出一个员工的编号,并且将经常取到的员工数据在缓存中实时更新。这样当多次取同一个数据时的效率就会有不错的提高。over-eager evaluation的目的是降低平均效率,和之前的实现方法相同必须考虑使用的环境。
2. Prefetching
Prefetching(预先取出)是另一种做法,比如当你需要从磁盘中读取数据时,即使你需要的只是少量的数据,但系统还是会读取一个块,因为读取一个块比读取小块数据要快,而且当你读取一小块数据时,旁边的数据被需要的概率也相对比较大,系统就是这样为你取数据。
这个当然也可以使用在代码的优化上,比如动态分配数组,比较一般的做法时当数组到达上界时就将数组进行扩展,但是这样做如果一直需要对数组进行数据的插入时,这样做的效率因为不断调用内存分配函数不断下降。为何我们不每次动态分配时给他分配一个块呢比如将内存扩展为原来的多少倍之类的,这样做不是更加合理?可能你的数组不需要这么大内存空间但是相比于处理数据比较多的情况时的代价还是不错的。
3.总结
我们可以明显现的看到急式评估是在用内存空间的牺牲来获取效率,所以说这两者之间需要一个平衡,我们不能为了代码的效率不顾系统的内存,也不能为了节省内存放弃代码的运行效率,需要将平衡控制在二者之间,这个需要你自己判断。而且上述的是一种编程的思想不要只用C++取思考他,抽象他是最好的,它适用于任何语言。
条款十九:了解临时对象的来源
在C语言中临时变量就是指暂时作为数据的替代品的变量,例如经常使用的数据交换程序swap中的temp,但是在C++中临时和C语言中不同,上面所说的临时变量在C++中为一个局部对象。而C++中真正的临时对象是不可见的也不会出现在你的代码中。一个非堆对象(non-heap object)并且没有为它命名便是临时对象。临时对象的两种情况:
- 隐式类型转换被强行使用来试函数调用成功;
- 函数返回对象时。
因为临时对象的产生会有对象的产生和销毁所以对代码的效率而言是不可忽略的。
1. 隐式类型转换产生临时对象
当函数形参类型和实参类型不同时编译器会调用隐式类型转换来匹配函数参数这时就会产生一个临时对象。比如:
void operate(const string& str);
//函数调用时
char* str = "do";
operate(str); //类型不匹配
在函数调用时函数参数不匹配str是char类型而函数参数需要const string类型,此时编译器会自动用char来初始化string类型的变量来产生一个临时变量,当函数调用失败时临时对象被销毁,类似于局部对象。这种处理在不同功能的环境下可能会提高兼容性,也可能成为累赘,甚至影响代码的结果。可以参考条款5。因此需要根据情况考虑是否进行代码的修改等。在上述例子中如果对象以值传递的话或是对象被传递给一个常引用这种转换才会发生,但是如果传递给一个非常引用就不会发生类似的转换。
2. 函数返回值
返回值的问题可能不太好解决,一般情况下我们并不希望在这里承担额外的成本但是对于返回值的临时对象貌似我们又无能为力,但是还是存在一些优化方案来避免这些额外的开销,这些将在条款20中阐述。
3.总结
临时对象对资源的耗费是我们不想看到的,所以我们需要敏锐的眼力来排除这些临时对象产生的代码。任何时候当我们看到常引用参数就要小心,这里很可能会产生一个临时对象来拖累你的代码,而且当看到函数返回值时也应该小心。
条款二十:协助完成“返回值优化”
如果函数以值传递来返回值,则对象的构造函数和析构函数的调用是无法避免的,也就是无法进行更深层次的优化。有些代码你是无法进行过多的优化的,比如:
class Rational
{
public:
Rational(int mer = 0,int deno = 1);
//TODO:add the function here
}
const Rational* operator*(const Rational& _rst,const Rational& _snd);
上述代码中一定会产生新对象(尽管如此,C++程序员还是可以试图找到进行某些优化的方法见条款23和条款21),而且上述代码返回的是一个指针有些时候还必须考虑删除指针的代价和麻烦。
还有一种可能是函数返回一个引用,但是返回一个在函数内部构建的对象的引用没有任何意义,因为在函数结束时对象会被销毁,引用所表示的东西不再存在。所以有些函数必须返回一定的对象时不要强迫它。我们要做的是在对象创建的同时的成本不应该试图消除对象的创建工作,而是尽量降低对象的创建成本。
我们可以让编译器在返回对象时不产生临时变量而减少相关的成本,我们需要做的就是返回constructor arguments来取代对象。如:
const Rational operator*(const Rational& _rst,const Rational _snd)
{
return Rational(_rst.mer() * _snd.mer(), _rst.deno()._snd.deno());
}
这样在代码中也许看起来还是必须为构造函数和析构函数付出代价,但是C++编译器允许对临时变量进行优化,这就是C++中的返回值优化。当然也可以将函数声明为inline来消除额外的开销。
条款二十一:利用重载技术避免隐式类型转换
为了避免隐式类型转换我们在之前的条款中,描述了隐式类型转换带来的危害,但是有些时候隐式类型转换可以兼容用户的一些行为,但是同时因为隐式类型转换又会引发临时变量的创建,而导致的额外的开销我们又不得不去重视。我们可以采用重载的方式指定特定的参数来防止临时对象的产生,来达到我们提高效率的目的(注意:重载时重载操作符必须至少一个是用户定制类型)。
但是这样做我们必须考虑程序的环境如果程序中指定的对象和可能发生隐式类型转换的数据可能发生和重载操作不同的关系时,就要可能只能接受效率的削弱问题。另外更多的重载函数可能会导致条款16的问题,所以还是要看具体的情况,这里只是提供一种方式。
条款二十二:考虑操作符复合形式(op=)取代其独身形式(op)
在写程序时对于用户定制类型的对象必须由用户自定义重载相关操作符的运算,而我们一般建议用对象的复合操作符(如:operator+=)来实现对象的独身操作符(如:operator+),这样在进行代码的维护时我们只需对复合操作符进行维护就可以了。如:
class number
{
public:
number& operator+=(const number& _rst);
number& operator-=(const number& _rst);
};
const number operator+(const number& _rst,const number& _snd)
{
return number(_rst) += _snd;
}
const number operator-(const number& _rst,const number& _snd)
{
return number(_rst) -= _snd;
}
代码中的复合操作是从头写起的,而独身操作是引用复合操作,相对的维护就比较简单。当然,我们也可以将代码整合为模板这样在使用函数时就更加方便。
template<class T>
const T operator+(const T& _rst,const T& _snd)
{
return T(_rst) += _snd;
}
template<class T>
const T operator-(const T& _rst,const T& _snd)
{
return T(_rst) -= _snd;
}
现在还有一个问题没有讨论就是函数的效率问题。
第一,一般来说调用复合操作符的效率相对于独身版本来说效率要高。因为独身版本要返回一个新对象要承担对象的构造和析构的代价,而复合版本不用考虑这些;
第二,同时提供独身版本和复合版本为用户提供多种选择,如何将代码优化就是客户的权利而不是有你来掌控,而当你是用户时你要知道复合操作的效率要比独身操作的效率高。
其他:看看下面两段代码:
template<class T>
const T operator+(const T& _rst,const T& _snd)
{
return T(_rst) + _snd;
}
template<class T>
const T operator+(const T& _rst,const T& _snd)
{
T result(_rst)
return result + _snd;
}
可能在你看来两段代码没有区别但是第一段代码的效率相对于第二段代码的效率要高,因为第一段代码编译器可以选择返回值优化,但是因为第二段代码中有命名对象编译器无法选择返回值优化在一个命名对象上。在程序中匿名对象相对于命名对象更容易销毁所以在临时对象和命名对象之间抉择时,尽量考虑临时对象。
总结
需要知道的是复合版本相对于独身版本有着更高的效率的倾向,作为一名程序库设计者应该提供二者的实现;作为软件开发人员,如果程序将效率作为重要因素,尽量使用复合版本。
条款二十三:使用其他程序库
程序设计中我们都希望有一种小、快速、威力大、弹性十足、有扩展性有良好支持、使用时没有束缚,而且没有bug的程序库,但是现实生活中这种东西不可能存在,多多少少会做一些折中。而且不同的程序库在不同方面有不同的偏向,从而在另一个方向有牺牲。比如:stdio库和iostream库的偏向就有所不同,在向屏幕输出内容时,iostream库的效率低于stdio的效率,因为iostream库的输出在编译器就决定了,而stdio是在程序执行期决定的。但是iostream相对于stdio库更加的安全可扩充使用起来更加的灵活。其实,在对程序进行优化时,要根据你的程序的权重来选择不同的程序库和优化方案来达到你的目标。
条款二十四:了解virtual functions、multiple inheritance、virtual base class、runtime type identification的成本
1. 虚函数
在C++中因为虚函数的存在使得多态机制可以让用户类的设计和使用时有更大的灵活性,而虚函数如何管理和调用对于程序的效率来说很是重要。类中的虚函数的实现原理是函数指针也就是虚函数指针(virtual table pointres简写为vptrs),而这些虚函数指针存储在一个虚函数表(virtual tables简写为vtbls)中。vtbl通常是一个有函数指针组成的数组,但是有些编译器也会选择使用链表来管理虚函数,但是策略基本相同,就是使用线性表来管理函数指针。程序中的每一个class一旦声明或者继承了虚函数,那么这个类一定有一个vtbl,而虚函数表中保存的就是这个对象的个中虚函数的指针。如下代码:
class father
{
private:
int _num;
public:
int _fuck;
public:
virtual int fun_rst()
{
std::cout << "fun_rst used!\n";
return 1;
}
virtual int fun_thd()
{
std::cout << "fun_thd used!\n";
return 3;
}
virtual int fun_snd()
{
std::cout << "fun_snd used!\n";
return 3;
}
void print_p()
{
printf("_fuck的地址 %p\n", &this->_fuck);
printf("_num的地址 %p\n", &this->_num);
}
};
在vs的命令行工具下输入cl /d1 reportSingleClassLayoutBase1 yuan.cpp命令来查看函数中类的虚函数表其中 reportSingleClassLayoutBase1 Base1是指定类的名字,yuan.cpp是对应的源文件必须经过编译。如图为上述代码的虚函数表:

从打印出的内容可以看出类的数据成员和函数是分开的,非虚函数是不会保存在虚函数表中,而且虚函数表中的虚函数的排列顺序是和代码的顺序相关的。从图中可以看出类的大小为12个字节除了两个成员外又多了4个字节也就是一个int类型的长度,多余的字节就是虚函数表的指针,他指向虚函数表。我们可以通过虚函数表指针来访问虚函数,代码如下:
father tmp;
typedef int(*FUN)();
FUN ptr = NULL;
int* p_vtbl = (int*)&(tmp); //虚函数表地址
int* p_vtbl_function = (int*)*p_vtbl; //虚函数表中第一个虚函数的地址
for (int i = 0; i < 3; i++)
{
((int (*)())*((int*)*((int*)&(tmp)) + i))(); //函数调用的展开
ptr = (FUN)*(p_vtbl_function + i);
ptr();
}
从图中可以很容易的看出类中虚函数的调用原理((int (*)())*((int*)*((int*)&(tmp)) + i))();是将类的地址转换为对应虚函数的地址,i为偏移量。我们通过打印虚函数的地址和成员函数的地址可以猜测,类中的成员函数和数据成员的存储方式是虚函数表的指针然后才是数据成员,也就是说对象对应的指针就是虚函数表的地址,下图只是一个示意图不保证完全正确,因为不同编译器的行为不同:

上面说的是简单的一个类,下面代码展示一个继承的类:
class son :public father
{
public:
virtual void son_fun()
{
std::cout << "son fun\n";
}
virtual int fun_snd()
{
std::cout << "function in the son!\n";
}
};

图中显示的是继承类的虚函数表,可以看出未被类重写的父类虚函数仍旧保存在虚函数表中,而被重写的虚函数被重写的函数替代。
因此每一个类中最少有一个虚函数表(多重继承有多个),这个虚函数表一定会占用一定的内存空间,而这个虚函数表的大小取决于类中虚函数的多少。这个虚函数表的存储位置取决于编译器。
这种存储策略分为两种阵营,第一种是暴力式做法就是在每一个需要虚函数表的目标文件中产生一个虚函数表的副本,最后再由链接器剥离重复的副本,使得最终的程序库或者可执行文件中只有一个虚函数表的实体。
另一种策略是探勘式做法,决定哪一个目标文件应该内含某个class的虚函数表。基本的做法是:类的虚函数表被产生于“内含第一个non-inline,non-pure虚函数定义式”的目标文件中,所以不要将虚函数声明为inline否则可能为虚函数表的创建产生麻烦。
从上面的虚函数原理看来虚函数会带来两个成本问题:第一,虚函数表的保存必须耗费一定的内存空间,这取决于你的虚函数的多少;第二类成员中必须维护一个虚函数表的指针。
因为虚函数的调用就是利用函数指针进行调用,所以虚函数的调用基本不构成性能上的瓶颈。
2. 多重继承
在C++中多继承往往将问题复杂化,在多重继承中类中一般有多个虚函数表(每个基类对应一个虚函数表),而且定位相关的虚函数表也比较复杂。成本方面多重继承相对于单继承的成本增加和继承的类相关,内存空间的压力增加了一些,运行期的调用成本也有一定的增加。
而且多重继承也会增加另一个麻烦,当孙子继承于某两个父类而这两个类有继承自同一父类时,孙子中就会存在两个祖先的成员数据,这可以通过虚继承和虚基类来解决。但是会在类中增加隐藏的指针,这些指针用来防止基类对象的复制。内存图如下(内存分布一把取决于编译器这里只说一种):
class grad_father{};
class father_rst:virtual public grad_father{};
class father_snd:virtual public grad_father{};
class son:public father_rst,public father_snd{};

增加指针只是一些编译器的做法而另一些编译器并不会增加相应的指针而将这份工作交由虚函数表来做。图中只是为了理解一种处理方式而已。如果加上虚函数表的话就是下面这样:

图中阴影部分为编译器为你的类增加的部分,而且类中只有三个虚函数表不是四个,这种做法可以有效的减少程序的开销。
3. RTTI(runtime type identification)
在运行时类的信息会被存储在type_info对象中,我们可以使用type_id来获取类的相关信息。拥有虚函数的类为了管理这个type_info对象可能将他保存在虚函数表中,因此每个类都要为type_info的对象负责。但这并不不意味着你的程序会因为RTTI机制而付出更多的效率代价。RTTI让你可以在程序中实时的获取类的类型等方面的信息,这比你自己管理你的类来说可能更加有效,因为你无法保证你自己的管理能够让你的类在任何地方都被识别。因此我们需要了解他的成本而不是摒弃。
条款二十五:将constructer和nonmember function虚化
1. 虚化构造函数
当看到将构造函数虚化时你可能想到C++语法不是只支持析构函数的虚化而不允许构造函数的虚化吗?其实这里说的是将构造函数虚化,不是构建虚构造函数。我们可以想象一个场景,我们开发了一个处理服务器的软件,内容为文字,图片,视频等我们将程序中这些数据的管理设计为下面的代码:
class data_object
{
public:
virtual void operate() = 0;
};
class text:public data_object
{
public:
virtual void operate();
}
class photo:public data_object
{
public:
virtual void operate();
};
class data_manager
{
private:
std::list<data_object*> _data_list;
}
而数据储存在服务器的磁盘上我们需要通过从磁盘上读取数据可能代码如下:
class data_manager
{
private:
std::list<data_object*> _data_list;
public:
data_manager(istream& str)
{
while(1)
{
//TODO:read data from disk and insert into list
}
}
};
如果我们将数据的读取交由一个函数去做,代码就会变成:
class data_manager
{
private:
std::list<data_object*> _data_list;
public:
static data_object* read_data(istream& str);
data_manager(istream& str)
{
while(1)
{
//TODO:read data from disk and insert into list
_data_list.push_back(read_data(str));
}
}
};
read_data函数的作用就是根据从磁盘输入的数据类型生成对应的类的类型,这就是一个虚构造函数尽管他不是虚函数但是完成了虚函数可以完成的功能。在这里构造函数将自己无法完成的功能外包出给成员函数,就如同现实生活中的外包公司一般完成一些额外的任务。
另一中虚构造函数就是虚拷贝构造函数,徐拷贝构造函数会返回一个自身的指针,指向自身的一个副本,代码如下:
class object
{
public:
virtual object* clone() const = 0;
}
class dialog:public object
{
public:
virtual dialog* clone() const
{
return new dialog(*this);
}
}
class widget:public object
{
public:
virtual widget* clone() const
{
return new widget(*this);
}
}
从代码中可以看到虚拷贝构造函数其实就是调用了一个拷贝构造函数而已,他的行为取决于类的拷贝构造函数,如果在环境中只是进行简单的浅拷贝,那么clone的行为会紧跟拷贝构造函数,如果需要深拷贝clone的行为亦然。也就是说保留这之前我们谈到过的缓时评估。
上述虚拷贝构造函数能够成功的原因是C++中允许继承类也就是子类重新定义基类也就是父类中的虚函数时使用与父类不同的返回值,但是返回值必须存在继承关系,如果两个虚函数的返回值一个是int另一个是void就会编译错误!
2. 虚化无成员函数(non-member function)
对于无成员函数的虚化可以让无成员函数也拥有多态的性质,但是如果仅仅是按照一般的函数设计就会出现一些不方便的地方比如,根据类的类型重载<<操作符:
class father
{
public:
virtual ostream& operator<<(ostream& os) const
{
os<<"father out!\n";
return os;
}
};
class son:public father
{
public:
virtual ostream& operator<<(ostream& os) const
{
os<<"son out!\n";
return os;
}
};
上述代码可以实现对应的功能但是调用方式就不是那么的方便了。必须按照以下方式调用:
father fh;
son s;
s<<cout;
fh<<sout;
这明显和我们习惯的调用方式有所差距。另一中简单的办法是将打印的功能封装为一个成员函数让这个操作符重载函数调用这个封装的函数比如
#include<iostream>
using namespace std;
class object
{
public:
virtual ostream& print(ostream& os) const = 0;
};
class dialog:public object
{
public:
virtual ostream& print(ostream& os) const
{
std::cout<<"dialog run!\n";
}
};
class widget:public object
{
public:
virtual ostream& print(ostream& os) const
{
std::cout<<"widget run!\n";
}
};
inline ostream& operator<<(ostream& os,const object& ob)
{
return ob.print(os);
}
int main(int arg,char* ar[])
{
dialog dlg;
widget w;
cout<<dlg;
cout<<w;
return 0;
}
代码中将打印工作封装再由重载操作调用完成更好的包装。
条款二十六:限制某个class所能产生的对象的数量
1.允许零个或者一个对象
每当产生一个对象最基本的步骤就是调用构造函数,因此阻止对象产生最简单的办法是将对象的构造函数声明为私有的,这时只有拥有特权的类或者函数才能创建这个对象。因此我们可以这样做:
class object
{
private:
object();
object(const object& _rst);
public:
friend object& create_object();
}
object& create_object()
{
static object p;
return p;
}
可能友元函数的做法会为因为函数的声明和实现是全局的而带来一定的麻烦。当然我们也可以不使用友元函数,使用类内部的静态函数创建类的对象。
class object
{
private:
object();
object(const object& _rst);
public:
static object& create_object();
}
object& object::create_object()
{
static object p;
return p;
}
另一种比较直观的做法就是使用命名空间将类和函数隔离起来。
这种做法有几个优点:
第一,所生成的对象是函数中的静态对象而不是类中的对象,这就意味着只有在你第一次调用相关函数时这个对象才会被创建,如果函数从未被调用就意味着这个对象不会产生,C++——你不应该为你不需要的东西付出任何的代价的哲学理念一致。
第二,对于如此简短的函数我们却没有使用inline。因为inline意味着这个函数内部有内部连接,这将可能导致目标代码的复制,包括函数中的静态变量,这可能就和你最初期望的有区别了。
第三,初始化时机,如果对应的对象是一个class static就意味着在不同编译单元中我们将无法保证静态类的初始化时机,这只能交由变一起执行。
另外,当然也可以不适用function static是用class static并为你的类增加几个限制,比如在类中增加一个对象计数器,构造函数中对技术器进行++,在析构器中–,并且确保这个计数器不会大于1,如果大于1就抛出异常。这是一种简单直观的做法。
2.不同的对象构造状态
上述的使用计数器的方法会产生一个问题,如果我们对我们构造的类进行了继承,这就意味着每个继承的类中有一个基类也就是这个类的拷贝,当我们创建子类的对象时就会出现无法创建多种子类的对象的问题。比如:
class dialog:public object{};
class widget:public object{};
dialog dlg;
widget w; //throw a exception
无法生成widget的类的对象,因为基类中限制了多个拷贝的存在,而子类中一定会存在一个父类的拷贝的。不仅仅是继承当我们使用嵌套类的时候这类问题同样会产生。解决这个问题的办法也很简单就是采用之前使用到的办法将构造函数声明为私有,这样除了拥有相关权限的函数或者类能够创建对象,其他都无能为力。但这并不意味着这个对象只能创建有限个对象。可以将对象的创建包装成静态函数就可以完成。
class object
{
private:
object();
object(const object&);
public:
static object* init();
static object* init(const object&);
}
object* object::init()
{
return new object(); //注意指针的删除问题
}
object* object::init(const object& _rst)
{
return new object(_rst);
}
3.允许对象生生灭灭
之前的代码存在一个很大缺陷,当我们希望使用一个唯一的对象时,这个对象贯穿于全局是同一个对象为无法做到,需要使用时创建一个对象,不需要时销毁该对象,再次需要时在创建的工作。相对而言解决办法也很简单就是将前面提到的两种解决办法综合起来使用。代码如下:
class object
{
private:
static size_t _object_count;
object();
object(const object& _rst);
public:
object* init();
object* init(const object* _rst);
}
size_t object::_object_count = 0;
object::object()
{
if(1 <= _object_count)
{
throw;
}
++_object_count;
}
object* object::init()
{
return new object();
}
当然我们不用局限于之间单个对象可以任意修改_object_count的数值来满足自己的需求。
4.一个用来计算对象个数的基类
当我们需要重复的完成上述代码的功能时这是一个很繁杂的任务为何不将你的代码封装为一个类。思想很简单就是将一个功能封装为一个类。代码如下:
#include <iostream>
template<class T>
class count_object
{
private:
static size_t _count;
static const size_t _max;
void init();
public:
class too_much_object{};
static size_t get_count();
protected:
count_object();
count_object(const count_object& _rst);
~count_object();
};
template<class T>
void count_object<T>::init()
{
if (_count >= _max)
{
throw too_much_object();
}
++_count;
}
template<class T>
count_object<T>::count_object()
{
init();
}
template<class T>
count_object<T>::~count_object()
{
_count--;
}
template<class T>
count_object<T>::count_object(const count_object& _rst)
{
init();
}
template<class T>
size_t count_object<T>::get_count()
{
return _count;
}
class object_user :private count_object < object_user >
{
public:
static object_user* create_ob();
static object_user* create_ob(const object_user& _rst);
int print();
using count_object<object_user>::get_count;
using count_object<object_user>::too_much_object;
~object_user();
protected:
private:
//using count_object<object_user>::_count;
object_user();
object_user(const object_user& _rst);
};
template<class T>
size_t count_object<T>::_count = 0;
const size_t count_object<object_user>::_max = 5;
object_user::~object_user()
{
std::cout << "对象销毁!\n";
}
object_user* object_user::create_ob()
{
return new object_user;
}
object_user* object_user::create_ob(const object_user& _rst)
{
return new object_user(_rst);
}
object_user::object_user()
{
std::cout << "object create!\n";
}
object_user::object_user(const object_user& _rst)
{
std::cout << "object create!\n";
}
int object_user::print()
{
std::cout << count_object<object_user>::get_count() << std::endl;
return 0;
}
int main()
{
try
{
object_user* ptr1 = object_user::create_ob();
object_user* ptr2 = object_user::create_ob();
object_user* ptr3 = object_user::create_ob();
object_user* ptr4 = object_user::create_ob();
object_user* ptr5 = object_user::create_ob();
object_user* ptr6 = object_user::create_ob(); //throw
ptr1->print();
}
catch (count_object<object_user>::too_much_object& rm)
{
std::cout << "too much objects!\n";
}
system("pause");
return 0;
}
按照书中所说可以使用using来改变基类中的权限,但是事实上无法改变基类中私有成员的权限,基类中的私有成员不可被访问。
条款二十七 要求或者禁止对象产生于heap中
有时我们希望程序中所用到的所有对象都分配在heap中,以至于我们很明确所有对象都在内存中,因此要对所有对象进行内存的回收,就不用担心考虑那个需要哪个不需要了。反之,限定对象产生于栈中,拥有自己的内存管理可能是我们另一种夙求。
一、要求对象产生于heap中
要求对象只能产生于heap中意味着需要一种方法必须用new来产生对象,可以将构造函数和析构函数都声明为private,但就无法创建对象;所以只将析构函数声明为private,将构造函数声明为public更好,比如:
class person
{
private:
int num;
int age;
public:
person()
{
std::cout<<"constructer is runing"<<std::endl;
}
person(int num, int age)
{
this->num = num;
this->age = age;
}
void destroy()
{
delete this;
}
private:
~person()
{
std::cout<<"destructer is runing"<<std::endl;
}
};
  只需在使用对象之后显式的调用destroy方法就可以销毁,否则无法销毁。
person* p = new person;
p->destroy();
//delete p; //error
书上提到可以将构造函数声明为private。
二、判断某个对象是否位于heap中
假如我们为person创建一个子类,直接继承自person(需要将person析构函数的权限改为protected)如
class man:public person{};
这种情况下使用man m构造一个栈上的对象是不会出现问题的(书上是这么说的,但我个人认为应该对所有类一视同仁,即对man的析构函数进行私有化,但是作者没有)
可能的一种解决方案是为对象设立一个标志位,拦截operate new方法,如果对象创建在栈上就抛出异常。
class man:public person
{
public:
class heapAllocateException{};
static void* operator new(size_t size);
man();
private:
static bool isHeap; //堆内的标志位
};
bool man::isHeap = false;
void * man::operator new(size_t size)
{
isHeap = true;
return ::operator new(size);
}
man::man()
{
if(!isHeap)
{
throw heapAllocateException();
}
isHeap = false;
}
这样就可以解决单个对象的内存分配问题,但是另一种情况可不是这样运作比如man *p = new man[10]这种情况下内存的分配是一次性的,只会在第一个对象的创建时进行检查,即便你想使用operate new[]也无法解决。
还有另一种情况,new man(*new man)代码本身就是错误的,会产生内存泄漏,但是只是为了说明一些问题,我们期待的编译器运行顺序是
- 为第一个对象调用operator new
- 为第一个对象调用constructor
- 为第二个对象调用operator new
- 为第二个对象调用constructor
但是一般编译器都会进行优化,对应的执行顺序就变成了 - 为第一个对象调用operator new
- 为第二个对象调用operator new
- 为第一个对象调用constructor
- 为第二个对象调用constructor
当然,也可以利用系统内栈和堆的增长方式来进行判断生成的对象位于何处。有些系统的栈是从高地址向低地址长,堆从低地址向高地址生长,有些系统反之,但对单一的系统总是固定的。所以产生的一种认为是:
bool onHeap(const void * ptr)
{
char onStack;
return ptr < & onStack;
}
因为onStack是局部变量所以一定在栈中所以它的地址相对于堆的地址一定大(仅对一种系统有用)。但是这个方法有个缺陷,对象不仅仅存在于heap和stack中也可以被声明为static,而static对象不在栈中也不再堆中。这就可能造成一定的错误。
然而,我们探究对象是否在堆中的最终目的是判断删除对象是否安全,如果一味的纠结于前者似乎有些本末倒置。事实上,“判断指针删除"是否安全要易于"判断指针是否指向堆”。因此可以尝试:
void* operator new()
{
//TODO: 为对象分配内存
// 将地址添加到集合中
// 返回地址
}
void operator delete(void *ptr)
{
//TODO: 释放内存
// 将地址从集合中删除
}
bool isSafeToDelete(const void* ptr)
{
//TODO: 删除的地址是否在对应的集合中
}
这样做可以很有效(只是完成任务)的解决这个问题,但是又有一个问题,为每个类维护一个地址的映射是否过于小题大做,对效率来说代价是否太高?答案是,Yes。最直接的管理方法是为每一个类声明一个共同的祖父——一个抽象类,把管理内存集合的累活权交给他来做。
class heapTrack
{
public:
class MissingExecption{};
virtual ~heapTrack() = 0;
static void* operator new(size_t size);
static void operator delete(void* ptr);
bool isHeap()const;
private:
typedef const void* ArrayAddress;
static std::list<ArrayAddress> address;
};
//std::list<ArrayAddress> heapTrack::address;
heapTrack::~heapTrack(){}
void* heapTrack::operator new(size_t size)
{
void* ptr = ::operator new(size);
address.push_front(ptr);
return ptr;
}
void heapTrack::operator delete(void* ptr)
{
std::list<ArrayAddress>::iterator it = std::find(address.begin(), address.end(), ptr);
if(it != address.end())
{
address.erase(it);
::operator delete(ptr);
}
else
{
throw MissingExecption();
}
}
bool heapTrack::isHeap()const
{
const void* ptr = dynamic_cast<const void*>(this);
std::list<ArrayAddress>::iterator it = std::find(address.begin(), address.end(), ptr);
return it != address.end();
}
三、禁止对象产生于heap中
禁止对象产生于heap相对于以上问题要简单的多,可以将’operator new’声明为private。
class ob
{
private:
void* operator new();
void operator delete(void* ptr);
}
条款二十八: 智能指针
智能指针是一类拥有自动资源管理的指针,我们使用智能指针会获得各种指针的控制权:
- 构造和析构(Construction and Destruction) 我们可以指定智能指针在构建和析构对象时做什么,也可以保证对象内存的安全回收。
- 复制和赋值(Copying and Assignment) 当使用智能指针进行复制和赋值时我们可以控制,有时我们希望进行深拷贝有时希望进行浅拷贝。
- 解引(Dereferencing) 当使用智能指针所指的对象时,我们有权决定如何做。
通常智能指针和我们用到的普通指针很相似,只是进行了一些功能上的封装让我们使用指针更加安全,更加方便。
一、智能指针的构造、赋值和析构
智能指针中比较烦人的一种和我们在构造一个对象时遇到的一样,深拷贝和浅拷贝的问题。C++中提供的auto_ptr
template 可以完成自动回收对象的内存的任务。他可能实现代码是:
template<class T>
class auto_ptr
{
public:
auto_ptr(T* ptr = 0):pointee(ptr){}
~auto_ptr(){delete this->pointee;}
//TODO:..
private:
T* pointee;
};
仅仅对一个对象进行操作似乎很是简单,但是如果对两个指针进行相互赋值会发生什么:
auto_ptr<TreeNode> ptr_rst(new TreeNode);
auto_ptr<TreeNode> ptr_snd = ptr_rst;
这就出现一个问题就如深浅拷贝的问题一样。STL中auto_ptr的做法是当auto_ptr被复制或者赋值时进行“对象拥有权”的转移。
template<class T>
class auto_ptr
{
private:
T* piontee;
public:
auto_ptr(auto_ptr<T>& _rst);
auto_ptr<T>& operator=(auto_ptr<T>& _rst);
//TODO:...
};
template<T>
auto_ptr<T>::auto_ptr(auto_ptr<T>& _rst)
{
this->piontee = rst.pointee; //将_rst中的内存接管
_rst.piontee = 0;
}
template<T>
auto_ptr<T> auto_ptr<T>::operator=(auto_ptr<T>& _rst)
{
if(this == &_rst)
return *this;
delete pointee;
pointee = _rst.pointee;
rst.pointee = 0;
return *this;
}
从上面的代码中可以看到,auto_ptr采用了对象接管的方式,但是这会产生一个问题,当一个auto_ptr作为函数的参数时,就会发生值的拷贝,对象转移到函数内部的局部变量中,而当函数结束时,对象就会被自动销毁,我们之前所拥有的变量变成空壳。因此此种情况使用const的引用进行参数传递是不错的选择。
二、实现Dereferencing Operators(解引操作符)
实现指针的解引很简单就是对*进行重载即可,需要注意的是在返回值中使用引用是一种安全的方式。,如果使用其它方式可能会涉及虚函数,对象的切割等不必要的问题。
三、测试智能指针是否为NULL
通常情况下我们判断一个指针是否为空无非三种操作:
if(ptr)
if(!ptr)
if(ptr == NULL)
但是在智能指针中部可以这样使用,因此智能指针提供了一种隐式类型转换的方式可以放多种指针进行比较重载void*
template<class T>
class SmartPtr
{
public:
operator void*();
}
现在可以使用上面三种方式进行指针的判断,但是这种情况又出现一个相对严重的问题,任意两个指针都可以进行比较,这貌似有点过了。还有一种方式是对!进行重载这样避免了一些问题但是仍存在一些小的风险,但相对于上一种做法要好点。
四、将智能指针转换为转储文件指针
在代码中我们经常需要使用一个指针作为函数参数,但是智能指针不支持这样的操作,我们可以使用(&*ptr)来完成相关的转换,但貌似并不是直面问题所在。我们可以为智能指针提供一个隐式类型转换,这样不但解决了这个问题也解决之之前说道的NULL判断问题。但是想想我们使用智能指针的目的是什么,现如今我们却要退回去。
另外,为智能指针提供一个隐式类型转换可能是的我们本来打算避免的问题全部浮现。比如delete ptr假如ptr是一个智能指针,本来这样做非法,但是现在因为有隐式类型转换,这样做编译器不会认为有错,对象就会被删除两次。因此尽量不要为智能指针提供隐式类型转换。
五、智能指针和“与继承有关的”类型转换
假设有如下代码
class product
{
public:
product(const std::string& title);
virtual void play()const = 0;
virtual void displayTitle()const = 0;
};
class paino:public product
{
public:
paino(const std::string& title);
virtual void play()const;
virtual void displayTitle()const;
};
class bam:public product
{
public:
bam(const std::string& title);
virtual void play()const;
virtual void displayTitle()const;
};
void display(const product* ptr, int num)
{
for(int i = 0; i < num; i ++)
{
ptr->displayTitle();
ptr->play();
}
}
//TODO in main
paino *ptr = new paino("Paino");
bam *p = new bam("Bam");
display(ptr, 2);
display(p, 2);
如果使用智能指针上面的代码编译器就会报错:
void display(const SmartPtr<product>&p, int num);
SmartPtr<paino> ptr(new paino("Paino"));
SmartPtr<bam> p(new bam("Bam"));
display(ptr, 3);
display(p, 3);
这里可以使用隐式类型转换解决这个问题,但是这样做有两个问题:第一,你必须为特定的类添加特定的转换函数,这对于template来说很可笑;第二,我们实际用到的类的继承关系可不止这麽简单。C++提供了一种方式。
template<class T>
class SmartPtr
{
private:
T* pointee;
public:
SmartPtr(T* realPtr = 0);
T* operator->()const;
T& operator*()const;
template<class newType>
operator SmartPtr<newType>()
{
return SmartPtr<newType>(pointee);
}
};
这样做我们之前的代码就可以顺利运行,但是这样做的缺点是这种方法只提供在某些C++扩展中并不是所有的都支持,当然还有其他模板内的问题,因此移植性不太好。
总结一下,智能指针虽很智能但是他始终和指针不同,因此不能和指针相提并论。
六、智能指针和const
通常我们使用指针有三种书写形式
const int* p;
const int*const p;
int* const p;
智能指针也可以只是稍微麻烦一点点
int* p;
const SmartPtr<int> ptr = p;
const SmartPtr<const int> ptr = p;
SmartPtr<const int> ptr = p;
这样做会有一些限制,智能从non-const转换至const反之无效。对const能做的任何事对non_const也成立,反之不可以。
条款二十九: Reference counting(引用计数)
引用计数的使用有两个目的:第一个是简化内存管理,当然这并不简单,特别是类似于智能指针中指针的对象传递问题;第二个是节省内存,加快程序运行,毕竟对同一变量进行多次的存储是很愚蠢的行为。假定有一个字符串类:
class String
{
public:
String(const char* value = "");
String& operator=(const String& rst);
//TODO:
private:
char* data;
}
进行如下操作:
String a,b,c,d;
a = b = c = d = "Hello World";
为了实现每一个对象都有一份自己的数据可能是这样的:
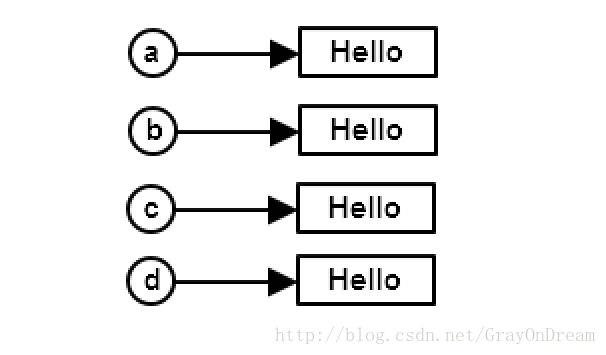
另一种情况,为了节省内存,可能是这样的:
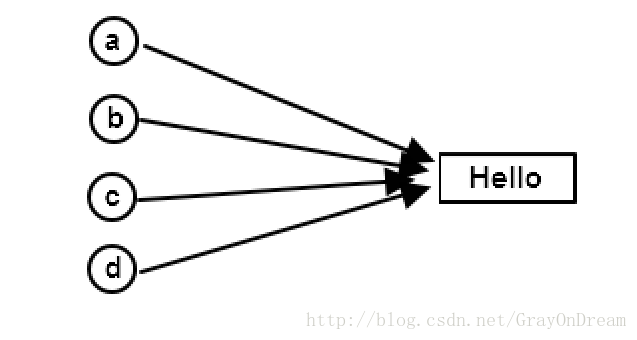
但是这样又存在一个严重的问题,任何一个对象对这个资源都没有控制权,如果有其他的对象所拥有的资源就会发生改变,造成一系列的问题。引用计数的解决方案有点类似于操作系统中的软连接技术,为这个资源增加引用计数,只有数值为0才真正删除资源,若需要修改怎生成拷贝再修改。
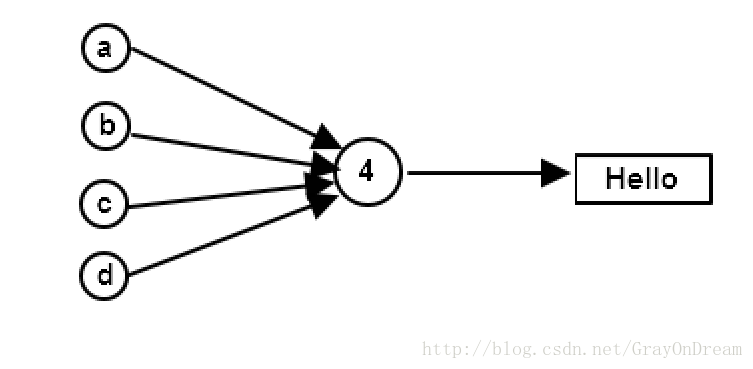
一、Reference Counting(引用计数)的实现
我们所需要的能够记录当前拥有同样资源的对象的数目和资源本身,因此必须独立于对象,所以有两中方法:第一种,静态变量和静态方法,这的确了实现了独立于对象但是自我资源的管理方面又很差;另一种是嵌套结构,在类中声明一个嵌套类,将嵌套类的方法和数据全部声明为private,禁止非友元类的访问,当然可以使用struct结构体(默认为私有)。
class String
{
private:
struct StringValue
{
int referenceCount;
char* data;
StringValue(const char* initValue);
~StringValue();
};
StringValue *value;
public:
String(const char* initValue = "");
String(const String& rst);
String& operator=(const String& rst);
~String();
//TODO:
private:
char* data;
};
String::String(const char* initValue):value(new StringValue(initValue))
{}
String::String(const String& rst)
{
++value->referenceCount;
}
String::StringValue::StringValue(const char* initValue):referenceCount(1)
{
data = new char[strlen(initValue) + 1];
strcpy(data, initValue);
}
String::StringValue::~StringValue()
{
delete[] data;
}
String::String(const char* initValue = ""):value(new StringValue(initValue))
{}
String::~String()
{
if(--value->referenceCount == 0)
{
delete value;
}
}
String& String::operator=(const String& rst)
{
if(value == rst.value)
{
return *this;
}
if(--value->referenceCount == 0)
{
delete value;
}
value = rst.value;
++value->referenceCount;
return *this;
}
上面的类无论是执行赋值,拷贝和删除等操作都尽可能的将同一资源的个数现在在一个以内,而且解决了资源共享的问题。
二、Copy-on-Write(写时才复制)
上述代码还存在一个问题就是如果某一对象对资源的某个值进行修改,我们不能修改资源本身因为其他对象也在使用,这里采用当读取资源一部分的数据时直接将数据拷贝为对象生成独有的一份,因为我们无法知道对象使用资源去干什么了。这里有点类似于高速缓存的写出算法。
String& String::operator=(const String& rst)
{
if(value == rst.value)
{
return *this;
}
if(--value->referenceCount == 0)
{
delete value;
}
value = rst.value;
++value->referenceCount;
return *this;
}
const char& String::operator[](int index)const
{
return value->data[index];
}
char& String::operator[](int index)
{
if(value->referenceCount > 1)
{
--value->referenceCount;
value = new StringValue(value->data);
}
return value->data[index];
}
三、Pointers,References以及Copy-On-Write
即便上述代码解决了很多问题但是对于下面的问题也很棘手。
String s1 = "Hello";
char* p = &s1[2];
我们无法得知程序中是否有一个指针指向地应的资源,更不可能知道该指针是否修改了资源,这就造成一些列问题。有一种办法是设置一个标志位来表明资源是否可以共享,一旦标志位被置为不再共享则每个对象就拥有自己单独资源,简单粗暴。当然,也可以用代理类将读写分开在后面会阐述。
四、一个Reference-Counting(引用计数)基类
引用计数可用于很多场合不仅仅是字符串类,但是我们每次实现都要重写一个类相对来说有点过于繁杂,下面有一个办法可以将引用计数和外界资源之间联系起来。可以定义一个类,这个类具有引用计数的能力,能够追踪资源是否可共享,以及资源的销毁等能力。
class ReferObject
{
public:
ReferObject();
ReferObject(const ReferObject& rst);
ReferObject& operator=(const ReferObject& rst);
virtual ~ReferObject() = 0;
void addReference();
void removeReference();
void markUnShareble();
bool isSharable() const;
bool isShared()const;
private:
int referenceCount;
bool shareable;
};
ReferObject::ReferObject():referenceCount(0),shareable(true){}
ReferObject::ReferObject(const ReferObject&):referenceCount(0),shareable(true){}
ReferObject& ReferObject::operator=(const ReferObject&)
{
return *this;
}
ReferObject::~ReferObject(){}
void ReferObject::addReference()
{
++this->referenceCount;
}
void ReferObject::removeReference()
{
if(--referenceCount == 0)
{
delete this;
}
}
void ReferObject::markUnShareble()
{
shareable = false;
}
bool ReferObject::isSharable()const
{
return shareable;
}
bool ReferObject::isShared()const
{
return referenceCount > 1;
}
因此当使用上述类时只需将对应对象中的引用计数的嵌套类继承自上述类,对应String终究是StringValue应该继承自ReferObject,只需将对应资源的指针进行修改即可。
class String
{
private:
struct StringValue:public ReferObject
{
char* data;
StringValue(const char* initValue);
~StringValue();
};
StringValue *value;
public:
String(const char* initValue = "");
String(const String& rst);
String& operator=(const String& rst);
~String();
//TODO:
private:
char* data;
};
五、自动操作引用次数(Reference Count)
ReferObject为我们提供了一些成员函数进行对象的引用计数和资源的管理但是当涉及到具体的类时,还需要我们自己负责指针和资源的管理。我们可以使用上一个条款提到的智能指针来处理这些问题。
template<class T>
class ReferPtr
{
public:
ReferPtr(T* realPte = 0);
ReferPtr(const ReferPtr& rst);
~ReferPtr();
ReferPtr& operator=(const ReferPtr& rst);
T* operator->()const;
T* operator*()const;
private:
T* pointee;
void init();
};
template<class T>
ReferPtr<T>::ReferPtr(T* realPtr):pointee(realPtr)
{
init();
}
template<class T>
ReferPtr<T>::ReferPtr(const ReferPtr& rst):pointee(rst->pointee)
{
init();
}
template<class T>
void ReferPtr<T>::init()
{
if(pointee == 0)
{
return;
}
if(pointee->isSharable() == false)
{
pointee = new T(*pointee);
}
pointee->addReference();
}
template<class T>
ReferPtr<T> ReferPtr<T>::operator=(const ReferPtr& rst)
{
if(pointee != rst.pointee)
{
if(pointee)
{
pointee->removeReference();
}
pointee = rst.pointee;
init();
}
return *this;
}
template<class T>
ReferPtr<T>::~ReferPtr()
{
if(pointee)
{
pointee->removeReference();
}
}
从代码中可以看出要让上述代码中的智能指针正确T必须继承自ReferObject或者拥有ReferObject的功能。
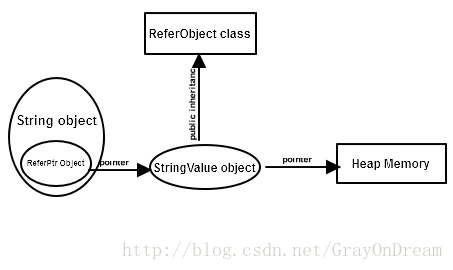
六、把所有努力放在一起
上面说了很多解决哪方面问题的方法,现在是时候把他们组装起来。下面是结构图:
#include <iostream>
#include <string.h>
using namespace std;
//smart point
template<class T>
class ReferPtr
{
public:
ReferPtr(T* realPte = 0);
ReferPtr(const ReferPtr& rst);
~ReferPtr();
ReferPtr& operator=(const ReferPtr& rst);
T* operator->()const;
T* operator*()const;
private:
T* pointee;
void init();
};
class ReferObject
{
public:
ReferObject();
ReferObject(const ReferObject& rst);
ReferObject& operator=(const ReferObject& rst);
virtual ~ReferObject() = 0;
void addReference();
void removeReference();
void markUnShareble();
bool isSharable() const;
bool isShared()const;
private:
int referenceCount;
bool shareable;
};
class String
{
private:
struct StringValue
{
int referenceCount;
char* data;
StringValue(const char* initValue);
~StringValue();
};
StringValue *value;
public:
String(const char* initValue = "");
String(const String& rst);
String& operator=(const String& rst);
const char& operator[](int index)const;
char& operator[](int index);
~String();
//TODO:
private:
char* data;
};
String::String(const char* initValue):value(new StringValue(initValue))
{}
String::String(const String& rst)
{
++value->referenceCount;
}
/StringValue
String::StringValue::StringValue(const char* initValue):referenceCount(1)
{
data = new char[strlen(initValue) + 1];
strcpy(data, initValue);
}
String::StringValue::~StringValue()
{
delete[] data;
}
String::String(const char* initValue = ""):value(new StringValue(initValue))
{}
String::~String()
{
if(--value->referenceCount == 0)
{
delete value;
}
}
String& String::operator=(const String& rst)
{
if(value == rst.value)
{
return *this;
}
if(--value->referenceCount == 0)
{
delete value;
}
value = rst.value;
++value->referenceCount;
return *this;
}
const char& String::operator[](int index)const
{
return value->data[index];
}
char& String::operator[](int index)
{
if(value->referenceCount > 1)
{
--value->referenceCount;
value = new StringValue(value->data);
}
return value->data[index];
}
/ReferObject
ReferObject::ReferObject():referenceCount(0),shareable(true){}
ReferObject::ReferObject(const ReferObject&):referenceCount(0),shareable(true){}
ReferObject& ReferObject::operator=(const ReferObject&)
{
return *this;
}
ReferObject::~ReferObject(){}
void ReferObject::addReference()
{
++this->referenceCount;
}
void ReferObject::removeReference()
{
if(--referenceCount == 0)
{
delete this;
}
}
void ReferObject::markUnShareble()
{
shareable = false;
}
bool ReferObject::isSharable()const
{
return shareable;
}
bool ReferObject::isShared()const
{
return referenceCount > 1;
}
/ReferObject
/ReferPtr
template<class T>
ReferPtr<T>::ReferPtr(T* realPtr):pointee(realPtr)
{
init();
}
template<class T>
ReferPtr<T>::ReferPtr(const ReferPtr& rst):pointee(rst->pointee)
{
init();
}
template<class T>
void ReferPtr<T>::init()
{
if(pointee == 0)
{
return;
}
if(pointee->isSharable() == false)
{
pointee = new T(*pointee);
}
pointee->addReference();
}
template<class T>
ReferPtr<T> ReferPtr<T>::operator=(const ReferPtr& rst)
{
if(pointee != rst.pointee)
{
if(pointee)
{
pointee->removeReference();
}
pointee = rst.pointee;
init();
}
return *this;
}
template<class T>
ReferPtr<T>::~ReferPtr()
{
if(pointee)
{
pointee->removeReference();
}
}
/ReferPtr
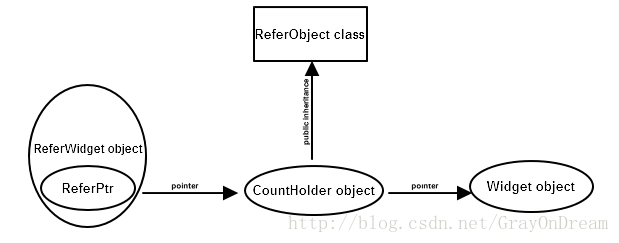
七 、将Reference Counting加到既有的Classes上
上述代码智能对我们自定义的类进行加工,但是对于程序库提供的却无能为力。 假如有一个weight类,我们期待引用计数的功能添加到踏上去,我们可以利用一个间接的类来做这件事。
class ReferObject
{
public:
ReferObject();
ReferObject(const ReferObject& rst);
ReferObject& operator=(const ReferObject& rst);
virtual ~ReferObject() = 0;
void addReference();
void removeReference();
void markUnShareble();
bool isSharable() const;
bool isShared()const;
private:
int referenceCount;
bool shareable;
};
template<T>
class ReferPtr
{
public:
ReferPtr(T* realPtr = 0);
ReferPtr(const ReferPtr& rst);
~ReferPtr();
ReferPtr& operator=(const ReferPtr& rst);
const T* operator->()const;
T* operator->();
const T& operator*()const;
T& operator*();
private:
struct CountHolder:public ReferObject
{
~CountHolder(){delete pointee};
T* pointee;
}
CountHolder* counter;
void init();
void makecopy();
}
template<class T>
void ReferPtr<T>::init()
{
if(counter->isSharable() == false)
{
T* oldValue = counter->pointee;
counter = new CountHolder;
counter->pointee = new T(*oldValue);
}
counter->addReference();
}
template<class T>
ReferPtr<T>::ReferPtr(T* realPtr):counter(new CountHolder)
{
counter->pointee = realPtr;
init();
}
template<class T>
ReferPtr<T>::ReferPtr(const ReferPtr& rst):counter(rst.counter)
{
init();
}
template<class T>
ReferPtr<T>::~ReferPtr()
{
counter->removeReference();
}
template<class T>
ReferPtr& ReferPtr<T>::operator=(const ReferPtr& rst)
{
if(counter != rst.counter)
{
counter->removeReference();
counter = rst.counter;
init();
}
return *this;
}
template<class T>
const T* ReferPtr<T>::operator->()const
{
return counter->pointee;
}
template<class T>
const T& ReferPtr<T>::operator*()const
{
return *(counter->pointee);
}
class Widget
{
public:
Widget(int size);
Widget(const Widget& rst);
~Widget();
Widget& operator=(const Widget& rst);
void doThis();
int show()const;
}
class ReferWidget
{
public:
ReferWidget(int size):value(new Widget(size)){}
void doThis(){value->doThis();}
int show()const{return value->show();}
private:
ReferPtr<Widget> value;
}
八、总结
引用计数的目的是为了节省资源,提高代码效率,但并不是所有情况下都可以使用引用计数,一般可以使用引用计数的请款有:
相对较多的对象共享较多的资源;
对象的资源生成成本比较高或者占用内存多;
引用计数只是一种优化代码的技术,并不是一种规范,因此使用时尽量以情况而定慎重考虑。
条款三十: Proxy classes(替身类、代理类)
在C++中不允许使用non-const构建数组意思是下面这段代码非法:
int data = 10;
int array[data];
int array2[data][data];
我们可以自己动手实现一个二维数组,允许他使用non-const变量进行初始化。
一、实现二维数组
我们可以根据数组的原理进行构建,一维数组为多个相同数据的集合,二维数组为多个相同的一维数组的集合,三维数组为多个相同的二维数组的集合。因此可以这样定义:
template<class T>
class Array2D
{
public:
class Array
{
public:
T& operator[](int index);
constT& operator[](int index)const;
}
Array operator[](int index);
const Array operator[](int index)const;
}
你可能想利用一个类解决并为其提供一个成员函数可以取出对应的值,但是这样有个问题就是我们无法私用传统的数组操作:
class array
{
public:
array(int _rst, int _snd);
get_data(int _rst, int _snd);
}
和之前的嵌套类相比较可以使用传统的数组操作不是更好吗!上述Array象征一维数组,Array2D象征二维数组但是Array对于使用Array2D的用户来说并不需要有概念,因此它是用来代替观念上的并不存在的一维数组被称为Proxy Classes。
二、区分operator[ ]的读写操作
对于一个数组,我们肯定需要读取和修改数据,问题是二者对于数组来说操作相同都是operator[ ],对于读操作我们只希望一个右值,二写操作希望拥有一个左值。区分左右值的原因是读取比写如要快得多,读取只需简单的返回一个值,而写入可能需要对数据进行拷贝。但是我们无法知道使用operator[ ]时到底期望左值引用还是右值引用。
我们可以使用之前提到的缓式评估,当知道是否对对象进行操作时再进行相关的处理。
在处理相关事宜之前我们夏利哦啊对于proxy所做的三件事:
-
产生它,例子中指的是它代表字符串中哪一个字符;
-
以它作为赋值动作的目标
-
以其他方式使用
下面是String的引用计数版本,利用proxy来区分左右值:class String { public: class CharProxy { public: CharProxy(String& str, int index); //左值引用 CharProxy& operator=(const CharProxy& rst); CharProxy& operator=(char ch); //右值引用 operator char() const; char* operator&(); const char* operator()const; private: String& theString; int charIndex; }; const CharProxy operator[](int index)const; CharProxy operator[](int index); friend class CharProxy; private: ReferPtr<StringValue> value; }; const String::CharProxy String::operator[](int index)const { return CharProxy(const_cast<String>(*this), index); } String::CharProxy String::operator[](int index) { return CharProxy(*this, index); } String::CharProxy::operator char()const { return theString.value->data[charIndex]; } String::CharProxy& String::CharProxy::operator=(const CharProxy& rst) { if(theString.value->isShared()) { theString.value = new StringValue(theString.value->data); } theString.value->data[theIndex] = rst.theString.value->data[rst.charIndex]; return *this; } String::CharProxy& String::CharProxy::operator=(char ch) { if(theString.value->isShared()) { theString.value = new StringValue(theString.value->data); } theString.value->data[charIndex] = ch; return *this; } const char* String::CharProxy::operator&()const { return &(theString.value->data[charIndex]); } char* String::CharProxy::operator&() { if(theString.value->isShared()) { theString.value = new StringValue(theString.value->data); } theString.value->markUnsharable(); return &(theString.value->data[charIndex]); }上述代码仍有缺陷,因为它是一个代理并不是真正的对象所以无法和真正的对象一样做一些具体的事情,同时还会产生之前条款说明的一些临时对象的问题,因此使用时需要多加考虑。
条款三十一:让函数根据一个以上的对象类型来决定如何虚化
假设我们决定写一个视频游戏软件,场景中涉及到太空飞船,太空站,小行星等。在空间中可能发生下面四种碰撞结果:
- 太空飞船以低速碰撞太空站,则安全泊入,否则二者所受损害和太空飞船的速度成正比;
- 太空飞船和太空飞船或者太空站和太空站碰撞,则二者所受损害和自己的的速度成正比;
- 小号的行星和太空飞船或者太空站碰撞,小行星损毁,如果是大号的小行星则太空飞船和太空站损毁;
- 小行星和小行星碰撞,则分裂成更小的行星散开。
因为三者都有共同的属性,我们可以为他们构建一个共同的抽象基类。
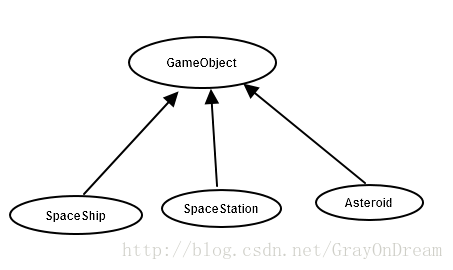
class GameObject{};
class SpaceStation:public GameObject{};
class SpaceShip:public GameObject{};
class Asteroid:public GameObject{};
我们可能建立的碰撞处理函数:
void checkCollision(GameObject& ob1, GameObject& ob2)
{
if(theyJustCollision(ob1, ob2))
{
processCollision(ob1, ob2);
}
else
{
//TODO:...
}
}
但是上面的第吗无法ob1和ob2具体的类型只知道他们是GameObject。因此我们可以使用其他方式实现。
一、虚函数+RTTI(运行时类型识别)
我们可以为GameObject提供一个虚函数,供不同的派生类处理碰撞事件,最一般的处理方法是通过嵌套的if-then处理:
class GameObject
{
public:
virtual void collision(GameObject& otherOb) = 0;
};
class SpaceShip:public GameObject
{
public:
virtual void collision(GameObject& otherOb);
}
class CollisionWithUnknownObject //当和未知物体碰撞抛出异常
{
public:
CollisionWithUnknownObject(GameObject& otherOb);
};
void SpaceShip::collision(GameObject& otherOb)
{
const type_info& obType = typeid(otherOb);
if(obType == typeid(SpaceShip))
{
SpaceShip& ptr = static_cast<SpaceShip&>(otherOb);
//Process the collision
}
if(obType == typeid(SpaceStation))
{
SpaceStation& ptr = static_cast<SpaceStation&>(otherOb);
//Process the collision
}
if(obType == typeid(Asteroid))
{
Asteroid& ptr = static_cast<Asteroid&>(otherOb);
//Process the collision
}
throw CollisionWithUnknownObject(otherOb);
}
这种处理方式有一种C语言过程设计的味道,并不像C++面向对象的风格,而且需要我们考虑到所有的情况,这对于维护来说并不友好。
二、只使用虚函数
可以使用下面的方法解决上述问题:
class SpaceShip;
class SpaceStation;
class Asteroid;
class GameObject
{
public:
virtual void collide(GameObject& otherOb) = 0;
virtual void collide(SpaceShip& otherOb) = 0;
virtual void collide(SpaceStation& otherOb) = 0;
virtual void collide(Asteroid& otherOb) = 0;
};
class SpaceShip:public GameObject
{
public:
virtual void collide(GameObject& otherOb);
virtual void collide(SpaceShip& otherOb);
virtual void collide(SpaceStation& otherOb);
virtual void collide(Asteroid& otherOb);
};
void SpaceShip::collide(GameObject& otherOb)
{
otherOb.collide(*this);
}
上述代码相对来说很简单,尽管他能解决我们遇到的问题,但是当你的设计中需要添加其他对象时,你就必须修改原来的类来适应新的情况,这对于一个工程来说很糟糕,因此使用时尽量保证你的设计的对象基本不会修改。
三、自行仿真虚函数表格(Virtual Function Tables)
在之前的章节我们说过类中的虚函数表,这里我们可以利用虚函数表的原理为我们的碰撞处理函数建立一个表,通过查找表来实现相应的功能。
class GameObject
{
public:
virtual void collide(GameObject& otherOb) = 0;
//TODO:
}
class SpaceShip:public GameObject
{
public:
virtual void collide(GameObject& otherOb);
virtual void hitSpaceStation(SpaceStation& otherOb);
virtual void hitSpaceShip(SpaceShip& otherOb);
virtual void hitAsteroid(Asteroid& otherOb);
//TODO:
private:
typedef void(SpaceShip::*HitFunctionPtr)(GameObject&);
typedef std::map<string, HitFunctionPtr> hitMap;
static HitFunctionPtr lookup(const GameObject& whatWeHit);
};
void SpaceShip::collide(GameObject& otherOb)
{
HitFunctionPtr ptr = lookup(otherOb);
if(ptr)
{
(this->*ptr)(otherOb);
}
else
{
throw CollisionWithUnknownObject(otherOb);
}
}
SpaceShip::HitFunctionPtr SpaceShip::lookup(const GameObject& whatWeHit)
{
static HitMap collideMap;
HitMap::iterator mapIt = collideMap.find(typeid(whatWeHit).name());
if(mapIt == collideMap.end())
{
return 0;
}
return (*mapIt).second;
}
上述代码通过collide筛选需要执行的方法通过lookup函数在map映射中寻找我们需要用到的方法进行处理,上述代码并不是最终版本因为map并未进行初始化,只是描述了如何使用。
四、将自行仿真的虚函数表初始化
进行初始化时我们不能直接给map添加值,因为map中的值和函数最终期望的导致虽然是同一个基类的派生,但是始终不是同一个类,因此可能引发错误。,因此通过改变函数参数,再将指针进行转换即可。
class GameObject
{
public:
virtual void collide(GameObject& otherOb) = 0;
};
class SpaceShip:public GameObject
{
private:
static HitMap* initializeCollisionMap();
public:
virtual void collide(GameObject& otherOb);
virtual void hitSpaceShip(GameObject& otherOb);
virtual void hitSpaceStation(GameObject& otherOb);
virtual void hitAsteroid(GameObject& otherOb);
};
SpaceShip::HitMap* SpaceShip::initializeCollisionMap()
{
HitMap* ptr = new HitMap;
(*ptr)["SpaceShip"] = &hitSpaceShip;
(*ptr)["SpaceStation"] = &hitSpaceStation;
(*ptr)["Asteroid"] = &hitAsteroid;
return ptr;
}
void SpaceShip::hitSpaceShip(GameObject& otherOb)
{
SpaceShip& ptr = dynamic_cast<SpaceShip&>(otherOb);
//TODO:
}
void SpaceShip::hitSpaceStation(GameObject& otherOb)
{
SpaceStation& ptr = dynamic_cast<SpaceStation&>(otherOb);
//TODO:
}
void SpaceShip::hitAsteroid(GameObject& otherOb)
{
Asteroid& ptr = dynamic_cast<Asteroid&>(otherOb);
//TODO:
}
五、使用分成员函数的碰撞处理函数
前面提到了如果新增类就必须修改代码的问题,上述代码似乎没有解决这个问题,当然我们并不希望只因对象的增加就修改代码类主体。如果使用分成员函数处理就可以解决这个问题还可以解决之前我们忽略的问题——该由谁来处理碰撞事件。
#include "SpaceShip.h"
#include "SpaceStation.h"
#include "SpaceAsteroid.h"
namespace
{
void shipAsteroid(GameObject& spaceShip, GameObject& asteroid);
void shipStation(GameObject& spaceShip, GameObject& spaceStation);
void asteroidStation(GameObject& asteroid, GameObject& spaceStation);
//为了实现对称性
void asteroidShip(GameObject& asteroid, GameObject& spaceShip);
void stationShip(GameObject& spaceStation, GameObject& spaceShip);
void stationAsteroid(GameObject& spaceStation, GameObject& asteroid);
typedef void(*HitFunctionPtr)(GameObject&, GameObject&);
typedef map<pair<string, string>, HitFunctionPtr> hitMap;
pair<string, string> makeStringPtr(const char* str1, const char* str2);
hitMap* initializeCollisionMap();
HitFunctionPtr lookup(const string& ob1, const string ob2);
}//namespace
void processCollision(GameObject& ob1, GameObject& ob2)
{
HitFunctionPtr ptr = lookup(typeid(ob1).name(), typeid(ob2).name());
if(ptr)
{
ptr(ob1, ob2);
}
else
{
throw unKnownCollision(ob1, bo2);
}
}
namespace
{
pair<string, string> makeStringPtr(const char* str1, const char* str2)
{
return pair<string, string>(str1, str2);
}
}
namespace
{
hitMap* initializeCollisionMap()
{
hitMap* ptr = new hitMap;
(*ptr)[makeStringPtr("SpaceShip", "Asteroid")] = &shipAsteroid;
(*ptr)[makeStringPtr("SpaceShip", "SpaceStation")] = &shipStation;
//TODO:
}
return ptr;
}
namespace
{
HitFunctionPtr lookup(const string& ob1, const string& ob2)
{
static auto_ptr<hitMap> collisionMap(initializeCollisionMap());
hitMap::iterator it = collisionMap->find(make_pair(ob1, ob2));
if(it == collisionMap->end())
{
return 0;
}
return (*it).second;
}
}
六、继承 + 自行仿真的虚函数表
上述表述中一直说的是单个继承的子类,如果有下面的继承关系呢?
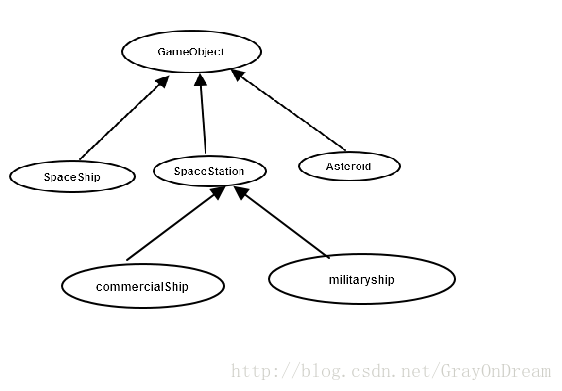
假如调用我们设计的函数就会发现结果并不如愿,尽管militaryShip被看作SpaceShip但是lookup函数并不知道这些。这种时候我们只能使用之前的双虚函数,的确很难堪。
七、将自行仿真的虚函数表初始化(again)
对于这块我没看太懂,就只贴代码
class CollisionMap
{
public:
typedef void (*HitFunctionPtr)(GameObject&, GameObject&);
void addPtr(const string& type1, const string& type2, HitFunctionPtr collisionFunction, bool symmetric = true);
void removePtr(const string& type1, const string& type2);
HitFunctionPtr lookup(const string& type1, const string& type2);
static CollisionMap& theCollisionMap();
private:
CollisionMap();
CollisionMap(const CollisionMap&);
};
class RegisterCollisionFunction
{
public:
RegisterCollisionFunction(const string& type1, const string& type2, CollisionMap::HitFunctionPtr collisionFunction, bool symmetric = true)
{
CollisionMap::theCollisionMap().addPtr(type1, type2, collisionFunction, symmetric);
}
}
条款三十二:在未来时态下发展的程序
这个条款没有说明具体的技术问题,只是说了一些在写程序中应坚持的原则。
1、准备好未知的变化:
现代计算机语言的发展速度之快是我们无法预估的,伴随这些新技术的出现客户的需求也发生了根本性的变化,当你写你的类时必须接受“状况总会改变”的事实,也许你无法知道未来可能面对的状况,但你必须为之做好准备。你的程序必将面对不止这一代开发者,更可能面对如今我们无法想象的问题,因此为你的程序添加一些可维护性的文档或者接口是必要的。
2、避免将规范规定化
可能你希望你的代码被如何如何使用,而且禁止某些比必要的动作,但是使用你的代码的开发人员完全可以不按照你的规范进行操作,也许他们并没有认真读你的文档,这可能在开发中带来一些不必要的麻烦,但是如果你的代码中提供了这种限制,并且错误的操作会带来错误提示,即把规范实现在你的代码中。
3、为类的赋值和拷贝函数做好准备
及时为类的赋值和拷贝函数做好准备是个不错的选择。
4、尽量将你的代码局部化
局部化是指尽可能减小系统对代码造成的影响,有点跨平台的意味。
5、将代码泛化
让你的代码适应大多数情况,除非会造成很重大的不良后果。
6、将设计需求放在首位
你的代码始终服务于设计需求,别偏离了轨道。
条款三十三:将非尾端类(non-leaf classes)设计为抽象类(abstract classes)
假如我们希望管理两个类,他们有以下集成结构:
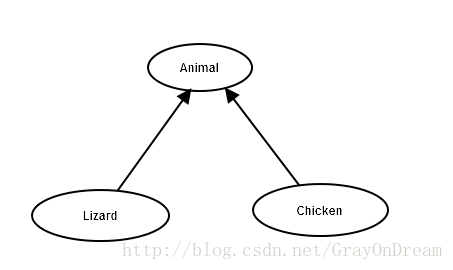
下面是我们的类的定义:
class Animal
{
public:
Animal& operator=(const Animal& rst);
};
class Lizard:public Animal
{
public:
Lizard& operator=(const Lizard& rst);
};
class Chicken:public Animal
{
public:
Chicken& operator=(const Chicken& rst);
};
class Animal
{
public:
Animal& operator=(const Animal& rst);
};
class Lizard:public Animal
{
public:
Lizard& operator=(const Lizard& rst);
};
class Chicken:public Animal
{
public:
Chicken& operator=(const Chicken& rst);
};
现在我们需要实现对象之间的赋值,可以将赋值操作声明为virtual,这样就可以定位到具体的类进行操作。但是又带来一个问题这个代码允许不同类型之间的赋值,但是这样做明显是不对的。一种有效的做法是在对传入函数的指针进行操作之前进行动态类型转换当传入的对象并不是我们期望的时候会抛出bad_cast exception异常这样就可以避免不同类型之间的转换。
Lizard& Lizard::operator=(const Animal& rst)
{
const Lizard& rst_liz = dynamic_cast<const Lizard&>(rst);
//TODO:...
}
另一种不需要dynamic_cast支持的方法是 将父对象的赋值重载方法声明为私有的这样也可以达到目的,但是问题是Animal不能赋值给Animal。
class Animal
{
private:
Animal& operator=(const Animal& rst);
};
class Lizard:public Animal
{
public:
Lizard& operator=(const Lizard& rst);
};
class Chicken:public Animal
{
public:
Chicken& operator=(const Chicken& rst);
};
Animal ob1, ob2;
ob1 = ob2; //error 试图调用私有方法
我们需要考虑的是既然在程序中需要将Animal实例化为什么不可以为三者共同构建一个抽象类,即便逻辑上Aniaml是其他两个类的基类。
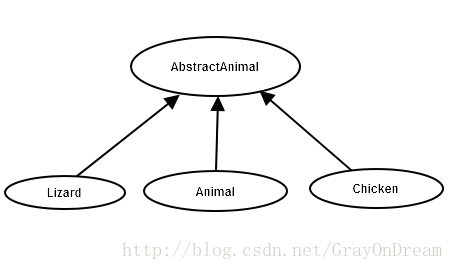
class AbstractAnimal
{
protected:
AbstractAnimal& operator=(const AbstractAnimal& rst);
public:
virtual ~AbstractAnimal() = 0;
};
class Animal:public AbstractAnimal
{
public:
Animal& operator=(const Animal& rst);
};
class Chicken:public AbstractAnimal
{
public:
Chicken& operator=(const Chicken& rst);
};
class Lizard:public AbstractAnimal
{
public:
Lizard& operator=(const Lizard& rst);
};
从上面看出在我们写程序的时候不要简单的从逻辑上直接映射类与类之间的关系,用上面的方法也许是一个不错的选择。
条款三十四:如何在同一个程序中结合C++和C
这一条款说明一些当你希望在C++文件中使用C代码时需要注意的问题。
一、Name Mangling(名称重整)
在C语言中不支持重载而C++中支持重载,这就意味着即便你直接将你的C语言代码放入C++即便代码中出现了多个名称相同的方法也可能造成编译器并不报错和警告的情况的出现。而且C++编译器为了支持重载都会把函数名进行重整而,函数名称的重整可能给我们的程序带来一定的麻烦因此可以使用extern "C"来将函数声明为C特点的函数,要求编译器以C函数对待。
下面三种方式都可以,第三种更具移植性:
extern "C" void func();
extern "C"
{
void func_1();
void func_2();
}
#ifdef __cplusplus
extern "C"{
#endif
void fun_1()
void fun_2()
#ifdef __cplusplus
}
#endif
二、Statics的初始化
这里涉及的问题是静态成员的初始化和构造函数的执行在main函数之前,但是我们一般以main函数为程序的执行入口有时我们可以这样做:
extern "C" int realMain(int argc, char** argv);
int main(int argc, char** argv)
{
return realMain(argc, argv);
}
但是这个问题并不是这么简单就能解决的,更多的工作可能需要你去做。
三、动态内存分配
C++中动态内存分配使用new销毁用delete,而C语言中动态内存分配用malloc销毁用free,这里只要注意对应关系就好,不要弄混。
四、数据结构的兼容
C++中的struct和C语言中的struct相比拥有同等的结构即便在C++中添加了非虚函数,这也不会影响内存布局因此二者之间进行交流几乎不影响兼容性。
简单的说是一下五条:
- 确定你的C++和C编译器产出兼容的目标文件;
- 将双方都使用函数声明extern “C”;
- 如果可能尽量在C++中撰写main;
- new申请的用delete删除,malloc申请的用free删除;
- 两个语言之间的数据结构的交流限制于C所能理解的范围。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









