






提问:作为DBA运维的你,是否遇到这些烦恼
1、某客户现场,业务系统生产环境下,GreatDB集群出现告警,发现主从之间GTID存在不一致
2、系统运行前期一直很稳定,怎么会突然出现不一致,不知道是什么原因?
心中有章,遇事不慌
作为DBA的你,遇到问题无从下手,除了在问题面前徘徊,还能如何选择?如果你一次或多次遇到该问题还是无法解决,又很懊恼,该如何排忧呢?关注公众号,关注《包拯断案》专栏,让小编为你排忧解难~
#包拯秘籍#
一整套故障排错及应对策略送给你,让你像包拯一样断案如神:
#首先
遇到此类问题后,我们要做到心中有章(章程),遇事不慌。一定要冷静,细心排查故障现象(与研发/用户仔细沟通其反馈的问题,了解故障现象、操作流程、数据库架构等信息),不放过任何细节和线索
#其次
我们要根据故障现象进行初步分析。认真研读文档。心中要想:是什么原因导致GTID不一致?是主从切换了,丢数据了还是因为误操作?
#然后
针对上述思考,我们需要逐步验证并排除,确定问题排查方向。
#接着
确定了问题方向,进行具体分析。通过现象得出部分结论,通过部分结论继续排查并论证。
#最后
针对问题有了具体分析后,根据当前的细节和理论,复现和分析出所有场景,最终梳理出故障报告。
真刀实战,我们能赢
说了这么多理论,想必实战更让你心动。那我们就拿一个真实案例进行分析---某全国股份制银行一个租赁业务系统正式生产环境下,出现GreatDB数据库集群告警,遇到数据库主从库之间GTID不一致的问题,该如何快速分析处理:
1、故障发生场景
某天凌晨,在项目现场兢兢业业进行数据库运维的你,突然遇到GreatDB数据库集群出现告警,心中一惊:业务系统运行一直很稳定,怎么会突然出现GTID不一致,是主从切换了、丢数据了,还是误操作了……一系列疑问在心中产生,DBA赶紧着手排查具体原因。
2、故障分析
数据库主从库GTID不一致,首先必须得对比一下主节点的GTID和从节点的GTID。从中发现从节点多了一个GTID,而且多出来的GTID中UUID是从节点自带的。通过解析binlog,发现对应GTID的操作是TRUNCATE
![]()
这里有个细节需要注意一下,truncate语句中带了注释信息:generated by server, implicitly emptying in-memory table,确认是由内部触发的,还指向了memory表。
此时就有疑问了:什么操作会使从节点触发自动的truncate?
3、执行操作
步骤1:确认表结构
确认truncate的表为memroy引擎表

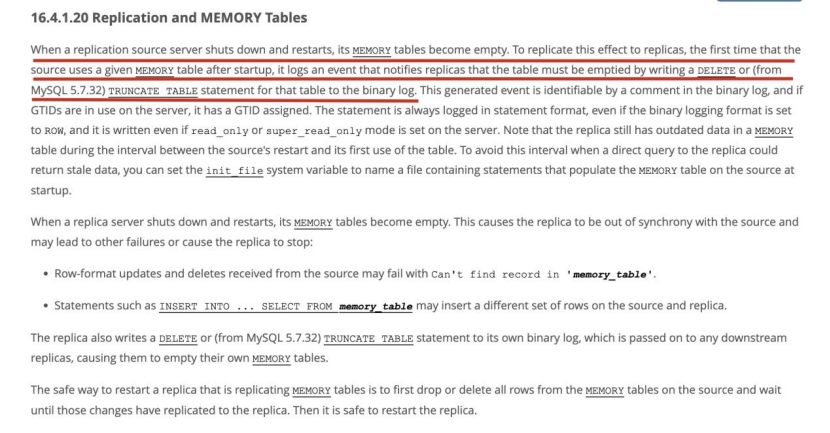
步骤2:查看文档中针对memory引擎表在主从复制下的介绍
关于主从复制场景,当数据库shutdown或者restart后,memory表会被清空。为将这个结果同步到从节点,所有节点的同一memory表都为空。因此,当数据库启动后第一次使用memory表时,会在binlog中记录truncate table或delete memory table的操作。
看到这是不是恍然大悟:memory引擎表在数据库重启后,第一次使用该表会触发truncate。但为什么是在从节点触发的,并且又是什么操作触发的呢?带着疑问继续往下排查。
步骤3:故障溯源与场景复现
从同事描述操作情况得知:当时从节点进行了重启,并执行了use db和查询数据的操作,操作后就出现了GTID不一致的告警。这种情况下DBA就会怀疑:是不是use db触发的(在执行use db时,会把表加入table cache并打开)。
带着上述疑问,复现一下场景:
创建一张memory引擎表、重启数据库节点,之后进行use db操作。在use db操作前后分别查询一下当前的GTID,发现执行use db操作后多了一条GTID。
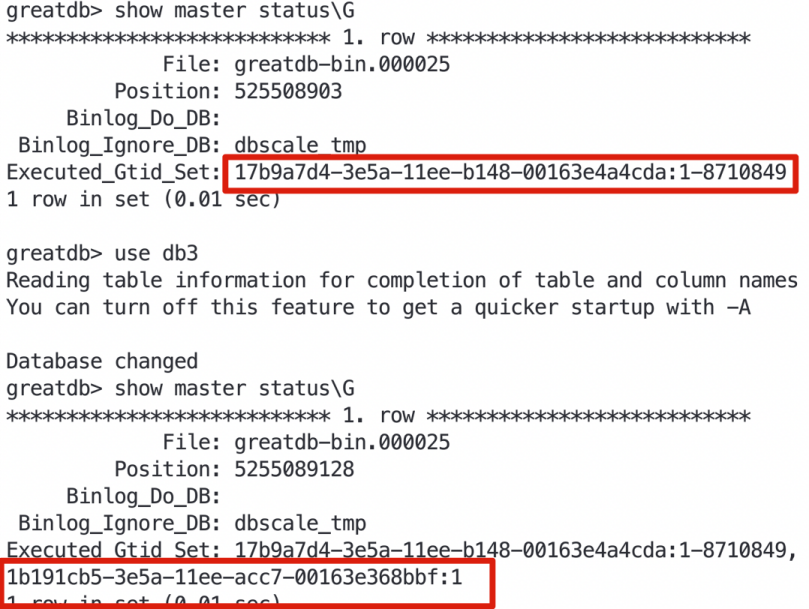
通过解析binlog,这一点也得到了证实。
![]()
截至目前,就知道本次触发场景的全貌了。更深一步想想,是否还有其他场景会触发这种故障呢?
举一反三,才能深刻理解
通过测试,发现以下几种场景都会触发memory引擎表的truncate,以下均是在数据库重启后第一次操作该命令
(1)use db
(2)查询information_schema.tables
(3)select 查询该表
(4)greatdbdump
(5)主节点对该memory表数据进行插入或更新(主节点未重启的情况下)
4、深入剖析
我们再深入想一步:如果触发主从切换,会不会出现这个问题呢?正常进行主从切换时,各个数据库均未重启,此时切换后可以查询到memory引擎表的数据。
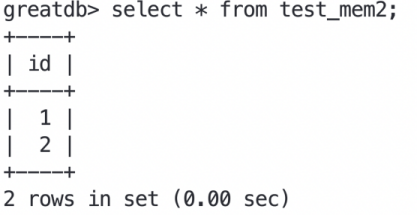
从节点查询memory引擎表的数据也存在
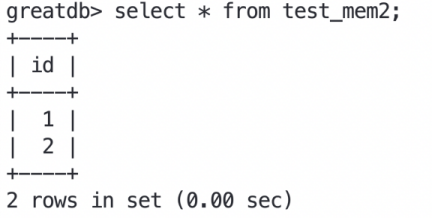
如果数据库从节点重启过,并且新的主节点是这个重启过的数据库节点,则会出现一种情况:切换前可以查询到memory引擎表数据,切换后无法查询memory引擎表数据。
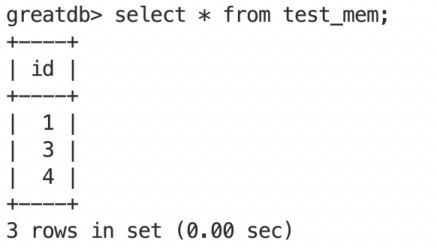
切换后进行查询

在进行select查询时,会触发新的主节点对该memory引擎表进行truncate,同时该truncate语句会通过主从同步方式同步至从节点,所有节点memory引擎表的数据皆为空。
![]()
至此,问题也就排查清楚了:对于主从复制场景,当shutdown或者restart后,memory表会被清空。为了将这个结果同步到从节点,所有节点同一memory表都为空。因此,当数据库启动后第一次使用memory表时,会在binlog中记录truncate table或delete memory table操作。经验证,这一操作无论是在主节点还是从节点都会触发该操作。
具体而言,触发场景包括use db、查询information_schema.tables表、select memory table、mysqldump、主节点对memory引擎表进行数据插入。
5、故障解决
对于上述场景,根据具体情况采取以下操作方式:
1)如果数据库所有主从节点均未重启,可以将表的引擎更改为innodb引擎。
2)如果从节点存在重启的情况下,但并未触发truncate,这时不管是直接操作表数据还是更改引擎都会出现问题。为了数据安全,需要先将主节点的表引擎更改为innodb,之后若从节点出现GTID不一致,则对从节点进行备份恢复(此时从节点的memory引擎表没有数据,主节点有数据)。
复盘总结
1、memory引擎表,在主从复制场景下不推荐,容易出现主从之间memory引擎表数据不一致和GTID不一致的问题;
2、在配置基线中,要将一些不常用的引擎或存在风险的引擎禁用掉,在规避故障风险的同时也方便统一管理。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









