






根据word模板生成word和PDF
需求:有一个固定的合同模板,在vue前台填写指定的信息,替换合同模板指定的内容
我们使用的默认模板内容如图:

我们在前端填写的字段就是合同名称、项目名称和项目金额,vue将这些内容填写到name、project、money字段,进行替换。
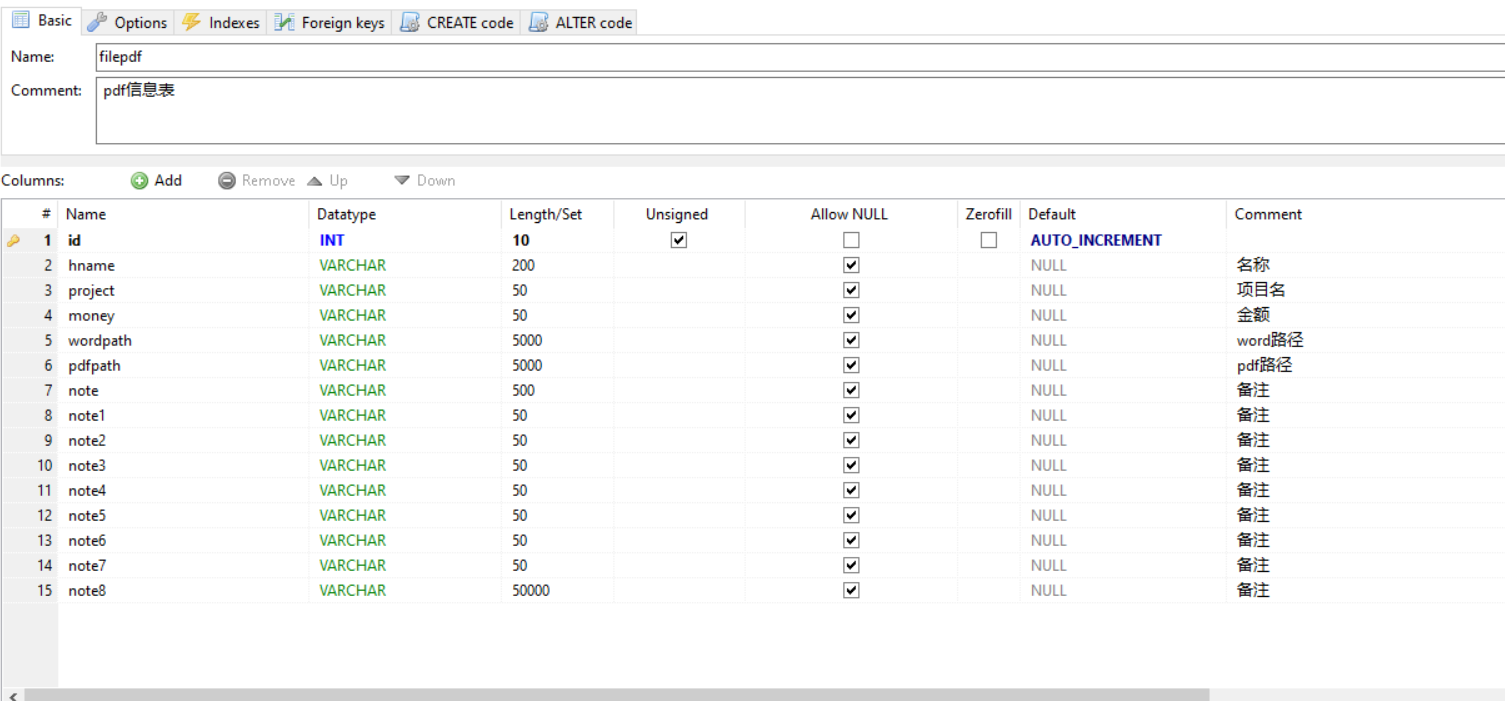
数据库表内容:(仅作为测试demo使用,需根据具体需求更改)
前端界面:
路径字段不应该展示,这里只是为了演示方便
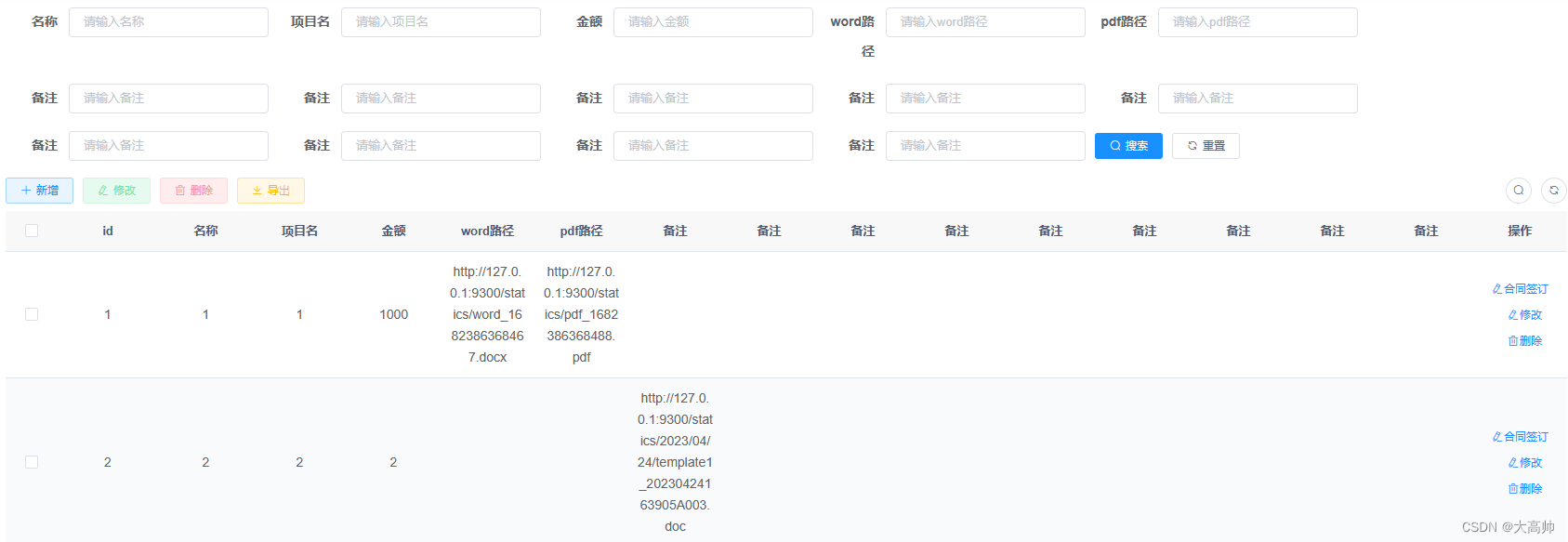
点击合同签订按钮,跳转字段填写界面

这里填写的信息会传递到后台,进行替换,并且把替换后的word以及pdf路径生成到wordpath和pdfpath字段里,进而实现下载功能。
前台代码:(基础信息查询界面不再展示,只展示)
<template>
<div class="app-container">
<el-card class="box-card">
<h1 style="text-align: center">生成合同信息</h1>
<el-form ref="form" :model="form" :rules="rules" label-width="80px">
<el-form-item label="名称" prop="hname">
<el-input v-model="form.hname" placeholder="请输入名称" />
</el-form-item>
<el-form-item label="项目名" prop="project">
<el-input v-model="form.project" placeholder="请输入项目名" />
</el-form-item>
<el-form-item label="金额" prop="money">
<el-input v-model="form.money" placeholder="请输入金额" />
</el-form-item>
<el-form-item label="备注" prop="note">
<el-input v-model="form.note" placeholder="请输入备注" />
</el-form-item>
<div style=" text-align: right;">
<el-button @click="updateForMation">提交信息</el-button>
<el-button @click="wordxiazai">word下载</el-button>
<el-button @click="pdfxiazai">pdf下载</el-button>
</div>
</el-form>
</el-card>
</div>
</template>
<script>
import { getClean, uploadFile,updateFile } from "@/api/module/gs/details";
import { listFilepdf, getFilepdf, delFilepdf, addFilepdf, updateFilepdf} from "@/api/project/filepdf";
export default {
data() {
return {
// 遮罩层
loading: true,
// 选中数组
ids: [],
// 非单个禁用
single: true,
// 非多个禁用
multiple: true,
// 显示搜索条件
showSearch: true,
// 总条数
total: 0,
// pdf信息表格数据
filepdfList: [],
// 弹出层标题
title: "",
// 是否显示弹出层
open: false,
// 查询参数
queryParams: {
pageNum: 1,
pageSize: 10,
hname: null,
project: null,
money: null,
wordpath: null,
pdfpath: null,
note: null,
note1: null,
note2: null,
note3: null,
note4: null,
note5: null,
note6: null,
note7: null,
note8: null
},
// 表单参数
form: { hname: '',
project: '',
money: '',
wordpath: '',
pdfpath: '',
note: null,
note1: null,
note2: null,
note3: null,
note4: null,
note5: null,
note6: null,
note7: null,
note8: null},
// 表单校验
rules: {
}
};
},
created() {
const id = this.$route.query.id;
console.log(id)
if (id) {
// 获取表详细信息
getFilepdf(id).then(response => {
this.form = response.data;
});
}
},
methods: {
/** 查询pdf信息列表 */
getList() {
this.loading = true;
listFilepdf(this.queryParams).then(response => {
this.filepdfList = response.rows;
this.total = response.total;
this.loading = false;
});
},
//点击提交信息按钮将字段信息传递到后台
updateForMation(){
updateFile(this.form).then(response => {
});
},
wordxiazai(){
//下载功能:重点url就是word的路径的字段值
var name = this.pdfpath;
var url = this.form.wordpath;
var suffix = url.substring(url.lastIndexOf("."), url.length);
const a = document.createElement('a')
a.setAttribute('download', name )
a.setAttribute('target', '_blank')
a.setAttribute('href', url)
a.click()
},
pdfxiazai(){
//下载功能:重点url就是pdf的路径的字段值
var name = this.pdfpath;
var url = this.form.pdfpath;
var suffix = url.substring(url.lastIndexOf("."), url.length);
const a = document.createElement('a')
a.setAttribute('download', name )
a.setAttribute('target', '_blank')
a.setAttribute('href', url)
a.click()
}
}
}
</script>
//js连接后台路径,另一个"@/api/project/filepdf"不写了
export function updateFile(data) {
return request({
url: '/project/api/process/',
method: 'post',
data: data,
})
}
后台代码:
这段代码的大致流程是:
- 接收前端传递过来的Filepdf对象,其中包含了Word文件的路径、姓名、项目名称和金额等信息。
- 将Word文件读取为XWPFDocument对象,遍历其中的所有段落,并判断是否包含需要替换的文本串,如果包含则进行文本替换。
- 将替换后的XWPFDocument写入到新的Word文件中(命名方式为"word_当前时间戳.docx")。
- 将新生成的Word文件读取为另一个XWPFDocument对象,然后将其转换为PDF格式,并将PDF输出到新的文件中(命名方式为"pdf_当前时间戳.pdf")。
- 将新生成的Word和PDF文件的访问路径(“http://127.0.0.1:9300/statics/具体名称”)分别设置到Filepdf对象的Wordpath和Pdfpath字段中。
- 更新Filepdf对象,并返回操作成功的信息。
// 文件处理接口
@PostMapping("/process")
public AjaxResult processFile(@RequestBody Filepdf filepdf) throws IOException {
//接收到前台传递过来的filepdf
//把 filepdf的Wordpath字段设置为模板的路径
filepdf.setWordpath("D:\\YinHe-Yqgbathe\\ruoyi-modules\\ruoyi-project\\src\\main\\java\\com\\ruoyi\\project\\module\\gs\\template.docx");
//wordfilePath设置为模板的路径
String wordfilePath = filepdf.getWordpath();
//声明fis,以字节流的形式读取文件,fis 代表一个 FileInputStream 对象,它指向要读取的 Word 文件。
FileInputStream fis = new FileInputStream(wordfilePath);
//创建一个 XWPFDocument 实例,该实例与指定的 Word 文件建立了连接,XWPFDocument 是一个用于处理 .docx 文件的类
XWPFDocument document = new XWPFDocument(fis);
//使用 for 循环遍历 XWPFDocument 中的所有段落
for (XWPFParagraph paragraph : document.getParagraphs()) {
//使用 XWPFParagraph 类中的 getParagraphText() 方法来获取当前处理的段落中包含的文本内容
String paragraphText = paragraph.getParagraphText();
// 判断该段落中是否包含需要替换的文本串,因为我们要替换name,project,money,具体根据需求更改
if (paragraphText.contains("name") || paragraphText.contains("project") || paragraphText.contains("money")) {
//使用while是为了替换每一个,防止漏掉
boolean foundMatch = true;
while (foundMatch) {
foundMatch = false;
//使用 XWPFParagraph 类中的 getRuns() 方法获取当前处理的段落中包含的所有文本样式 Run
for (XWPFRun run : paragraph.getRuns()) {
//调用 getText(int pos) 方法可以获取该文本样式 Run 中从指定位置(pos)开始的所有文本信息,并将其作为一个字符串返回
String runText = run.getText(0);
//以下三个if是具体替换,eg.如果有name就替换为filepdf.getHname(),就是前端接受的内容
if (runText != null && runText.contains("name")) {
runText = runText.replaceFirst("name", filepdf.getHname());
run.setText(runText, 0);
foundMatch = true;
}
if (runText != null && runText.contains("project")) {
runText = runText.replaceFirst("project", filepdf.getProject());
run.setText(runText, 0);
foundMatch = true;
}
if (runText != null && runText.contains("money")) {
runText = runText.replaceFirst("money", filepdf.getMoney());
run.setText(runText, 0);
foundMatch = true;
}
}
}
}
}
//关闭FileInputStream
fis.close();
//设置path1为D:/ruoyi/uploadPath,因为若依默认存储为D:/ruoyi/uploadPath,可以根据配置文件进行更改
String path = "D:/ruoyi/uploadPath";
//拼接具体名称,按照时间命名,并且存储到相应位置
String newwordFilePath = path + "/word_" + System.currentTimeMillis() + ".docx";
FileOutputStream fos = new FileOutputStream(newwordFilePath);
document.write(fos);
fos.close();
XWPFDocument doc = new XWPFDocument(new FileInputStream(newwordFilePath));// docx
//转为pdf
// 创建输出流,设置名称
String newPdfFilePath = path + "/pdf_" + System.currentTimeMillis() + ".pdf";
String outputPDFFiles = newPdfFilePath; // 输出的.pdf文件路径
FileOutputStream foss = new FileOutputStream(outputPDFFiles);
PdfOptions options = PdfOptions.create();
// 将 .docx 转换为 .pdf
PdfConverter.getInstance().convert(doc, foss, options);
// 关闭输出流
foss.close();
System.out.println("转换完成");
//因为前端不可以下载绝对路径,所以要拼接成http://127.0.0.1:9300/statics/***的形式,***为具体名称(D:/ruoyi/uploadPath后的名称)
//设置wordpath字段
int index = newwordFilePath.lastIndexOf("/");
String q = newwordFilePath.substring(index);
filepdf.setWordpath("http://127.0.0.1:9300/statics" + q);
//设置pdfpath字段
int index1 = newPdfFilePath.lastIndexOf("/");
String q1 = newPdfFilePath.substring(index1);
filepdf.setPdfpath("http://127.0.0.1:9300/statics" + q1);
// 执行更新
filepdfService.updateFilepdf(filepdf);
return AjaxResult.success();
}
注:需要在pom.xml中导入指定依赖,内容为:
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.15</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.13</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.15</version>
</dependency>
<dependency>
<groupId>fr.opensagres.xdocreport</groupId>
<artifactId>org.apache.poi.xwpf.converter.pdf</artifactId>
<version>1.0.6</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>xmpbox</artifactId>
<version>2.0.13</version>
</dependency>
<dependency>
<groupId>fr.opensagres.xdocreport</groupId>
<artifactId>org.apache.poi.xwpf.converter.pdf</artifactId>
<version>1.0.6</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>xmpbox</artifactId>
<version>2.0.13</version>
</dependency>
















 1804
1804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











