







前言
这篇文章是本人第一次看image caption相关类型的文章,参考了很多的笔记,但是总有一些地方还是有一些不理解,所以决定自己写一份笔记记录,并且只看image caption相关部分,VQA就没有看。小白一枚~有说的不对的请多指教
一、阅读这篇论文的目的?
了解何为自顶向下和自底向上,这两者组合的注意力机制又是怎么应用于image caption。

首先第一个问题,原文中的introduction就告诉了我们:在本文中,我们采用了类似的术语,将由非视觉或任务特定情境驱动的注意机制称为“自上而下”,而将纯视觉前馈注意机制称为“自下而上”。
二、作者研究思路和创新
1.研究思路
1、在人类视觉系统中,注意力可以通过由当前任务确定的自上而下的信号(例如,寻找某些东西)来自动聚焦,并且可以通过与意外,新颖或显着刺激相关的自下而上的信号自动聚焦。
2.大多数注意力机制通常会被训练成有选择地关注CNN的一个或多个层的输出。但是,这种方法很少考虑如何确定受关注的图像区域。
2.主要创新
一种结合了自下而上和自上而下的视觉注意力的机制:
自下而上的注意力(由 Faster R-CNN 实现)提出了一组显著的图像区域,每个区域由一个合并的卷积特征向量表示。
自上而下的机制使用特定于任务的上下文来预测图像区域上的注意力分布。然后将参与的特征向量计算为所有区域的图像特征的加权平均值。就是确定特征对文本的贡献度
三、算法思想
1、Bottom-Up Attention model
这部分主要内容就是Faster-RCNN,在此不多说,主要是使用 Faster R-CNN 来提取图片中的兴趣点,然后对感兴趣的区域采用 ResNet-101 来提取特征,使用 IoU 阈值来对所有区域进行一个筛选(“hard” attention)。对于每一个区域 ,
定义为每个区域的 mean-pooled convolutional 特征(2048维)。使用这种方法从很多候选配置中选出一小部分候选框。
所以V就可以看成是 bottom-up attention model 的输出,然后将这些用于top-down attention model,提取出对描述贡献大的显著性区域的特征。
Faster-RCNN的输出:

2、Captioning Model
主要有两个LSTM,第一个是Attention LSTM,对特征进行加权; 第二个是Language LSTM,产生输出。
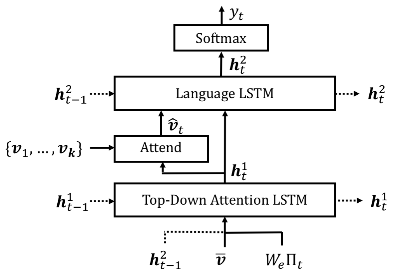
作者说这里两个LSTM都是用的标准LSTM,因此就简化表述为:
其中,对于LSTM的输入以及隐藏状态
使用上标1表示top-down attention LSTM,上标2表示language LSTM。我个人认为上图就是这篇论文的核心,作者把两个LSTM的隐藏状态相互利用,LSTM在图像描述问题中处理方式,其实最关键的地方是如何有效的让图像信息与文本信息进行交互,也就是如何利用好LSTM中的
这个变量
a、Top-Down Attention LSTM
top-down attention LSTM的输入是![]() ,
,
是由上一个时间步的 Language LSTM的 输出
k个image feature的 mean-pooled feature ![]()
上一时刻生成的encoding of word(为t时刻输入单词的one-hot encoding,
为embedding矩阵。)
这个输入提供给了Attention LSTM截至当前时间步的最大上下文信息,还有整个图片的内容,以及当前生成的单词内容。
我们将其汇总一下,得到下面这个公式。

看到这,貌似还是能够理解的,由图可知,三个东西丢进去然后得到,然后接下来的几个公式我一直没完全理解,先把公式放上来。

由上图可以发现,出了第一个LSTM就到了“Attention”模块,于是乎,我就在知乎上找到了这个

经过阅读会发现,如果你从下往上看,这里面的公式除了变量名,其他都一模一样,所以这上面几个公式的意思就是在每个t时刻,Attention LSTM 都会输出一个output ,并且都会为k个图像特征
生成一个权重,然后使用softmax进行标准化。最后进行加权平均。
b、Language LSTM
根据流程图可知,第二个LSTM的输入就是拼接第一个LSTM的隐含层输出和Attention的结果
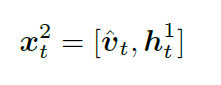
接下来第二步,用得到的,经过softmax,输出单词的概率分布。

其中,(…
)为单词的序列,而整个句子的概率分布为每个单词概率的连乘。

总结
实验部分我就不贴出来了,原文都有,当然效果是十分优秀的,我们可以看一张实验图
 从图中可以看出,红色框代表的就是RoIPooling之后的区域,红色框越突出,表明前面公式中的
从图中可以看出,红色框代表的就是RoIPooling之后的区域,红色框越突出,表明前面公式中的在这个区域的注意力权重数值比较大,其他区域相对较小。比如在生成“frisbee”这个单词时,模型就会关注“frisbee”所在区域的位置,因此该区域的红色框非常突出显示。
最后,文章中虽然没有提及在目前研究中最为广泛使用的Encode—Decode框架,但是基于自下而上的注意力模型的任务是获取图像兴趣区域,提取图像特征类似于对图像进行特征编码,实现编码阶段任务;而基于自上而下的注意力模型用于学习调整特征权重,实现了图像内容的“时刻关注”,逐词生成描述,相当于解码阶段,这其中的就和encode-decode中的向量C作用是类似的。















 854
854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









