







Pytorch学习笔记
学习视频:[B站up主:我是土堆]
一、help和dir指令
p
y
t
o
r
c
h
pytorch
pytorch可以看作一个工作箱,里面有很多的小格子装有不同的工具。
可以使用
d
i
r
(
)
dir()
dir()指令来查看这个工作箱里面有哪些分格区:
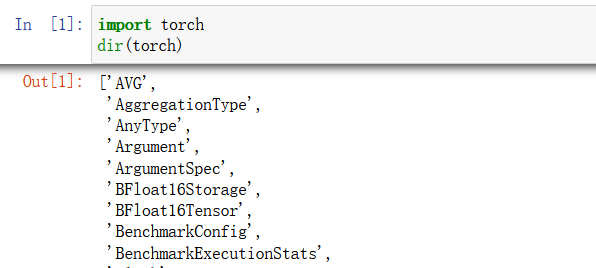
想要继续探索这个工具箱第一个分格区装了哪些工具,继续使用
d
i
r
(
)
dir()
dir()指令:
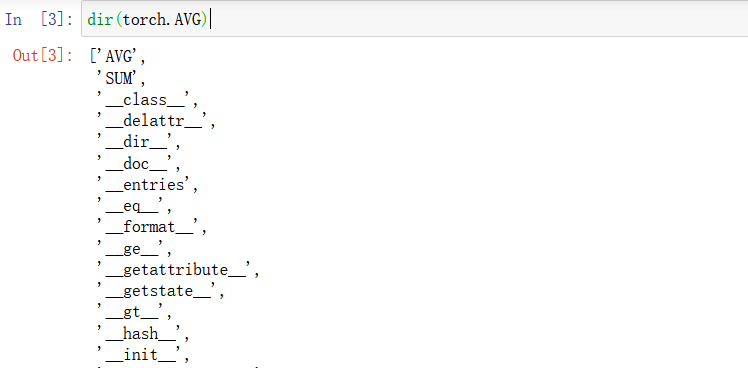
想知道这个分格区的第二个工具的作用,使用
h
e
l
p
(
)
help()
help()指令:

二、Pytorch加载数据
-
D a t a s e t 类 Dataset类 Dataset类:
提供一种方式去获取数据及其label -
D a t a l o a d e r 类 Dataloader类 Dataloader类:
为网络提供不同的数据形式
以图片数据为例子:
- 仅读取一张图片可以使用 P I L . I m a g e PIL.Image PIL.Image:
from PIL import Image
#图片路径
img_path = 'data\\train\\ants\\0013035.jpg'
#读取图片
img = Image.open(img_path)
#打印图片尺寸
print('尺寸:',img.size)
#展示图片
img.show()
- 获取多个文件,需要使用 o s os os:
import os
#数据所处文件夹
dir_path = 'data\\train\\ants'
#获取文件夹下文件的名字存于list数组中
img_path_list = os.listdir(dir_path)#<class:list> 第一个列表元素指向文件夹第一个文件的名字
一、接下来读取一些数据(图片),文件名为数据集的
l
a
b
e
l
label
label:
这里有很多蚂蚁和蜜蜂的图片,蚂蚁图片的路径是
d
a
t
a
/
t
r
a
i
n
/
a
n
t
s
data/train/ants
data/train/ants,蜜蜂图片的路径是
d
a
t
a
/
t
r
a
i
n
/
b
e
e
data/train/bee
data/train/bee;图片上一层就是该图片集的
l
a
b
e
l
label
label。
获取蚂蚁数据集
from PIL import Image
import os
from torch.utils.data import Dataset
class MyData(Dataset):
'''
需要重写Dataset的函数
'''
def __init__(self,root_dir,label_dir):
'''
初始化函数
root_dir:根路径 如:data\\train
label_dir:label 如:ants
'''
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir)#文件路径:data\\train\\ants 这个函数会自动加 /
self.img_path = os.listdir(self.path)#文件下的图片名:['img_1.jpg',img_2.jpg,……]
def __getitem__(self, index):
'''
根据索引读取文件
index:索引值
'''
img_name = self.img_path[index]#获取图片名字
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)#拼接成指向一个图片的详细地址
img = Image.open(img_item_path)#获取这一张图片
label = self.label_dir#获取图片的标签
return img,label
def __len__(self):
'''
数据长度
'''
return len(self.img_path)
读取数据:
root_dir = 'data/train'
ants_label_dir = 'ants'
ants_data = MyData(root_dir,ants_label_dir)
#获取第2个数据
img,label = ants_data[1]
img.show()
print(label)#ants
展示的图片

获取蜜蜂数据集:
bees_label_dir = 'bees'
bees_data = MyData(root_dir,bees_label_dir)
#获取第2个数据
img,label = bees_data[1]
img.show()

获取训练集数据(train文件夹下的ants数据集+bees数据集):
train_data = ants_data + bees_data#将两个数据拼接在一起
#len(ants_data)=124 ,len(bees_data)=121, len(train_data)=245
img1,label1 = train_data[1]
img1.show()
img2,label2 = train_data[124]
img2.show()
img1展示:
img2展示:
即按顺序拼接
二、读取
l
a
b
e
l
label
label和图片分开放的数据集:
这里有很多蚂蚁和蜜蜂的图片,蚂蚁图片的路径是
d
a
t
a
/
t
r
a
i
n
/
a
n
t
s
i
m
g
e
data/train/ants_imge
data/train/antsimge,蜜蜂图片的路径是
d
a
t
a
/
t
r
a
i
n
/
b
e
e
s
_
i
m
g
e
data/train/bees \_imge
data/train/bees_imge;
d
a
t
a
/
t
r
a
i
n
/
data/train/
data/train/下还存在两个文件夹:
a
n
t
s
_
l
a
b
e
l
ants \_label
ants_label和
b
e
e
s
_
l
a
b
e
l
bees \_label
bees_label,这两个文件夹里面放的是txt文档,文档与图片一一对应,保存图片的label。
train文件夹:
ants_image文件夹下:
ants_label文件夹下:
txt文档
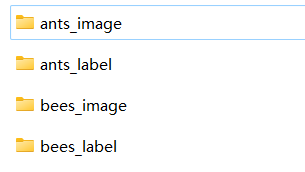
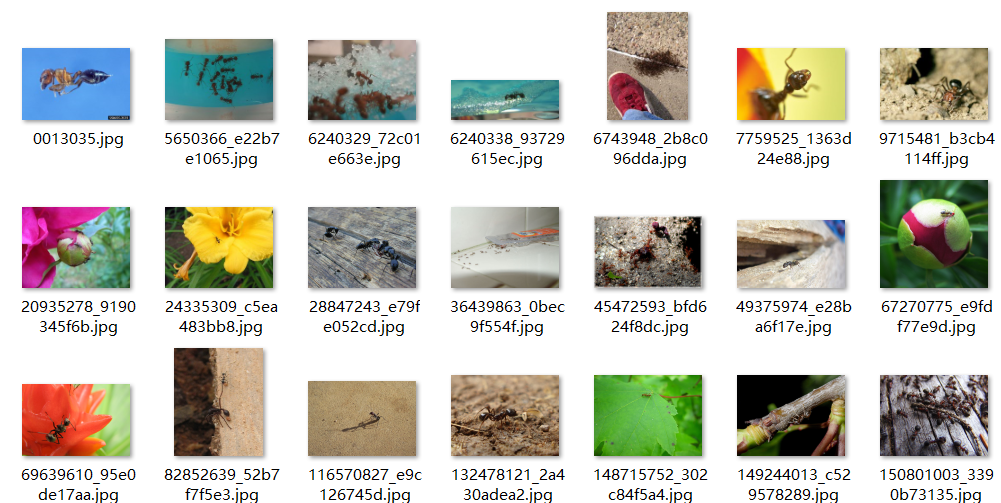

在原先的MyData类上进行修改即可
from PIL import Image
import os
from torch.utils.data import Dataset
class MyData(Dataset):
'''
需要重写Dataset的函数
'''
def __init__(self,root_dir,target_dir,label_dir):
'''
初始化函数
root_dir:根路径 如:data\\train
target_dir:数据所在文件名 如:ants_image
label_dir:标签所在文件名 如:ants_label
'''
self.root_dir = root_dir
self.target_dir = target_dir
self.img_path = os.path.join(self.root_dir,self.target_dir)#目标数据所在路径:data\\train\\ants_image
self.img_name_list = os.listdir(self.img_path)#文件下的图片名:['img_1.jpg',img_2.jpg,……]
self.label_path = os.path.join(self.root_dir,label_dir)#标签所在路径:data\\train\\ants_label
#标签文件名与图片文件名只有后缀不一样,不用读取
def __getitem__(self, index):
'''
根据索引读取文件
index:索引值
'''
img_name = self.img_name_list[index]#获取图片名字
img_item_path = os.path.join(self.root_dir,self.target_dir,img_name)#拼接成指向一个图片的详细地址
img = Image.open(img_item_path)#获取这一张图片
label_name = img_name.split('.')[0] + '.txt' #获取图片的标签文件名
label_item_path = os.path.join(self.root_dir,label_dir,label_name)#拼接成指向一个图片label的详细地址
with open(label_item_path,'r') as f:
label = f.read()
return img,label
def __len__(self):
'''
数据长度
'''
return len(self.img_path)
读取文件:
root_dir='data\\train'
target_dir='ants_image'
label_dir='ants_label'
ants_data = MyData(root_dir,target_dir,label_dir)
img,label = ants_data[0]
三、TensorBoard的使用
T
e
n
s
o
r
B
o
a
r
d
TensorBoard
TensorBoard作用:
记录日志信息并通过
t
e
n
s
o
r
b
o
a
r
d
tensorboard
tensorboard可视化
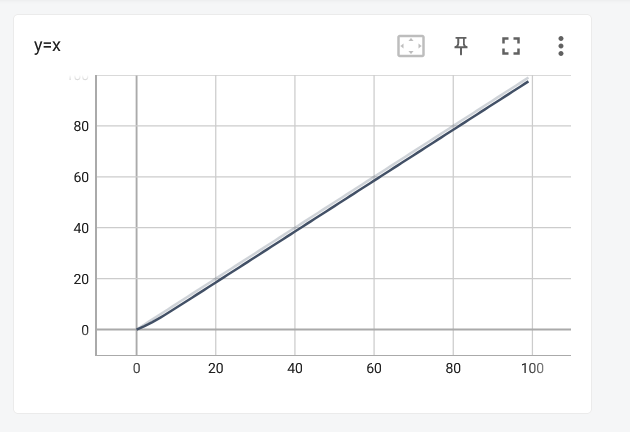
1. add_scalar()的使用
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs')#写到logs文件夹下
for i in range(100):
writer.add_scalar(tag='y=x',scalar_value=i,global_step=i)
writer.close()
'''
add_scalar(self, tag, scalar_value, global_step=None, walltime=None):
-tag:可视化图像标题
scalar_value:y轴
global_step:x轴
'''
改用端口:
在pytorch环境下输入:
tensorboard --logdir=日志文件所在绝对路径
可以看到端口号是6006
输入tensorboard --logdir=日志文件所在绝对路径 --port=6007
端口号变成6007


进入http://localhost:6007/后,可以看到绘制的图像:
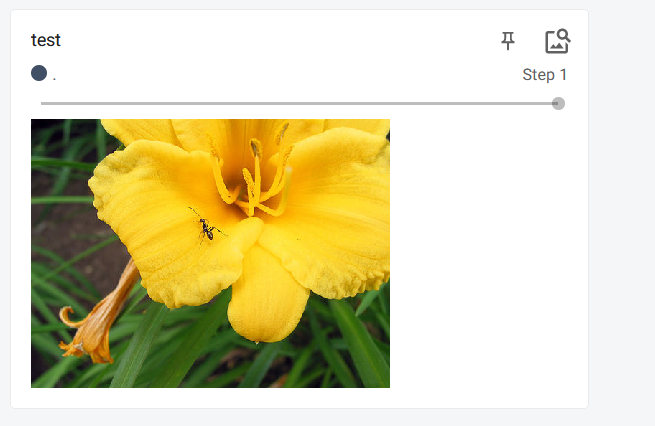
2. add_image()的使用
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter('log')
#图片路径地址
image_path = './image.jpg'
#读取图片
img_PIL = Image.open(image_path)
#转换为numpy.array类型
img_array = np.array(img_PIL)
#绘制
writer.add_image('test',img_array,1,dataformats='HWC')
writer.close()
a d d _ i m a g e ( s e l f , t a g , i m g _ t e n s o r , g l o b a l _ s t e p = N o n e , w a l l t i m e = N o n e , d a t a f o r m a t s = ′ C H W ′ ) add\_image(self, tag, img\_tensor, global\_step=None, walltime=None, dataformats='CHW') add_image(self,tag,img_tensor,global_step=None,walltime=None,dataformats=′CHW′)
-
i m g _ t e n s o r img\_tensor img_tensor: i m a g e image image d a t a data data
格式要求为 t o r c h . T e n s o r , n u m p y . a r r a y , o r s t r i n g / b l o b n a m e torch.Tensor, numpy.array, or \ string/blobname torch.Tensor,numpy.array,or string/blobname -
默认的图片数据格式是 H W C HWC HWC
进入http://localhost:6007/后,可以看到绘制的图片:
四、Transforms的使用
t
o
r
c
h
v
i
s
i
o
n
torchvision
torchvision是
p
y
t
o
r
c
h
pytorch
pytorch的一个图形库,主要用于构建计算机视觉模型。
t
o
r
c
h
v
i
s
i
o
n
.
t
r
a
n
s
f
o
r
m
s
torchvision.transforms
torchvision.transforms用于图形的变换。
1. Transforms中的Compose类
C
o
m
p
o
s
e
(
)
Compose()
Compose()类主要作用是串联多个图片变换的操作。
如下面代码,将图片先进行中心裁剪再转为
T
e
n
s
o
r
Tensor
Tensor。
transforms.Compose([
transforms.CenterCrop(10),
transforms.ToTensor(),
])
C o m p o s e ( ) Compose() Compose()内放的是一个列表,列表里的元素是想要执行的 t r a n s f o r m s transforms transforms操作。
2. Transforms中的ToTensor类
作用是将类型为 P I L I m a g e PIL\ Image PIL Image 或 n u m p y . n d a r r a y numpy.ndarray numpy.ndarray 的数据转变成 t e n s o r tensor tensor类型。
T o T e n s o r ToTensor ToTensor的使用:
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
#创建tensorboard和读取PIL image
writer = SummaryWriter('logs')
img_path = './Zoro.png'
img = Image.open(img_path)
#实例化ToTensor类并进行调用
trans_totensor = transforms.ToTensor()、
#PIL格式转为tensor格式
img_tensor = trans_totensor(img)
#在tensorboard进行显示
writer.add_image('ToTensor',img_tensor)
writer.close()
结果:
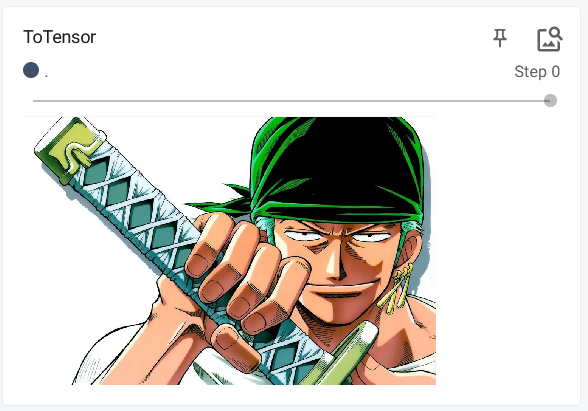
转换前的 P I L I m a g e PIL\ Image PIL Image 或者 n u m p y . n d a r r a y numpy.ndarray numpy.ndarray是 ( H × W × C ) (H \times W \times C) (H×W×C)且范围在 [ 0 , 255 ] [0, 255] [0,255],转换后的 t e n s o r tensor tensor是 ( C × H × W ) (C \times H \times W) (C×H×W)且范围在 [ 0.0 , 1.0 ] [0.0, 1.0] [0.0,1.0]。
T
r
a
n
s
f
o
r
m
s
Transforms
Transforms中的
T
o
P
I
L
I
m
a
g
e
ToPILImage
ToPILImage:
将
(
C
×
H
×
W
)
(C \times H \times W)
(C×H×W)的tensor或者
(
H
×
W
×
C
)
(H \times W \times C)
(H×W×C)的
n
u
m
p
y
.
n
d
a
r
r
a
y
numpy.ndarray
numpy.ndarray转换为
P
I
L
I
m
a
g
e
PIL\ Image
PIL Image。
3. Transforms中的Normalize类
使用均值和方差对 t e n s o r tensor tensor图片进行归一化。
对于
n
n
n个通道,需要提供均值
m
e
a
n
mean
mean:
(
M
1
,
.
.
.
,
M
n
)
(M1,...,Mn)
(M1,...,Mn)和标准差
s
t
d
std
std:
(
S
1
,
.
.
,
S
n
)
(S1,..,Sn)
(S1,..,Sn),然后对每个通道进行归一化:
o
u
t
p
u
t
[
c
h
a
n
n
e
l
]
=
(
i
n
p
u
t
[
c
h
a
n
n
e
l
]
−
m
e
a
n
[
c
h
a
n
n
e
l
]
)
/
s
t
d
[
c
h
a
n
n
e
l
]
output[channel] = (input[channel] - mean[channel]) / std[channel]
output[channel]=(input[channel]−mean[channel])/std[channel]
#归一化前
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
#归一化后
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image('Normalize',img_norm)
writer.close()
输出:
tensor(0.9647)
tensor(0.9294)
#(0.9647-0.5)/0.5 = 0.9294
展示结果:

4. Transforms中的Resize类
作用:将输入的 P I L I m a g e PIL\ Image PIL Image转换为所提供的尺寸 s i z e size size。
输入和输出都是 P I L PIL PIL
s i z e size size可以是一个序列 ( h , w ) (h,w) (h,w);也可以是一个 i n t int int,当只有一个数字,使用最小的边进行匹配(整体缩放,缩放后最小边的尺寸就是这个 i n t int int)
#转换前
print(img.size)
trans_reszie = transforms.Resize((512,512))
img_resize = trans_reszie(img)
#转换后
print(img_resize.size)
输出:
#转换前
(1092, 712)
#转换后
(512, 512)
4.1 结合前面的compose
#定义transforms操作
trans_totensor = transforms.ToTensor()
trans_reszie = transforms.Resize(512)
#组合
trans_compose = transforms.Compose([trans_reszie,trans_totensor])
#上面的transforms列表中的第一个是trans_reszie,所以需要传入的类型是PIL;最后返回的结果是resize后的tensor
img_resize_totensor = trans_compose(img)
注意:
当
C
o
m
p
o
s
e
Compose
Compose中的参数顺序是
[
t
r
a
n
s
t
o
t
e
n
s
o
r
,
t
r
a
n
s
r
e
s
z
i
e
]
[trans_totensor,trans_reszie]
[transtotensor,transreszie],会报错。因为
t
r
a
n
s
_
r
e
s
z
i
e
trans\_reszie
trans_reszie的输入需要的是PIL类型,
t
r
a
n
s
_
t
o
t
e
n
s
o
r
trans\_totensor
trans_totensor输出是
t
e
n
s
o
r
tensor
tensor类型
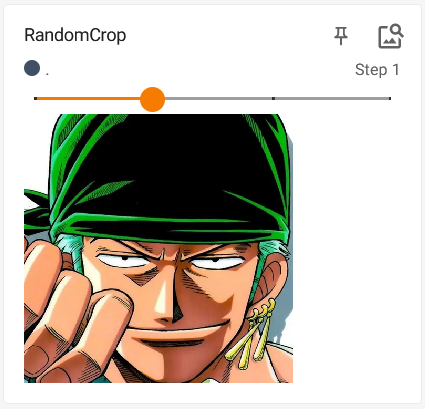
5. Transforms中的RandomCrop类
作用:对输入 P I L PIL PIL图片进行随机裁剪
初始化参数:
- s i z e size size:裁剪后的尺寸。可以是数字序列: ( h , w ) (h,w) (h,w);或者是一个数字 i n t int int,只有一个数字裁剪后是正方形的。
- pad_if_needed:是否需要进行填充
- p a d d i n g padding padding:对图像边界进行填充的像素值。可以是数字序列: ( h , w ) (h,w) (h,w)、 ( l e f t , t o p , r i g h t , b o t t o m ) (left, top, right, bottom) (left,top,right,bottom);或者是一个数字 i n t int int。
- p a d _ i f _ n e e d e d pad\_if\_needed pad_if_needed:是否进行填充
- f i l l fill fill:填充的数值
- p a d d i n g m o d e padding_mode paddingmode:填充的模式。“ c o n s t a n t constant constant”:利用常值进行填充;“ e d g e edge edge”:利用图像边缘像素点进行填充;“ r e f l e c t reflect reflect”;“ s y m m e t r i c symmetric symmetric”
tans_rcrop = transforms.RandomCrop(512)
trans_compose = transforms.Compose([tans_rcrop,trans_totensor])
img_rcrop = trans_compose(img)
writer.add_image('RandomCrop',img_rcrop,global_step=1)
writer.close()
展示结果:
6. python知识点: _ _ call_ _函数
若A类中有 _ _ c a l l _ _ \ \_ \ \_call\ \_ \ \_ _ _call _ _函数,可以使用 A ( 参数 ) A(参数) A(参数)调用 _ _ c a l l _ _ \ \_ \ \_call\ \_ \ \_ _ _call _ _函数。
class Person:
def __call__(self, name):
print('call_',name)
def hello(self,name):
print('hello_',name)
person = Person()
#调用的是call函数,call函数的调用十分简便
person('张三')
#其他函数需要加 . 来进行调用
person.hello('李四')
输出结果:
call_ 张三
hello_ 李四
7. 总结知识点
- 关注某个 c l a s s class class时,要先了解这个 c l a s s class class的输入和输出。
- 多看官方文档
- 关注方法需要什么参数;如 _ _ i n i t _ _ \ \_ \ \_init\ \_ \ \_ _ _init _ _函数,在初始化时可以传入什么参数
- 不知道返回值的时候,多用 p r i n t ( ) print() print()、 t y p e ( ) type() type()、 d e b u g debug debug
五、torchvision中的数据集使用
1. 数据集的下载
在官方网站可以找到很多的数据集和相关模型。
下图的
P
y
T
o
r
c
h
PyTorch
PyTorch是一个核心模块;
t
o
r
c
h
a
u
d
i
o
torchaudio
torchaudio是处理语言的一个模块;
t
o
r
c
h
t
e
x
t
torchtext
torchtext是处理文本的一个模块;
t
o
r
c
h
v
i
s
i
o
n
torchvision
torchvision是处理图像的一个模块。
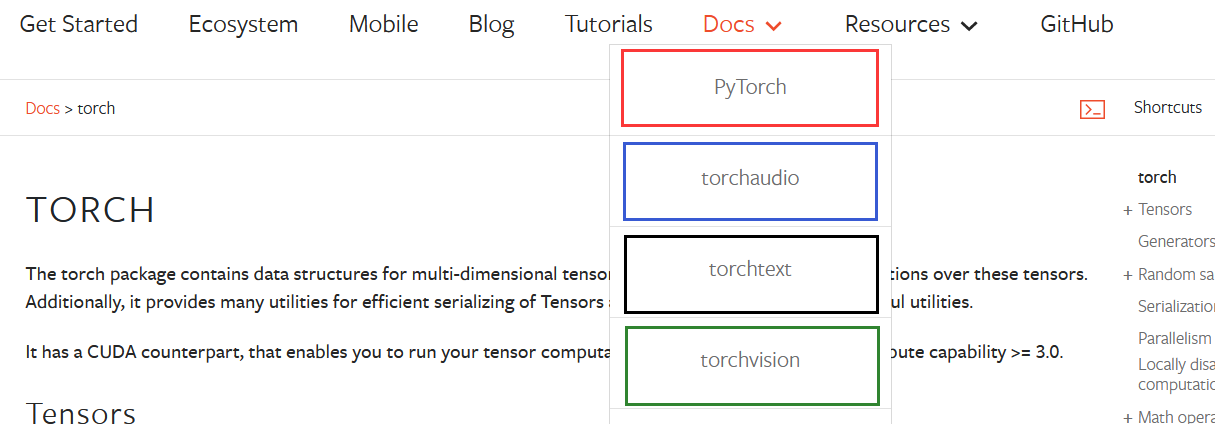
点击进入
t
o
r
c
h
v
i
s
i
o
n
torchvision
torchvision可以下载数据集或者训练好的模型和,如下图:

2. CIFAR-10 dataset的下载
可以通过 t o r c h v i s i o n torchvision torchvision中的 d a t a s e t dataset dataset类对数据集进行下载。如我们要下载 C I F A R − 10 CIFAR-10 CIFAR−10数据集,先在官方文档查看这个类方法的解释:

- r o o t ( s t r i n g ) root (string) root(string):数据集存放在文件夹;当 d o w n l o a d download download设置为 T r u e True True会自动下载到这个文件夹下
- t r a i n ( b o o l ) train (bool) train(bool):是 T r u e True True则创建训练集数据,否则创建测试集。
- $transform $:对图片的操作
- $download : 是否进行下载。 :是否进行下载。 :是否进行下载。True$则下载。
下载代码如下,下载到 . / d a t a s e t ./dataset ./dataset文件夹下,并将数据集每张( P I L PIL PIL)图片转成 t e n s o r tensor tensor类型
import torchvision
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
#训练集
train_set = torchvision.datasets.CIFAR10(root='./dataset',transform=dataset_transform,train=True,download=True)
#测试集
test_set = torchvision.datasets.CIFAR10(root='./dataset',transform=dataset_transform,train=False,download=True)
运行结果如下,会有一个链接。这样下载速度很慢,所以建议复制链接到迅雷去下载。若运行没有出现链接,可以去到 C I F A R 10 CIFAR10 CIFAR10类里去 u r l url url属性。

打印类别并获取第一个数据:
#打印数据集类别,上面返回的target就是指classes的下标,即属于那一类
print(test_set.classes) #['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
img,target = test_set[0]
print(test_set.classes[target]) #cat
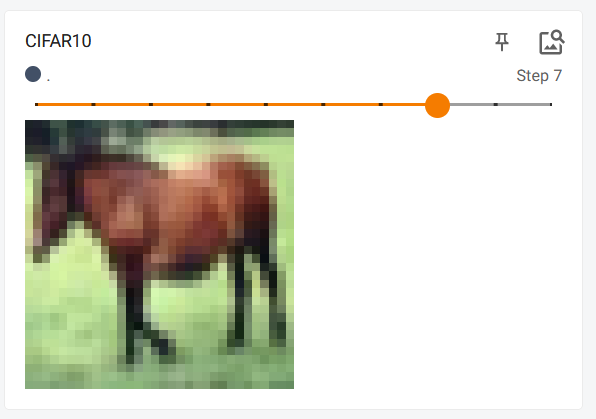
使用tensorboard进行展示
显示前
10
10
10张图片
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('p10')
for i in range(10):
img,target = train_set[i]
writer.add_image('CIFAR10',img,i)
writer.close()
展示结果:
2.1 CIFAR-10数据集介绍
官方介绍
这个数据集有
60000
60000
60000万张
32
×
32
32\times32
32×32的彩色图片;总共有
10
10
10个类别,每个类别都有
6000
6000
6000张图片;数据集的
50000
50000
50000张作为训练集,
10000
10000
10000张作为测试集。

六、DataLoader的使用
1. dataset类和datalodar的关系
d
a
t
a
s
e
t
dataset
dataset负责获取数据,如获得一副扑克牌;
d
a
t
a
l
o
a
d
e
r
dataloader
dataloader负责从
d
a
t
a
s
e
t
dataset
dataset中抽取数据,如怎么从一副扑克牌中抽取几张扑克。
如下图,
d
a
t
a
l
o
a
d
e
r
dataloader
dataloader负责抽取数据放入神经网络中,抓住牌的手可以看出需要获取数据的神经网络。

2.Dataloader官方介绍
官方介绍链接

参数:
- d a t a s e t ( D a t a s e t ) dataset (Dataset) dataset(Dataset):之前定义的 D a t a s e t Dataset Dataset,作用是提供数据集的位置、长度等信息。
- b a t c h _ s i z e ( i n t ) batch\_size (int) batch_size(int):每次抽取数据的大小
- s h u f f l e ( b o o l ) shuffle (bool) shuffle(bool):每个 e p o c h epoch epoch是否打乱数据
- n u m _ w o r k e r s ( i n t ) num\_workers (int) num_workers(int):线程数量。但在 w i n d o w window window环境下不太好使
- d r o p _ l a s t ( b o o l ) drop\_last (bool) drop_last(bool):最后抽取的数据抽不成一个完整的 b a t c h _ s i z e batch\_size batch_size, F a l s e False False的时候会保留这些数据, T r u e True True舍弃。
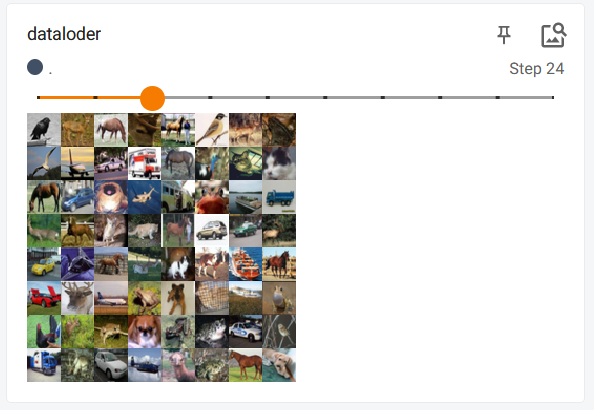
3.代码实例
import torchvision
from torch.utils.data import DataLoader
#获取数据
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#获取数据
test_data = torchvision.datasets.CIFAR10(root='./dataset',transform=torchvision.transforms.ToTensor(),train=False,download=True)
#dataloder的使用
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
writer = SummaryWriter('dataloder')
step = 0
for data in test_loader:
imgs,targets = data
#注意是images
writer.add_images('dataloder',imgs,step)
step+=1
writer.close()
因为这里 b a t c h s i z e batch_size batchsize=64,所以data都是 t o r c h . S i z e ( [ 64 , 3 , 32 , 32 ] ) torch.Size([64, 3, 32, 32]) torch.Size([64,3,32,32])。
d a t a s e t dataset dataset取出数据, d a t a l o a d e r dataloader dataloader将 d a t a s e t dataset dataset中的数据每64个打包成一组。
展示结果:
七、神经网络的基本骨架-nn.Module的使用
7.1 官方文档介绍
官方nn.Module文档

t
o
r
c
h
.
n
n
torch.nn
torch.nn包含了很多的神经网络模块,其中的
C
o
n
t
a
i
n
e
r
s
Containers
Containers(容器)表示的是神经网络的基本骨架。
如其中的
M
o
d
u
l
e
Module
Module,官方解释:
B
a
s
e
c
l
a
s
s
f
o
r
a
l
l
n
e
u
r
a
l
n
e
t
w
o
r
k
m
o
d
u
l
e
s
.
Base\ class\ for\ all\ neural\ network\ modules.
Base class for all neural network modules.
当我们使用
M
o
d
u
l
e
Module
Module时,创建的类都要继承这个类,如下面的代码:
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
#调用父类的初始化,必须有
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
#前向传播
def forward(self, x):
#x-->conv1-->relu-->conv2-->relu-->output
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
7.2 代码实例
尝试一个 + 1 +1 +1功能的神经网络:
import torch
from torch import nn
class Model(nn.Module):
def __index__(self):
super().__init__()
def forward(self,input):
output = input+1
return output
model = Model()
x = torch.tensor(1.0)
output = model(x)
print(output) #tensor(2.)
八、卷积层(Convolution Layers)
t o r c h . n n torch.nn torch.nn是 t o r c h . n n . f u n c t i o n torch.nn.function torch.nn.function的封装。即一个现成的工具( t o r c h . n n torch.nn torch.nn)和零件( t o r c h . n n . f u n c t i o n torch.nn.function torch.nn.function)的关系。
8.1 torch.nn.function.conv2d官方介绍
本小节讨论 2 D 2D 2D的卷积,即函数 c o n v 2 d conv2d conv2d
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
参数:
- i n p u t input input:输入的维度 ( m i n i b a t c h , i n _ c h a n n e l s , i H , i W ) (minibatch,in\_channels,iH,iW) (minibatch,in_channels,iH,iW)
- w e i g h t weight weight:卷积核维度 ( out_channels , in_channels groups , k H , k W ) (\text{out\_channels} , \frac{\text{in\_channels}}{\text{groups}} , kH , kW) (out_channels,groupsin_channels,kH,kW)
- s t r i d e stride stride:滑动的步数。一个数字或者一个数字序列 ( s H , s W ) (sH, sW) (sH,sW)
- p a d d i n g padding padding:填充。可以是字符串{ ‘ v a l i d ’ ‘valid’ ‘valid’, ‘ s a m e ’ ‘same’ ‘same’},或者是一个数字,或者是数字序列 ( p a d H , p a d W ) (padH, padW) (padH,padW)
8.2 代码实例
本小节将实现下面的卷积操作
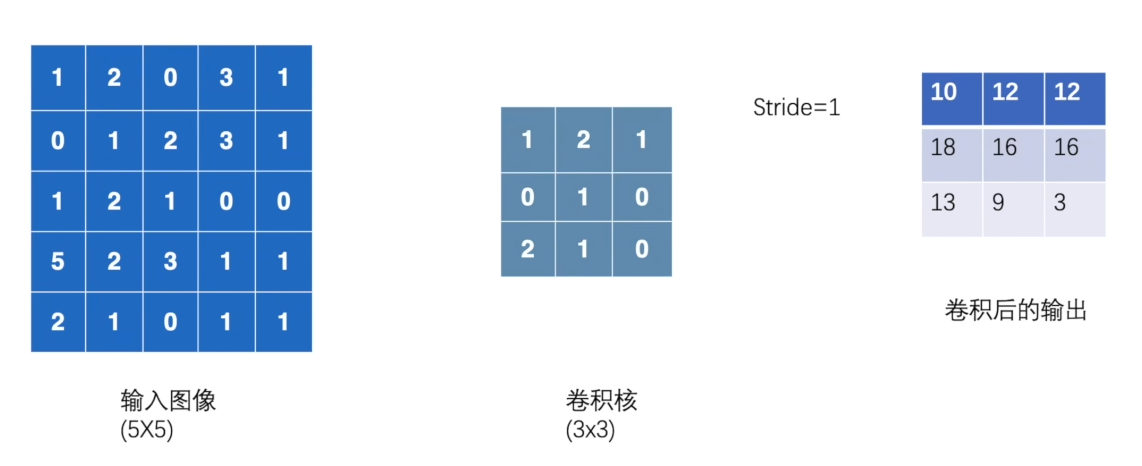
代码:
import torch
import torch.nn.functional as F
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
input = torch.reshape(input,(1,1,5,5))#(1,1,5,5) -- (样本数,通道数,w,h)
kernel = torch.reshape(kernel,(1,1,3,3))#(1,1,3,3) -- (卷积核数目,通道数,w,h)
output = F.conv2d(input,kernel,stride=1)
print(output)
输出结果:
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
8.3 torch.nn.Conv2d官方介绍
官方介绍

参数:
- i n _ c h a n n e l s ( i n t ) in\_channels (int) in_channels(int):输入图像的通道数
- o u t _ c h a n n e l s ( i n t ) out\_channels (int) out_channels(int):输出图像的通道数
- k e r n e l _ s i z e ( i n t o r t u p l e ) kernel\_size (int\ or\ tuple) kernel_size(int or tuple):卷积核尺寸
- s t r i d e ( i n t o r t u p l e ) stride (int\ or\ tuple) stride(int or tuple):滑动步数
- p a d d i n g ( i n t , t u p l e o r s t r ) padding (int, tuple\ or\ str) padding(int,tuple or str):填充方式
- b i a s ( b o o l ) bias (bool) bias(bool):是否为输出结果添加偏置
-
d
i
l
a
t
i
o
n
(
i
n
t
o
r
t
u
p
l
e
)
dilation(int\ or\ tuple)
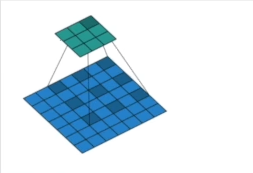
dilation(int or tuple):间隔空隙。如下图中的卷积核覆盖是间隔着距离的
输入维度与输出维度:
- I n p u t : ( N , C i n , H i n , W i n ) o r ( C i n , H i n , W i n ) Input: (N,C_{in},H_{in},W_{in})\ or\ (C_{in},H_{in},W_{in}) Input:(N,Cin,Hin,Win) or (Cin,Hin,Win)
- O u t p u t : ( N , C o u t , H o u t , W o u t ) o r ( C o u t , H o u t , W o u t ) Output:(N, C_{out}, H_{out}, W_{out})\ or\ (C_{out}, H_{out}, W_{out}) Output:(N,Cout,Hout,Wout) or (Cout,Hout,Wout)

8.4 代码实例
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
import torchvision
#获取数据
dataset = torchvision.datasets.CIFAR10('.\dataset',transform=torchvision.transforms.ToTensor(),train=False,download=True)
#抽取数据
dataloder = DataLoader(dataset=dataset,batch_size=64)
#定义卷积模型 x-->conv2d-->output
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv2d = nn.Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
output = self.conv2d(x)
return output
#模型实例化
model = Model()
#使用tensorboard进行可视化
writer = SummaryWriter('./logs')
step = 0
#遍历数据集
for data in dataloder:
imgs,targets = data
#输入前[64,3,32,32]
writer.add_images('input',imgs,step)
#放入模型
outputs = model(imgs)
#输入后[64,6,30,30] 转换成[……,3,30,30]才能可视化
outputs = torch.reshape(outputs,(-1,3,30,30))
writer.add_images('output', outputs, step)
step += 1
writer.close()
展示结果:


九、最大池化的使用
最大池化目的:
保留最大特征同时减小输入维度。
9.1 MaxPool2d官方介绍

参数:
- k e r n e l _ s i z e kernel\_size kernel_size:窗口大小
- s t r i d e stride stride:窗口移动步幅。默认值是 k e r n e l _ s i z e kernel\_size kernel_size
- p a d d i n g padding padding:填充数值
-
c
e
i
l
_
m
o
d
e
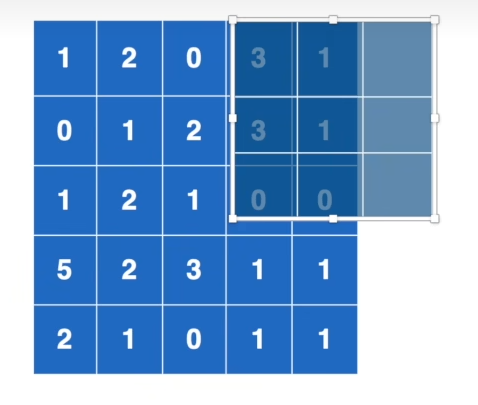
ceil\_mode
ceil_mode:如下图所示,区别在于池化核移动到边缘时,不能完全覆盖输入,是否依然要输出其最大值。
T
r
u
e
True
True则输出,
F
a
l
s
e
False
False不输出。
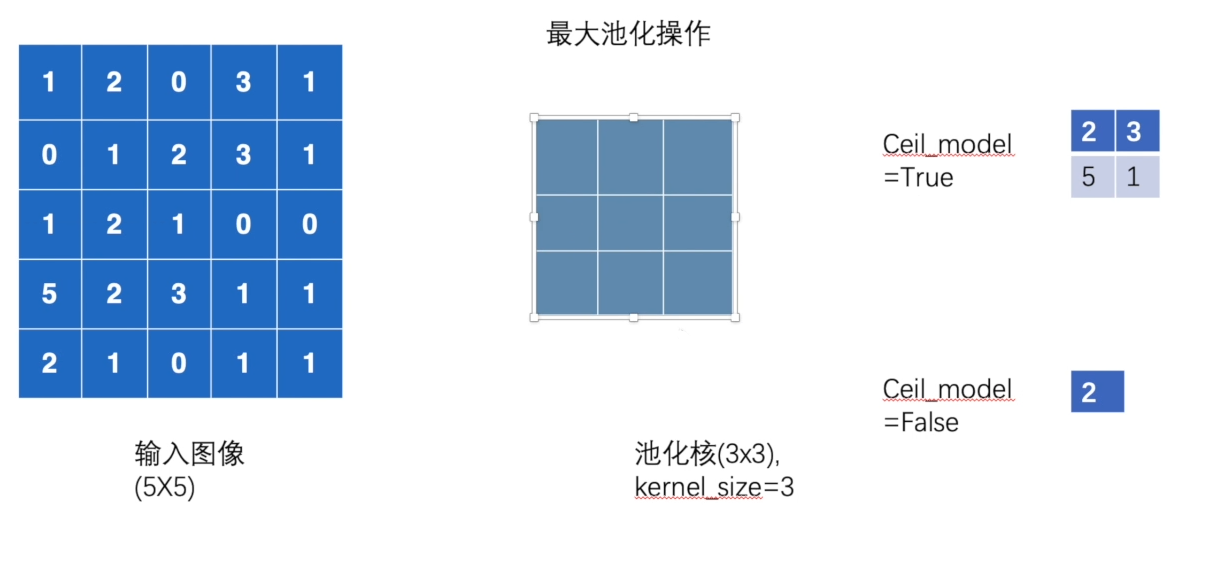
9.2 代码实例
我们要尝试下图的池化计算(注意
k
e
r
n
e
l
_
s
i
z
e
=
3
kernel\_size=3
kernel_size=3,
s
t
r
i
d
e
stride
stride也默认为
3
3
3)
import torch
from torch import nn
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32)
input = torch.reshape(input,(1,1,5,5))#(1,1,5,5) -- (样本数,通道数,w,h)
class Model(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,x):
output = self.maxpool1(x)
return output
model = Model()
output = model(input)
print(output)
'''tensor([[[[2., 3.],
[5., 1.]]]])'''
9.3 最大池化的直观感受
我们对CIFAR10数据集的测试集进行最大池化并可视化结果:
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10('./dataset',train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloder = DataLoader(dataset,batch_size=64)
class Model(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,x):
output = self.maxpool1(x)
return output
model = Model()
writer = SummaryWriter('logs')
step = 0
for data in dataloder:
imgs,targets = data
writer.add_images('input',imgs,step)
output = model(imgs)
writer.add_images('output',output,step)
step+=1
writer.close()
展示结果:
原始输入
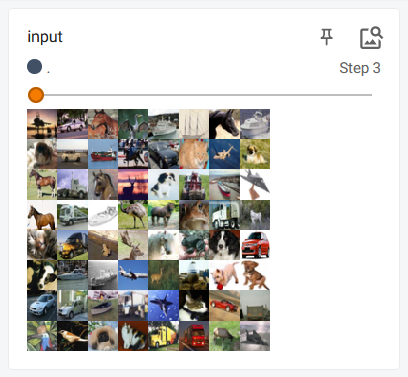
池化后输出:
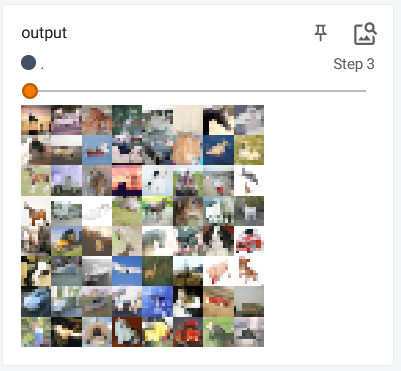
输出的结果变模糊了,有点类似视频的画质。保留图像的大部分特征并缩小图像维度。
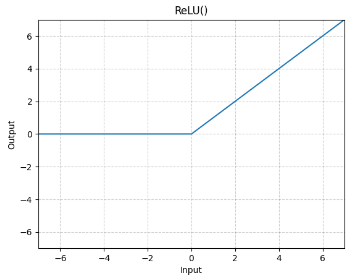
十、非线性激活
非线性函数的目的是为了给网络引入一些非线性特折,非线性特征足够多才能够拟合出符合各种曲线线(各种特征)的模型。
10.1 线性激活官方介绍
官方文档
以
R
e
L
U
ReLU
ReLU为例子
class
torch.nn.ReLU(inplace=False)
参数:
-
i
n
p
l
a
c
e
inplace
inplace:是否替换输入。
如 R e L U ( i n p u t , i n p l a c e = T r u e ) ReLU(input,inplace=True) ReLU(input,inplace=True),这里的 i n p u t input input的值会随着函数的使用而改变,可以不用变量接收返回值。
数学公式:
R
e
L
U
(
x
)
=
(
x
)
+
=
m
a
x
(
0
,
x
)
ReLU(x)=(x)+=max(0,x)
ReLU(x)=(x)+=max(0,x)
输入输出维度:

图像:
10.2 代码实例
import torch
from torch import nn
input = torch.tensor([[1,-0.5],
[-3,2]])
input = torch.reshape(input,(1,1,2,2))#(1,1,2,2) -- (样本数,通道数,w,h)
class Model(nn.Module):
def __init__(self):
super().__init__()
self.relu1 = nn.ReLU()
def forward(self,x):
output = self.relu1(x)
return output
model = Model()
output = model(input)
print(output)
'''
tensor([[[[1., 0.],
[0., 2.]]]])
'''
十一、线性层介绍
官方链接
L
I
N
E
A
R
LINEAR
LINEAR为例子
class
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
参数:
- i n _ f e a t u r e s in\_features in_features:输入特征数(前一层节点数)
- o u t _ f e a t u r e s out\_features out_features:输出特征数(当前层节点数)
- b i a s bias bias:是否添加偏置
l i n e a r linear linear就是计算 y = x A T + b y=xA^T+b y=xAT+b
经典的 L R LR LR算法的结构就是: x − > l i n n e a r − > S o f t m a x − > o u t p u t x->linnear->Softmax->output x−>linnear−>Softmax−>output,即线性层的输出一般作为激活函数的输入。
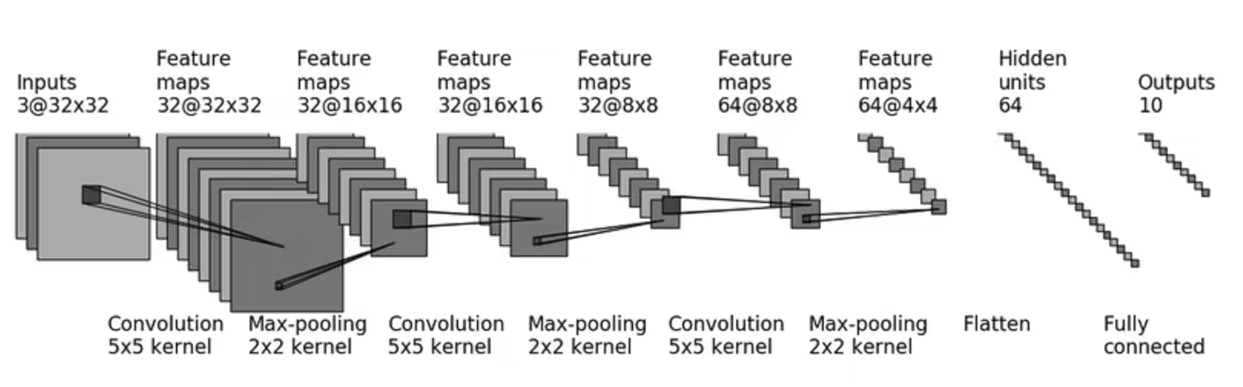
十二、搭建CIFAR-10网络模型
神经网络结构示意图如下:
12.1 不使用Sequential
import torch
from torch import nn
from torch.nn import Conv2d,MaxPool2d,Linear
from torch.nn.modules.flatten import Flatten
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(3,32,5,padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.faltten = Flatten()
self.linear1 = Linear(1024,64)
self.linear2 = Linear(64,10)
def forward(self,x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x= self.faltten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
model = Model()
#检测网络输出
input = torch.ones([64,3,32,32])
output = model(input)
print(output.shape)#torch.Size([64, 10])
要点:
- 对于 p a d d i n g 、 s t r i d e padding、stride padding、stride的确定可以使用公式进行计算
- F l a t t e n ( ) Flatten() Flatten()的引用在 t o r c h . n n . m o d u l e s . f l a t t e n torch.nn.modules.flatten torch.nn.modules.flatten。【本人是 1.4.1 1.4.1 1.4.1版本的 p y t o r c h pytorch pytorch】
- 如果不知道下一层的应该使用什么维度的卷积层,可以在
f
o
r
w
a
r
d
forward
forward里面截断输出上一层的维度。
例如:不知道第一层 F C FC FC输入是多少,可以在 f o r w a r d forward forward里面就前向传播到 f a l t t e n faltten faltten,查看它的输出维度就知道第一层 F C FC FC输入应该是 1024 1024 1024了。
12.2 使用Sequential
S e q u e n t i a l Sequential Sequential使代码更简洁和有序,代码如下:
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear, Sequential
from torch.nn.modules.flatten import Flatten
class Model(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x
model = Model()
#检测网络输出
input = torch.ones([64,3,32,32])
output = model(input)
print(output.shape)##torch.Size([64, 10])
12.3 模型的可视化
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('./logs')
writer.add_graph(model,input)
writer.close()
展示结构如下,双击查看详细结构
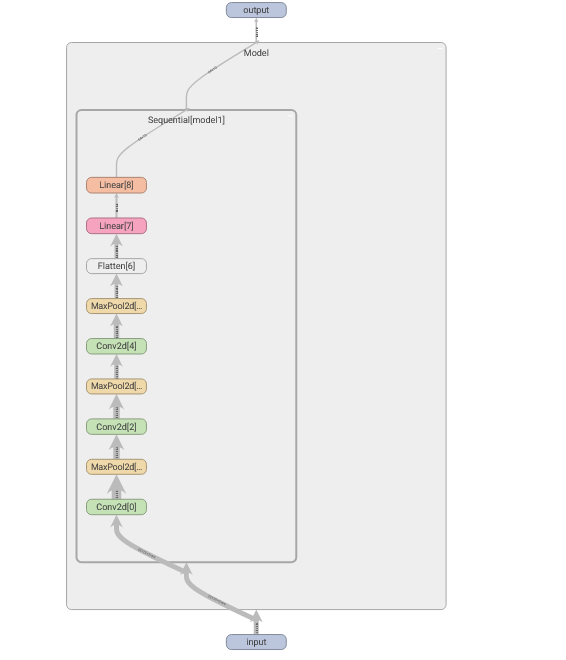
十三、损失函数与反向传播
L o s s Loss Loss的作用:
- 计算实际输出与目标之间的差距
- 为更新输出提供一定的依据(反向传播)
13.1 官方文档介绍
13.1.1 L1Loss
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
ℓ
(
x
,
y
)
=
L
=
{
l
1
,
…
,
l
N
}
⊤
,
l
n
=
∣
x
n
−
y
n
∣
ℓ(x,y)=L=\{l_1,…,l_N\}^⊤,l_n=∣x_n−y_n∣
ℓ(x,y)=L={l1,…,lN}⊤,ln=∣xn−yn∣
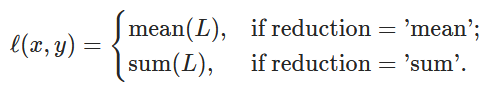
13.1.2 MSELoss
平方差
class
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
ℓ
(
x
,
y
)
=
L
=
{
l
1
,
…
,
l
N
}
⊤
,
l
n
=
(
x
n
−
y
n
)
2
ℓ(x,y)=L=\{l_1,…,l_N\}^⊤,l_n=(x_n−y_n)^2
ℓ(x,y)=L={l1,…,lN}⊤,ln=(xn−yn)2
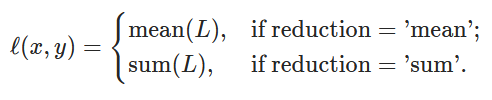
13.1.3 CrossEntropyLoss
一般用于多分类问题, C C C表示分类个数
class
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
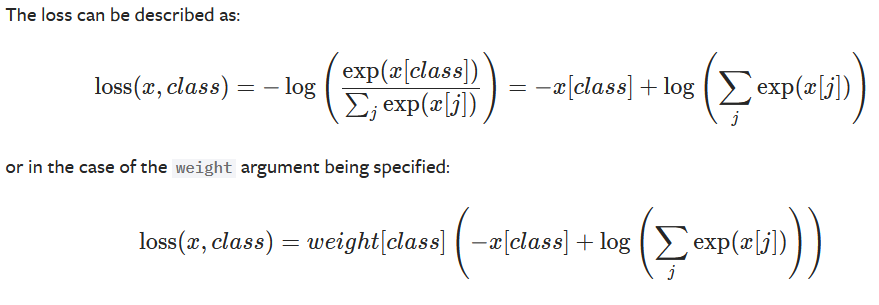
- x x x表示预测结果(多分类问题预测结果是数组)
- c l a s s class class表示真实的分类
- j j j的范围为 [ 0 , ( C − 1 ) ] [0,(C-1)] [0,(C−1)]
13.2 为CIFAR-10网络模型添加损失函数
#获取数据
dataset = torchvision.datasets.CIFAR10('.\dataset',transform=torchvision.transforms.ToTensor(),train=False,download=True)
#抽取数据
dataloder = DataLoader(dataset=dataset,batch_size=64)
#定义模型
model = Model()
#定义损失函数
loss = nn.CrossEntropyLoss()
#一个mini_batch计算一次损失函数
for data in dataloder:
imgs,targets = data
output = model(imgs)
res_loss = loss(output,targets)#损失函数值=loss(预测值,真实值)
print(res_loss)
输出结果:
Files already downloaded and verified
tensor(2.3027, grad_fn=<NllLossBackward>)
tensor(2.3200, grad_fn=<NllLossBackward>)
tensor(2.2939, grad_fn=<NllLossBackward>)
tensor(2.3089, grad_fn=<NllLossBackward>)
tensor(2.3268, grad_fn=<NllLossBackward>)
…………不展示全部输出
添加反向传播:
#一个mini_batch计算一次损失函数
for data in dataloder:
imgs,targets = data
output = model(imgs)
res_loss = loss(output,targets)#损失函数值=loss(预测值,真实值)
#反向传播
res_loss.backward()
在运行
r
e
s
_
l
o
s
s
.
b
a
c
k
w
a
r
d
(
)
res\_loss.backward()
res_loss.backward()之前,
m
o
d
e
l
model
model里面的梯度
g
r
a
d
grad
grad是
N
o
n
e
None
None的,如下图:

在运行之后,梯度
g
a
r
d
gard
gard就被附上了值,如下图:

之后采取优化算法使用这些值来优化模型。
十四、优化器
14.1 官方文档介绍
官方介绍
使用流程:
- C o n s t r u c t i n g i t Constructing\ it Constructing it(构建它):
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
参数:
m
o
d
e
l
.
p
a
r
a
m
e
t
e
r
s
(
)
model.parameters()
model.parameters():模型参数
l
r
lr
lr:学习率
- T a k i n g a n o p t i m i z a t i o n s t e p Taking\ an\ optimization\ step Taking an optimization step(进行优化步骤):
for input, target in dataset:
optimizer.zero_grad()#梯度归0
output = model(input)
loss = loss_fn(output, target)
loss.backward()#计算梯度
optimizer.step()#优化
14.2 为CIFAR-10网络模型添加优化器
如下面代码,在之前的基础上添加了外层 e p o c h epoch epoch迭代,一次迭代遍历一数据集。
优化器的添加要保证这三个的前后次序:
(
1
)
g
r
a
d
清零
−
−
>
(
2
)
反向传播计算
g
r
a
d
−
−
>
(
3
)
优化算法根据
g
r
a
d
执行梯度下降
(1)grad清零-->(2)反向传播计算grad-->(3)优化算法根据grad执行梯度下降
(1)grad清零−−>(2)反向传播计算grad−−>(3)优化算法根据grad执行梯度下降
#获取数据
dataset = torchvision.datasets.CIFAR10('.\dataset',transform=torchvision.transforms.ToTensor(),train=False,download=True)
#抽取数据
dataloder = DataLoader(dataset=dataset,batch_size=64)
#定义模型
model = Model()
#定义损失函数
loss = nn.CrossEntropyLoss()
#优化器
optim = torch.optim.SGD(model.parameters(),lr=0.01)
for epoch in range(20):
running_loss = 0.0
for data in dataloder:
optim.zero_grad() # grad清零
imgs, targets = data
output = model(imgs)
res_loss = loss(output, targets) # 损失函数值=loss(预测值,真实值)
res_loss.backward() # 反向传播计算grad
optim.step() # 优化算法进行梯度下降
running_loss += res_loss
十五、官网模型的加载(浅谈)
15.1 官网介绍
以 V G G 16 VGG16 VGG16为例子:
vgg = torchvision.models.vgg16(pretrained=False, progress=True, **kwargs)
-
p
r
e
t
r
a
i
n
e
d
pretrained
pretrained:是否下载权重进行预训练
当为 T r u e True True时,加载模型过程中会下载官网训练好的权重 - p r o g r e s s progress progress:是否显示进度条
这个模型使用的 I m a g e N e t ImageNet ImageNet数据集很大,官网不提供下载,可以去浏览器搜索资源下载。
在官网查看模型函数介绍时,要选择正确的 t o r c h v i s i o n torchvision torchvision版本,不同版本函数之间存在一定的差异。
15.2 模型的使用与修改
下图是
V
G
G
16
VGG16
VGG16的结构图,最后一层的输出维度是
1000
1000
1000,是一个多分类问题。
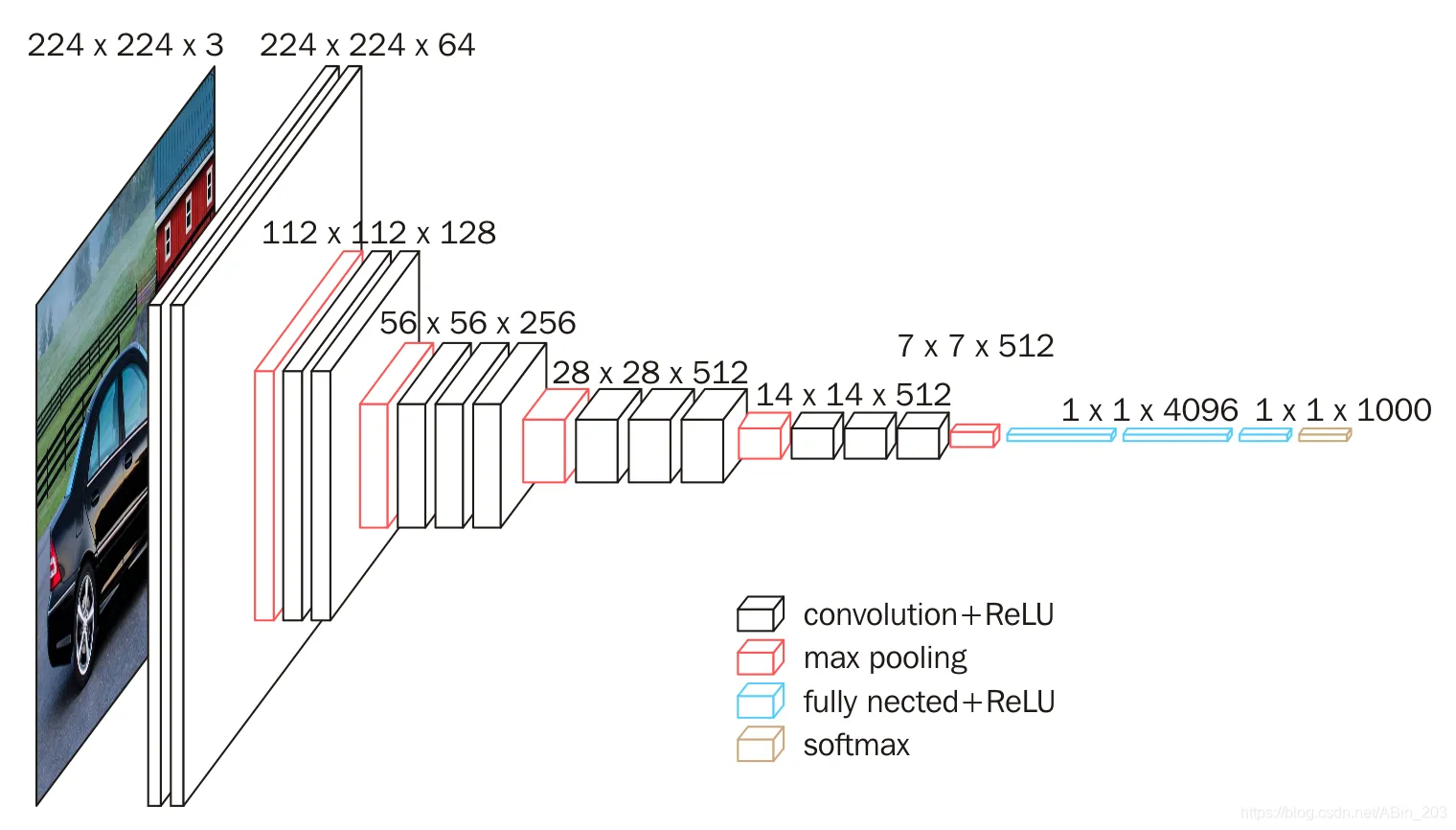
如何修改
V
G
G
16
VGG16
VGG16应用到
C
I
F
A
R
−
10
CIFAR-10
CIFAR−10这个数据集上呢?
- 添加新的输出层,可以添加一个输出维度为 10 10 10的 F C FC FC层
import torchvision
from torch.nn import Linear
vgg16 = torchvision.models.vgg16(pretrained=False,progress=True)
vgg16.add_module('add_linear',Linear(1000,10))
print(vgg16)
输出结果:
看下图红框,网络结构的最后一层成功的添加了一层全连接层。
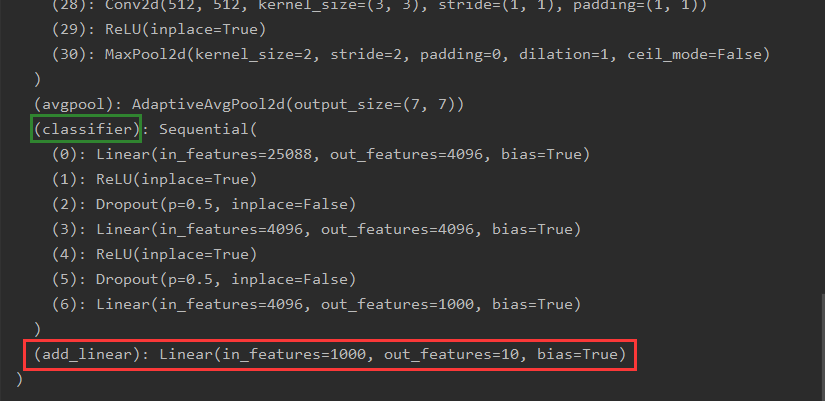
若想把这个 F C FC FC层添加到 c l a s s i f i e r classifier classifier中去,将
vgg16.add_module('add_linear',Linear(1000,10))
- 对原有输出层进行替换
vgg16.classifier[6]=Linear(4096,10)
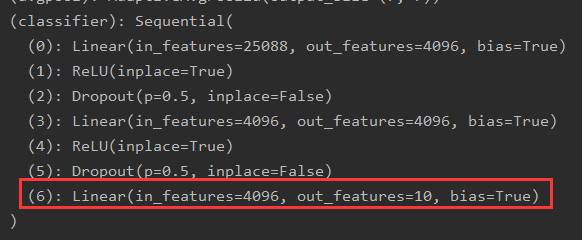
十六、网络模型的保存与读取
第一种方式:
保存模型结构和参数
vgg16 = torchvision.models.vgg16(pretrained=False,progress=True)
#保存方式一
torch.save(vgg16,'vgg16_method1.pth')#(模型,文件名)
#会在文件夹下生成一个vgg16_method1.pth文件,包含模型结构和参数权重
#读取方式一
model = torch.load('vgg16_method1.pth')
第一种方式在保存和读取自己定义的模型时,会有陷阱:
在读取模型时会报错,所以需要把模型
c
l
a
s
s
class
class定义复制到读取的那个
.
p
y
.py
.py文件中。也可以从定义模型
c
l
a
s
s
class
class的那个类
i
m
p
o
r
t
import
import进来。
第二种方式:
保存模型参数(官方推荐)
#保存方式二
torch.save(vgg16.state_dict(),'vgg16_method2.pth')#(模型的状态字典,文件名)
#状态字典中保存了模型的参数权重,不包含网络结构
#读取方式二
vgg16 = torchvision.models.vgg16(pretrained=False,progress=True)#重建网络结构
vgg16.load_state_dict(torch.load('vgg16_method2.pth'))#加载参数字典
十七、完整的模型训练套路
一、加载数据集
#加载数据集
train_data = torchvision.datasets.CIFAR10('./dataset',train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10('./dataset',train=False,transform=torchvision.transforms.ToTensor(),download=True)
train_data_len = len(train_data)
test_data_len = len(test_data)
#打印数据长度
print("训练集数据长度{}".format(train_data_len))
print("训练集数据长度{}".format(test_data_len))
#抽取数据
train_loader = DataLoader(train_data,batch_size=64)
test_loader = DataLoader(test_data,batch_size=64)
二、搭建网络模型与测试
这个网络模型的搭建可以在一个新py文件中定义,需要时从这个 p y py py文件 i m p o r t import import即可
#搭建模型
class Model(nn.Module):
def __init__(self):
super().__init__()
self.model = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
#测试模型输出维度
if __name__ == '__main__':
model = Model()
input = torch.ones((64,3,32,32))
output = model(input)
print(output.shape)
三、定义网络模型、损失函数、优化器与tensorboard的可视化
#创建网络模型
model = Model()
#添加tensorboard
writer = SummaryWriter('./logs')
#损失函数
loss_fn = nn.CrossEntropyLoss()
#优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
#设置网络训练参数
#记录训练次数
total_train_step = 0
#记录测试次数
total_test_step = 0
#训练轮次
epochs = 10
for epoch in range(epochs):
print("----第{}轮训练开始----".format(epoch+1))
for data in train_loader:
imgs,targets = data
outputs = model(imgs)
loss = loss_fn(outputs,targets)
#优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step+=1
if total_train_step%100 == 0:
print("训练次数{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss,total_train_step)
#测试集步骤开始
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():#确保不进行优化,仅测试
for data in test_loader:
imgs,targets = data
outputs = model(imgs)
loss = loss_fn(outputs,targets)
total_test_loss += loss.item()
#正确率计算
accuracy = (outputs.argmax(1)==targets).sum()
total_accuracy += accuracy
print("测试集整体上的正确率:{}".format(total_accuracy/test_data_len))
print("测试集整体上的Loss:{}".format(total_test_loss))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_len, total_test_step)
total_test_step +=1
#模型保存
#torch.save(model,"model_{}.pth".format(epoch))
writer.close()
完整代码
t
r
a
i
n
.
p
y
train.py
train.py:
from torch.utils.data import DataLoader
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
#加载数据集
train_data = torchvision.datasets.CIFAR10('./dataset',train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10('./dataset',train=False,transform=torchvision.transforms.ToTensor(),download=True)
train_data_len = len(train_data)
test_data_len = len(test_data)
#打印数据长度
print("训练集数据长度{}".format(train_data_len))
print("训练集数据长度{}".format(test_data_len))
#抽取数据
train_loader = DataLoader(train_data,batch_size=64)
test_loader = DataLoader(test_data,batch_size=64)
#创建网络模型
model = Model()
#添加tensorboard
writer = SummaryWriter('./logs')
#损失函数
loss_fn = nn.CrossEntropyLoss()
#优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
#设置网络训练参数
#记录训练次数
total_train_step = 0
#记录测试次数
total_test_step = 0
#训练轮次
epochs = 10
for epoch in range(epochs):
print("----第{}轮训练开始----".format(epoch+1))
for data in train_loader:
imgs,targets = data
outputs = model(imgs)
loss = loss_fn(outputs,targets)
#优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step+=1
if total_train_step%100 == 0:
print("训练次数{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss,total_train_step)
#测试集步骤开始
total_test_loss = 0
total_accuracy = 0
#确保不进行优化,仅测试
with torch.no_grad():
for data in test_loader:
imgs,targets = data
outputs = model(imgs)
loss = loss_fn(outputs,targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1)==targets).sum()
total_accuracy += accuracy.item()
print("测试集整体上的正确率:{}".format(total_accuracy/test_data_len))
print("测试集整体上的Loss:{}".format(total_test_loss))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_len, total_test_step)
total_test_step +=1
#模型保存
#torch.save(model,"model_{}.pth".format(epoch))
writer.close()
m o d e l . p y model.py model.py
import torch
from torch import nn
from torch.nn import Sequential,Conv2d,MaxPool2d,Linear
from torch.nn.modules.flatten import Flatten
#搭建模型
class Model(nn.Module):
def __init__(self):
super().__init__()
self.model = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
if __name__ == '__main__':
model = Model()
input = torch.ones((64,3,32,32))
output = model(input)
print(output.shape)
展示结果(没有训练完,太耗时间了,下节使用GPU加速会快很多):
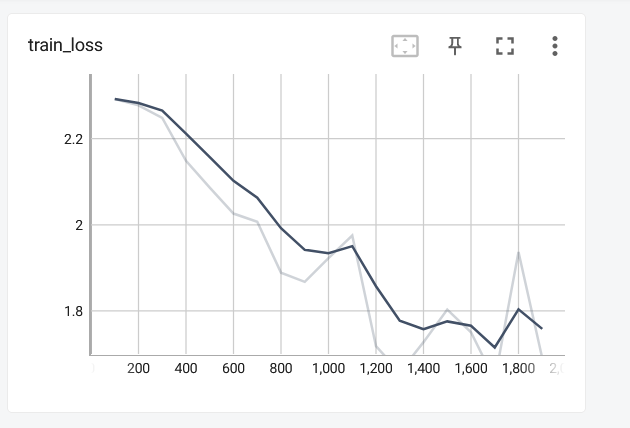
注意:
-
关于 t r a i n ( m o d e = T r u e ) train(mode=True) train(mode=True)和 e v a l ( ) eval() eval():
t r a i n ( ) train() train()表示开启训练,后续代码是进行训练集训练的。
e v a l ( ) eval() eval()表示开启测试,后续代码是进行验证集训练的。
但大部分情况下可以不用添加这两行代码,除非使用了 D r o p o u t , B a t c h N o r m Dropout,BatchNorm Dropout,BatchNorm -
当数字和 t e n s o r tensor tensor进行计算时,要使用 t e n s o r . i t e m tensor.item tensor.item进行计算
十八、使用CPU训练
18.1 第一种方式
在网络模型、数据(输入、标注)、损失函数处加上 . c u d a ( ) .cuda() .cuda()
if torch.cuda.is_available()是为了在gpu和cpu环境下都能跑。
-
第一处:网络模型
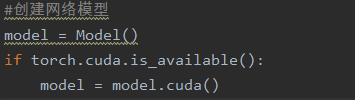
-
第二处:数据(输入、标注)
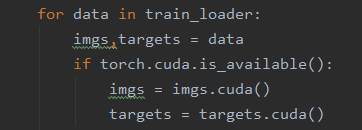
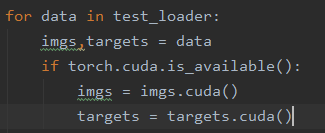
-
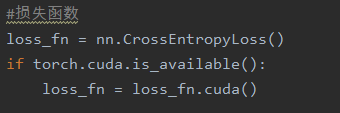
第三处:损失函数处
使用GPU训练速度快了好多。
10个轮次的训练,测试集正确率能达到53%
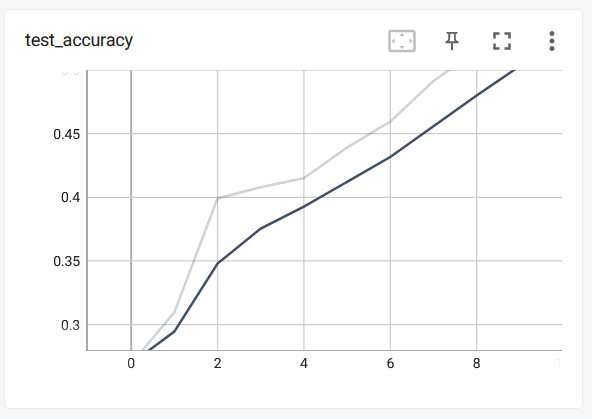
如果电脑上没有不能使用GPU加速,可以使用国外的 G o o g l e c o l a b Google\ colab Google colab或者国内的天池实验室来代跑我们的代码。
18.2 第二种方式
使用 . t o ( d i v i c e ) .to(divice) .to(divice)
- 先在开头定义训练的设备:
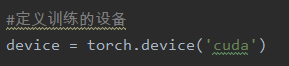
为了确保不能 G P U GPU GPU加速的情况下代码也能使用,可以替换成下面的代码:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
-
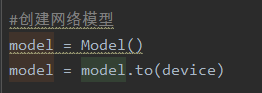
第一处:网络模型
可以不用赋值
-
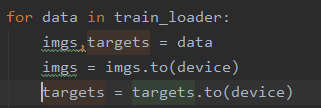
第二处:数据(输入、标注)
可以不用赋值
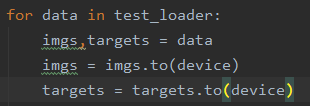
-
第三处:损失函数处

18.3 测试时注意事项
-
使用GPU加速训练的模型,在预测新数据时,要将数据进行转换,如 i m g = i m g . c u d a ( ) img = img.cuda() img=img.cuda()。
-
p n g png png格式是四个通道,除了RGB三通道外,还有一个透明的通道。因此应该使用 i m a g e = i m a g e . c o n v e r t ( ′ R G B ′ ) image = image.convert('RGB') image=image.convert(′RGB′)保留颜色通道。
-
加载训练好的模型时,若 m a p _ l o c a t i o n map\_location map_location报错,应添加 m a p _ l o c a t i o n = t o r c h . d e v i c e ( ′ c p u ′ ) map\_location = torch.device('cpu') map_location=torch.device(′cpu′)【cpu或cuda】
model = torch.load("model_gpu.pth",map_location=torch.device('cpu'))















 1457
1457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









