






前言
随着微服务架构的普及,我们的应用被拆分成越来越多的小服务,部署和运维的复杂度呈指数级增长。如何高效管理这些服务?如何保证它们的高可用?如何实现弹性扩缩容?这些问题一直困扰着技术团队。
容器技术(如 Docker)的出现解决了"环境一致性"的问题,但随之而来的是更大的挑战:如何编排和管理成百上千的容器?
这就是为什么我们需要 Kubernetes(K8S)。K8S 是云原生最核心的内容,也是云计算的未来。
K8S是什么?
Kubernetes(简称K8S)是 Google 基于内部使用的 Borg 系统开源的容器编排平台,它提供了一套完整的容器化应用部署、扩展和管理的解决方案。

K8S 像一个超级智能的"总管家",具备以下能力:
-
自动部署和复制应用容器
-
在容器失败时快速自愈
-
根据负载自动扩缩容
-
管理服务发现和负载均衡
-
编排存储系统
K8S 已成为容器编排的事实标准,主要有三个原因:
-
Google血统:由容器技术的先行者 Google 开发,基于其内部运行数十亿容器的经验
-
开源社区:拥有活跃的开源社区和强大的生态系统
-
声明式API:用户只需声明期望的状态,K8S 会自动调整实际状态以匹配期望状态
K8S核心架构
K8S 采用主从架构,分为控制平面( Control Plane )和数据平面( Data Plane )两部分。
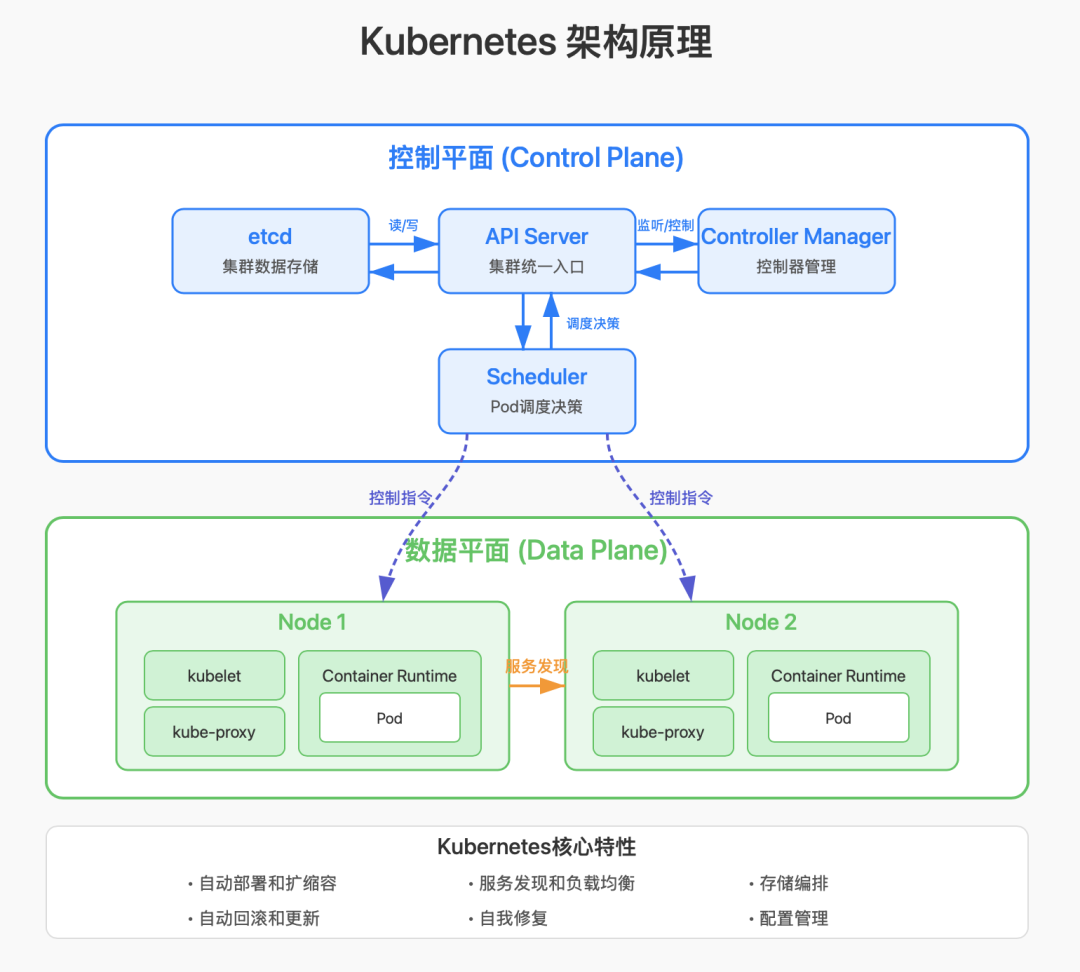
控制平面组件(Master节点)
API Server:所有操作的统一入口,提供 RESTful API
-
验证和处理API请求
-
作为集群状态的唯一真实来源
-
其他组件都通过它监听资源变化
etcd:分布式键值存储系统
-
存储集群所有配置和状态信息
-
高可用、强一致性设计
-
所有组件状态变化都会持久化到 etcd
Controller Manager:控制器管理器
-
运行各种控制器进程(如Node控制器、Replication 控制器等)
-
监控集群状态并维持期望状态
-
处理自动扩缩容、故障检测等任务
Scheduler:调度器
-
为新创建的 Pod 分配最合适的节点
-
考虑资源需求、硬件限制、亲和性规则等因素
-
实现高效的资源利用
数据平面组件(Worker节点)
数据平面主要由 Node 构成,Node 节点是真正运行工作负载的地方。每个Node 节点都包含运行 Pod 所需的所有服务,形成了 K8S 的数据平面。
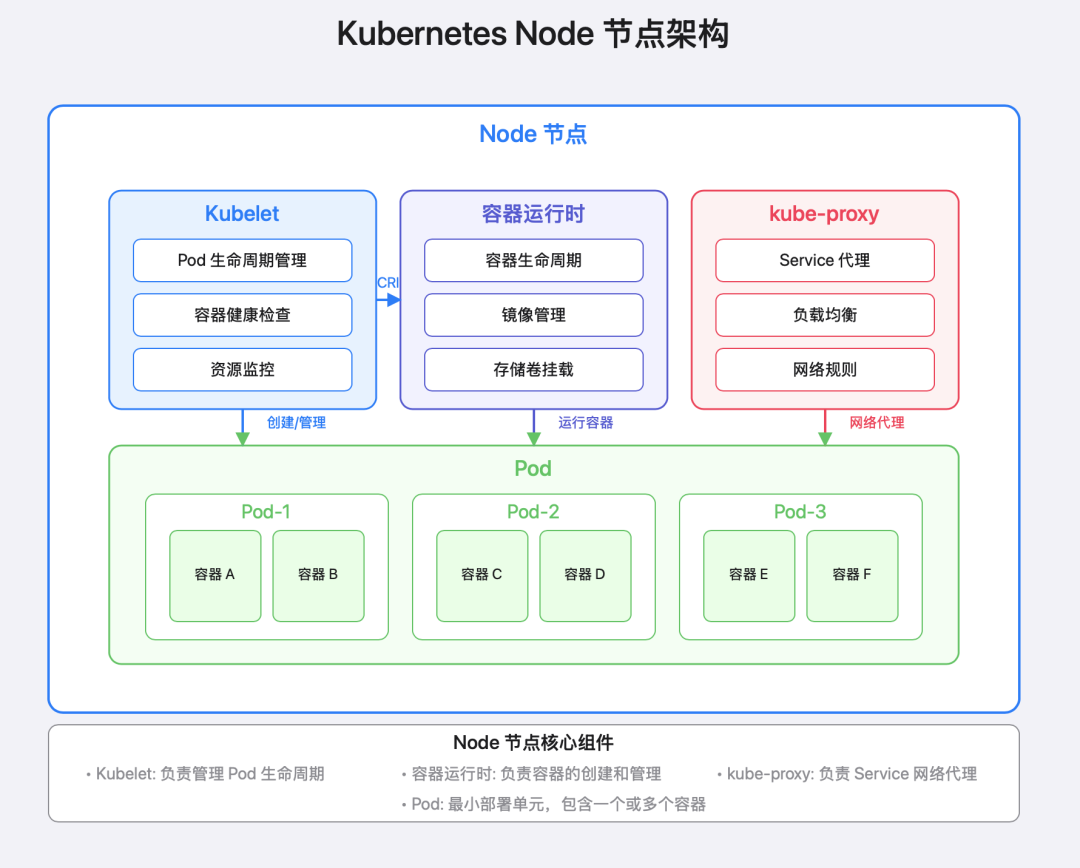
Kubelet:节点代理
-
确保 Pod 中的容器正常运行
-
定期向 API Server 报告节点和 Pod 状态
-
执行容器生命周期钩子
Container Runtime:容器运行时
-
负责运行容器(如 Docker、containerd 等)
-
管理容器的镜像和资源
Kube-proxy:网络代理
-
维护节点网络规则
-
实现 Service 的负载均衡
-
转发或路由流量到正确的容器
K8S工作流程
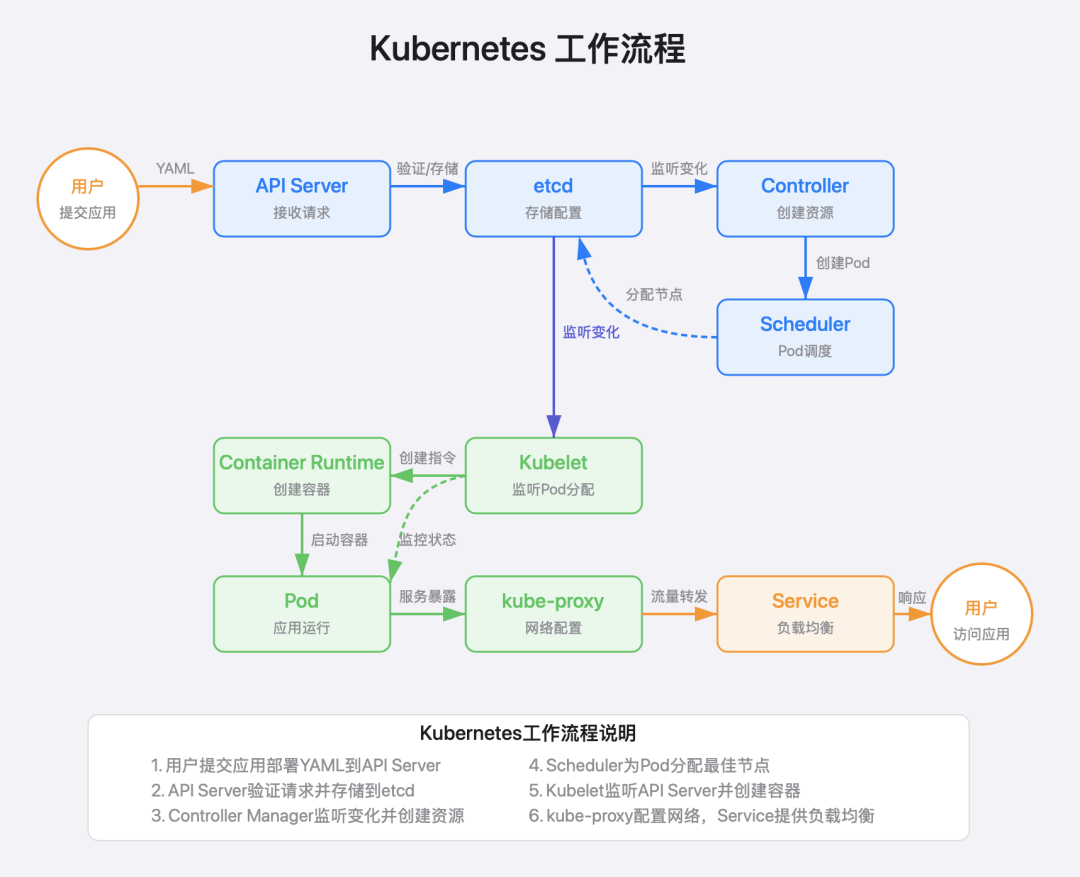
如图所示,当我们向K8S提交一个应用部署请求时,将经历以下流程:
-
用户通过 kubectl 或 API 调用,提交 YAML 文件到 API Server
-
API Server 验证并存储配置到 etcd
-
Controller Manager 监听变化并创建资源(Pod对象等)
-
Scheduler 为 Pod 分配节点
-
Kubelet 监听 API Server 并创建容器
-
Container Runtime 拉取镜像并启动容器
-
Kube-proxy 配置网络规则
-
应用开始运行,对外提供服务,实现负载均衡和服务发现
Pod生命周期与编排逻辑
Pod 是 K8S 中最小的可部署单位,而不是单个容器。一个 Pod 可以包含一个或多个紧密关联的容器,它们:
-
共享网络命名空间(可通过 localhost 互相访问)
-
共享存储卷
-
共享IPC命名空间
-
总是被调度到同一节点上
基于"边车模式"(Sidecar Pattern)设计,允许将主应用容器与辅助容器(如日志收集、数据处理、代理等)组合在一起。
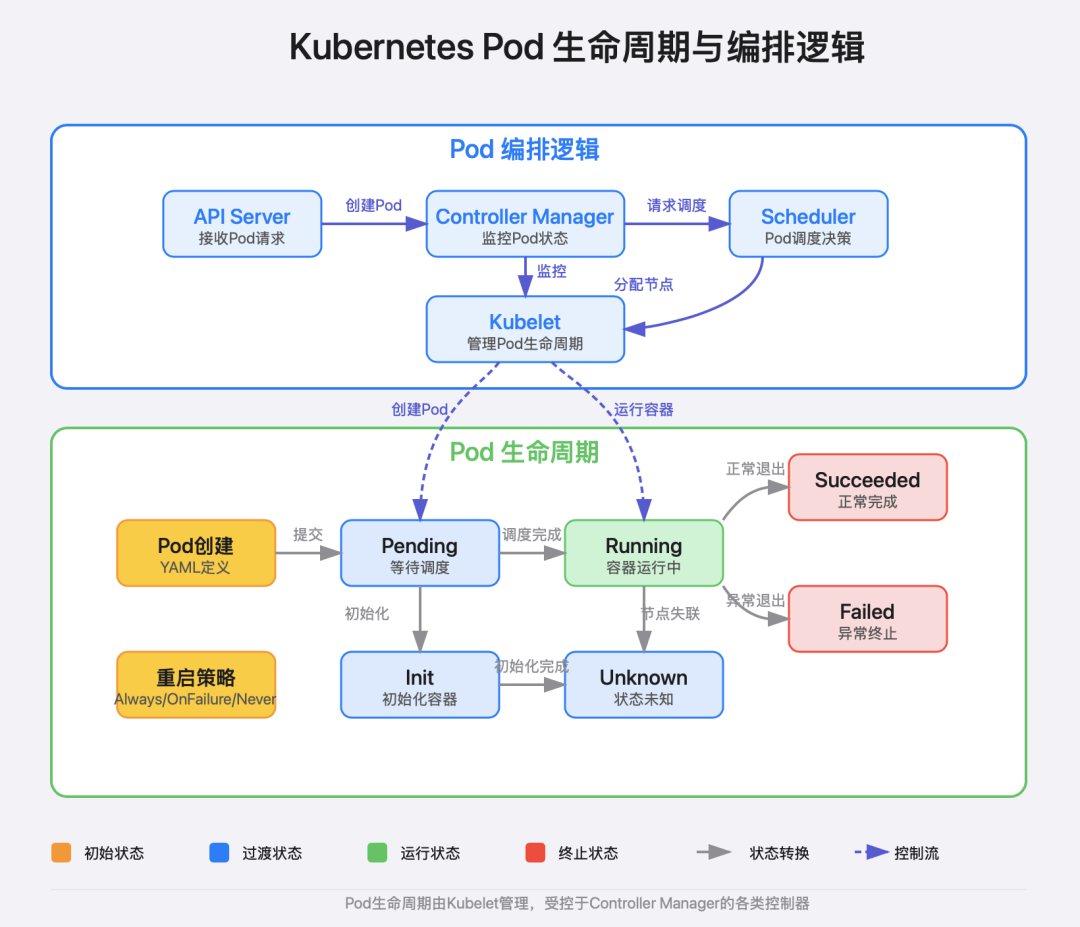
Pod的生命周期
Pod 的生命周期包含以下几个阶段:
-
Pending:已创建但尚未调度到节点,或者正在下载镜像
-
Running:Pod已绑定到节点,所有容器都已创建并至少有一个容器在运行
-
Succeeded:所有容器都已成功终止且不会重启
-
Failed:所有容器都已终止,但至少有一个容器失败退出
-
Unknown:由于某种原因无法获取 Pod 状态
在这个生命周期中,Pod 还可以定义两类钩子:
-
PostStart:容器创建后立即执行
-
PreStop:容器终止前执行
重启策略
K8S 提供了三种重启策略,控制容器失败时的行为:
-
Always(默认):无论容器以何种状态退出都重启
-
OnFailure:只有当容器非正常退出时才重启
-
Never:无论何种情况都不重启容器
K8S编排逻辑
K8S 的核心编排逻辑基于"声明式 API "和"控制循环"两个关键概念。
声明式API
与传统的命令式 API 不同,K8S 采用声明式 API:
-
用户只需描述"期望的状态"(Desired State)
-
K8S 负责确保"实际状态"(Actual State)与期望状态一致
-
系统持续监控并自动调整,无需人工干预
这种方式大大简化了应用管理,用户只需关注"要什么",而不是"怎么做"。
控制循环
K8S 的各个控制器都遵循相同的控制循环模式:
-
观察(Observe):监听资源变化
-
分析(Analyze):比较期望状态和实际状态
-
行动(Act):采取措施消除差异
这个循环不断执行,确保集群始终朝着期望状态演进。例如:
-
如果期望3个 Pod,但只有2个运行,控制器会创建1个新 Pod
-
如果某个节点故障,调度器会将其上的 Pod 重新调度到健康节点
-
如果容器崩溃,Kubelet 会根据重启策略重启容器
K8S实战五大技巧
合理设置资源请求与限制
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"最佳实践:
-
始终设置 requests 和 limits,避免资源争抢
-
CPU limits 设置为 requests 的1.5-2倍
-
基于实际负载测试调整参数,而不是凭感觉
利用健康检查提高可用性
livenessProbe:
httpGet:
path:/healthz
port:8080
initialDelaySeconds:30
periodSeconds:10
readinessProbe:
httpGet:
path:/ready
port:8080
initialDelaySeconds:5
periodSeconds:5最佳实践:
-
livenessProbe 检测应用是否活着,失败会重启容器
-
readinessProbe 检测应用是否就绪,失败会从服务负载均衡中移除
-
startupProbe(K8S 1.16+)用于启动慢的应用,防止过早的健康检查
优化Pod调度策略
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
-matchExpressions:
-key:kubernetes.io/e2e-az-name
operator:In
values:
-e2e-az1
-e2e-az2
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
-weight:100
podAffinityTerm:
labelSelector:
matchExpressions:
-key:app
operator:In
values:
-web-server
topologyKey:"kubernetes.io/hostname"最佳实践:
-
使用 nodeAffinity 将 Pod 调度到特定节点
-
使用 podAntiAffinity 避免关键 Pod 集中在同一节点
-
合理设置污点(Taints)和容忍(Tolerations)隔离特殊工作负载
实现优雅终止
terminationGracePeriodSeconds: 60
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 10; /app/preStop.sh"]最佳实践:
-
设置合理的 terminationGracePeriodSeconds(默认30秒)
-
实现 preStop 钩子处理连接排空
-
应用正确处理 SIGTERM 信号
使用HPA实现自动扩缩容
apiVersion: autoscaling/v2
kind:HorizontalPodAutoscaler
metadata:
name:web-app
spec:
scaleTargetRef:
apiVersion:apps/v1
kind:Deployment
name:web-app
minReplicas:3
maxReplicas:10
metrics:
-type:Resource
resource:
name:cpu
target:
type:Utilization
averageUtilization:80
-type:Resource
resource:
name:memory
target:
type:Utilization
averageUtilization:80最佳实践:
-
基于 CPU 和内存使用率自动扩缩容
-
设置合理的扩缩容阈值,避免频繁波动
-
考虑使用自定义指标(如请求队列长度、响应时间)
总结
Kubernetes 已经成为云原生时代的基础设施标准,掌握它已经成为每个技术人的必备技能。随着技术的发展, K8S 生态也在不断演进:
-
服务网格(如 Istio)增强了微服务治理能力
-
GitOps(如 ArgoCD、Flux)实现了声明式的持续交付
-
无服务器(如 Knative)简化了应用部署和自动扩缩容

















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









