







目录
前言
pipeline是Redis的一个提高吞吐量的机制,适用于多key读写场景,比如同时读取多个key的value,或者更新多个key的value,本篇记录一下pipeline的相关知识,各位看到此博客的小伙伴,如有不对的地方请及时通过私信我或者评论此博客的方式指出,以免误人子弟。多谢!
一、pipeline的作用、注意点
上面说了,pipeline就是为了提高吞吐量的,通常一次命令的消耗时间=一次网络时间 + 命令执行时间,我们都知道redis的性能是很高的,比起命令执行时间,网络时间很可能成为系统的瓶颈,使用pipelline可以将多条命令打包,一次性的发到redis服务,减少了网络请求次数,从而提升吞吐量。既然是通过网络传输命令,那pipeline每次携带的数据了不能过大,否则会占用网络影响网络性能。
二、pipeline与M操作(mget/mset等)区别
- M操作在Redis队列中是一个原子操作,pipeline不是原子操作。
- pipeline与M操作都会将数据顺序的传送顺序地返回(redis 单线程)。
- M 操作一个命令对应多个键值对,而Pipeline是多条命令。
- 原生批命令是服务端实现,而pipeline需要服务端与客户端共同完成。
三、测试pipeline性能
@Test
public void pipeline() {
redisService.flushDB();
long time1 = System.currentTimeMillis();
for (int i = 1; i <= 100000; i++) {
redisService.hset("key-" + i, "field-" + i, "value-" + i);
}
long time2 = System.currentTimeMillis();
System.out.println(time2 - time1);
redisService.flushDB();
long time3 = System.currentTimeMillis();
Pipeline pipeline = redisService.pipeline();
for (int i = 1; i <= 100; i++) {
for(int j = 0 ; j < 1000 ; j++ ) {
pipeline.hset("key-" + i + j, "field-" + i + j, "value-" + i + j);
}
pipeline.sync();
}
long time4 = System.currentTimeMillis();
System.out.println(time4 - time3);
}如上,使用pipeline将100000条命令分为100次每次发送1000条,运行结果如下:
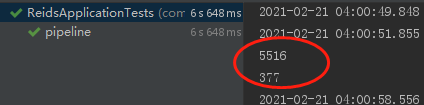















 3878
3878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









