







目录
前言
关于索引,经常有人把它比作字典,或者图书馆的目录,当我们想查一个字或者一本书的时候可以根据目录快速查找到想要的字或者某一本书,但是为什么通过索引查询就快了呢?咱们类比的这个字典到底是个什么呢,之前我是模模糊糊的有点印象的,为了加深下印象整理一篇博客记录一下,希望看到这篇博客的小伙伴,以后再有人问你的时候,不要只告诉人家索引就是一本字典,各位看到此博客的小伙伴,如有不对的地方请及时通过私信我或者评论此博客的方式指出,以免误人子弟。多谢!
什么是索引
从博客上一搜,关于索引的定义有很多不通的描述,以下是我找到的两种相对准确的描述方式:
- 索引是一种数据结构[排好序的],能够帮助我们快速的检索数据库中的数据。
- 数据库省之外,数据库还维护着一个满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构的基础上实现高级查找算法,这种数据结构就是索引。
上一篇mysql体系结构、存储文件和sql语句的执行流程说到,索引保存在磁盘中文件里的,结合上面两条,其实索引就是保存在磁盘中的,高效查询的一种数据结构。这种数据结构(如:B+Tree)将我们的数据按照某一规则排好序,将随机io变为顺序io,利于数据的查询。
索引的数据结构
Mysql的默认存储引擎为InnoDB,而InnoDB使用的数据结构是B+Tree,为什么选用B+Tree,B+Tree相比于其他常见几种数据结构有什么好处呢,这里简单记录一下我的理解。
二分查找法
在说数据结构之前先看下二分查找法,也称为折半查找法,顾名思义就是每次查找都可以讲查询范围减半。
基本思想是:将记录按有序化(递增或递减)排列,在查找过程中采用跳跃式方式查找,即先以有序数列的中点位置作为比较对象,如果要找的元素值小于该中点元素,则将待查序列缩小为左半部分,否则为右半部分。通过一次比较,将查找区间缩小一半。网上找了一个例子:
# 给出一个例子,注意该例子已经是升序排序的,且查找数字 48
数据:5, 10, 19, 21, 31, 37, 42, 48, 50, 52
下标:0, 1, 2, 3, 4, 5, 6, 7, 8, 9
- 步骤一:设 low 为下标最小值0,high 为下标最大值9。
- 步骤二:通过 low 和 high 得到 mid,mid=(low + high) / 2,初始时 mid 为下标4,也可以是5,看具体算法实现。
- 步骤三:mid = 4对应的数据值是31,31 < 48(我们要找的数字)。
- 步骤四:通过二分查找的思路,将 low 设置为31对应的下标4,high 保持不变为9,此时 mid 为6。
- 步骤五:mid = 6对应的数据值是42,42 < 48(我们要找的数字)。
- 步骤六:通过二分查找的思路,将 low 设置为42对应的下标6,high 保持不变为9,此时 mid 为7。
- 步骤七:mid = 7对应的数据值是48,48 == 48(我们要找的数字),查找结束。
通过3次二分查找就找到了我们所要的数字,而顺序查找需8次。
二叉查找树(Binary Search Tree)
二叉树跟二分的有点类似,它的每个节点的左节点值小于跟节点(中间值--类似二分查找法mid位置的值),而右节点值大于跟节点。看下它的定义:
二叉查找树(英语:Binary Search Tree),也称为二叉搜索树、有序二叉树(ordered binary tree)或排序二叉树(sorted binary tree),是指一棵空树或者具有下列性质的二叉树:
- 若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值。
- 若任意节点的右子树不空,则右子树上所有节点的值均大于它的根节点的值。
- 任意节点的左、右子树也分别为二叉查找树。
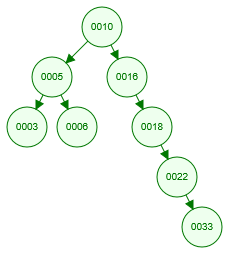
查找过程:假设该二叉查找树保存的是 id 索引,我们要检索一条 id=8 的数据,它会一个节点一个节点比对,首先把根节点(第一条插入的数据就是根节点)加载到内存中比对,8比10要小,这个时候会找10左边的节点,再把5加载到内存中比对,5比8要小,继续找5右边的节点,最后找到8这个节点。
补充一下:如果值相同,二叉树会向右节点插入,顺序向下一层比较。看下图:
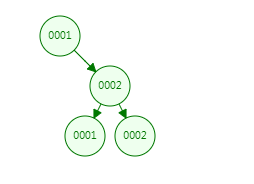
第一次:插入1 ,就一个值,它就是跟节点。
第二次:插入2,发现比1大,走右子树。
第三次:插入2,跟1比较,发现比1大,走右子树;跟2比,发现值相同,相同的情况下,走右子树。
第四次:插入1,跟1比较,发现值相同,相同的情况下,走右子树;再跟2比较,比二小,走左子树。
最终形成上面这颗二叉树。
二叉树的问题
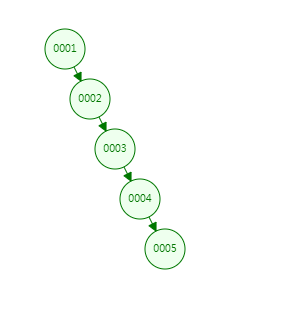
如上,当我们插入的数据是递增或者递减的时候,它会退化成链表,那它的检索效率和全表扫描一样了,没有任何变化。
平衡二叉查找树(Balanced Binary Tree)
为解决二叉树退化成链表问题,有了平衡二叉树,看下它的定义:平衡二叉搜索树(英语:Balanced Binary Tree)是一种结构平衡的二叉搜索树,即叶节点高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。当平衡二叉查找树发生节点变更时,基于每个节点的平衡因子,通过一次或多次左旋和右旋来达到树新的平衡。
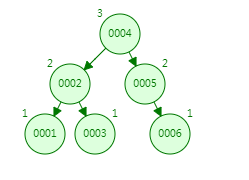
以上图的平衡二叉树为例,说下它的执行过程:
第一次:插入1 ,就一个值,它就是跟节点。
第二次:插入2,发现比1大,走右子树。
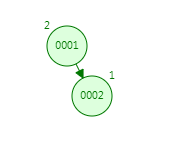
第三次:插入3,跟1比较,发现比1大,走右子树;跟2比,发现比2大,走右子树,平衡二叉树规定叶节点高度差的绝对值不超过1,现在右节点的高度为3,没有左节点(高度为0),绝对值大于1,那它会通过旋转达到平衡。
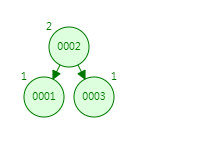
第四次:插入4,跟2比较,发现比2大,走右子树;跟3比较,发现比3大,走右子树。
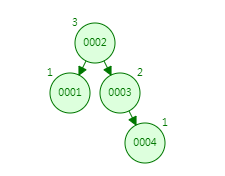
第五次:插入5,跟2比较,发现比2大,走右子树;跟3比较,发现比3大,走右子树;跟4比较,发现比4大,走右子树;现在右节点的高度为4,左节点高度为2,绝对值大于1,那它会通过旋转达到平衡。
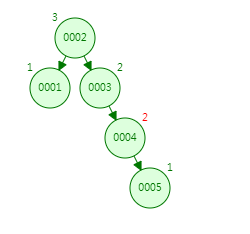
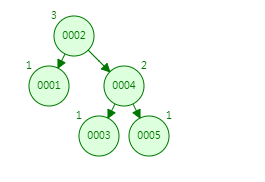
第六次:插入6,跟2比较,发现比2大,走右子树;跟4比较,发现比4大,走右子树;跟5比较,发现比5大,走右子树;现在右节点的高度为4,左节点高度为2,绝对值大于1,那它会通过旋转达到平衡。
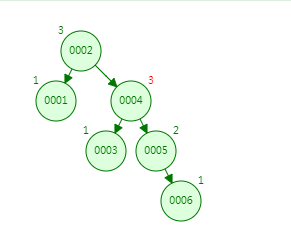
最终就是这样了:
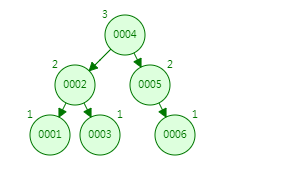
这只是演示数的生成,实际上数据存储在磁盘中,而磁盘块即是上面树中一个节点的保存位置,每个节点有三块数据内容:关键字、数据区、子节点引用。如下:从网上找了一张图,

关键字:比如我们用 ID 作为索引,那这里保存的就是 ID 内容。
数据区:可以是数据的磁盘位置,可以是真正的数据内容。
子节点引用:比如跟节点10的 P1 引用指向的是5节点,P2 引用指向的是20节点,基于 P1 和 P2 就可以通过顺序 IO 的方式加载子节点磁盘块的内容到内存中。
平衡二叉查找树的问题
太深了:数据处的深度决定着它的 IO 操作次数,IO 操作耗时大。随着数据增多,树的高度越来越高。
太小了:每一个磁盘块(节点/页)保存的数据量太小了,现在只是携带了一个数据,其实mysql的一页数据是16K,想想16K存储一个数据是不是太浪费了。
上面两种树都是二叉的,树叉越多,同样高度的数存储的数据就越多,每个磁盘块存储的数据越多,存储的数据也就越多,下面说下多路平衡查找树:B-Tree和B+Tree。
多路平衡查找树(B-Tree)
看下B-Tree这种多路平衡树的特点,m 阶 B-Tree 满足以下条件:
- 每个节点最多拥有 m 个子树。
- 根节点至少有2个子树。
- 分支节点至少拥有 m/2 颗子树(除根节点和叶子节点外都是分支节点)。
- 所有叶子节点都在同一层、每个节点最多可以有 m-1 个 key,并且以升序排列。
上面可能不太好理解,其实就是说m阶(如3阶,也可以说3路),就以3路来说吧,每个节点数据量不能超过3个,大于等于三个的时候会向上分裂,分裂的原则是三个值中间大小的向上一层。以3路 B-Tree树看下它的构建过程:
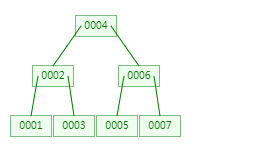
第一次:插入1 ,节点中一个值,少于3。
第二次:插入2,节点中两个值,少于3。
第三次:插入3,节点中三个值,大于等于3,需要分裂,123中2是中间数,所以2向上分裂。
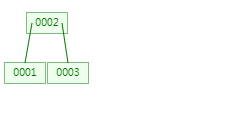
第四次:插入4,跟2比较,发现比2大,走右子树,进入到右子树节点中,此时节点中两个值,少于3。
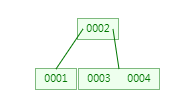
第五次:插入5,跟2比较,发现比2大,走右子树,进入到右子树节点中,此时节点中三个值345,345中4是中间数,所以4向上分裂。
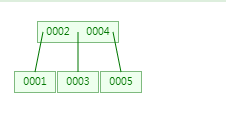
第六次:插入6,跟4比较,发现比4大,走右子树,进入到右子树节点中,此时节点中两个值,少于3。
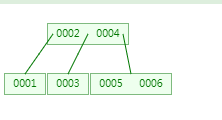
第七次:插入7,跟4比较,发现比4大,走右子树,进入到右子树节点中,此时节点中三个值567,567中6是中间数,所以6向上分裂,而上层节点中已经有24两个值,分裂后节点中有246三个值,大于3,需要再次向上分裂,而246中4是中间数,所以4向上分裂。
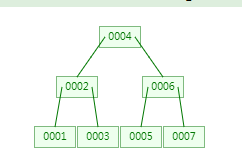
以上就是树的构建过程,下面看下从网上找的的一张磁盘中数据在B-Tree中的存储示例图:
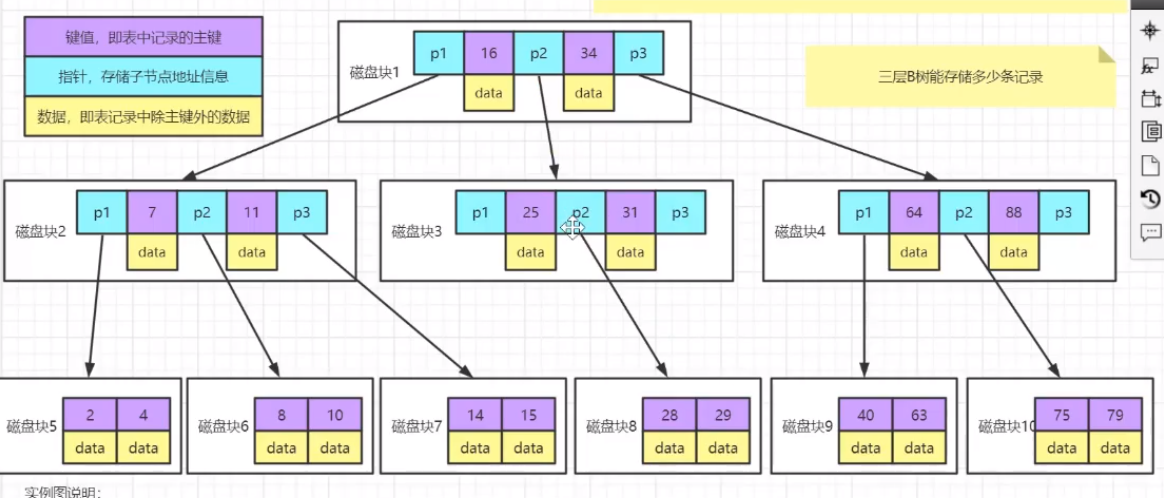
对比平衡二叉查找树,同样最多三次 IO 操作,B树最多可以检索到的数据量是22条数据(上面网上找的图中只有20条,不要介意),而平衡二叉查找树最多可以检索到的数据量是8条,当多路平衡二叉查找树的路数越多,在 IO 操作次数相同的情况下,它能检索的数据量越多。
每个磁盘块中存储的键值,指针和数据当中,数据是最占用空间的,想一下,一个表要是有10列,如键值中存表的主键id,data区要放置其它的9列数据,而且你id可以采用int这种类型,那其它列不能都是int吧,少不了varchar,datetime等其它类型,就拿varchar来说,是不是就比int占用空间多。
由上面分析我们得出结论:
- 字段的长度要设定的比较合理,能短则短,否则如果我们把这个字段作为索引,它会影响 B-Tree 的高度,进而影响索引的检索效率。
- 要合理的设置mysql的字段长度,增加mysql每一页数据存储的数据量,减少io次数。
另外,我们不能建过多的索引,会拖慢 MySQL 的新增、更新、删除操作,因为每次数据变更,都会对所有的索引数据进行节点的变更。
既然data区是最占用空间的,那能不能不存储data只存键值和指针呢,为此有了B+Tree。
加强版多路平衡查找树(B+Tree)
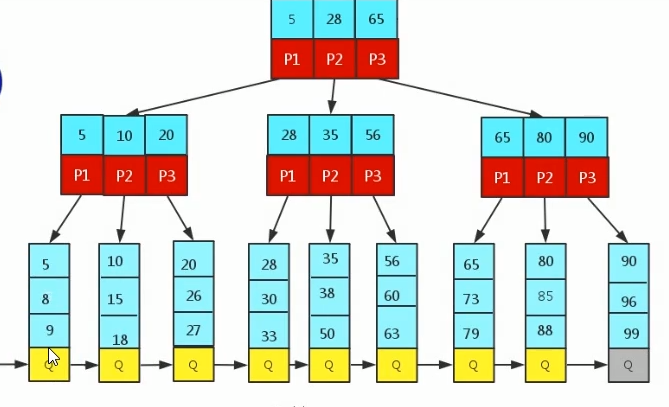
B+Tree 是在 B-Tree 基础上的一种优化,从 B-Tree 结构图中可以看到每个节点中不仅包含数据的 key 值,还有 data 值。而每一个页的存储空间是有限的,如果 data 数据较大时将会导致每个节点(即一个页)能存储的 key 的数量很小,当存储的数据量很大时同样会导致B-Tree 的深度较大,增大查询时的磁盘 I/O 次数,进而影响查询效率。在 B+Tree 中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储 key 值信息,这样可以大大加大每个节点存储的 key 值数量,降低 B+Tree 的高度。
InnoDB 存储引擎就是用 B+Tree 实现其索引结构,mysql对B+Tree又进行了进一步的优化,在原B+Tree基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高了区间访问的性能。
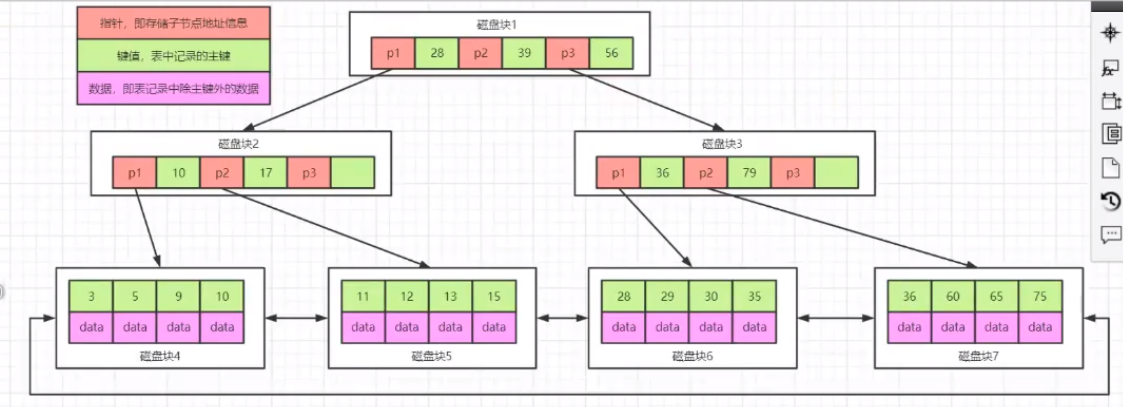
B+Tree 相对于 B-Tree 有几点不同:
- n叉B+Tree 最多n个key,而BTree最多n-1个key。
- B+Tree 非叶节点不保存数据相关信息,只保存关键字和子节点的引用。
- B+Tree 叶子节点保存所有的key信息,依照key大小顺序排列。
- 叶子节点中的数据在物理存储上是无序的,仅仅是在逻辑上有序(通过指针串在一起,可以是双向链表)。
为什么选用 B+Tree
- B+Tree 扫库、表能力更强:如果要从 B-Tree 中扫描表数据的话,基本要把整棵树都要扫描一遍,因为每个节点都存在数据区。B+Tree 就不需要扫描整棵树,只需要扫描叶子节点就可以了。
- B+Tree 的磁盘读写能力更强:B+Tree 的节点上是不保存数据的,那么它保存的关键字就更多,这样一次 IO 操作,加载的关键字就更多,所以它的磁盘读写能力更强。
- B+Tree 的排序能力更强:B+Tree 的叶子节点天然就是顺序存放的。
B+Tree 的特性
- 在块设备上,通过 B+Tree 可以有效的存储数据。
- 所有记录都存储在叶子节点上,非叶子(non-leaf)存储索引(keys)信息。
- B+Tree 含有非常高的扇出(fanout),通常超过100,在查找一个记录时,可以有效的减少 IO 操作。
B+Tree 存储数据量计算
在计算前,先了解几个概念:
扇出是每个索引节点(Non-LeafPage)指向每个叶子节点(LeafPage)的指针。
扇出数 = 索引节点(Non-LeafPage)可存储的最大关键字个数 + 1。
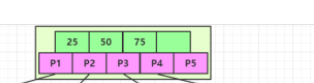
如上:每叶子页(LeafPage)4条记录,扇出树为5。下面开始计算:
假设 B+Tree 中页的大小是 16K,每行记录是 200Byte 大小,求出树的高度为1,2,3,4时,分别可以存储多少条记录。
高度为1时:
16K/200B 约等于 80 个记录(数据结构元信息如指针等忽略不计)。
高度为2时:
非叶子节点中存放的仅仅是一个索引信息,包含了 Key(索引键值) 和 Point 指针;Point 指针在 MySQL 中固定为 6Byte。而 Key 我们这里假设为 8Byte,则单个索引信息即为14个字节,KeySize = 14Byte。
高度为2,即有一个索引节点(索引页),和 N 个叶子节点。
一个索引节点可以存放 16K / KeySize = 16K / 14B = 1142个索引信息,即有(1142 + 1)个扇出,以及有(1142 + 1)个叶子节点(数据页),可以简化为1000。
数据记录数 = (16K / KeySize + 1)x (16K / 200B) 约等于 80W 个记录。
高度为3时:
高度为3的 B+Tree,即 ROOT 节点有1000个扇出,每个扇出又有1000个扇出指向叶子节点。每个节点是80个记录,所以一共有 8000W个记录。
高度为4时:
同高度3一样,高度为4时的记录书为(8000 x 1000)W。
上述的 8000W 等数据只是一个理论值。线上实际使用单个页的记录数字要乘以 70%,即第二层需要 70% x 70% ,依次类推。
因此在数据库中,B+Tree 的高度一般都在2~4层,这也就是说查找某一键值的行记录时最多只需要2到4次 IO,2~4次的 IO 意味着查询时间只需0.02~0.04秒(假设 IOPS=100,当前 SSD 可以达到 50000IOPS)。














 1223
1223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









