







Hadoop入门介绍
Hadoop背景介绍
发展钱途

什么是Hadoop
- HADOOP是apache旗下的一套开源软件平台
- HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
- HADOOP的核心组件有
A. HDFS(分布式文件系统)
B. YARN(运算资源调度系统)
C. MAPREDUCE(分布式运算编程框架) - 广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
Hadoop hive hbase flume kafka sqoop spark flink …….
Hadoop产生背景
- HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
- 2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。 - Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
Hadoop生态圈
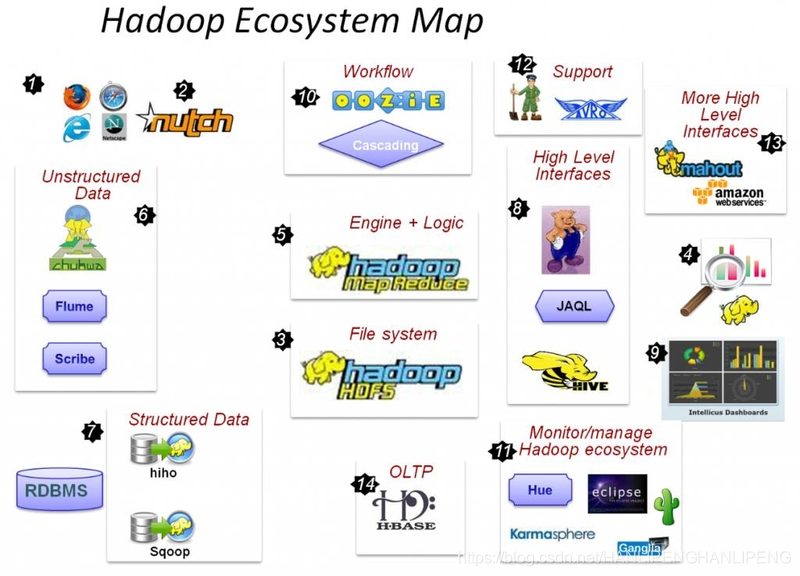
国内应用
用户画像

HADOOP用于网站点击流日志数据挖掘
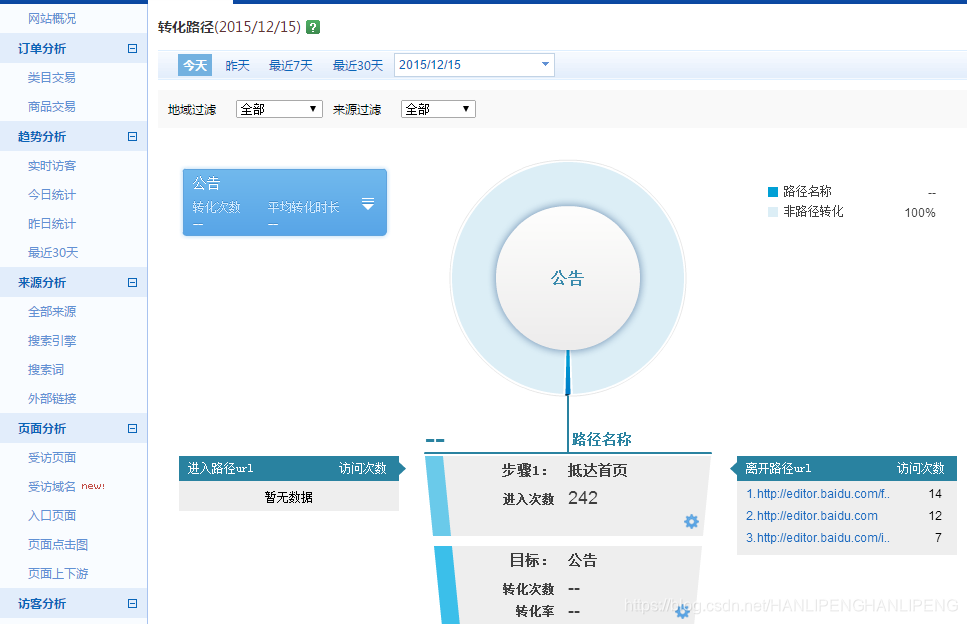
大屏展示
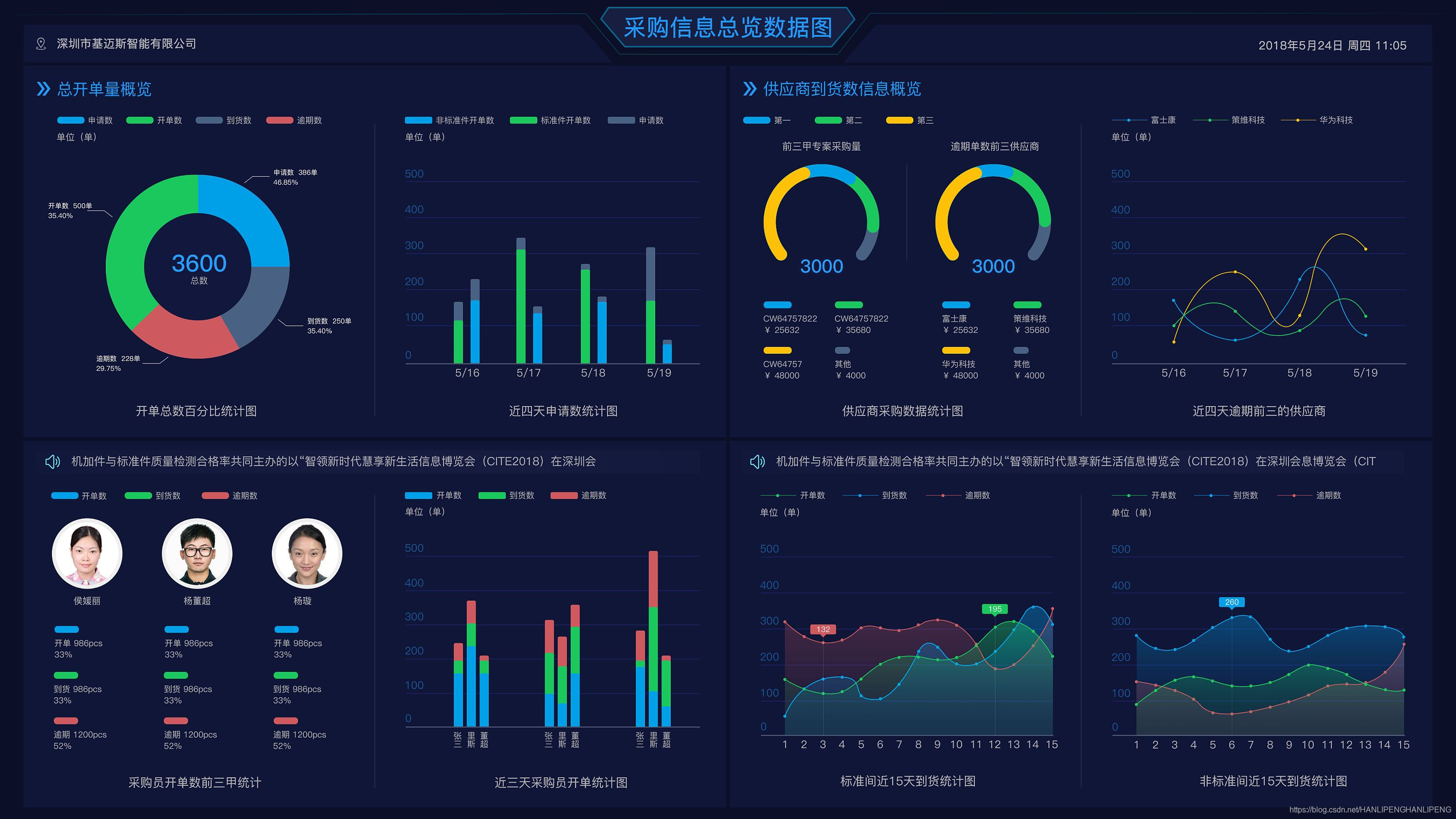

离线数据分析
web日志数据挖掘

案例需求描述
“Web点击流日志”包含着网站运营很重要的信息,通过日志分析,我们可以知道网站的访问量,哪个网页访问人数最多,哪个网页最有价值,广告转化率、访客的来源信息,访客的终端信息等。
数据来源
获取方式:在页面预埋一段js程序,为页面上想要监听的标签绑定事件,只要用户点击或移动到标签,即可触发ajax请求到后台servlet程序,用log4j记录下事件信息,从而在web服务器(nginx、tomcat等)上形成不断增长的日志文件。
形如:
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
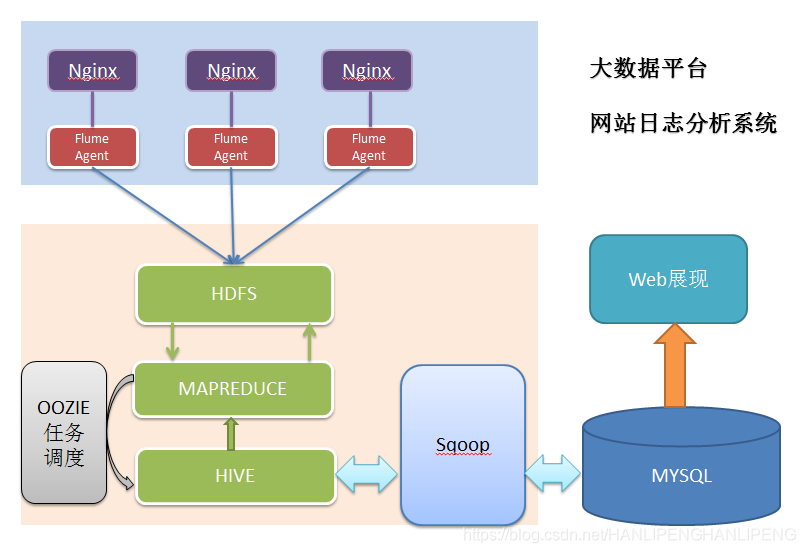
流程解析
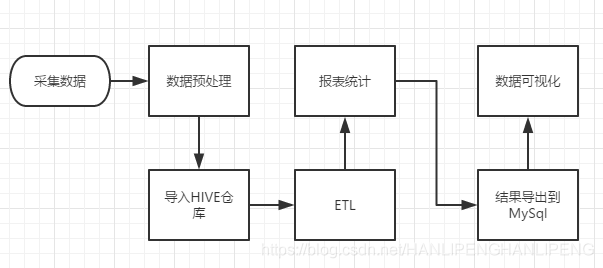
- 数据采集:定制开发采集程序,或使用开源框架FLUME
- 数据预处理:定制开发mapreduce程序运行于hadoop集群
- 数据仓库技术:基于hadoop之上的Hive
- 数据导出:基于hadoop的sqoop数据导入导出工具
- 数据可视化:定制开发web程序或使用kettle等产品
- 整个过程的流程调度:hadoop生态圈中的oozie工具或其他类似开源产品
项目架构图
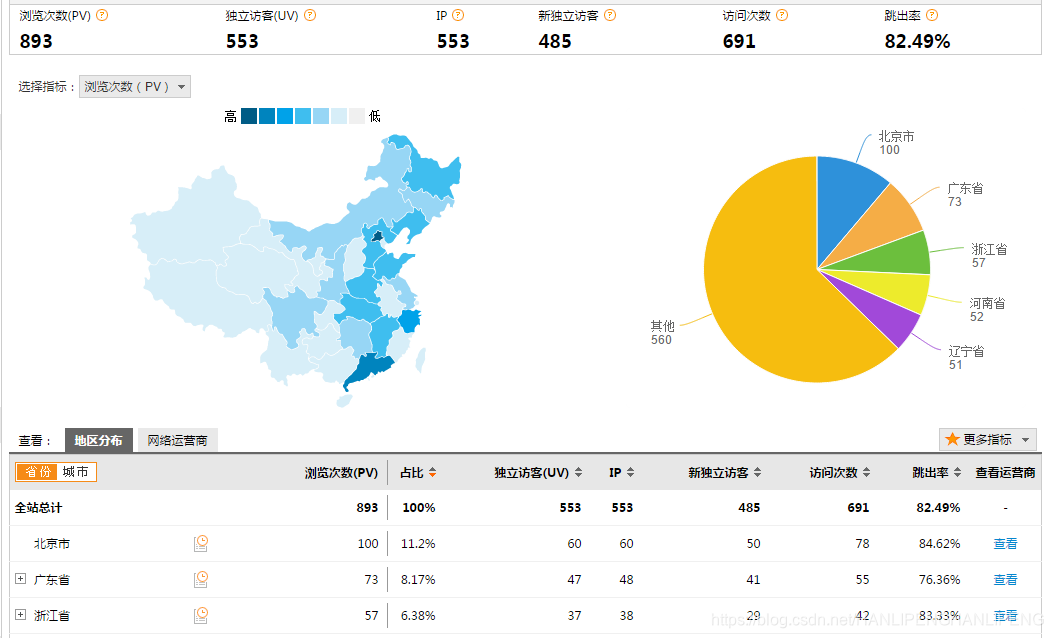
项目效果图
本文由鹏鹏出品














 351
351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









