






Redis
文章目录
一. 基础理论
1. 什么是Redis:
Redis,即 远程字典服务
是一个免费且开源使用ANSI C语言编写 支持网络 可基于内存亦可持久化的日志型 key-value数据库
并提供多种语言的API 是当下最热门的NoSQL技术之一 也被人们称之为结构化数据库
2.Redis能干嘛?
- 内存存储,持久化 内存中是断电即失 持久化很重要 持久化方案(rdb aof)
- 效率高 可以用于高速缓存
- 发布订阅系统
- 地图信息分析
- 计时器,计数器
3.Redis 的特性
- 多样的数据类型
- 持久化
- 集群
- 事务
二.redis 自带的性能测试
Redis自带redis-benchmark可以为Redis做基准性能测试,支持的参数如下。
-c(clients)选项代表客户端的并发量(默认50)
-n(num)选项代表客户端请求数量(默认100000)
-q 选项仅仅显示redis-benchmark的requests per second信息
-r(random)选项,可以向Redis插入更多随机的值
-P 选项代表每个请求pipeline的数据量(默认为1)
-k 选项代表客户端是否使用keepalive,1为使用,0为不使用,默认值为1
-t 选项可以对指定命令进行基准测试
–csv 选项会将结果按照csv格式输出
实例:
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
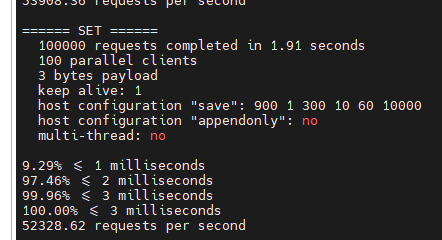
解释------>
100000 个请求 1.91s
每次请求有100个并行客户端
每次写3个字符串
保持一台服务器连接
所有请求在3ms内完成
每秒处理了52328.62请求
三.Redis的基本知识
1. Redis的数据库
Redis有16个数据库 默认使用的是第0个
2. 如何切换数据库
通过select来切换数据库
[root@hdzs-zhuji bin]# redis-cli -p 6379
127.0.0.1:6379>
127.0.0.1:6379> SELECT 3 ---切换3号数据库
OK
127.0.0.1:6379[3]> DBSIZE ---查看数据库的DB大小
(integer) 0
127.0.0.1:6379[3]>
127.0.0.1:6379> KEYS * ---查看所有的key
1) "name"
2) "counter:__rand_int__"
3) "key:__rand_int__"
127.0.0.1:6379> FLUSHDB ---清库 清空数据库 FLUSHALL 清空全部库
OK
127.0.0.1:6379> KEYS *
(empty array)
3. redis是单线程
Redis 是基于内存操作,CPU不是Redis的性能瓶颈,Redis的性能瓶颈是根据机器内存和网络带宽
为什么单线程还这么快?
核心: redis是将所有数据全部放在内存中的, 没有多线程(CPU上下文切换)
四. Redis的数据类型
-
Redis的常用命令
Exists name 判断当前Key是否存在 Move name 1 移除当前的key 1代表当前数据库 Expire name 10 设置key的过期时间 单位是s 10s Ttl name 查看当前key的剩余时间 Type name 查看key的数据类型 AppEnd name "内容" 追加内容(不存在就新增) -
Redis的数据类型
基础数据类型
String
set name wblx ---k-name v-wblx get nameList
在Redis里 List可以用做 栈 队列 阻塞队列 ###写列表数据--从头塞 LPUSH list 1 LPUSH list 2 LPUSH list 3 ###从尾塞 RPUSH list 4 ###查看 LRANGE list 0 -1 获取全部 LRANGE list 0 1 获取指定范围Set
Set也是集合 但是set里面的值是不能重复的 ###写集合数据 sadd name 1 sadd name 2 sadd name 3 ###查数据 SMEMBERS name ###判断某一个值是不是在set集合中 SISMEMBER name haha 返回1/有 0/没有Hash
Hash 其实就是一个MAP集合 我们常用的Redis数据类型 都是K-V 的形式 Hash ---- 相当于 key-map = key-<k-v> ###写一个hash数据 hset xinxi name wblx hset xinxi name wblx age 12 ###查数据 hget xinxi nameZset
zset是有序集合 zadd myset name wblx ---添加一个值 zadd myset name haha age 12 ---添加多个值 ZRANGE myset 0 -1 --查看myset的全部数据 排序 ZRANGEBYSCORE myset -inf +inf --用key去排序 用于数字的排序特殊数据类型
geospatial —地理位置
主要用处 朋友的定位 附近的人 打车距离的计算
###添加一个地理位置 116.1 39.2---维度 经度 名称 geoadd china:city 116.1 39.2 beijin ###查询 GEOPOS china:city beijinHyperloglog
Hyperloglog是Redis的一个基数统计的算法
什么是基数? 不重复的元素
A{1,2,3,4,} --那么基数就是4
主要用处可以用来统计网页的用户访问量
###添加一组数据
PFadd neme zhangsan lisi wanger
###统计基数
PFCOUNT name ---->3 不重复的元素
Bitmaps
位存储 (0 1)可以记录两种情况
比如统计项目的活跃人数 0不活跃 1活跃 /打卡情况等
占用内存很小
###添加数据
setbit daka 0 1
setbit daka 1 0
setbit daka 2 1
setbit daka 3 0
setbit daka 4 1
setbit daka 5 1
###查看
getbit daka 5
###统计
bitcount daka 统计为1的
五. Redis事务
Redis事务本质: 一组命令的集合 一个事务中的所有命令都会被序列化,在事务执行过程中,会按照顺序执行
一次性 顺序性 排他性(不允许被打断) 执行一系列的命令
注意:
-
Redis事务没有隔离级别的概念
所有的命令在事务中,并没有直接被执行 只有发起执行命令的时候才会执行
-
Redis单条命令是保存原子性的,但是事务不保证原子性
Redis事务流程
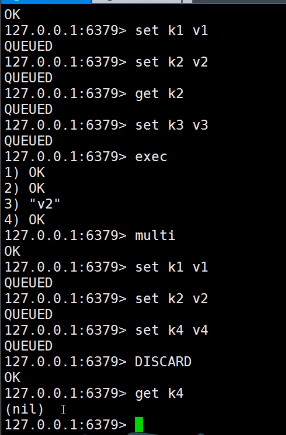
开启事务(multi)
命令入队(…)
执行事务(exec)/取消事务(DISCARD)
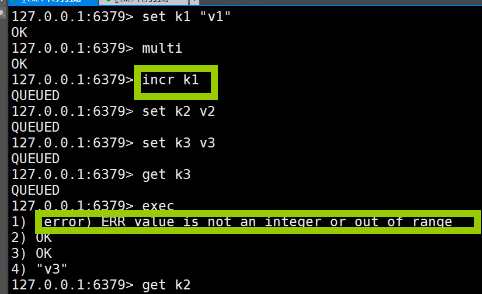
Redis事务的常见异常
- 编译型异常,命令写错了-----事务中的所有命令都不会被执行
- 运行时异常,事务命令队列有语法错误,那么在执行的时候-----其他命令是可以执行的,错误命令抛出异常
六. Redis实现乐观锁
1. 悲观锁和乐观锁---- 一种上锁的态度
悲观锁: 很悲观, 认为什么时候都会出问题 无论做什么都会加锁
乐观锁:很乐观, 认为什么时候都不会出现问题, 所以不会上锁 会在更新的时候判断一下,是否有人修改过这个数据
----->乐观锁
加一个version, 更新的时候再去比较version
2. Redis 监视测试
####正常执行
set money 100
set out 0
watch money # 监视money对象
multi # 开始事务
DECRBY money 20 # 花掉 减去20
INCRBY out 20 #开销 增加20
exec #执行事务
###不正常执行
#测试多线程修改值 使用watch可以当做redis的乐观锁操作
set money 100
set out 0
watch money # 监视money对象
multi # 开始事务
DECRBY money 20 # 花掉 减去20
INCRBY out 20 #开销 增加20
######在事务执行之前 原始数据已经被改动了#######
exec #执行事务会失败
####
先解锁
unwatch 解锁
watch money 上锁
七.Redis的配置文件
- redis.conf 配置文件 单位 对大小写不敏感
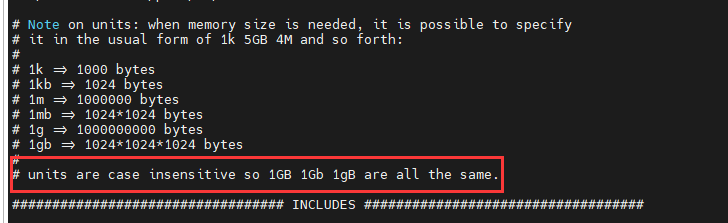
- 支持conf文件的组合
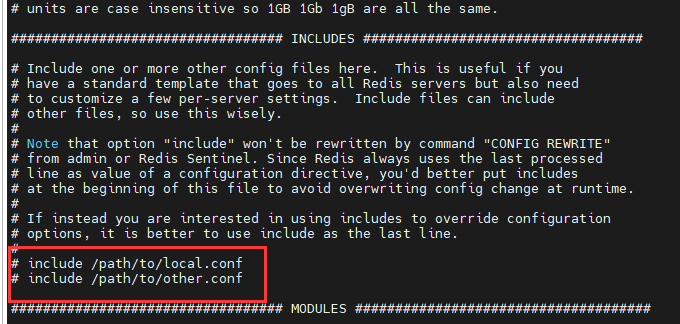
- 绑定的ip
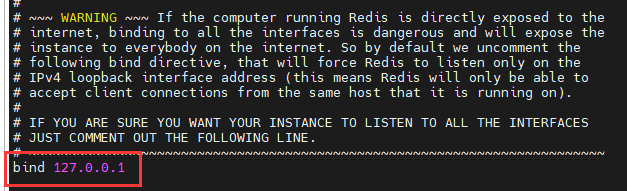
- 是否受保护 默认就是yes
-
端口号的配置 默认6379

-
运行选项配置

daemonize yes ---后台 守护进程
daemonize no ---前台运行 默认值
如果是后台运行 需要指定一个pid
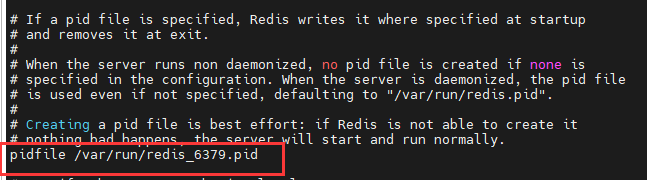
- 日志级别

可以指定日志文件名

-
Redis 数据库数量
默认有16个数据库

- 启动logo 是否开启

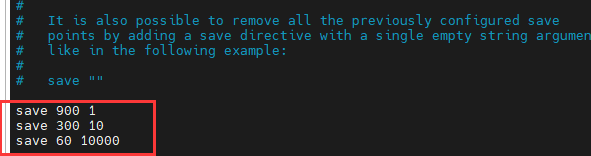
- Redis 的快照 rdb
```
持久化:
在规定时间内 执行了多少操作 则会持久化到文件 .rdb .aof里面
Redis是内存数据库,如果没有持久化,那么数据断电就会消失
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""
#######如果900s内 至少有1个key进行了修改 我们就会进行持久化操作
save 900 1
#######如果300s内 至少有10个key进行了修改 我们就会进行持久化操作
save 300 10
#######如果60s内 至少有10000个key进行了修改 我们就会进行持久化操作
save 60 10000
# The filename where to dump the DB
dbfilename dump.rdb # rdb保存的文件名称
stop-writes-on-bgsave-error yes ---持久化出错是否继续工作
rdbcompression yes ---是否压缩rdb 文件
rdbchecksum yes ---保存rdb文件的时候是否进行检验
dir ./ ---rdb文件的保存目录 默认当前目录下
```
aof
```
appendonly no ---默认是不开启aof模式的 即默认使用rdb持久化的方式
appendfilename "appendonly.aof" ---aof 持久化文件名称
##执行方式
# appendfsync always ---每次修改都会同步 性能不行
appendfsync everysec ---默认每秒执行一次 可能会丢失这1s的数据
# appendfsync no ---不同步 操作系统自己同步数据 速度最快
```
-
Redis 安全相关配置
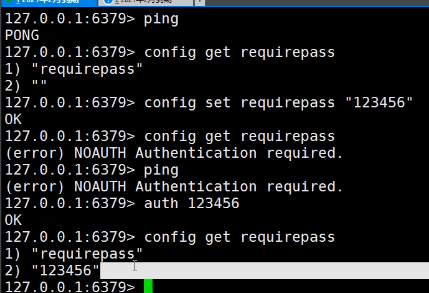
- 给Redis设置登录密码(默认是没有密码的) —数据库设置
-
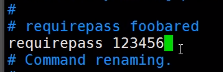
配置文件设置
 -
Redis 的限制配置

maxclients 10000 # 设置能连接Redis的最大客户端的数量 maxmemory <bytes> # redis 配置最大的内存容量 maxmemory-policy noeviction # 内存到达上限后的处理策略 ----删除过期的key,报错等
八. Redis 的持久化
1. RDB (Redis DataBase)
-
什么是RDB:
在指定的时间间隔内,讲内存中的数据集 快照写入磁盘
它恢复时是将快照文件直接读到内存里
-
RDB 持久化流程
Redis会单独创建(fork)一个子进程来进行持久化,先将数据写到一个临时文件里面
等到持久化过程都结束了,再用这个临时文件替换上次持久化好的文件
注:
在整个过程中 主进程是不进行任何IO操作的 这样就确保了极高的性能
如果进行大规模数据的恢复,且对于数据的完整性不是非常敏感,那么RDB方式要比AOF的更加高效
RDB的缺点是最后一次持久化后的数据可能丢失
-
RDB文件产生的三种情况
- Save的规则满足的情况下,会自动触发rdb规则
- 执行flushall命令,也会触发我们的rdb规则
- 退出redis,也会产生rdb文件
备份就自动生成一个dump.rdb
-
恢复rdb文件
-
只需要将rdb文件放到我们的redis启动目录就可以了,redis启动时会自动检查dump.rdb文件
-
查看dump.rdb需要存放的位置
cofig get dit ---连接redis查询 该目录下有dump.rdb文件 就会先扫描 并恢复其中的数据
-
-
RDB 持久化模式的优缺点
优点:
- 适合大规模的数据恢复
- 前提要对数据的完整性要求不高
缺点:
- 需要一定的时间间隔 --可修改
- 意外宕机 最后一次修改的数据就没了
- fork进程的时候 会占用一定的内容空间
2. AOF 持久化模式
-
什么是AOF:
将我们的所有命令都记录下来,恢复的时候就把这个文件全部在执行一遍
-
AOF持久化流程
以日志的形式来记录每个写操作(读不记录) 只许追加文件但不可以改写文件
redis启动之初会读取该文件重新构建数据 用来恢复数据
Aof 保存的文件是 appendonly.aof 文件 ----默认不开启
-
AOF文件的修复
当aof文件错误的情况下 redis是启动不起来的 可以使用redis自带的修复工具
redis-check-aof 进行修复
redis-check-aof --fix appendonly.aof -
AOF持久化方案的优缺点
优点
-
每一次修改都同步 文件的完整性比较好
----根据配置来
缺点
-
相对于数据文件来说 aof远大于rdb 修复的速度也比rdb慢
—所以默认就是rdb模式
九. Redis发布订阅
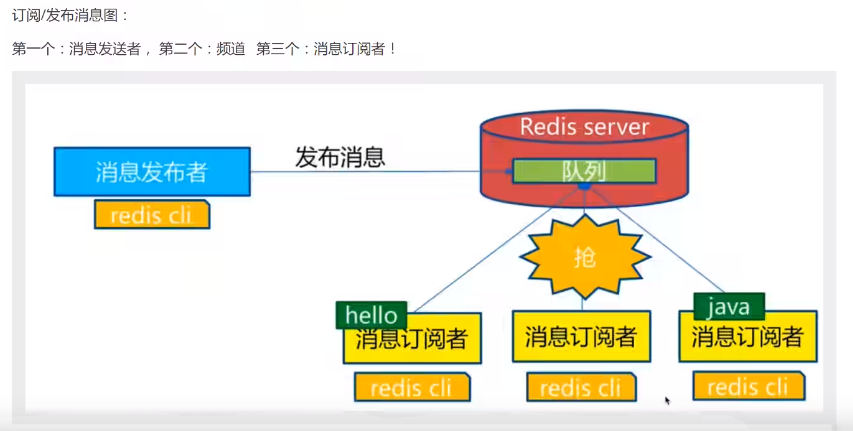
1. 什么是Redis的发布订阅
Redis发布订阅(pub/sub)是一种消息通信模式 发送者(pub)发送消息,订阅者(sub)接收消息
Redis客户端可以订阅任意数量的频道
-
2. 订阅以及发布测试
------订阅
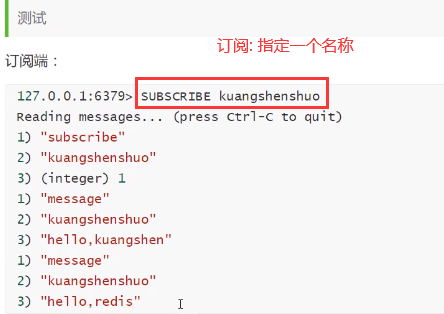
-----发布

3. Redis实现订阅的原理
-
通过SUBSCRIBE命令订阅某频道后 redis-server里维护了一个字典 字典的键就是一个个频道
字典的值则是一个链表,链表中保存了所有订阅这个channel的客户端,SUBSCRIBE命令的关键,就是
将客户端添加到给定channel的订阅链表中
-
通过PUBLISH 命令向订阅者发送消息,redis-server 会使用给定的频道作为键,在它所维护的channel字典
中查找记录了订阅这个频道的所有客户端链表,遍历这个链表,将消息发送给订阅者
-----即时聊天 群聊都可以实现 订阅关注等
十. Redis的主从复制
1. Redis主从复制的概念
主从复制: 是指将一台Redis服务器的数据,复制到其他的Redis的服务器, 前者称为主节点 后者称为从节点
默认情况下 每台Redis服务器都是主节点 且一个主节点可以有多个从节点(或者没有) 但一个从节点只能有一个主节点
2. 主从复制的作用
-
数据冗余: 主从复制实现了数据的热备份 是持久化之外的一种数据冗余方式
-
故障恢复: 当主节点出现问题,可以由从节点提供服务,实现快速的故障恢复 实际上是一种数据的冗余
-
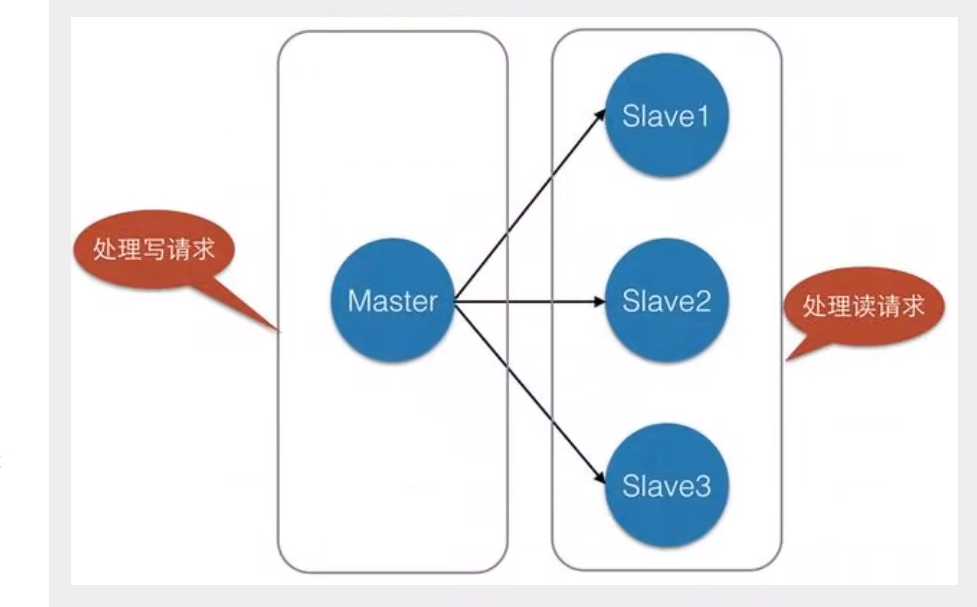
负载均衡: 在主从复制的基础上 配合读写分离 可以由主节点提供写服务 从节点提供读的服务,提高Redis服务器的并发量
-
高可用基石:主从复制才是Redis真正实现高可用的基础
SO 一般来说 要将Redis运用于工程项目中 只使用一台Redis是不行的
1. 结构上 单个Redis服务器会发生单点故障 一台服务器需要处理所有的请求负载 压力较大
1. 容量上 单个Redis服务器内存容量有限
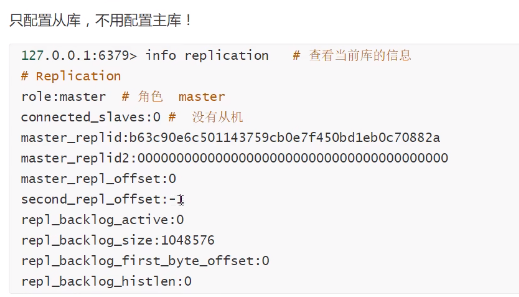
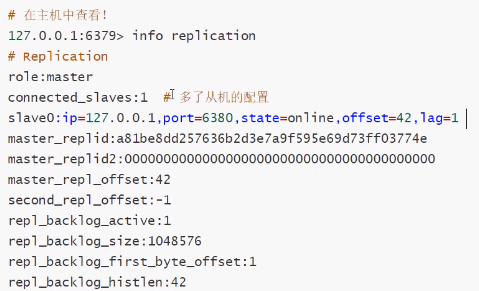
3. Redis角色的查询
4. 简单实现Redis 主从复制测试
1. 复制3个redis的配置文件(redis.conf),然后修改对应信息(正常情况都是部署在不同机器上)
- 端口号
- pid名称
- log文件名
- dump.rdb --持久化的文件名称(防止冲突)
2. 复制原理:
slave启动成功连接到master 后会发送一个sync同步命令
master接到命令 启动后台的存盘进程 同时收集所有接收到的用于修改数据集命令
在后台进程执行完毕之后 master将传送整个数据到slave 并完成一次完全同步
两个概念:
- 全量复制:slave服务在接收到数据库文件数据后 将其存盘并加载到内存中
- 增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步
所以: 只要从机重新连接master 一次完全同步(全量复制)将自动执行
- 通过指定配置名称 单机多启动

- 开始搭建一主二从
—默认情况下 每台Redis服务器都是主节点; 一般情况只需要配置从机就好了
通过命令的方式进行配置------暂时的
##选择一台从机 将6379的Redis服务当做主机
SLAVEOF 127.0.0.1 6379
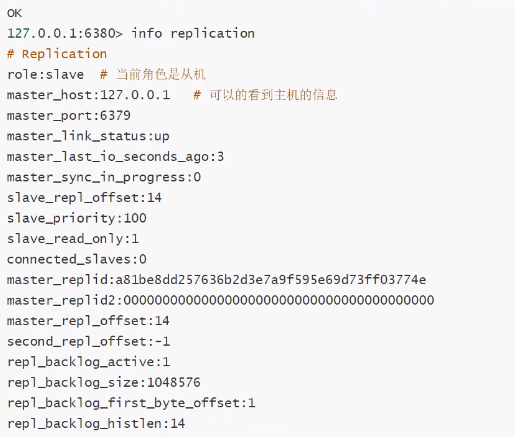
通过配置文件进行配置----永久的
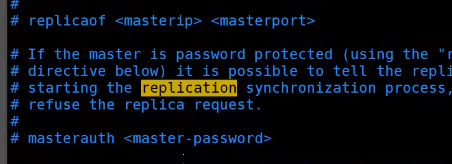
replicaof 主机ip 端口
####如果有密码#####
masterauth 密码
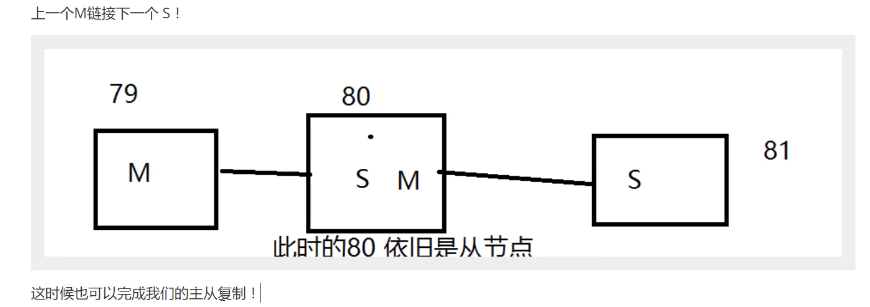
- 层层连接模式
3. 注意事项
- 主机可以写 从机不能写只能读

-
主机中所有信息和数据,都会自动被从机保存
-
主机断开连接,从机依旧连接到主机的,但是没有写的操作,这个时候,主机如果回来了,从机依旧可以直接获取到主机写的信息
-
如果使用的命令行去配置的主从 这个时候如果重启了 就会变成主机 只要再一次变成从机 立马就会从主机中取到值
4. 主机没了怎么办?
手动操作
-
主机如果断开了连接 通过连接从机 执行 SLAVEOF no one 让自己变成主机
主机恢复后 需要重新配置 不推荐…
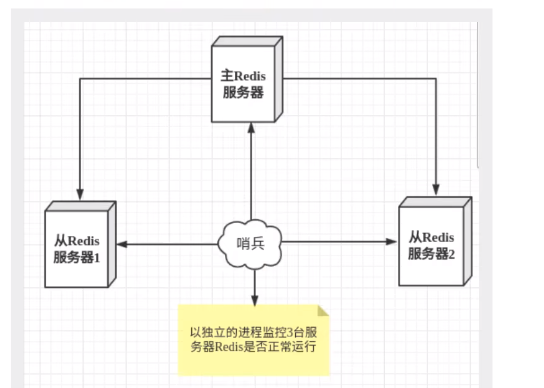
十一. 哨兵模式
------自动选择主机------
1. 什么是哨兵模式
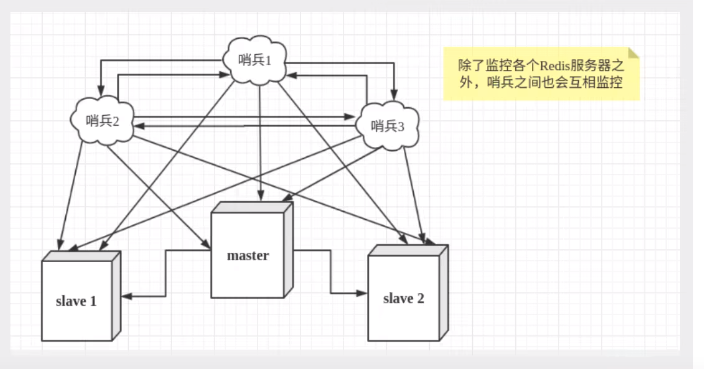
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行
能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
原理就是 哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例
2. 哨兵监控流程
-
主Redis服务宕机
-
哨兵1号先检查到了这个结果,这时系统不会马上进行故障转移过程
仅仅是1号主观认为主服务器不可用,这个现象称为主观下线
-
当后面的哨兵也检测到主服务器不可用,并且数量达到了一定值
-
哨兵之间开始投票,投票的结果由一个哨兵发起,进行故障转移操作
-
转移成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现
切换主机,这个过程叫作 客观下线
3. 相关配置
-
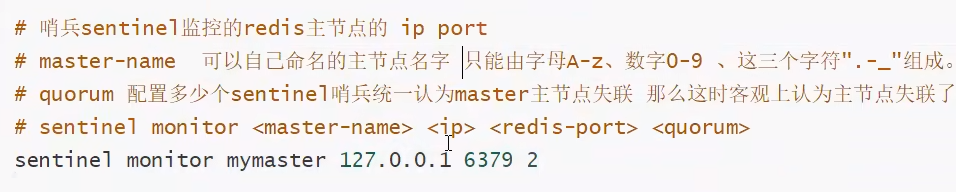
配置哨兵配置文件 sentinel.conf
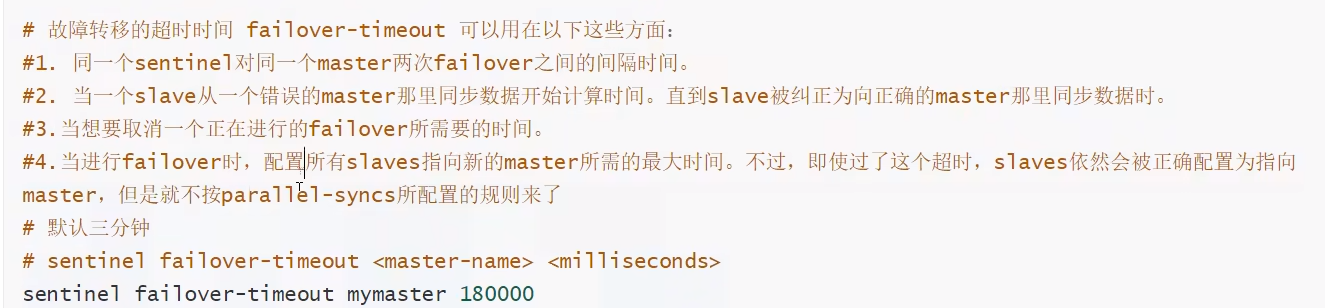
# sentinel monitor 被监控的名称 host port 1 # 文件内容 sentinel monitor myredis 127.0.0.1 6379 1 1----代表主机挂了 slave投票看谁接替主机 票数最多的 就会成为主机 -
启动哨兵
redis-sentinel xxx/sentinel.conf
注意: 如果主机此时回来了, 只能归并到新的主机下 当做从机
4. 哨兵模式的优缺点
优点:
- 哨兵集群,基于主从复制模式,所有的主从配置优点,它都具备
- 主从可以切换,故障可以转移,系统的可用性就会更好
- 哨兵模式就是主从模式的升级,手动到自动
缺点:
- Redis不好在线扩容, 集群容量一旦到达上限,在线扩容就十分麻烦
- 实现哨兵模式的配置其实很麻烦
5. 配置文件







十二. Redis缓存穿透和雪崩
1. 缓存穿透
-
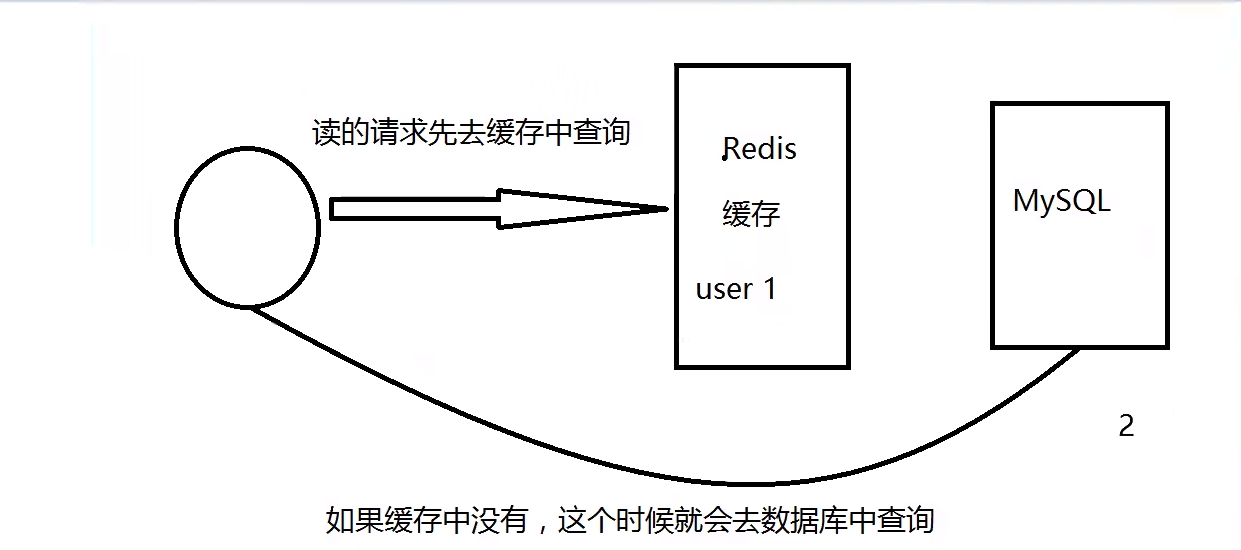
什么是缓存穿透—查不到
用户想要查询一个数据 发现Redis内存数据库没有 也就是缓存没有命中 于是向持久层数据库查询
发现也没有 于是本次查询失败 当用户很多的时候 缓存都没有命中 于是都去请求了持久层数据库
这会给持久层数据库造成了很大压力 即出现了缓存穿透
-
解决方案:
-
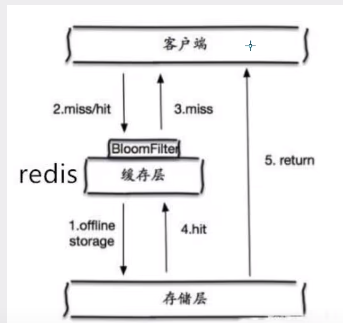
布隆过滤器
布隆过滤器是一种数据结构,对所有可能查询的参数以Hash形式存储,在控制层先进行检验 不符合则丢弃
从而避免了对底层存储系统的查询压力
-
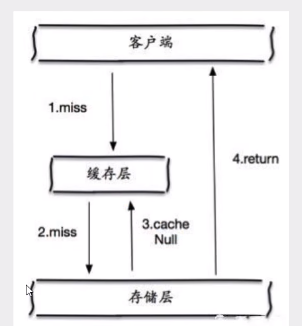
缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间 之后再访问这个数据将会从缓存中获取 保护后端数据源
这种方案有弊端
-
如果空值能够被缓存起来 这就意味着缓存需要更多的空间存储更多的键 因为这当中可能会有很多空值的键
-
即使对空值设置了过期时间 还是会存在缓存层和存储层的数据会有一段时间窗口的不一致 这对于需要保持一致性的业务会有影响
-
缓存击穿—查询次数太多
缓存击穿: 是指一个key非常热点 在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间 持续的大并发就穿破缓存
当某个key在过期的瞬间 有大量的请求并发访问 这类数据一般都是热点数据 由于缓存过期 会同时访问数据库来查询最新数据,并且回写缓存 会导数据库瞬间压力过大
解决方案
-
设置热点数据用不过期
从缓存层面上来看 没有设置过期时间 所以不会出现热点key过期后产生的问题
-
加互斥锁
分布式锁:加分布式锁 保证对于每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限
因此只需要等待即可 这种方式将高并发的压力转到了分布式锁 因此对分布式锁考验较大

2. 缓存雪崩
1. 概念
缓存雪崩是指在某个时间段 缓存集中过期失效 例如 Redis宕机
2. 产生原因

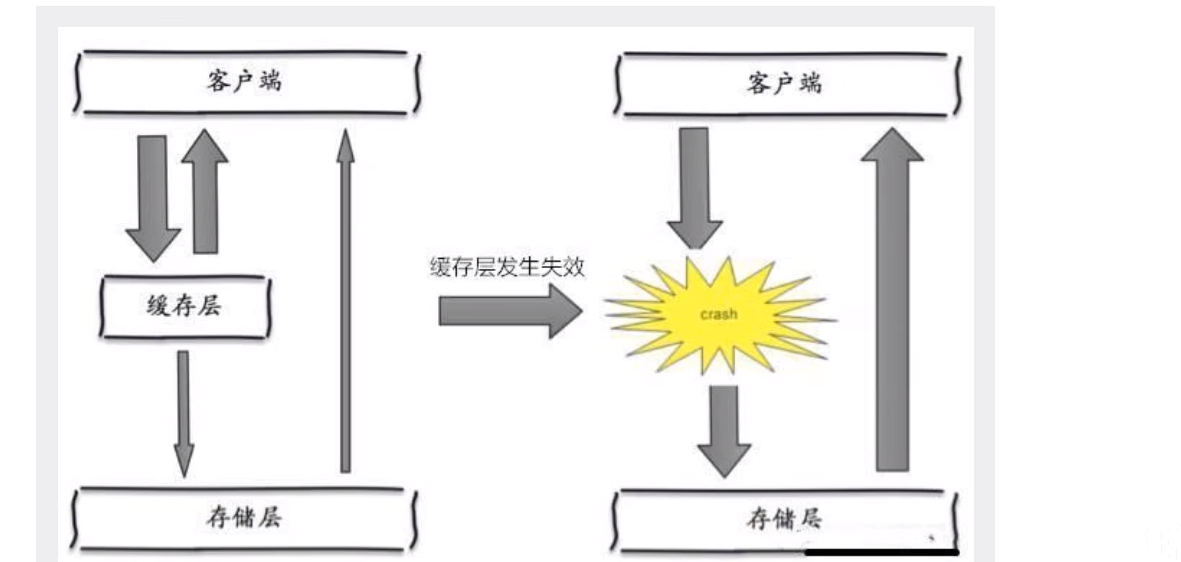
3. 解决方案
-
Redis高可用 : 既然可能会挂掉 那么就多增设几台Redis
-
限流降级: 在缓存失效后 通过加锁或者队列来控制读数据库 写缓存的线程数量
比如对某个key 只允许一个线程查询数据和写缓存 其他线程等待
-
数据预热: 数据加热的含义就是在正式部署之前 我先把可能的数据预先访问一遍
这样部分可能大量访问的数据就会加载到缓存中 在即将发生大并发访问前手动触发
加载缓存不同的key 设置不同的过期时间 让缓存失效的时间点尽量均匀















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









