







 本文介绍了如何通过训练语言库提升Tesseract对手写体的识别效果。通过使用jTessBoxEditor和Tesseract,遵循7步训练过程,包括合并图片、生成box文件、特征文件、字符集、聚集特征等,最终创建自定义的.traineddata字典文件,显著提高识别准确率。
本文介绍了如何通过训练语言库提升Tesseract对手写体的识别效果。通过使用jTessBoxEditor和Tesseract,遵循7步训练过程,包括合并图片、生成box文件、特征文件、字符集、聚集特征等,最终创建自定义的.traineddata字典文件,显著提高识别准确率。
前面讲的都是对于标准字的识别,但对于验证码或者手写字体识别率就会非常低。为了让Tesseract识别自己的语言,可以通过训练语言库的方式来解决。下面通过一个识别手写字体的例子来了解Tesseract提供什么方式训练自己的语言库。
首先我们来看下未经过训练的Tesseract对接下来的这张图片的识别率。
待识别图片:
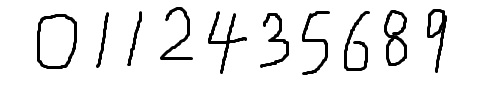
识别结果:
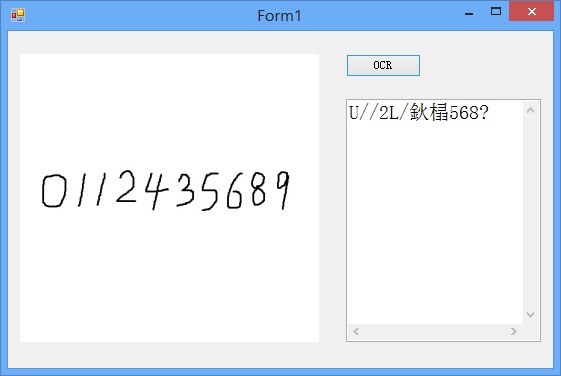
可以看出识别效果很不理想。下面训练手写字体的语言库,看看训练后的Tesseract识别效果如何。
为了训练语言库,我们需要两个工具,Tesseract和jTessBoxEditor。经过前面的介绍,Tesseract相信大家应该不陌生了,至于jTessBoxEditor的用途,后面用到时将会介绍。
训练步骤:
1.下载
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









