







目录
1 深浅拷贝
1.1 浅拷贝
若执行
a = [[1, 2], 3, 4]
# 下面这种做法与b = a[:]是一样的效果
# 但是与b = a不一样,该操作更浅
b = a.copy()
则得到下面的状态:
- 为b开辟一块地址将a指向的地址赋给b
- b与a有了相同的指向
- 对于不可变类型(数值型、元组、字符串等),若改变b中元素的指向,则发现a中的相应元素并不改变
- 但对于指向的可变元素(如列表,本身元素也是一种指向),例如改变b[0][1],则会发现a中的对应位置也进行了相同的修改,如图二,这是因为a和b的[0]号位置指向同一个列表元素,该列表元素[0][1]存入的是指向元素的地址,改变该元素的地址同步影响两个。


1.2 深拷贝
若执行
import copy
a = [[1, 2], 3, 4]
# copy.py 中的深拷贝方法
b = copy.deepcopy(a)

可以发现重新为里面的子列表开辟了一块空间存储地址,此时再修改b[0][1]就不会影响a中的值了,这就叫深拷贝
2 set (集合)
满足数学中集合的一切概念,就是讲不同的元素放在一个集合里,满足集合三要素:
5. 确定性 (set中的元素必须是不可变的,也就是必须可哈希的)
6. 无序性 (set中的元素不可通过切片获取,但是可迭代)
7. 互异性 (set建立集合的时候会自动去重)
另外:用set建立的集合本身不可哈希
用frozenset建立的集合是可哈希的
2.1 集合的建立(只有这一种建立方法)
s1 = set('alvin alex li')
print(s1) #{'v', 'a', 'l', 'i', ' ', 'x', 'n', 'e'}
可发现去重了
2.2 集合的访问
s1 = set('alvin alex li')
for i in s1:
print(i) #返回集合中的元素str型
if 'v' in s1:
print('yes')
2.3 更新集合
s1 = set('al') #{'l', 'a'}
# 1 .add()方法,参数视为一个整体
s1.add('qwe') #{'l', 'qwe', 'a'}
# 2 .upda()方法,参数被视为一个列表
s1.update('rty') #{'t', 'a', 'qwe', 'r', 'l', 'y'}
s1.update([1, 'zxc']) #{1, 'zxc', 't', 'a', 'qwe', 'r', 'l', 'y'}
2.4 删除集合
# 接上面代码:
# 1. 删除单个元素
s1.remove(1)
# 2. 随机删除
s1.pop()
# 3. 清空集合
s1.clear()
2.5 集合类型操作符
- 等价 == 不等价 != 返回布尔变量
s1 = set('qwe')
s2 = set('qweq')
print(s1 == s2) #True
print(s1 != s2) #False
- 子集 超集 >< 返回布尔变量
s1 = set('qwe')
s2 = set('qweq')
print(s1 <= s2) #True
print(s1 < s2) #False
print(s1.issupset(s2)) #等价于s1 < s2
print(s1.issupperset(s2)) #等价于s1 > s2
- 集合操作:交、并、差、对称差
s1 = set([1, 2, 3, 4])
s2 = set([3, 4, 5, 6])
print(s1 & s2) #{3, 4}
print(s1.intersection(s2)) #{3, 4}
print(s1 | s2) #{1, 2, 3, 4, 5, 6}
print(s1.union(s2)) #{1, 2, 3, 4, 5, 6}
print(s1-s2) #{1, 2}
print(s1.difference(s2)) #{1, 2}
print(s1^s2) #{1, 2, 5, 6}
print(s1.symmetric_difference(s2)) #{1, 2, 5, 6}
print(s1,s2) #{1, 2, 3, 4} {3, 4, 5, 6}
3 函数
3.1 函数的创建
# foo也可以视为一个变量,存的是地址,指向函数的这块代码
def foo():
pass
3.2 命名规则
同变量的命名规则,不用保留次
并且识别大写小,
3.3 形参和实参
在函数命名的时候会在括号里传入参数,此时的参数叫做形参,调用之前并不占用内存,而在函数调用的时候传入的参数叫做实参,会分配内存
3.4 函数的参数
- 必须参数:def foo(x, y): 如果按照这种方式命名的话,传入参数必须必须有且按照顺序传。
- 关键字参数:就是在必须参数的基础上,如果不按照顺序的话必须将形参带上,让解释器知道现在需要传入的参数的内容。
举例:
def foo(name, age):
print(name, age)
foo('zhao', 27) #zhao 27
foo(27, 'zhao') #27 zhao
foo(age=27, name='zhao') #zhao 27
- 缺省参数:def foo(x, y, z = 1): 像这种形参中加入等号且有值得参数就是告诉解释器,可以不进行该参数的传入,按照形参默认值进行运算
def foo(name, age, sex='male'):
print(name, age, sex)
foo('zhao', 27) #zhao 27 male
foo('zhao', 27, 'female') #zhao 27 female
foo('zhao', 27, sex='female') #zhao 27 female
#foo(age=27, name='zhao', 'female') #SyntaxError: positional argument follows keyword argument
foo(age=27, name='zhao', sex='female') #zhao 27 female
- 元组参数:def foo(*args): 传入参数可以不定长度,但是必须是多个参数,有两个方式 foo(1, 2, 3, 4) 或者 foo(*[1, 2, 3])
def add(*args):
print(args) #(1, 4, 6, 9)
print(type(args)) #<class 'tuple'>
sum = 0
for v in args:
sum += v
return sum
print(add(1, 4, 6, 9)) # 20
print(add(*[1, 2, 3])) # 6
- 元组参数:def foo(**kwargs): 传入参数可以不定长度,但是必须是多个参数,有两个方式 foo(name=‘zhao’, age=23, sex=‘male’) 或者 foo(*{‘name’: ‘zhao’, ‘age’: 23, ‘sex’: ‘male’})
def print_info(**kwargs):
print(kwargs)
print(type(kwargs)) #<class 'dict'>
for i in kwargs:
print('%s:%s' % (i, kwargs[i]), end='\t') # 根据参数可以打印任意相关信息了
return
print_info(name='alex', age=18, sex='female') #name:alex age:18 sex:female
print_info(**{'hobby': 'girl', 'nationality': 'Chinese', 'ability': 'Python'})
#hobby:girl nationality:Chinese ability:Python
- 混合参数必须按照以下顺序: 必须参数->缺省参数->元组参数->字典参数。其中缺省参数可有可无,因为实参必须加入,否则后面的参数不认。
3.5 返回值
返回值如果返回多个,结果是元组
3.6 高阶函数(装饰器会用到)
该例子可以看出函数名也是变量,可以进行复制操作
满足(二者之一):
- 形参有函数变量
- 返回函数
def foo(x, y, f):
return f(x)+f(y)
res = foo(5, 6, abs)
或者:
def foo():
x = 3
def wrapper():
return x
return wrapper
print(foo()) #<function foo.<locals>.wrapper at 0x0000029A5106E268>
print(foo()()) #3
f = foo()
print(f
3.7 作用域范围
- L(local):局部作用域,最底层函数内的变量,只作用于函数内部
- E(enclosing):嵌套于父级函数的作用域,叫内部作用域,里面还有函数
- G(global):全局作用域,模块里面定义的变量
- B(built-in):系统固定模块里的变量,一般用不上
x = int(4) #———————————————————————
g_count = 0 #——————————————————————|
def outer(): # |
e_count = 1 #————————————————| |
def inner(): # | |
l_count = 2 #——————————| | |
print(l_count) #———————| | |
return 0 # ——————————| | |
print(e_count) # ——————————| |
return inner()# ——————————————|
print(g_count) #————————————————|
outer()
教程中写到 Python 中变量的查找顺序:“在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再去内置中找。可以看一个具体的例子。
Python 的一个内建值 int,我们首先将其赋值为 0,然后定义一个函数 fun1()。
int = 0
def fun1():
int = 1
def fun2():
int = 2
print(int)
fun2()
函数 fun1() 的作用就是调用函数 fun2() 来打印 int 的值。
调用函数 fun1():
fun1()
2
因为 local 中的 int = 2,函数将其打印出来。
将函数 fun2() 中的 int = 2 删除:
int = 0
def fun1():
int = 1
def fun2():
print(int)
fun2()
调用函数 fun1():
fun1()
1
因为 local 找不到 int 的值,就去上一层 non-local 寻找,发现 int = 1 并打印。
而进一步删除函数 fun1() 中的 int = 1:
int = 0
def fun1():
def fun2():
print(int)
fun2()
调用函数 fun1():
fun1()
0
因为 local 和 non-local 都找不到 int 的值,便去 global 中寻找,发现 int = 0 并打印。
若删除 int = 0这一条件:
del int
def fun1():
def fun2():
print(int)
fun2()
调用函数 fun1():
fun1()
<class ‘int’>
因为 local、non-local、global 中都没有 int 的值,便去 built-in 中寻找 int 的值,即:
int
<class ‘int’>
3.8 内部作用域修改外部作用域的值
搜索变量优先级顺序:L>E>G>B
函数内部不可修改全局变量,只能查看,若想修改,需要加global关键词进行声明。
嵌套函数内部不能修改父级函数的E作用域变量,需要加nonlocal变量进行声明。
g_count = 1
def outer():
g_count = 5
print(g_count)
outer()
print(g_count)
#输出:
#5
#1
上述案例相当于在函数内部声明局部变量,只不过是和全局变量重名
g_count = 1
def outer():
print(g_count) #Unresolved reference 'g_count'
g_count = 5
#或者
def outer():
g_count += 5 #Unresolved reference 'g_count'
都会报错==Unresolved reference ‘g_count’ ==,这是因为在局部作用域中解释器发现对g_count进行修改和引用,第一种是找到里面有定义,但是在后面,所以解释器认为该变量是局部变量,
第二种是要对该变量进行修改,但是解释器发现内部并未对该变量进行声明
如何修改:
g_count = 1
def outer():
global g_count
g_count = 5
print(g_count)
outer()
prin
或者
def outer():
e_count = 1
def inner():
nonlocal e_count
e_count = 5
print(e_count)
outer()
prin
引入作用域的操作有:class、def、lambda
而if、try、for不会引入新的作用域,其中命名的变量将在当前作用域一直有效
此处是与C++不同的地方
4 递归函数
函数内部调用其本身,需满足以下条件:
- 有一个结束条件
- 函数返回值为函数本身
说明:但凡是递归能做的事情,循环都能做
并且递归由于调用栈,因此效率比较低
但是,递归清晰,特别适用于比较复杂的逻辑地推。
# 循环示例
def f(n):
sum = 1
for i in range(n):
sum *= i+1
return sum
# 递归函数示例
def f2(n):
if n == 0:
return 1
return n * f(n-1)
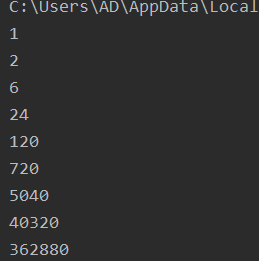
for i in range(1, 10):
print(f2(i))
5 常用内置函数
需要 impor functools 包
5.1 reduce()
reduce(function, sequence, starting_value)
from functools import reduce
def add1(x,y):
return x + y
print (reduce(add1, range(1, 101)))## 4950 (注:1+2+...+99)
print (reduce(add1, range(1, 101), 20))## 4970 (注:1+2+...+99+20)
对sequence中的item顺序迭代调用function,如果有starting_value,还可以作为初始值调用.
5.2 lambda()
普通函数与匿名函数的对比:
#普通函数
def add(a,b):
return a + b
print add(2,3)
#匿名函数
add = lambda a,b : a + b
print add(2,3)
#========输出===========
5
5
匿名函数的命名规则,用lamdba 关键字标识,冒号(:)左侧表示函数接收的参数(a,b) ,冒号(:)右侧表示函数的返回值(a+b)。
因为lamdba在创建时不需要命名,所以,叫匿名函数















 3466
3466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









