










背景
需求需要计算大容量环境下多个数据库数据的负载,并把分库关系迁移,以实现多个数据库节点负载均衡。
现象
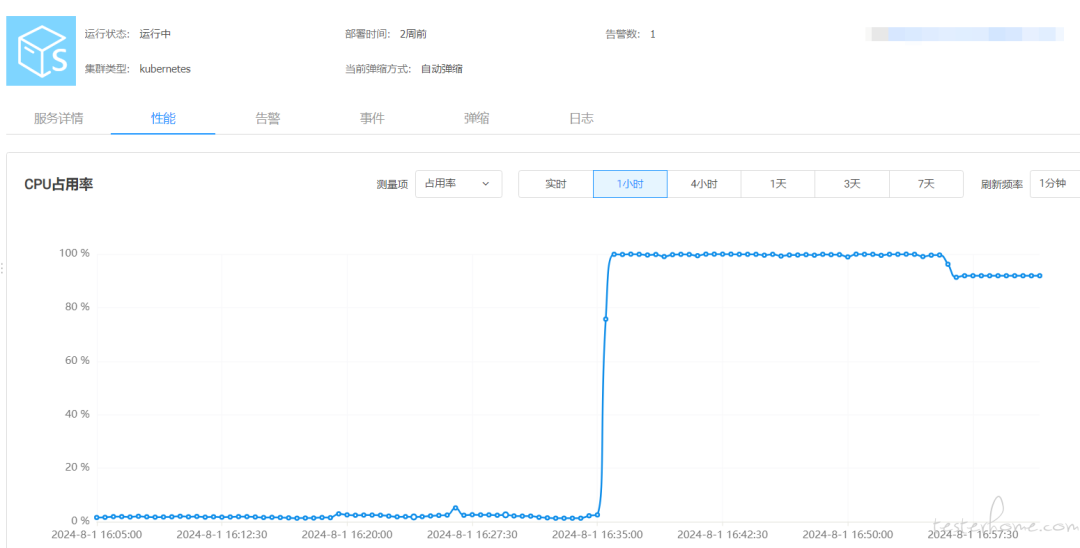
执行分库迁移脚本后,脚本执行进度始终保持 10%,组件 CPU 使用率冲到 95% 以上,且后台没有打印出有用的日志。
排查过程
-
尝试重启组件并重写执行脚本:判断该故障是否可复现。结论:故障可以复现。
-
查看新增代码:发现新增代码量太大,若进行全面代码走查将耗费大量时间,且由于后台日志较少,增加了代码走查的难度。
-
使用 arthas 工具排查:
3.1 编译并打包 arthas,然后将其部署到节点上。
3.2 通过
kubectl -n zenap cp {arthas-path} {pod}:{任意路径}命令将 arthas 拷贝到容器中。3.3 进入容器内的 arthas 目录,执行
java -jar arthas-boot.jar,并选择容器中运行的 java 进程 pid。3.4 使用 arthas 提供的命令进行问题排查,首先执行
dashboard命令查看面板。- 发现
pool-47-thread-1线程占用 CPU 90.98%,疑似进入死循环。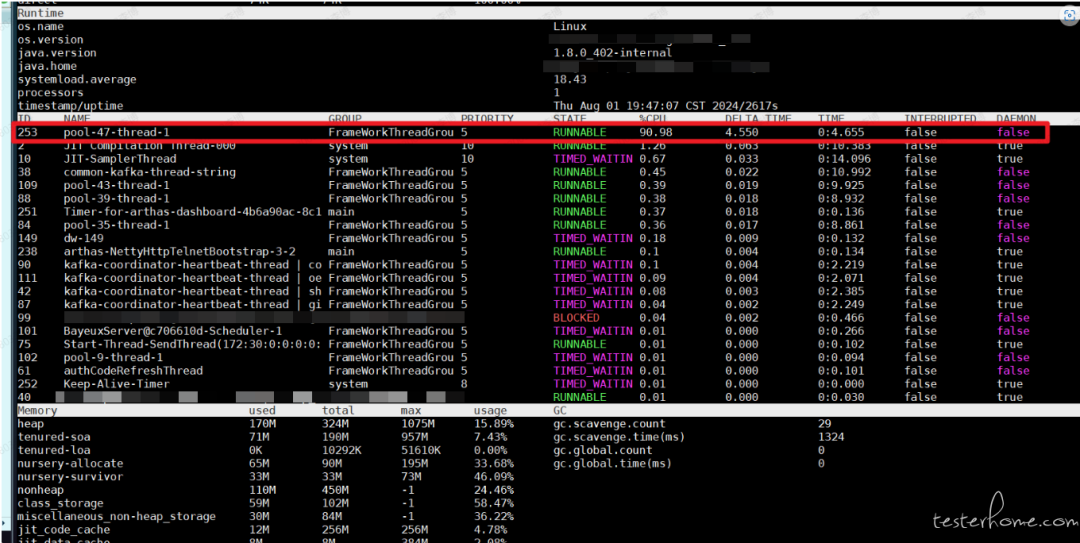
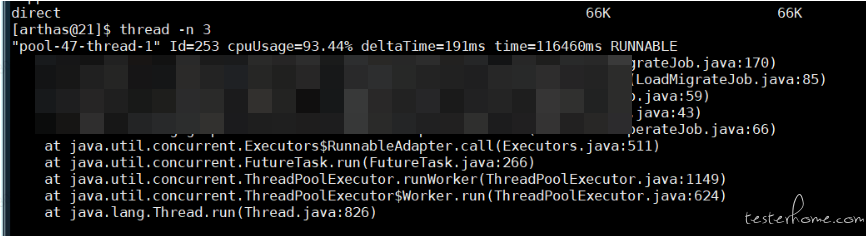
3.5 继续执行
thread -n 3命令找到该线程,查看其堆栈信息。- 发现占用 CPU 的线程堆栈中,
LoadMigrateJob的regularMigrate方法存在问题。
代码问题定位:
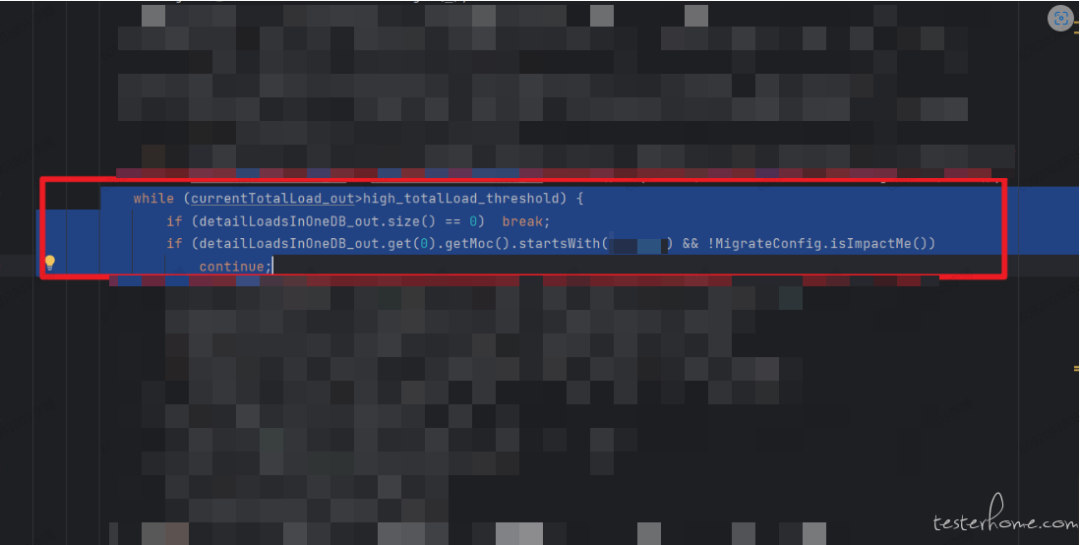
- 在while循环中,第二个if逻辑判断如果网元以cn.me开头且配置为False,则会继续循环。
- 但是,循环内没有对detailLoadsInOneDB_out进行任何增减操作,导致每次循环都会走continue流程,从而引发死循环。
- 这就是为什么 CPU 使用率会一直冲高。
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走!
软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









