






我们今天讨论的话题是编译器或者说是语言处理器更准确一些
一 什么是语言处理器?
我所见到的就是这些框框了
1.编译器
2.解释器(java虚拟机也是解释器)
3.编译器+解释器(混合型hybrd)
编译器编译后的目标程序, 并不一定是可执行程序; 解释器就如一个高级的处理器, 它能理解复杂的源程序,
直接去执行程序, 但它的内部做了很多与编译器相同的工作, 而且最终还要用真正的机器指令去执行, 这也
使得解释程序一般较编译程序运行的更慢, 但它非常灵活, 实时性高
明白它们的特点是重要的, 由于侧重点不同, 在不同场合叫法可能不同
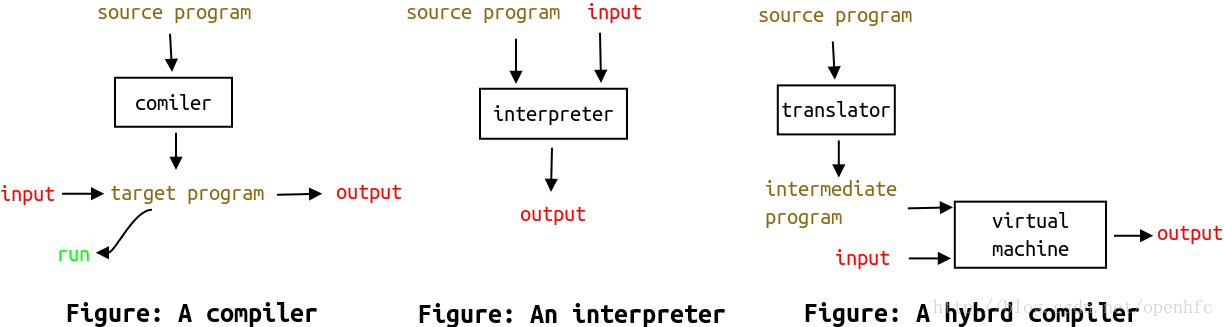
大家看图思考编译器和解释器各有什么优缺点?
二 它干了什么呢?
目前能看到的, 也就是:
1.将源程序翻译为目标程序
2.将源程序直接执行, 完成我们部署的任务
三 一个典型且完整的语言处理系统
未必所有的语言处理器都是这样的结构, 因为这都是人造的. 随着计算机技术的发展一些概念是演变的, 抓住重点是关键

1. 其中的各个模块都做了什么呢?
<1>. 预处理器: 一个源程序可能被分为多个不同的模块, 并存放在不同的文件中, 它的一个作用就是将源程序聚合在一起.
在C/C++中它还负责处理预处理指令, 就是#开头的东西.
但它一般不会将源程序转换为一种中间形式(特点)
<2>. 编译器: 编译器会接受预处理后的源程序(预处理器处理了它不认识的东西), 产生一个目标程序作为输出
<3>. 汇编器: 接收特定的汇编程序, 然后产生特定机器代码;
这里的汇编指令(真指令)和机器指令是对应的, 可以说汇编器是最早的编译器类型.
人们通常把这组指令的集合, 称做指令集(RISC,CISC)
它是软硬件的接口, 任何需要软件支持的机器生产出来, 都一定定义一套指令集.
<4>. 连接器: 它能够解决外部内存地址问题.
这不得不说汇编器产生的可重定位机器代码,
这里的可重定位是指某些汇编程序定义的内存区 (数据区, 文本区, Bss区<Block Started by Symbol) 的地址需要重新安排.
<5>. 加载器: 把可执行文件放到内存中执行
2. 语言处理系统为什么要这样划分模块呢?
为了好实现它啊. 为了组件的重用啊. 等等的我就不知道了...
随着计算机的发展, 各种体系的处理器被生产出来, 各种语言被发明出来, 软件危机后软件工程的革命. 让这种方法成为必然.
就如独立的汇编器, 可以为不同语言所共用, 人们就不用再重复的实现一种东西了
这种独立允许一对多, 多对一的映射, 这是非常灵活的
四 更进一步
这个图反应了一般编译器的各个阶段.

1. 词法分析: 将一个个字符(有限集 & 需要处理编码格式)比喻为描述一个人的特点的集合(发型, 五官 ...),
在这里就是一个组成词法单元(token)的必要元素, 它是独立的, 简单的理解就是一个字符;
它看到所有特点以后就能确定这个人是谁了(词法单元token), 如果不认识这个人, 那么就报错(不过这似乎不容易发生, 思考为什么).
词法单元是一个无限的集合(所有字符的任意组合),怎样用有限的东西描述无限的东西?
2. 语法分析: 它只认识词法单元流, 只认识每个人, 你拿来他的衣服, 它不知道是谁的. 它会分析这群人是不是按照它要求组织的,
如, 列队必须从左到右从高到低排列, 你不这样排列它就会告诉你这样不行;语法规定了源程序的组织方法,
同样程序的集合是无限的, 自然语法也是一个无限的集合
3. 语义分析: 顾名思义, 分析这群人要干嘛? 有什么要求? 如, 男女面对面站, 哦你们几个要结婚啊!
4. 中间代码生成器: 知道了你们什么意思, 那我们(编译器)也没钱啊! 不过我们就是给你们传话的, 但这个最有资本的厉害家伙(处理器)
只能明白几句话(指令集), 而且很忙! 说厉害其实最傻逼, 你说什么它做什么, 所以一定要把话说的简练. 不然就给你
浪费时间. 所以为了说好话就生成一个好处理的话(ps:这说的什么话啊). 中间代码生成器就做了这个工作, 典型的有三地址代码,
这里的中间代码是与机器无关的, 有两个重要的性质: (1)易于生成 (2)能够方便的翻译为目标机器上的语言
5. 机器无关代码优化器: 它就是让话说的更短更好, 但它不知道处理器理解那种话更快, 所以它不会管机器
6. 代码生成器: 它负责将这些优化好的代码, 翻译成特定的处理器上的指令
7. 机器相关代码优化: 这里在优化这些机器认识的指令
8. 符号表: 它是记录程序中使用的变量的名字, 并在分析过程中收集名字的各种属性信息, 它是非常重要的, 它贯穿编译器的大部阶段
看了这些, 一定了解了编译器还有两个重要的工作: (1)错误处理, (2)优化
在这个过程中有三个分析(analysis)和中间代码生成, 把这称为编译器的前端(front end), 它们的工作完全何机器无关
而综合(synthesis)是为了构造我们所要的目标程序, 被称为后端(back end)
与机器无关的优化通常是加在编译器的前端与后端, 为了生成更好的目标代码
前端是分析后端是综合分析的结果产生目标程序, 如果不做任何优化, 为前端优化生成的中间代码也不是必须的, 不过一般不会这么做
编译器将优化看的很重要
前面说的编译器的各个阶段是编译器的逻辑组织方式. 在一个特定的实现中, 多个阶段的活动可以被组合为一趟或叫一遍(pass).
每遍读入一个输入文件产生一个输出文件(特点), 这便是pass的概念
五 我们常说的, 你理解吗?
1.动静之别
什么静态XX,动态XX;什么意思呢?
为一个语言设计编译器时,我们有一个主要矛盾:编译器能够为一个程序做出那些判定
如果一个语言使用的策略支持编译时(compile time)判定,那么我们就说这个语言的这个策略为静态策略(static)
相反一个只允许在程序运行时(run time)才能确定的策略称为动态策略(dynamic)
就像还在妈妈肚子里(编译时)的胎儿一样,他刚生下来(编译结束,就是这个点)就有一些确定的事实,大眼睛,双眼皮...
这当然在妈妈肚子里的时候就决定了(编译时),我们就可以说决定眼睛的大小是静态策略,而这个孩子的性格我们
还是不能直接看出的,这就看他走这一遭了(运行时),这里决定性格便是动态策略
哎! 例子有些rubbish啊
2.环境与状态

这里的名字就是我们程序中的各种标识符,它是高级语言提供给我们的超级武器啊! 编译器为名字做了大量工作
环境是一个名字到内存位置(变量)的映射, 所谓变量其实是内存的抽象,我们平时说的变量其实是一个侧重的说法
是命令式语言的特色,这样才有了副作用,左值之说(具体见从程序设计语言的发展谈起)
环境是什么,龙书里这样说“环境的改变需遵循语言的作用域规则”,不同的作用域里可以有相同的名字,但环境会让他们
找到自己的家
状态是一个内存位置到他们值的映射,用C语言的说法就是状态将左值映射为他们相应的右值
了解了这些大家是否可以思考C中的值调用(call-by-value)/传值和引用调用(call-by-reference)/传址的区别了,wiki上有关与这些的讲解
3.声明和定义
声明是告诉我们名字的类型, 而定义告诉我们它的值
int i = 1;
int i; 是i的一个声明, i = 1; 是i的一个定义(定值)
同样函数什么都一样的道理
转载请注明出处 哈喽易http://blog.csdn.net/openhfc
注:这篇博文主要让大家对编译系统有一个感觉, 若文中存在任何不当之处, 希望大家指出















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









