







初识Hadoop之HDFS
HDFS—Hadoop Distributed FileSystem :HDFS以前的名字是叫NDFS,即Nutch分布式文件系统,主要谈谈它的原理,这里就引用网上的的一些资料,自己经过理解后整理的一些漫画图。讲解原理之前,先来看看在集群中的一系列后台程序。它们分别是Namenode、Datanode、Scondary Namenode,
Namenode
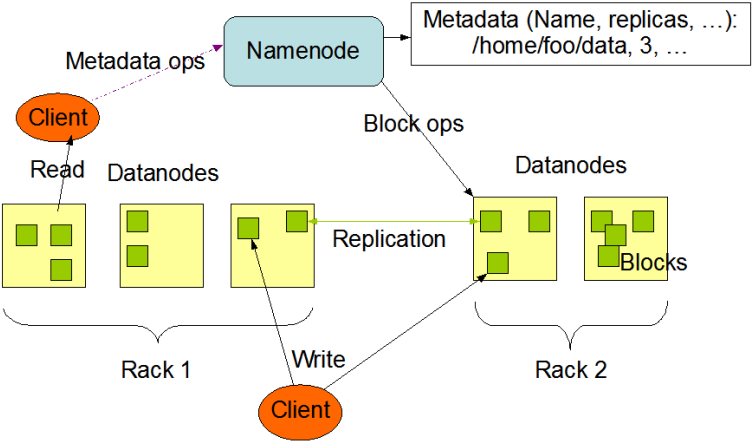
Namenode 管理着文件系统的Namespace。它维护着文件系统树以及文件树中所有的文件和文件夹的元数据。管理这些信息的文件有两个,分别是Namespace 镜像文件和操作日志文件,这些信息被缓存在RAM中,当然,这两个文件也会被持久化存储在本地硬盘。Namenode记录着每个文件中各个块所在的数据节点的位置信息,但是他并不持久化存储这些信息,因为这些信息会在系统启动时从数据节点重建。从图中可以看出,namenode是不直接参与文件信息的读取与写入的,namenode只是给Client提供整个文件系统树,按照一定的算法给它分配它所需要的datanode,然后Client直接和Datanode交互。
Datanode
Datanode是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表。
集群中的每个服务器都运行一个DataNode后台程序,这个后台程序负责把HDFS数据块读写到本地的文件系统。当需要通过客户端读/写某个 数据时,先由NameNode告诉客户端去哪个DataNode进行具体的读/写操作,然后,客户端直接与这个DataNode服务器上的后台程序进行通 信,并且对相关的数据块进行读/写操作。
Secondary NameNode
Secondary NameNode是一个用来监控HDFS状态的辅助后台程序。就像NameNode一样,每个集群都有一个Secondary NameNode,并且部署在一个单独的服务器上。Secondary NameNode不同于NameNode,它不接受或者记录任何实时的数据变化,但是,它会与NameNode进行通信,以便定期地保存HDFS元数据的 快照。由于NameNode是单点的,通过Secondary NameNode的快照功能,可以将NameNode的宕机时间和数据损失降低到最小。同时,如果NameNode发生问题,Secondary NameNode可以及时地作为备用NameNode使用。
知道了各个节点最基本的介绍后,那么下面就通过一组漫画来深入理解HDFS
一:系统中的三大部分
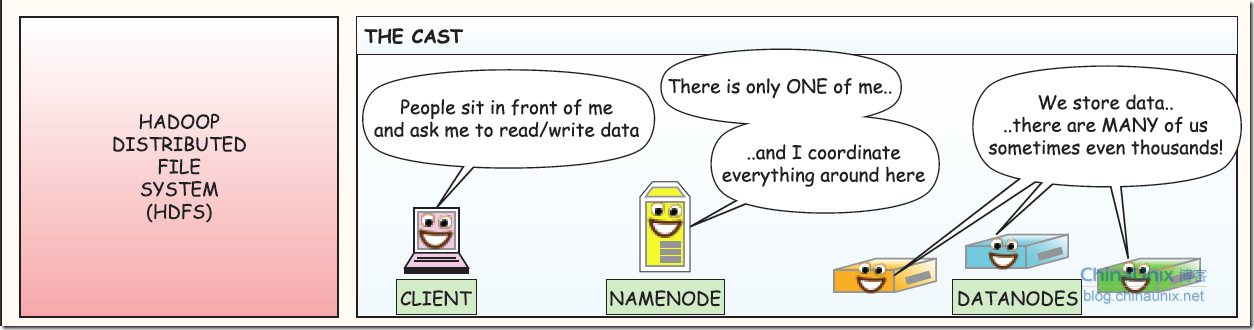
从图中可以知道的是
Client:用户通过与namenode和datanode交互来访问整个文件系统 <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









