







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
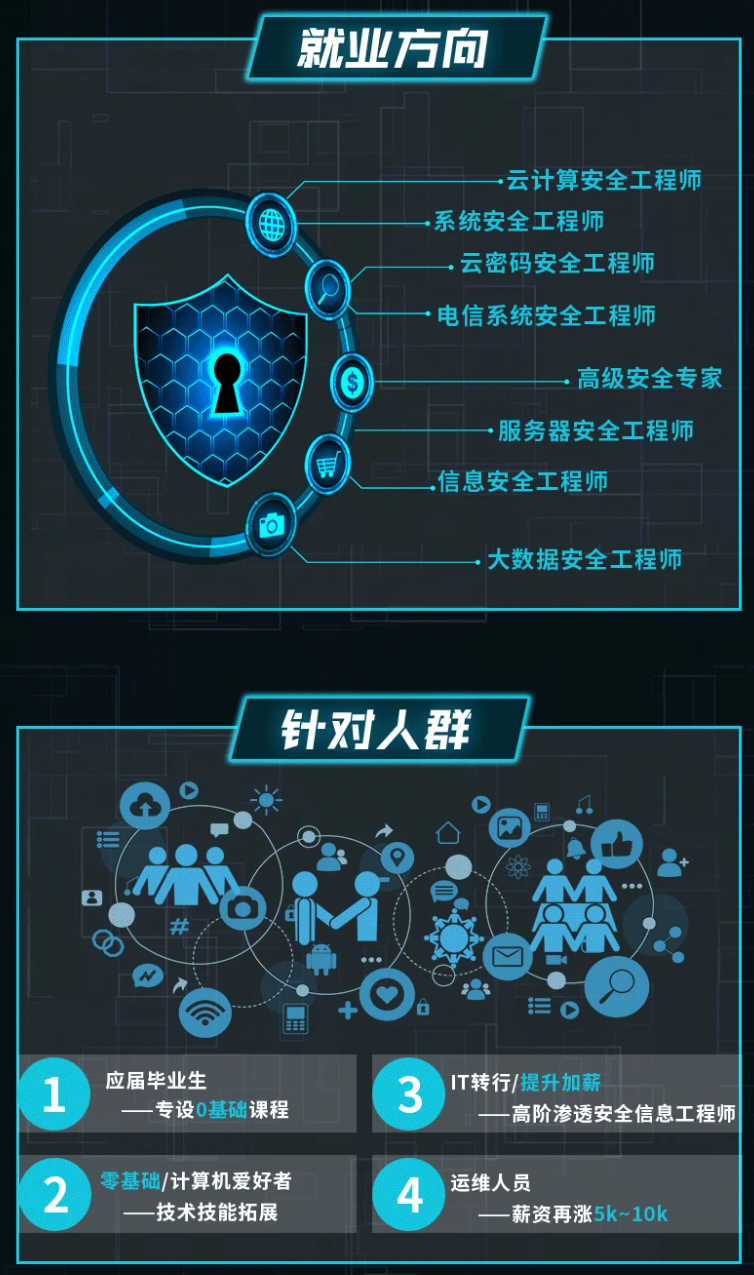
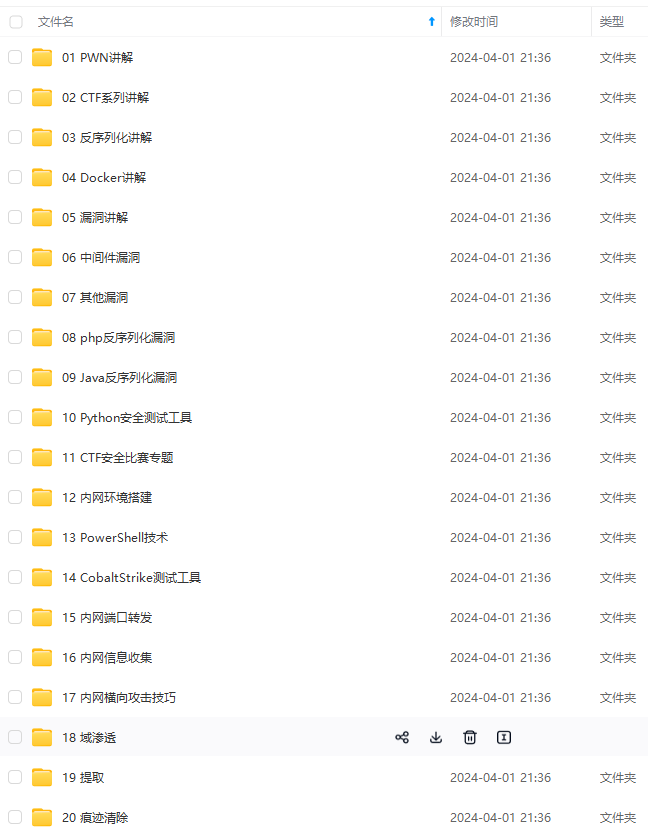
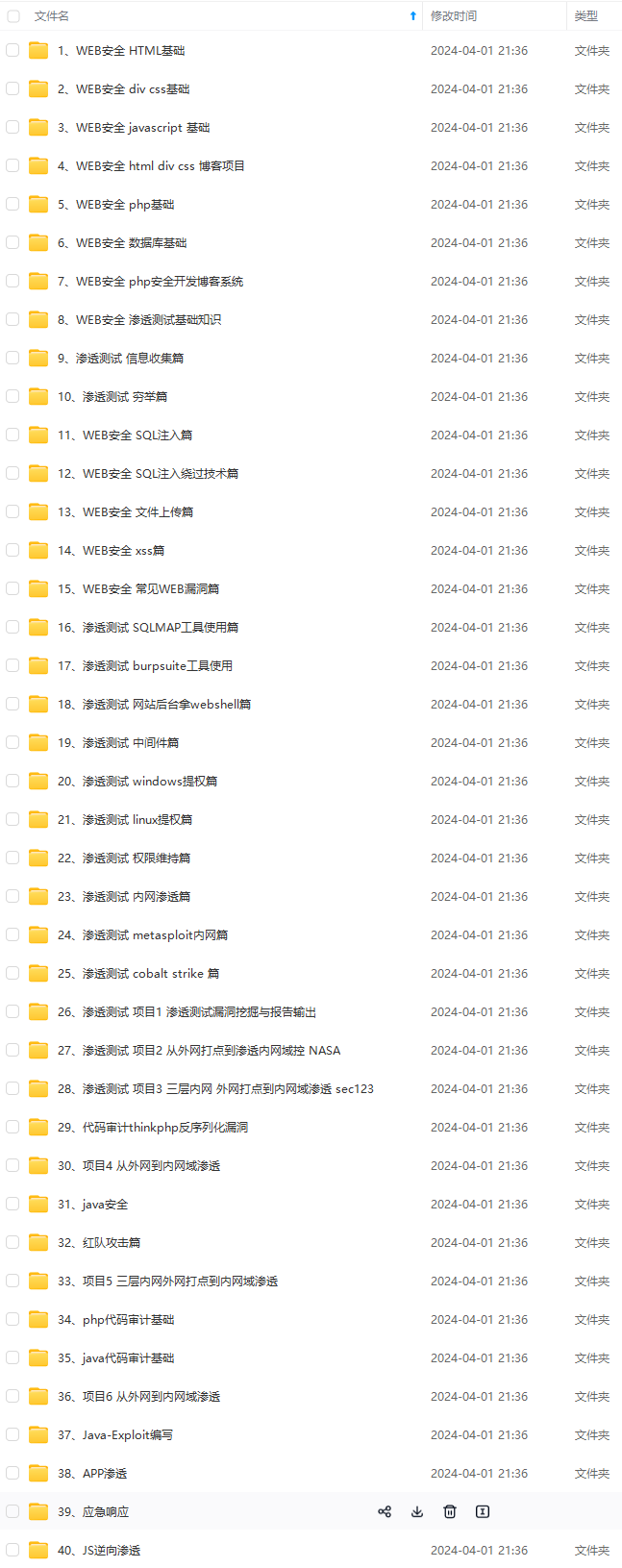
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
| %G | %F 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
辅助符号
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| 在正数前面显示空格 | |
| # | 在八进制数前面显示零(‘0’),在十六进制前面显示’0x’或者’0X’(取决于用的是’x’还是’X’) |
| 0 | 显示的数字前面填充’0’而不是默认的空格 |
| % | ‘%%‘输出一个单一的’%’ |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
‘grade:%f’ % 12.345678
‘grade:12.345678’‘grade:%.2f’ % 92.2354
‘grade:92.24’‘grade:%c’ % 66
‘grade:B’‘grade:%s’ % ‘good’
‘grade:good’
更多内容,读者自行尝试吧。
f"{}"
python版本>=3.6
比上面的,以及.format()效率要高。如果你的python版本高一点,建议使用这个。
同样,格式化符号有很多,博主不再黏贴,针对数字,字符串,时间之类的都有,黏贴的话文章太长。
例如,datetime的格式化符号。
举例
代码:
from datetime import datetime
now = datetime.now()
print(f’datetime_now:{now:%F %X}')
terminal:
datetime_now:2020-09-05 09:39:15
pycharm里面敲的,不是交互式。
转义字符
转义字符
| 转义字符 | 描述 |
|---|---|
| (在行尾时) | 续行符 |
| \ | 反斜杠符号 |
| ’ | 单引号 |
| " | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy代表的字符,例如:\o12代表换行 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
代码:
print(‘hello\nworld’)
terminal:
hello
world
原始字符串(操作符r)
这个没有放到前面的操作符中,因为在转义字符后面讲比较好。r可以使字符串里面就是字符串内容本身,没有转义等。
代码:
print(r’hello\nworld’)
terminal:
hello\nworld
在pycharm中不加r时,字符串中的\n是橘色的,加了后就是绿色了。
方法
s = ‘hello world’
type(s)
<class ‘str’>
一个字符串是类str的一个对象,也就可以调用str类的方法。
拆分
split(sep=None, maxsplit=-1)
返回一个由字符串内单词组成的列表,使用 sep 作为分隔字符串。 如果给出了 maxsplit,则最多进行 maxsplit 次拆分(因此,列表最多会有 maxsplit+1 个元素)。 如果 maxsplit 未指定或为 -1,则不限制拆分次数(进行所有可能的拆分)。
如果给出了 sep,则连续的分隔符不会被组合在一起而是被视为分隔空字符串 (例如 '1,,2'.split(',') 将返回 ['1', '', '2'])。 sep 参数可能由多个字符组成 (例如 '1<>2<>3'.split('<>') 将返回 ['1', '2', '3'])。 使用指定的分隔符拆分空字符串将返回 ['']。
sep没给的话是默认是空格,几个空格都可以。
“hello world,i’m lady_killer”.split(‘,’)
[‘hello world’, “i’m lady_killer”]
“hello wor ld,i’m lady_killer”.split()
[‘hello’, ‘wor’, “ld,i’m”, ‘lady_killer’]
rsplit方法参数相同,不同的是从右边开始
拼接
join(iterable)
返回一个由 iterable (可迭代的对象)中的字符串拼接而成的字符串。 如果 iterable 中存在任何非字符串值包括bytes对象则会引发TypeError。 调用该方法的字符串将作为元素之间的分隔。
‘:’.join(“2020 09 05 13 54”.split())
‘2020:09:05:13:54’
替换
replace(old, new[, count])
返回字符串的副本,其中出现的所有子字符串 old 都将被替换为 new。 如果给出了可选参数 count,则只替换前 count 次出现。
>>> “”.join(“hello world,i’m lady killer”[::-1]).replace(‘dlrow’,‘world’)
“rellik ydal m’i,world olleh”
移除前导、末尾字符
strip([chars])
返回原字符串的副本,移除其中的前导和末尾字符。 chars 参数为指定要移除字符的字符串。 如果省略或为 None,则 chars 参数默认移除空格符。 实际上 chars 参数并非指定单个前缀或后缀;而是会移除参数值的所有组合。
" hello world ".strip()
‘hello world’
"12.45 ".strip()
‘12.45’
“2323345623323”.strip(‘32’)
‘456’
32可以组合成2、3、23、32等。 你可以理解为前后遍历含chars中任一字符便删除,无法删除时停止。
统计子串
count(sub[, start[, end]])
返回子字符串 sub 在 [start, end] 范围内非重叠出现的次数,默认是整个字符串。 可选参数 start 与 end, 会被解读为切片表示法。
‘www.example.com’.count(‘com’)
1‘www.example.com’.count(‘w’,1,7)
2
寻找子串索引
find(sub[, start[, end]])
返回子字符串 sub 在 s[start:end] 切片内被找到的最小索引。 可选参数 start 与 end 会被解读为切片表示法。 如果 sub 未被找到则返回 -1。
‘www.example.com’.find(‘w’,1,7)
1
‘www.example.com’.find(‘w’,3,7)
-1
rfind方法,参数相同,返回找到的最大的索引
index与rindex在未找到时会引发ValueError,不建议使用。
转换大小写
转为小写
lower()
返回原字符串的副本,其所有区分大小写的字符均转换为小写。
‘WWW.example.com’.lower()
‘www.example.com’
转为大写
upper()
返回原字符串的副本,其中所有区分大小写的字符均转换为大写。 请注意如果 s 包含不区分大小写的字符或者如果结果字符的 Unicode 类别不是 “Lu” (Letter, uppercase) 而是 “Lt” (Letter, titlecase) 则 s.upper().isupper() 有可能为 False。
>>> ‘www.example.com’.upper()
‘WWW.EXAMPLE.COM’
判断字符串类型
全是字母
isalpha()
如果字符串中的所有字符都是字母,并且至少有一个字符,返回 True ,否则返回 False 。字母字符是指那些在 Unicode 字符数据库中定义为 “Letter” 的字符,即那些具有 “Lm”、“Lt”、“Lu”、“Ll” 或 “Lo” 之一的通用类别属性的字符。 注意,这与 Unicode 标准中定义的"字母"属性不同。
‘www.example.com’.isalpha()
False
‘wwwexamplecom’.isalpha()
True
全是数字
isdecimal()
如果字符串中的所有字符都是十进制字符且该字符串至少有一个字符,则返回 True , 否则返回 False 。十进制字符指那些可以用来组成10进制数字的字符,例如 U+0660 ,即阿拉伯字母数字0 。 严格地讲,十进制字符是 Unicode 通用类别 “Nd” 中的一个字符。
‘1’.isdecimal()
True‘IV’.isdecimal()
False‘六六六’.isdecimal()
False
isdigit()
如果字符串中的所有字符都是数字,并且至少有一个字符,返回 True ,否则返回 False 。 数字包括十进制字符和需要特殊处理的数字,如兼容性上标数字。这包括了不能用来组成十进制数的数字,如 Kharosthi 数。 严格地讲,数字是指属性值为 Numeric_Type=Digit 或 Numeric_Type=Decimal 的字符。
‘IV’.isdigit()
False
‘六六六’.isdigit()
False
isnumeric()
如果字符串中至少有一个字符且所有字符均为数值字符则返回 True ,否则返回 False 。 数值字符包括数字字符,以及所有在 Unicode 中设置了数值特性属性的字符,例如 U+2155, VULGAR FRACTION ONE FIFTH。 正式的定义为:数值字符就是具有特征属性值 Numeric_Type=Digit, Numeric_Type=Decimal 或 Numeric_Type=Numeric 的字符。
‘IV’.isnumeric()
False‘六六六’.isnumeric()
True
大小写
isupper()
如果字符串中至少有一个区分大小写的字符 4 且此类字符均为大写则返回 True ,否则返回 False 。
islower()
如果字符串中至少有一个区分大小写的字符 4 且此类字符均为小写则返回 True ,否则返回 False 。
对齐
居中
center(width[, fillchar])
返回长度为 width 的字符串,原字符串在其正中。 使用指定的 fillchar 填充两边的空位(默认使用 ASCII 空格符)。 如果 width 小于等于 len(s) 则返回原字符串的副本。
左对齐
ljust(width[, fillchar])¶
返回长度为 width 的字符串,原字符串在其中靠左对齐。 使用指定的 fillchar 填充空位 (默认使用 ASCII 空格符)。 如果 width 小于等于 len(s) 则返回原字符串的副本。
右对齐
rjust(width[, fillchar])
返回长度为 width 的字符串,原字符串在其中靠右对齐。 使用指定的 fillchar 填充空位 (默认使用 ASCII 空格符)。 如果 width 小于等于 len(s) 则返回原字符串的副本。
zfill(width)
返回原字符串的副本,在左边填充 ASCII '0' 数码使其长度变为 width。 正负值前缀 ('+'/'-') 的处理方式是在正负符号 之后 填充而非在之前。 如果 width 小于等于 len(s) 则返回原字符串的副本。
格式化
format(*args, **kwargs)
执行字符串格式化操作。 调用此方法的字符串可以包含字符串字面值或者以花括号 {} 括起来的替换域。 每个替换域可以包含一个位置参数的数字索引,或者一个关键字参数的名称。 返回的字符串副本中每个替换域都会被替换为对应参数的字符串值。
其他
方法太多,上面列举了经常用的,其余的请查看官方文档。
相关内置函数
字符串长度
不像c++ string,没有length()方法,但可以使用len函数返回长度。
len(s)
返回对象的长度(元素个数)。
len(‘hello world’)
11
字符的Unicode码
chr(i)
返回 Unicode 码位为整数 i 的字符的字符串格式。
ord(c)
对表示单个 Unicode 字符的字符串,返回代表它 Unicode 码点的整数。
chr(97)
‘a’
ord(‘a’)
97
其他类型转为字符串
class str(object=b’', encoding=‘utf-8’, errors=‘strict’)
返回一个str版本的对象
num = 65
s = str(num)
type(s)
<class ‘str’>
常用函数
常在oj中使用的函数
获得所有非空子串
列表表达式+切片
def get_substring(a_str):
n = len(a_str)
return [a_str[i:j + 1] for i in range(n) for j in range(i, n)]
获得所有非空子序列
二进制+位运算
def get_subsequence(a_str):
n = len(a_str)
sub_sequence = []
for i in range(1, 1 << n):
substr = ""
for j in range(n):
if i >> j & 1 == 1:
substr += a_str[j]
sub_sequence.append(substr)
return sub_sequence
判断是不是非空字符串的非空子序列
双指针
def is_subsequence(a, b):
i, j, m, n = 0, 0, len(a), len(b)
while j < n and i < m:
if a[i] == b[j]:
i += 1
j += 1
else:
i += 1
return j == n
判断是否为回文字符串
双指针
def is_huiwen(a_str):
left, right = 0, len(a_str) - 1
while left < right:
if a_str[left] != a_str[right]:
return False
left += 1
right -= 1
return True
相关模块
- string — 常见的字符串操作
- re — 正则表达式操作
- difflib — 计算差异的辅助工具
- textwrap — 文本自动换行与填充
- unicodedata — Unicode 数据库
- stringprep — 因特网字符串预备
- readline — GNU readline 接口
- rlcompleter — GNU readline 的补全函数
如何自学黑客&网络安全
黑客零基础入门学习路线&规划
初级黑客
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:282G全网最全的网络安全资料包评论区留言即可领取!
7、脚本编程(初级/中级/高级)
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
如果你零基础入门,笔者建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习;搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime;·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完;·用Python编写漏洞的exp,然后写一个简单的网络爬虫;·PHP基本语法学习并书写一个简单的博客系统;熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选);·了解Bootstrap的布局或者CSS。
8、超级黑客
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,附上学习路线。
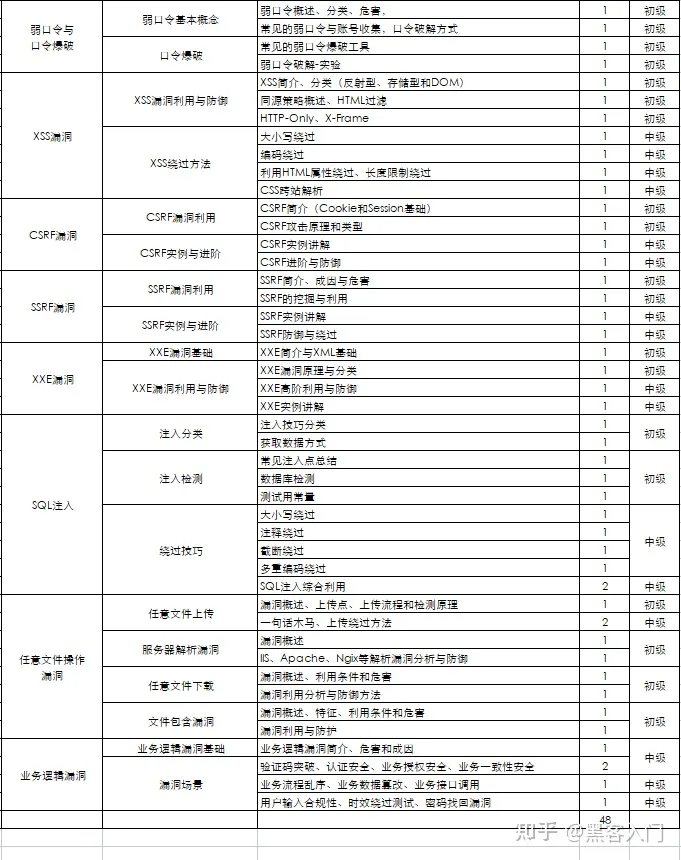
网络安全工程师企业级学习路线

如图片过大被平台压缩导致看不清的话,评论区点赞和评论区留言获取吧。我都会回复的
视频配套资料&国内外网安书籍、文档&工具
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

一些笔者自己买的、其他平台白嫖不到的视频教程。
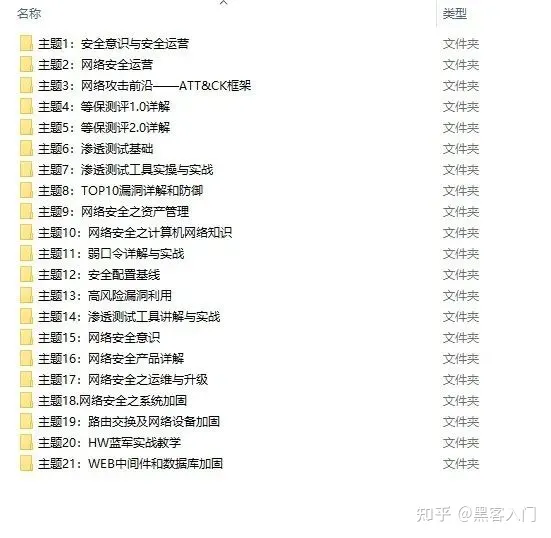
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
师企业级学习路线
如图片过大被平台压缩导致看不清的话,评论区点赞和评论区留言获取吧。我都会回复的
视频配套资料&国内外网安书籍、文档&工具
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。
一些笔者自己买的、其他平台白嫖不到的视频教程。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









