










 本文介绍了一款基于Python的拉勾网爬虫项目,该项目实现了对杭州地区数据采集岗位的招聘信息爬取,并通过Flask进行了数据可视化展示。
本文介绍了一款基于Python的拉勾网爬虫项目,该项目实现了对杭州地区数据采集岗位的招聘信息爬取,并通过Flask进行了数据可视化展示。
文章目录
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 python招聘大数据分析与可视化
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分
🧿 选题指导, 项目分享:
1 课题背景
基于Python的拉钩网杭州爬虫相关职位大数据可视化分析,爬取了杭州有关数据采集岗位的相关数据, 并进行分析,在用Flask进行可视化展示。
2 实现效果
web服务
身份验证
分析页
数据分析
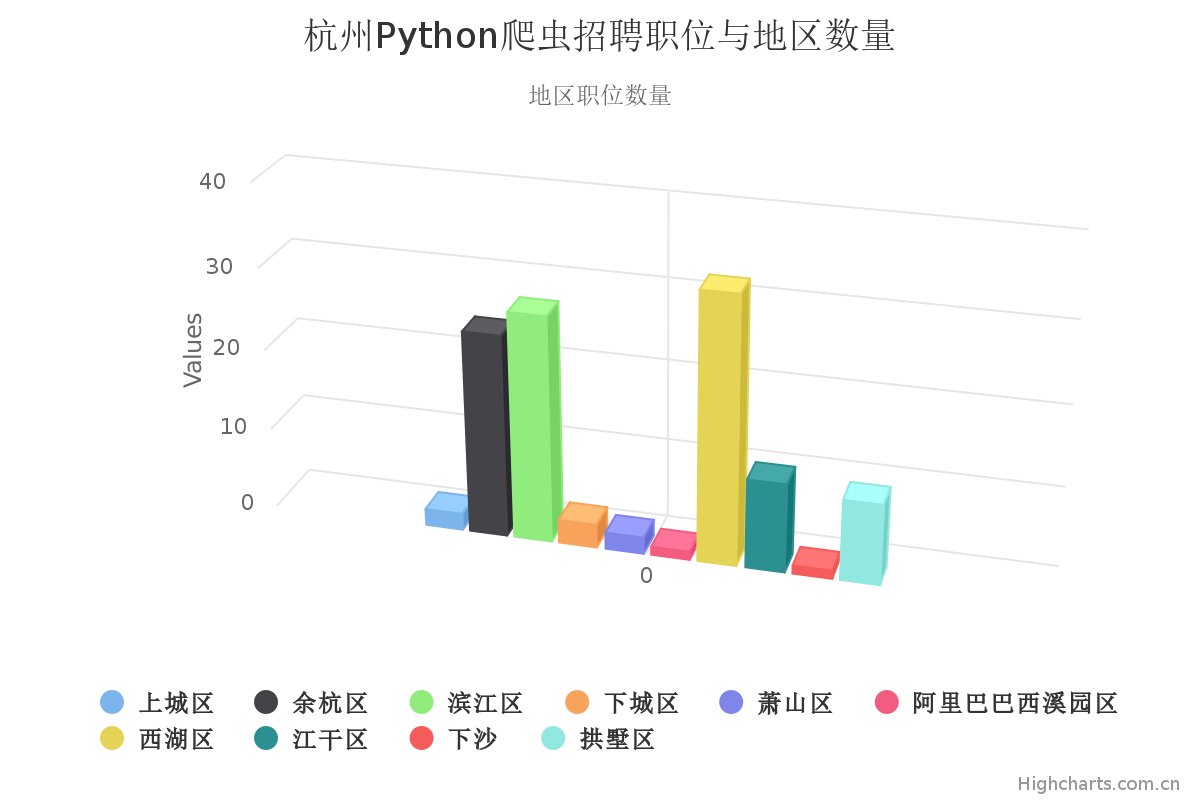
职位地区数量
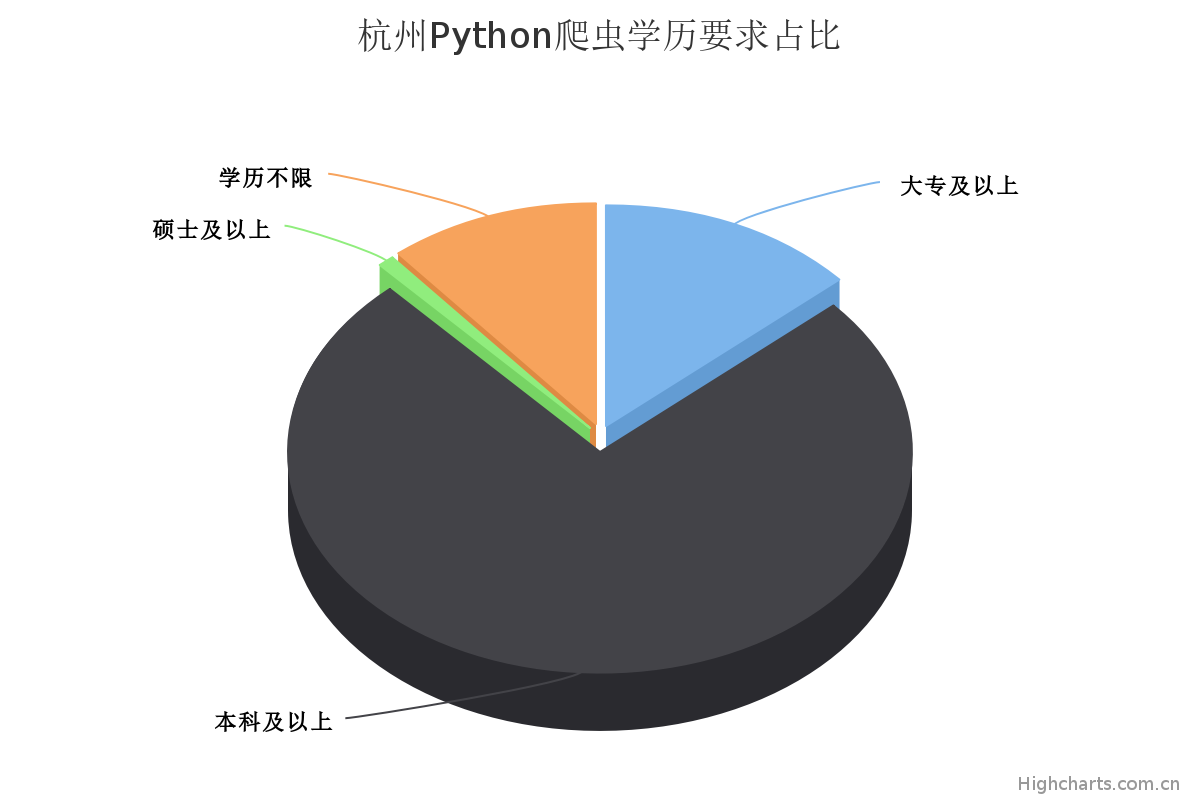
学历要求占比
职位描述词云

3 项目实现
在整体结构上涉及三个部分,
- 数据采集
- 数据存储
- 数据分析与可视化
数据采集
在数据采集上,使用 Scrapy-Redis和Redis来实现多机器分布爬取,目标网站是拉钩网,由于拉钩网的反爬 还是比较严厉的,所以需要进行一下防ban的操作。
防Ban操作
如果在不采取防Ban操作的情况下,那么会触发lagou网的反爬机制,会强制302到登录页面,所以有必要采取一下相关操作
下载延迟
这里采用scrapy 的自动下载延迟扩展
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_START_DELAY = 10
AUTOTHROTTLE_MAX_DELAY = 10
AUTOTHROTTLE_DEBUG = True
使用IP代理
- 自己维护IP池:这样的方式不推荐。因为这样的方式所获取的IP质量不高。
- 设置代理IP:花钱买个代理IP,这样会好一下
添加随机UA操作
useragent ,request_header这是网页对于访问者的验证,在爬虫中需要设置UserAgent,否则部分网络将无法爬取。
- 使用第三方随机UA的库
- 添加中间件,进行UA的随机切换
- 代码如下
# -*- coding: utf-8 -*-
from fake_useragent import UserAgent
class RandomUserAgentMiddlware(object):
# 随机更换user-agent
def __init__(self, crawler):
super(RandomUserAgentMiddlware, self).__init__()
self.ua = UserAgent()
self.ua_type = crawler.settings.get("RANDOM_UA_TYPE", "random")
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
# 当每个request通过下载中间件时,该方法被调用。
def get_ua():
return getattr(self.ua, self.ua_type)
request.headers.setdefault('User-Agent', get_ua())
添加针对JS的抓取支持
由于拉钩网的页面都是是用js来加载数据的,所有这里需要使用一种方式来处理JS,其实方式有很多,这里我采用的是selenium+PhantomJS的方式:
- 引入selenium和PhantomJS
- 编写中间件进行js的处理
import os
import scrapy
from scrapy import signals
from scrapy.xlib.pydispatch import dispatcher
from selenium import webdriver
class LgspiderSpider(scrapy.Spider):
name = 'LGSpider'
allowed_domains = ['lagou.com']
start_urls = [
"https://www.lagou.com/jobs/list_python%E7%88%AC%E8%99%AB?px=default&city=%E6%9D%AD%E5%B7%9E"
]
def __init__(self, callbackUrl=None, **kwargs):
super(LgspiderSpider, self).__init__()
dispatcher.connect(self.spider_open_receiver, signals.spider_opened)
dispatcher.connect(self.spider_closed_receiver, signals.spider_closed)
def spider_open_receiver(self):
self.logger.info('Notice!! !!!Spider is start')
self.webkit_dir = self.crawler.settings.get("WEBKIT_DIR", "Error")
self.webkit = os.path.join(self.webkit_dir, r'phantomjs-2.1.1-windows\bin\phantomjs.exe')
self.logger.info('Notice!! !!!Init webkit from dir %s' % self.webkit)
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = False
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.settings.userAgent"] = "Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0"
cap["phantomjs.page.customHeaders.User-Agent"] = 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0'
self.driver = webdriver.PhantomJS(executable_path=self.webkit, desired_capabilities=cap)
def spider_closed_receiver(self):
self.logger.info('Notice!! Spider is closed')
if self.driver is not None:
self.driver.quit()
- 中间件
from scrapy.http import HtmlResponse
class DynamicCrawlMiddleware(object):
def __init__(self, crawler):
super(DynamicCrawlMiddleware, self).__init__()
self.isDynamic = crawler.settings.getbool('DYNAMIC_CRAWL', False)
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
if self.isDynamic:
spider.driver.capabilities['phantomjs.page.settings.userAgent'] = UserAgent()
spider.driver.capabilities['phantomjs.page.customHeaders.User-Agent'] = UserAgent()
spider.driver.get(request.url)
import time
time.sleep(2)
spider.logger.info("load url for WebKit:{0}".format(spider.driver.current_url))
return HtmlResponse(url=spider.driver.current_url, body=spider.driver.page_source, encoding="utf-8",request=request)
'''
setting.py
'''
# 是否使用Webkit来执行动态加载
DYNAMIC_CRAWL = True
RANDOM_UA_TYPE = "random"
DOWNLOADER_MIDDLEWARES = {
'LaGouSpiderProject.middlewares.RandomUserAgentMiddlware': 543,
'LaGouSpiderProject.middlewares.DynamicCrawlMiddleware': 540,
}
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'www.lagou.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
定义条目加载器
- 定义解析字段,定义架加载器
- 字段如下
import scrapy
class LagouJobItem(scrapy.Item): # 拉勾网职位信息
title = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
salary = scrapy.Field()
job_city = scrapy.Field()
work_years = scrapy.Field()
degree_need = scrapy.Field()
job_type = scrapy.Field()
publish_time = scrapy.Field()
job_advantage = scrapy.Field()
job_desc = scrapy.Field()
job_addr = scrapy.Field()
company_name = scrapy.Field()
company_url = scrapy.Field()
tags = scrapy.Field()
crawl_time = scrapy.Field()
### 进行数据提取
> 数据提取这里,要使用 `Xpath`和`Css`选择器来进行数据的解析具体的解析规则如下
* 编写解析规则
* 进行数据解析
```python
from datetime import datetime
from scrapy.exceptions import CloseSpider, IgnoreRequest
from scrapy.http import Request
from LaGou.LaGouSpiderProject.items import LagouJobItemLoader, LagouJobItem
def parse(self, response):
'''
拉钩网的职位列表信息中,第一条数据与其他的条目数据是不同的,这里需要注意
:param response:
:return:
'''
if response.status is not 200:
raise CloseSpider()
# 解析职位列表中第一条数据并生成请求
xpath_div_first_li_position = response.xpath(
'//div[@class="s_position_list "]/ul[@class="item_con_list"]/li[@class="con_list_item first_row default_list"]')
first_position_address_link_list = xpath_div_first_li_position.xpath(
'./div[@class="list_item_top"]/div[@class="position"]/div[@class="p_top"]/a[@class="position_link"]/@href').extract()
for detail_first_page_url in first_position_address_link_list:
yield Request(url=detail_first_page_url, callback=self.detail_page_data)
# 解析职位列表中其余的数据,并生成请求
xpath_default_li_posittion = response.xpath(
'//div[@class="s_position_list "]/ul[@class="item_con_list"]/li[@class="con_list_item default_list"]')
value_default_page_link_list = xpath_default_li_posittion.xpath(
'./div[@class="list_item_top"]/div[@class="position"]/div[@class="p_top"]/a[@class="position_link"]/@href').extract()
print value_default_page_link_list
for default_detail_page_link in value_default_page_link_list:
yield Request(url=default_detail_page_link, callback=self.detail_page_data)
def detail_page_data(self, response):
if response.status is not 200:
raise IgnoreRequest()
# 解析拉勾网的职位
item_loader = LagouJobItemLoader(item=LagouJobItem(), response=response)
item_loader.add_css("title", ".job-name::attr(title)")
item_loader.add_value("url", response.url)
# item_loader.add_value("url_object_id", common.get_md5(response.url))
item_loader.add_css("salary", ".job_request .salary::text")
item_loader.add_xpath("job_city", "//*[@class='job_request']/p/span[2]/text()")
item_loader.add_xpath("work_years", "//*[@class='job_request']/p/span[3]/text()")
item_loader.add_xpath("degree_need", "//*[@class='job_request']/p/span[4]/text()")
item_loader.add_xpath("job_type", "//*[@class='job_request']/p/span[5]/text()")
item_loader.add_css("tags", '.position-label li::text')
item_loader.add_css("publish_time", ".publish_time::text")
item_loader.add_css("job_advantage", ".job-advantage p::text")
item_loader.add_css("job_desc", ".job_bt div")
item_loader.add_css("job_addr", ".work_addr")
item_loader.add_css("company_name", "#job_company dt a img::attr(alt)")
item_loader.add_css("company_url", "#job_company dt a::attr(href)")
item_loader.add_value("crawl_time", datetime.now())
job_item = item_loader.load_item()
return job_item
数据清洗
提出来的数据是不规范的,需要进行一下清洗,需要使用 MapCompose, TakeFirst, Join,remove_tags的函数
- 去空格
- 去网页标签
- 去特殊符号
- 格式化时间
import scrapy
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose, TakeFirst, Join
from w3lib.html import remove_tags
from LaGou.LaGouSpiderProject.Util import common
def formatTime(value):
# 对抓取的时间进行计算,格式化
return common.format_time(value)
def remove_splash(value):
# 去掉工作城市的斜线
return value.replace("/", "")
def handle_jobaddr(value):
addr_list = value.split("\n")
addr_list = [item.strip() for item in addr_list if item.strip() != "查看地图"]
return "".join(addr_list)
def handle_jobdecs(value):
decs_list = value.split("\n")
return "".join(decs_list)
class LagouJobItem(scrapy.Item):
# 拉勾网职位信息
title = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
salary = scrapy.Field()
job_city = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
work_years = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
degree_need = scrapy.Field(
input_processor=MapCompose(remove_splash),
)
job_type = scrapy.Field()
publish_time = scrapy.Field()
job_advantage = scrapy.Field()
job_desc = scrapy.Field(
input_processor=MapCompose(remove_tags,handle_jobdecs),
)
job_addr = scrapy.Field(
input_processor=MapCompose(remove_tags, handle_jobaddr),
)
company_name = scrapy.Field()
company_url = scrapy.Field()
tags = scrapy.Field(
input_processor=Join(",")
)
crawl_time = scrapy.Field()
数据入库
- 用Flask的orm框架来生成对用的数据库,来存放爬虫爬到的数据
- 涉及的字段尽量和items中一致。
- 并且需要考虑入库操作的异步的模式
4 数据分析与可视化
在数据可视化上,使用Flask来实现一个WebServer,因为Flask比较轻,所以我非常喜欢Flask,基于插件,想要什么功能 直接用插件来实现即可。用Flask来进行数据的可视化,可以分析一下,杭州各个区的数据采集相关的职位数量,薪资和工作年限的分布清空 或者统计一下,在任职需求中出现频率最高的词汇 Top10等等。
创建Flask
这个没有什么太特别的地方
# coding:utf8
from flask import Flask
import WebConfig
app = Flask(__name__)
app.config.from_object(WebConfig)
@app.route('/')
def index():
return 'hello Spider'
if __name__ == '__main__':
app.run()
构建命令行操作
为了能在cmd/shell中控制WebServer和Spider,需要设计几个操作命令,使用的是flask_script
提供以下几个命令
- db init (数据库初始化)
- create_admin -a <帐户名> - p <密码>
- 用于向数据库种添加Admin,用于登录WebServer
- 需要使用者 在命令行中进行输入,并加密储存
- runserver -host <帐户名> -port <密码> (启动WebServer)
- 接受用户输入的 host 和 port 进行host和port设置
- 默认是在 host=127.0.0.1 port = 5000 下运行
- runspider -debug <是否是调试模式> (启动Spider)
- 模式模式下,会自动将爬取的数据输出到 data.json文件中
- drop_all_db 重置数据库,进行信息提示,需要用户输入确认信息才能执行。
由于进行到此时,还没有进行db相关操作,所有先实现 runserver和 runspider的俩个部分的逻辑,
这里要注意项目的目录结构,否则会出现问题,可以参考d代码中的目录结构
在根目录创建 一个 Manager.py这样的一个文件用于命令的管理 部分代码如下
# coding:utf8
from flask_script import Manager
from scrapy import cmdline
from LaGouSpiderProject.WebServer.WebServer import app
manager = Manager(app=app)
@manager.option('-host', '--host', dest='host', help='run server host', default='127.0.0.1')
@manager.option('-port', '--port', dest='port', help='run server port', default=5000)
def runserver(host, port):
app.run(host=host, port=port)
@manager.option('-debug', '--debug', dest='debug', help='is debug ??', default=1)
def runspider(debug):
if debug == 0:
cmdline.execute('scrapy crawl LGSpider -o data.json -t json'.split())
else:
cmdline.execute('scrapy crawl LGSpider'.split())
if __name__ == '__main__':
manager.run()

















 1036
1036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









