






0 简介
今天学长向大家分享一个毕业设计项目
毕业设计 深度学习语义分割实现弹幕防遮(源码分享)
🧿 项目分享:见文末!
1 课题背景
弹幕是显示在视频上的评论,可以以滚动、停留甚至更多动作特效方式出现在视频上,是观看视频的人发送的简短评论。
各大视频网站目前都有弹幕功能,之家也于2020年5月正式上线视频弹幕功能,受到了广大网友的喜爱,大家在观看视频的同时,也能通过弹幕进行互动。
但密集的弹幕,遮挡视频画面,严重影响用户观看体验,如何解决?

查阅了相关视频网站,发现B站推出了一种蒙版弹幕技术,可以让弹幕自动躲避人形区域,达到弹幕不挡人的效果。
B站视频弹幕不挡人的效果

2 技术原理和方法
2.1基本原理
通过AI计算机视觉的技术,对视频内容进行分析,并将之前已经定义好的“视频主体内容”进行识别,生成蒙版并分发给客户端后,让客户端利用 CSS3 的特性进行渲染从而达成最终的效果。这样就形成了我们最终看到的,“不挡脸”弹幕效果。
实现方法就正如 PS 中的“蒙版“一样,实心区域允许,空白区域拒绝,从而达到弹幕不挡人的效果。而技术的核心就在蒙版的生成上,所以将这个功能称之为“蒙版弹幕”。
2.2 技术选型和方法
1、提取视频帧画面。对音视频的处理,大家一般都会想到FFmpeg组件,我们也是使用FFmpeg组件提取每帧的视频画面,使用的是PyAV组件,PyAV是FFmpeg封装,能够灵活的编解码视频和音频,并且支持Python常用的数据格式(如numpy)。
2、识别视频帧画面人像区域。解决方案:使用AI计算机视觉的实例分割技术,可以识别视频帧画面的人像区域。
3、AI框架:目前市面上的AI框架,主要以TensorFlow,PyTorch最流行。
- TensorFlow:出身豪门的工业界霸主,由Google Brain团队研发。具有如下优点:支持多种编程语言;灵活的架构支持多GPU、分布式训练,跨平台运行能力强;自带TensorBoard组件,能可视化计算图,便于让用户实时监控观察训练过程;官方文档非常详尽,可查询资料众多;社区庞大,大量开发者活跃于此。
- PyTorch:以动态图崛起的学术界宠儿,是基于Torch并由Facebook强力支持的python端的开源深度学习库。具有如下优点:简洁:PyTorch在设计上更直观,追求尽量少的封装,建模过程透明,代码易于理解;易用:应用十分灵活,接口沿用Torch,契合用户思维,尽可能地让用户实现“所思即所得”,不过多顾虑框架本身的束缚;社区:提供完整的文档和指南,用户可以通过全面的教程完成从入门到进阶,有疑问也可以在社区中获得各种及时交流的机会。我们的选择:PyTorch。原因:TensorFlow入门难度较大,学习门槛高,系统设计过于复杂;而PyTorch入门难度低,上手快,而且提供的功能也非常易用,预训练模型也非常多。
4、实例分割技术:实例分割(Instance Segmentation)是视觉经典四个任务中相对最难的一个,它既具备语义分割(Semantic Segmentation)的特点,需要做到像素层面上的分类,也具备目标检测(Object Detection)的一部分特点,即需要定位出不同实例,即使它们是同一种类。
3 实例分割
简介
实例分割已成为机器视觉研究中比较重要、复杂和具有挑战性的领域之一。为了预测对象类标签和特定于像素的对象实例掩码,它对各种图像中出现的对象实例的不同类进行本地化。实例分割的目的主要是帮助机器人,自动驾驶,监视等。
实例分割同时利用目标检测和语义分割的结果,通过目标检测提供的目标最高置信度类别的索引,将语义分割中目标对应的Mask抽取出来。实例分割顾名思义,就是把一个类别里具体的一个个对象(具体的一个个例子)分割出来。

Mask R-CNN算法
本项目使用Mask R-CNN算法来进行图像实例分割。
网络结构图:
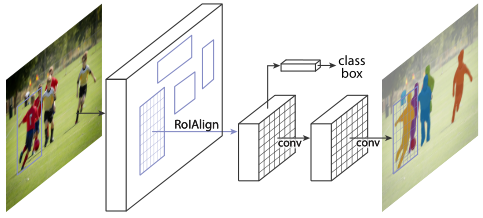
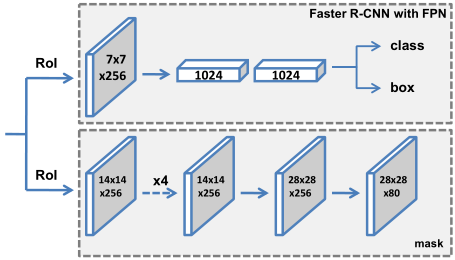
Mask R-CNN,一个相对简单和灵活的实例分割模型。该模型通过目标检测进行了实例分割,同时生成了高质量的掩模。通常,Faster R-CNN有一个用于识别物体边界框的分支。Mask R-CNN并行添加了一个对象蒙版预测分支作为改进。使用FPN主干的head架构如图所示。
关键代码
##利用不同的颜色为每个instance标注出mask,根据box的坐标在instance的周围画上矩形
##根据class_ids来寻找到对于的class_names。三个步骤中的任何一个都可以去掉,比如把mask部分
##去掉,那就只剩下box和label。同时可以筛选出class_ids从而显示制定类别的instance显示,下面
##这段就是用来显示人的,其实也就把人的id选出来,然后记录它们在输入ids中的相对位置,从而得到
##相对应的box与mask的准确顺序
def display_instances_person(image, boxes, masks, class_ids, class_names,
scores=None, title="",
figsize=(16, 16), ax=None):
"""
the funtion perform a role for displaying the persons who locate in the image
boxes: [num_instance, (y1, x1, y2, x2, class_id)] in image coordinates.
masks: [height, width, num_instances]
class_ids: [num_instances]
class_names: list of class names of the dataset
scores: (optional) confidence scores for each box
figsize: (optional) the size of the image.
"""
#compute the number of person
temp = []
for i, person in enumerate(class_ids):
if person == 1:
temp.append(i)
else:
pass
person_number = len(temp)
person_site = {}
for i in range(person_number):
person_site[i] = temp[i]
NN = boxes.shape[0]
# Number of person'instances
#N = boxes.shape[0]
N = person_number
if not N:
print("\n*** No person to display *** \n")
else:
# assert boxes.shape[0] == masks.shape[-1] == class_ids.shape[0]
pass
if not ax:
_, ax = plt.subplots(1, figsize=figsize)
# Generate random colors
colors = random_colors(NN)
# Show area outside image boundaries.
height, width = image.shape[:2]
ax.set_ylim(height + 10, -10)
ax.set_xlim(-10, width + 10)
ax.axis('off')
ax.set_title(title)
masked_image = image.astype(np.uint32).copy()
for a in range(N):
color = colors[a]
i = person_site[a]
# Bounding box
if not np.any(boxes[i]):
# Skip this instance. Has no bbox. Likely lost in image cropping.
continue
y1, x1, y2, x2 = boxes[i]
p = patches.Rectangle((x1, y1), x2 - x1, y2 - y1, linewidth=2,
alpha=0.7, linestyle="dashed",
edgecolor=color, facecolor='none')
ax.add_patch(p)
# Label
class_id = class_ids[i]
score = scores[i] if scores is not None else None
label = class_names[class_id]
x = random.randint(x1, (x1 + x2) // 2)
caption = "{} {:.3f}".format(label, score) if score else label
ax.text(x1, y1 + 8, caption,
color='w', size=11, backgroundcolor="none")
# Mask
mask = masks[:, :, i]
masked_image = apply_mask(masked_image, mask, color)
# Mask Polygon
# Pad to ensure proper polygons for masks that touch image edges.
padded_mask = np.zeros(
(mask.shape[0] + 2, mask.shape[1] + 2), dtype=np.uint8)
padded_mask[1:-1, 1:-1] = mask
contours = find_contours(padded_mask, 0.5)
for verts in contours:
# Subtract the padding and flip (y, x) to (x, y)
verts = np.fliplr(verts) - 1
p = Polygon(verts, facecolor="none", edgecolor=color)
ax.add_patch(p)
ax.imshow(masked_image.astype(np.uint8))
plt.show()
4 实现效果
原视频

生成帧蒙板

最终效果
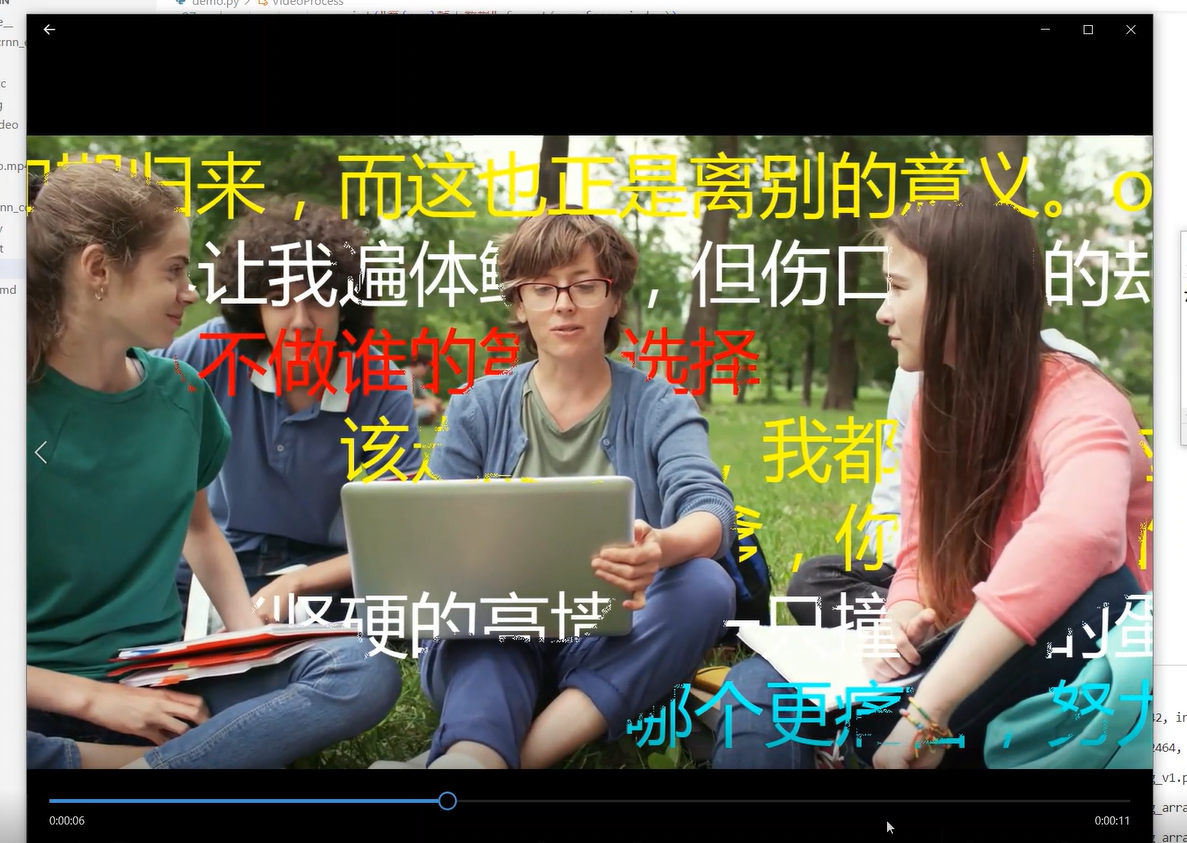
最后
🧿 项目分享:见文末!















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









