







全文检索
用户访问我们的首页,一般都会直接搜索来寻找自己想要购买的商品。 而商品的数量非常多,而且分类繁杂。如果能正确的显示出用户想要的商品,并进行合 理的过滤,尽快促成交易,是搜索系统要研究的核心。 面对这样复杂的搜索业务和数据量,使用传统数据库搜索就显得力不从心,一般我们都 会使用全文检索技术。
- 面对这样复杂的搜索业务和数据量,使用传统数据库搜索就显得力不从心,一般我们都 会使用全文检索技术。
- 常见的全文检索技术有 Lucene、solr 、elasticsearch 等。
索引结构

- 逻辑索引结构部分是一个倒排索引表:
- 将要搜索的文档内容分词,所有不重复的词组成分词列表。
- 将要搜索的文档最终以Document方式存储起来。
- 每个词和document都有关联。
如下:
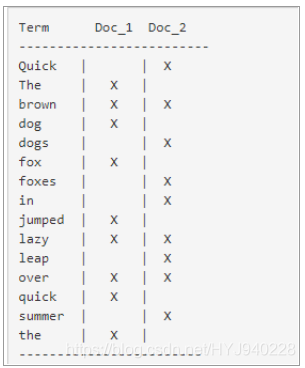
现在如果我们想要搜索quick brown,我们只需要查询包含每个词条的文档:

两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅仅计算匹配词条数量的简单相似算法,那么,我们可以说,对于我们查询的相关性来讲第一个文档比第二个文档更佳。
概述
- ElasticSearch是一个基于Lucene的搜索服务器。他提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。ElasticSearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当下流行的企业级说说引擎。设计用于云计算中国,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
- 官方网址:https://www.elastic.co/cn/products/elasticsearch
- Github:https://github.com/elastic/elasticsearch
- 优点:
- 可以作为一个大型分布式集群(数百台服务器)技术,处理PB级的数据,也可以运行在单机上
- 将全文检索、数据分析以及分布式技术合并在了一起,才形成了独一无二的ES;
- 开箱即用,部署简单
- 全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理;
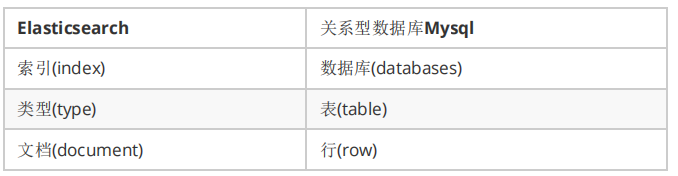
ElasticSearch与MySQL的逻辑结构概念对比
使用postman工具操作索引库
1、 新建文档
- 以post方式提交到localhost:9200/testindex/doc
提交一个json数据:

将返回如下结果:

_id是由系统自动生成的。
2、查询文档
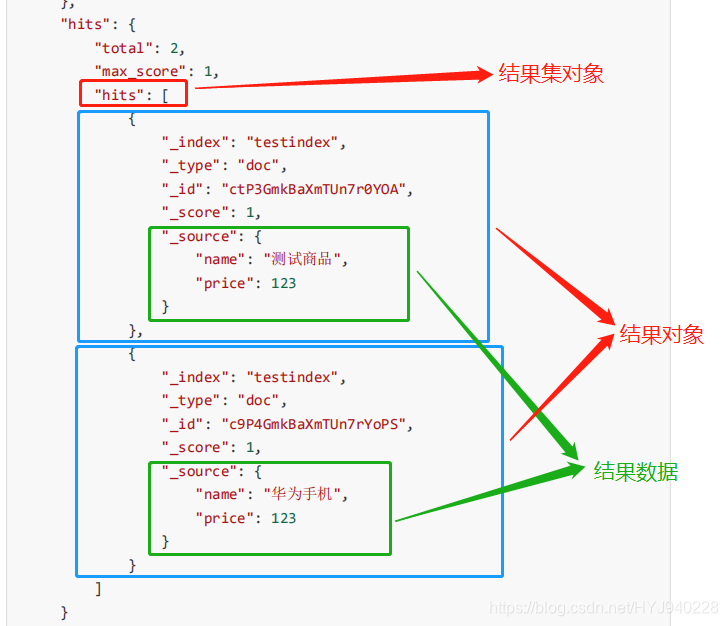
查询某索引某类型的全部数据,以get方式请求 http://127.0.0.1:9200/testindex/doc/_search 返回结果如下:

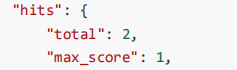
hits采样统计:
- total:总共搜索到的结果条数
- max-score:值得大小表示其与搜索词条的相关程度(值越大越精准)
映射与数据类型
映射(Mapping)相当于数据表的表结构。ElasticSearch中的映射(Mapping)用来 定义一个文档,可以定义所包含的字段以及字段的类型、分词器及属性等等。
映射可以分为动态映射和静态映射。
- 动态映射 (dynamic mapping):
- 在关系数据库中,需要事先创建数据库,然后在 该数据库实例下创建数据表,然后才能在该数据表中插入数据。而ElasticSearch中不需 要事先定义映射(Mapping),文档写入ElasticSearch时,会根据文档字段自动识别类 型,这种机制称之为动态映射。
- 静态映射 :
- 在ElasticSearch中也可以事先定义好映射,包含文档的各个字段及其类 型等,这种方式称之为静态映射。
字符串类型

整数类型
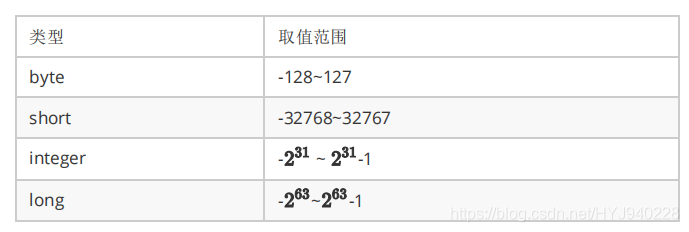
浮点类型
date类型
日期类型表示格式可以是以下几种:
- 日期格式的字符串,比如 “2018-01-13” 或 “2018-01-13 12:10:30”
- long类型的毫秒数( milliseconds-since-the-epoch,epoch就是指UNIX诞生的UTC 时间1970年1月1日0时0分0秒)
- integer的秒数(seconds-since-the-epoch)
Boolean类型
- 逻辑类型(布尔类型)可以接受true/false
binary类型
- 二进制字段是指用base64来表示索引中存储的二进制数据,可用来存储二进制形式 的数据,例如图像。默认情况下,该类型的字段只存储不索引。二进制类型只支持 index_name属性。
array类型
- 在ElasticSearch中,没有专门的数组(Array)数据类型,但是,在默认情况下,任 意一个字段都可以包含0或多个值,这意味着每个字段默认都是数组类型,只不过,数组 类型的各个元素值的数据类型必须相同。在ElasticSearch中,数组是开箱即用的(out of box),不需要进行任何配置,就可以直接使用。
- 在同一个数组中,数组元素的数据类型是相同的,ElasticSearch不支持元素为多个 数据类型:[ 10, “some string” ],常用的数组类型是:
- 字符数组: [ “one”, “two” ]
- 整数数组: productid:[ 1, 2 ]
- 对象(文档)数组: “user”:[ { “name”: “Mary”, “age”: 12 }, { “name”: “John”, “age”: 10 }],ElasticSearch内部把对象数组展开为 {“user.name”: [“Mary”, “John”], “user.age”: [12,10]}
object类型
- JSON天生具有层级关系,文档会包含嵌套的对象
IK分词器
什么是IK分词器
*使用postman测试 post方式提交 http://127.0.0.1:9200/testindex/_analyze提交JSON数据:{“analyzer”: “chinese”, “text”: “王富贵儿” }
- 返回如下结果:
{
"tokens": [
{ "token": "王",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "富",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "贵",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "儿",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
},
]
}
默认的中文分词是将每个字看成一个词,这显然是不符合要求的,所以我们需要安装中 文分词器来解决这个问题。
IK分词是一款国人开发的相对简单的中文分词器。虽然开发者自2012年之后就不在维护 了,但在工程应用中IK算是比较流行的一款!我们今天就介绍一下IK中文分词器的使用。
IK分词器安装
- 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
- 下载6.5.2版\elasticsearch\elasticsearch-analysis-ik- 6.5.2.zip
- 先将其解压,将解压后的elasticsearch文件夹重命名文件夹为ik
- 将ik文件夹拷贝到elasticsearch/plugins 目录下。
- 重新启动,即可加载IK分词器
IK提供了两个分词算法ik_smart 和 ik_max_word- 其中 ik_smart 为最少切分,ik_max_word为最细粒度划分
- 最小切分:使用postman测试 post方式提交 http://127.0.0.1:9200/testindex/_analyze提交:{“analyzer”: “ik_smart”, “text”: “超级程序员” }
- 返回结果:

- 返回结果:
- 最小切分:使用postman测试 post方式提交 http://127.0.0.1:9200/testindex/_analyze提交:{“analyzer”: “ik_smart”, “text”: “超级程序员” }
- 最细切分:使用postman测试 post方式提交 http://127.0.0.1:9200/testindex/_analyze 提交: {{“analyzer”: “ik_max_word”, “text”: “超级程序员” }
- 返回结果为:

- 返回结果为:
- 其中 ik_smart 为最少切分,ik_max_word为最细粒度划分
自定义词库
- 进入elasticsearch/plugins/ik/config目录
- 新建一个my.dic文件,添加你想要分词的词语或短语
- 修改IKAnalyzer.cfg.xml(在ik/config目录下)
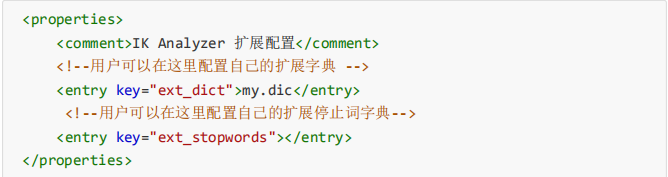
当输入你自定义的字符串时ik分词器就会按照你的配置进行分词
Kibana
Kibana简介
- Kibana 是一个开源的分析和可视化平台,旨在与 Elasticsearch 合作。Kibana 提供 搜索、查看和与存储在 Elasticsearch 索引中的数据进行交互的功能。开发者或运维人员 可以轻松地执行高级数据分析,并在各种图表、表格和地图中可视化数据。
- 如果Kibana远程连接Elasticsearch ,可以修改config\kibana.yml
- 执行bin\kibana.bat
- 打开浏览器,键入http://localhost:5601 访问Kibana
- 我们这里使用Kibana进行索引操作,Kibana与Postman相比省略了服务地址,并且有语 法提示,非常便捷。
创建索引与映射字段

- 类型名称:就是前面将的type的概念,类似于数据库中的不同表 字段名:任意填写,可以指定许多属性,例如:
- type:类型,可以是text、long、short、date、integer、object等
- index:是否索引,默认为true
- store:是否单独存储,默认为false ,一般内容比较多的字段设置成true,可提 升查询性能
- analyzer:分词器
创建索引结构:
静态映射方式:

文档增加与修改
增加文档自动生成ID
- 通过POST请求,可以向一个已经存在的索引库中添加数据
语法:
POST 索引库名/类型名
{
“key”:“value”
}
实例:

- 响应结果:

查询命令:
- GET 索引库名/_search
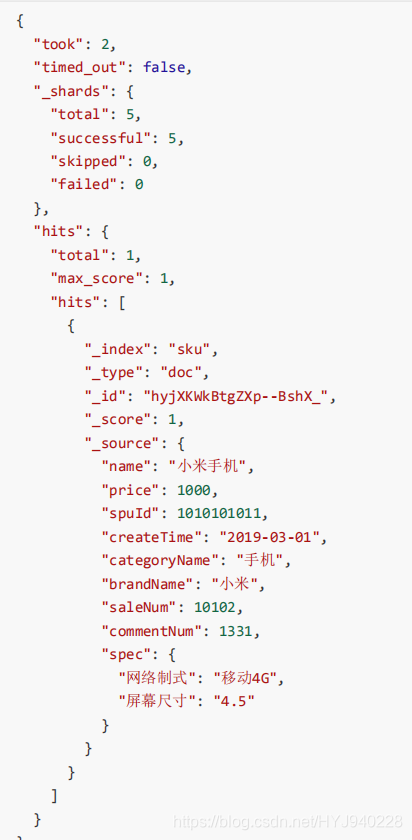
实例:
GET sku/_search
** 新增文档指定ID**
语法:
PUT /索引库名/类型/id值
{
。。。。。。。。
}
实例:
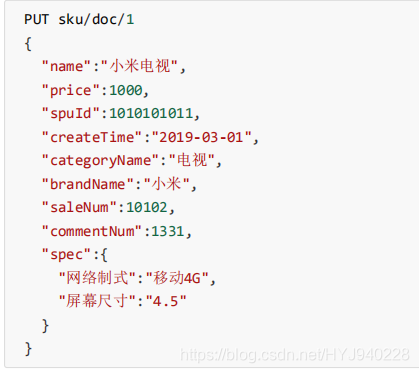
索引查询
- 基本语法
GET /索引库名/_search
{
"query":{
"查询类型":{
"查询条件":"查询条件值"
}
}
}
这里的query代表一个查询对象,里面可以有不同的查询属性
- 查询类型:
- 例如:match_all, match, term, range 等等
- 查询条件:查询条件会根据类型的不同,写法也有差异
查询所有(match_all)
实例:

- took:查询花费时间,单位是毫秒
- time_out:是否超时
- _shards:分片信息
- hits:搜索结果总览对象
- total:搜索到的总条数
- max_score:所有结果中文档得分的最高分
- hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息
- _index:索引库
- _type:文档类型
- _id:文档id
- _score:文档得分
- _source:文档的源数据
实例:

匹配查询(match)
示例:查询名称包含手机的记录
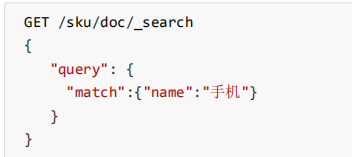
这样查询他会先进行分词;即:小米;手机 so:名字包含这两个的都会被查询出来
如何避免?

这样只会查询出包含“小米电视”的结果
多字段查询(multi_match)
multi_match 与 match类似,不同的是它可以在多个字段中查询
实例:

- 这样会查询出:名字or品牌or分类包含“小米”的文档源数据
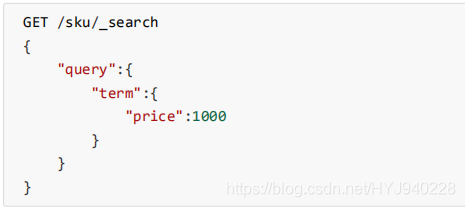
词条匹配(term)
term查询被用于精确值 匹配,这些精确值可能是数字、时间、布尔或者那些未分词的字 符串
实例:
- 查询价格为1000的文档源数据
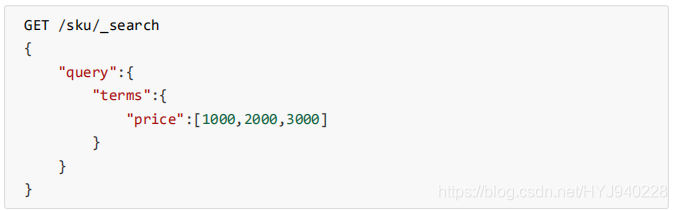
多词条匹配(terms)
terms 查询和 term 查询一样,但它允许你指定多值进行匹配。如果这个字段包含了指定 值中的任何一个值,那么这个文档满足条件
实例:
- 查询价格为:1000、2000、3000的文档源数据
布尔组合(bool)
bool 把各种其它查询通过 must (与)、 must_not (非)、 should (或)的方式进行 组合
示例:查询名称包含手机的,并且品牌为小米的文档源数据

示例:查询名称包含手机的,或者品牌为小米的。

过滤查询
过滤是针对搜索的结果进行过滤,过滤器主要判断的是文档是否匹配,不去计算和 判断文档的匹配度得分,所以过滤器性能比查询要高,且方便缓存,推荐尽量使用过滤 器去实现查询或者过滤器和查询共同使用。
示例:过滤品牌为小米的记录:

分组查询
示例:按分组名称聚合查询,统计每个分组的数量
size为0 不会将数据查询出来,目的是让查询更快。
我们也可以一次查询两种分组统计结果:

JavaRest 高级客户端入门
elasticsearch 存在三种Java客户端。
- Transport Client
- Java Low Level Rest Client(低级rest客户端)
- Java High Level REST Client(高级rest客户端)
这三者的区别是:
- TransportClient没有使用RESTful风格的接口,而是二进制的方式传输数据
- ES官方推出了Java Low Level REST Client,它支持RESTful。
- 但是缺点是因为 TransportClient的使用者把代码迁移到Low Level REST Client的工作量比较大。
- ES官方推出Java High Level REST Client,它是基于Java Low Level REST Client的封 装,并且API接收参数和返回值和TransportClient是一样的,使得代码迁移变得容易 并且支持了RESTful的风格,兼容了这两种客户端的优点。强烈建议ES5及其以后的 版本使用Java High Level REST Client
准备工作:引入依赖

快速入门
新增和修改数据
插入单条数据:
- HttpHost : url地址封装
- RestClientBuilder: rest客户端构建器
- RestHighLevelClient: rest高级客户端
- IndexRequest: 新增或修改请求
- IndexResponse:新增或修改的响应结果
//1.连接rest接口
HttpHost http=new HttpHost("127.0.0.1",9200,"http");
RestClientBuilder builder= RestClient.builder(http);
//rest构建器
RestHighLevelClient restHighLevelClient=new RestHighLevelClient(builder);//高级客户端对象
//2.封装请求对象
IndexRequest indexRequest=new IndexRequest("sku","doc","3");
Map skuMap =new HashMap();
skuMap.put("name","华为p30pro");
skuMap.put("brandName","华为");
skuMap.put("categoryName","手机");
skuMap.put("price",1010221);
skuMap.put("createTime","2019‐05‐01");
skuMap.put("saleNum",101021);
skuMap.put("commentNum",10102321);
Map spec=new HashMap();
spec.put("网络制式","移动4G");
spec.put("屏幕尺寸","5");
skuMap.put("spec",spec);
indexRequest.source(skuMap);
//3.获取响应结果
IndexResponse response = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
int status = response.status().getStatus();
System.out.println(status);
restHighLevelClient.close();
如果ID不存在则新增,如果ID存在则修改。
批处理请求:
BulkRequest: 批量请求(用于增删改操作)
BulkResponse:批量请求(用于增删改操作)
//1.连接rest接口
HttpHost http=new HttpHost("127.0.0.1",9200,"http");
RestClientBuilder builder= RestClient.builder(http);
//rest构建器
RestHighLevelClient restHighLevelClient=new RestHighLevelClient(builder);//高级客户端对象
//2.封装请求对象
BulkRequest bulkRequest=new BulkRequest();
IndexRequest indexRequest=new IndexRequest("sku","doc","4");
Map skuMap =new HashMap();
skuMap.put("name","华为p30pro 火爆上市");
skuMap.put("brandName","华为");
skuMap.put("categoryName","手机");
skuMap.put("price",1010221);
skuMap.put("createTime","2019‐05‐01");
skuMap.put("saleNum",101021);
skuMap.put("commentNum",10102321);
Map spec=new HashMap();
spec.put("网络制式","移动4G");
spec.put("屏幕尺寸","5");
skuMap.put("spec",spec);
indexRequest.source(skuMap);
bulkRequest.add(indexRequest);//可以多次添加
//3.获取响应结果
BulkResponse response = restHighLevelClient.bulk(bulkRequest,RequestOptions.DEFAULT);
int status = response.status().getStatus();
System.out.println(status);
String message = response.buildFailureMessage(); System.out.println(message);
restHighLevelClient.close();














 8443
8443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









