






 本文介绍了线性回归的基本概念、均方误差损失函数、随机梯度下降算法,并提供了从零开始实现线性回归的代码示例。随后探讨了Fashion-MNIST数据集的应用,包括softmax回归和交叉熵损失函数的讲解以及相关实现。
本文介绍了线性回归的基本概念、均方误差损失函数、随机梯度下降算法,并提供了从零开始实现线性回归的代码示例。随后探讨了Fashion-MNIST数据集的应用,包括softmax回归和交叉熵损失函数的讲解以及相关实现。
3.1 线性回归
3.1.1 线性回归的基本概念
回归是变量与变量之间建立的某种联系的表达的一类方法。
线性回归就是回归当中数据具有线性联系的一种方法模型。在机器学习中,一般使用高维数据集,所以使用线性代数表示更好。如下:
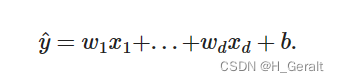
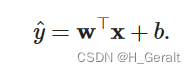
简而言之,就是n维的输入乘以权重,再加上偏差。
3.1.2 均方误差损失函数
损失函数(loss function)能够量化目标的实际值与预测值之间的差距。 通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。 回归问题中最常用的损失函数是平方误差函数。 当样本𝑖的预测值为𝑦^(𝑖),其相应的真实标签为𝑦(𝑖)时, 平方误差可以定义为以下公式:
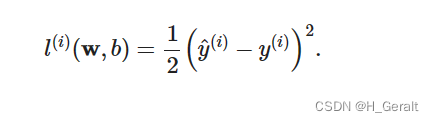
3.1.3 随机梯度下降(SGD)
SGD算法是从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。(重点:每次迭代使用一组样本。)
具体详情:随机梯度下降法(stochastic gradient descent,SGD)
3.2 线性回归的从零开始实现
实现的代码
#matplotlib inline
import random
import torch
import pylab
from d2l import torch as d2l
from matplotlib import pyplot as plt
#手写数据集
def synthetic_data(w,b,num_examples):
x = torch.normal(0, 1, [num_examples , len(w)])#均值为0,方差为1的随机数,有n个样本,w列
y = torch.matmul(x, w)+b #y=wx+b
y += torch.normal(0, 0.01, y.shape)#加上一个噪音项
return x, y.reshape((-1, 1))
true_w=torch.tensor([2, -3.4])
true_b=4.2
features, labels = synthetic_data(true_w, true_b, 1000)
print('features:', features[0])#打印样本
print('labels:', labels[0])#打印标签
d2l.set_figsize()
d2l.plt.scatter(features[:, 1].detach().numpy(), labels.detach().numpy(),1)
plt.show()#展示出样本与标签的散点图
#读取数据集
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(indices[i:min(i+batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
#感受小批量的运算
batch_size = 10
for x,y in data_iter(batch_size,features,labels):
print(x, '\n', y)
break
#初始化模型参数
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
#定义模型
def linreg(x,w,b):
return torch.matmul(x,w) + b # return X*w+b
#定义均方误差损失函数
def squared_loss(y_hat, y):
return(y_hat - y.reshape(y_hat.shape))**2 / 2 #(y1-y2)^2/2
#定义随机梯度下降函数
def sgd(params, lr, batch_size):
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
#训练模型
lr=0.3
num_epochs = 10
net = linreg
loss =squared_loss
for epoch in range(num_epochs): #训练十轮
for x, y in data_iter(batch_size, features, labels): #分十批读取数据
l = loss(net(x,w,b), y) #损失函数
l.sum().backward() #反向传播计算梯度
sgd([w, b], lr, batch_size) #使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features,w,b), labels)
print(f'epoch {epoch+1} , loss {float(train_l.mean()):f}') #打印每一轮的损失函数的损失值
print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')3.3 线性回归的从零开始实现
实现的代码
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
from torch import nn
import matplotlib.pyplot as plt
from torchvision import transforms
from torchvision import datasets
#生成数据集
true_w=torch.tensor([2,-3.4])
true_b=4.2
features,labels=d2l.synthetic_data(true_w, true_b,1000)
#读取数据集
batch_size=10
dataset=data.TensorDataset(features,labels)
data_loader=data.DataLoader(dataset,batch_size,shuffle=True)#构建一个数据迭代器
next(iter(data_loader))
#定义网络
net=nn.Sequential(nn.Linear(2,1))
#初始化模型参数
net[0].weight.data.normal_(0,0.01)
net[0].bias.data.fill_(0)
#定义损失函数与优化函数
loss=nn.MSELoss()
trainer=torch.optim.SGD(net.parameters(), lr=0.03)
#训练
num_Epoch=10
loss_list_test=[]
for i in range(num_Epoch):
for X,y in data_loader:
l=loss(net(X),y)
trainer.zero_grad() #梯度归零
l.backward() #梯度反向传播得到每个参数的梯度值
trainer.step() #梯度下降执行参数更新
l=loss(net(features),labels)
loss_list_test.append(l.detach().cpu().numpy())
print(f'epoch {i + 1}, loss {l:f}')
#模型评价
w = net[0].weight.data
print('w的估计误差:', true_w - w.reshape(true_w.shape))
b = net[0].bias.data
print('b的估计误差:', true_b - b)
#画图展示出每一轮的损失值
plt.plot(loss_list_test)
plt.xlabel('EPOCH')
plt.ylabel('loss_shuzhi')
plt.show()3.4softmax回归
3.4.1softmax运算
softmax函数能够将未规范化的预测变换为非负数并且总和为1,同时让模型保持 可导的性质。简而言之,就是softmax函数可以把输入映射到0-1的区间,同时归一化保证和为1。相应公式为:

3.4.2 交叉熵损失函数
交叉熵损失函数主要用于分类问题,判断实际输出与预期输出的差别,也就是交叉熵的值越小,两个概率分布就越接近。
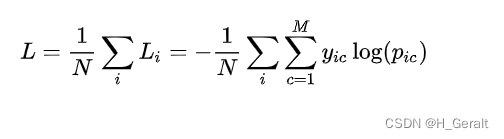
3.5 softmax回归的实现
3.5.1 读取数据集
读取Fashion-MNIST数据集(读取时,下载速度慢的话,可以搭个梯子)
#读取数据集
def load_data_fashion_mnist(batch_size, resize=None): #@save
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root="./data", train=True, transform=trans)#, download=True
mnist_test = torchvision.datasets.FashionMNIST(
root="./data", train=False, transform=trans)#, download=True
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=4),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=4))3.5.2 代码的具体实现
具体代码实现:
import torch
import torchvision
from d2l.torch import Accumulator, Animator
import multiprocessing as mp
from time import time
from torchvision import datasets, transforms
from torch.utils import data
import numpy
import matplotlib.pyplot as plt
from d2l import torch as d2l
from IPython import display
#读取数据集
def load_data_fashion_mnist(batch_size, resize=None): #@save
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root="./data", train=True, transform=trans)#, download=True
mnist_test = torchvision.datasets.FashionMNIST(
root="./data", train=False, transform=trans)#, download=True
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=4),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=4))
#读取数据集的标签
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot'];
return [text_labels[int(i)]for i in labels];
#展示其中的图片
def show_images(imgs,num_rows,num_cols,titles=None,scale=1.5):
figsize=(num_cols * scale,num_rows * scale)
_,axes=d2l.plt.subplots(num_rows,num_cols,figsize=figsize)
axes=axes.flatten()
for i ,(ax,img) in enumerate(zip(axes,imgs)):
if torch.is_tensor(img):
ax.imshow(img.numpy())
else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
return axes
batch_size=256
num_inputs=784
num_outputs=10
W=torch.normal(0,0.01,size=(num_inputs,num_outputs),requires_grad=True)
b=torch.zeros(num_outputs,requires_grad=True)
#softmax回归函数
def softmax(x):
x_exp=torch.exp(x)
partition=x_exp.sum(1,keepdim=True)
return x_exp/partition
def net(X):
return softmax(torch.matmul(X.reshape((-1,W.shape[0])),W) + b)##
y = torch.tensor([0, 2])
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
#交叉熵损失函数
def cross_entropy(y_hat,y):
return -torch.log(y_hat[range(len(y_hat)),y])
#计算预测正确数量
def accuracy(y_hat,y):
if len(y_hat.shape)>1 and y_hat.shape[1]>1:
y_hat=y_hat.argmax(axis=1)
print(y_hat)
cmp=y_hat.type(y.dtype)==y
return float(cmp.type(y.dtype).sum())
def evalute_accuracy(net,data_iter):
if isinstance(net,torch.nn.Module):
net.eval()
metric=Accumulator(2)
with torch.no_grad():
for x,y in data_iter:
metric.add(accuracy(net(x),y),y.numel())
return metric[0]/metric[1]
#训练
def train_epoch_ch3(net,train_iter,loss,updater):
if isinstance(net,torch.nn.Module):
net.train()
metric=Accumulator(3)
for X,y in train_iter:
y_hat=net(X)
l=loss(y_hat,y)
if isinstance(updater,torch.optim.Optimizer):
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()),accuracy(y_hat,y),y.numel())
return metric[0]/metric[2],metric[1]/metric[2]
def train_ch3(net,train_iter,test_iter,loss,num_epochs,updater):
animator=Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics=train_epoch_ch3(net,train_iter,loss,updater)
test_acc=evalute_accuracy(net,test_iter)
animator.add(epoch+1,train_metrics+(test_acc,))
train_loss,train_acc=train_metrics
assert train_loss<0.5,train_loss
assert 1 >= train_acc > 0.7,train_acc
assert 1 >= test_acc > 0.7,test_acc
#sgd优化函数
def updater(batch_size):
return d2l.sgd([W,b],0.1,batch_size)
num_epochs=10
def predict_ch3(net,test_iter,n=6):
for X,y in test_iter:
break
trues=d2l.get_fashion_mnist_labels(y)
preds=d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
titles=[true+'\n'+pred for true,pred in zip(trues,preds)]
d2l.show_images(X[0:n].reshape((n,28,28)),1,n,titles=titles[0:n])
#main函数
if __name__ == '__main__':
#y = torch.tensor([0, 2])
# y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
batch_size=256
num_epochs = 10
train_iter, test_iter = load_data_fashion_mnist(batch_size)
#train_iter, test_iter = load_data_fashion_mnist(18) #, resize=64
#X,y=next(iter(train_iter))
train_ch3(net,train_iter,test_iter,cross_entropy,num_epochs,updater)
#show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y))
predict_ch3(net,test_iter)
plt.show()















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









