







1、树的概念 + 二叉树概念和逻辑结构
【注意】:n个结点的二叉树有多少种形态: 卡特兰数 
2、二叉树性质和存储结构
(1)性质
1.二叉树第i层最大结点数:,最少结点数:1
2.二叉树(k层)最大节点数:,最少结点数:k
3.二叉树叶子结点数n0,度为2的结点数n2,则 n0 = n2 + 1
4.具有n个结点的完全二叉树的深度k =
5.具有n个结点的完全二叉树,按层序编号:
若 i > 1,其双亲结点为 ;
若 2i > n,i 为叶子结点,无左孩子,否则左孩子为 2i;
若 2i + 1 > n,i 无右孩子,否则右孩子为 2i +1
(2)两种特殊的二叉树
1.满二叉树(深度为k,结点数n为)
特点:每一层的结点数都是满的(最大节点数);叶子节点都在最底层。
2.完全二叉树(深度为k, 结点数n
)
特点:叶子结点可能出现在最底层和倒数第二层;
任一结点,若右子树最大层次为 i,则左子树最大层次为 i 或 i+1;
所以:满二叉树一定是完全二叉树,但完全二叉树不一定是满二叉树。
(3)存储结构
顺序存储
实现:按满二叉树的结点层次编号,依次存放二叉树中的数据元素
缺点:存储密度小,浪费空间
适用:满二叉树和完全二叉树,并且蕴含结点之间的关系
链式存储
存储结构:
typedef struct BiNode {
ElemType data;
struct BiNode *lchild, *rchild;// 左右孩子指针
}BiNode, *BiTree;【注意】在n个结点的二叉链表中,有 n + 1 个空指针域。
3、遍历二叉树和线索二叉树
(1)遍历二叉树
三种遍历:先(DLR)、中(LDR)、后(LRD)
【注意】给树求出遍历结果、给两个序列(中+先/中+后/中+层)逆推树都要会!
算法实现(利用递归):
算法思想:
先序遍历:若二叉树为空,则空操作;
若二叉树非空,访问根结点D,先序遍历左子树L,先序遍历右子树R。
中序遍历:若二叉树为空,则空操作;
若二叉树非空,中序遍历左子树L,访问根结点D,中序遍历右子树R。
后序遍历:若二叉树为空,则空操作;
若二叉树非空,后序遍历左子树L,后序遍历右子树R,访问根结点D。
// 先序遍历
void PreOrder(BiTree T){
if(T != NULL){
visit(T);
PreOrder(T->lchild);
PreOrder(T->rchild);
}
}
// 中序遍历
void InOrder(BiTree T){
if(T != NULL){
InOrder(T->lchild);
visit(T);
InOrder(T->rchild);
}
}
// 后序遍历
void PostOrder(BiTree T){
if(T != NULL) {
PostOrder(T->lchild);
visit(T);
PostOrder(T->rchild);
}
}算法实现(非递归):
利用栈实现中序遍历(先序遍历和中序遍历就访问位置不同,在结点入栈时访问):
算法思想:
建立一个栈;
根结点入栈,遍历左子树;
根结点出栈,输出根结点,遍历右子树;
// 利用栈实现二叉树的中序遍历
void InOrder2(BiTree T){
InitStack(S); BiTree p = T;
while(p || !isEmpty(S)){
if(p != NULL) {
Push(S, p); p = p->lchild; //若是先序遍历,即在Push前先访问结点
}else {
Pop(S, p); visit(p); p = p->rchild;
}
}
}利用队列实现层次遍历:
算法思想:
建立一个队列;
根结点入队;
队不空时循环,根结点出队,左右孩子入队;
// 利用队列实现层次遍历
void LevelOrder(BiTree T){
InitQueue(Q); BiTree p; EnQueue(Q, T);
while(!isEmpty(Q)) {
DeQueue(Q, p);
visit(p);
if ( p->lchild != NULL )
EnQueue(Q, p->lchild);
if ( p->rchild != NULL )
EnQueue(Q, p->rchild);
}
}算法分析:
1. 三种遍历的递归算法访问路径相同,只是访问结点的实际不同。每个结点都经过3次:第1次经过时访问=> 先序;第2次经过时访问=>中序;第3次经过时访问=>后序。
2. 时间复杂度O(n) // 每个结点只访问一次;空间复杂度O(n) // 栈占用的最大辅助空间
算法应用:
1. 复制二叉树
算法思想:
如果是空树,递归结束;
否则,申请新结点空间,复制根结点;
递归复制左子树,右子树;
// 复制二叉树
int Copy(BiTree T, BiTree &newT){
if ( T == NULL ){
newT = NULL;
return 0;
}
newT = (BiNode *)malloc(sizeof(BiNode));
newT->data = T->data;
Copy(T->lchild, newT->lchild);
Copy(T->rchild, newT->rchild);
}2.计算二叉树深度
算法思想:
如果是空树,则深度为0;
否则,递归计算左子树深度为m,递归计算右子树深度为n,取较大者+1;
// 计算二叉树的深度
int Depth(BiTree T){
if(T == NULL) return 0;
m = Depth(T->lchild);
n = Depth(T->rchild);
if ( m > n) return (m + 1);
else return (n + 1);
} 3.计算结点总数
算法思想:
若为空树,则结点总数为0;
否则,遍历左子树和右子树,最后根结点(+1)
// 计算二叉树结点总数
int NodeCount(BiTree T) {
if( T == NULL ) return 0;
return NodeCount(T->lchild) + Node(T->rchild) + 1;
}4.计算叶子结点数
算法思想:
若为空树,则叶子结点数为 0;
否则,递归左子树和右子树,若没有左右孩子则 + 1;
// 计算二叉树叶子结点个数
int LeafCount(BiTree T) {
if ( T == NULL ) return 0;
if( T->lchild == NULL && T->rchild == NULL)
return 1;
return LeafCount(T->lchild) + LeafCount(T->rchild);
}(2)线索二叉树
会手画中序、后序线索二叉树即可。(先写出序列,再画)
存储结构(增设两个标志位ltag和rtag):
// 线索二叉树的存储结构
typedef struct ThreadNode{
int data;
struct ThreadNode *lchild, *rchild;
int ltag, rtag;// 0为孩子,1为前驱或后继
}ThreadNode, *ThreadTree;【注意】为保证第一个序列的第一个结点和最后一个结点的一致性,可以增设一个头结点(ltag=0,指向根节点;rtag=1,执行序列的最后一个结点 )!
4、树和森林
(1)树的存储结构
双亲表示法:数据域(结点本身信息)+双亲域(双亲结点在数组中的下标);
特点:找双亲容易,找孩子难;
孩子链表法:n个头结点用顺序表存储,n个结点有n个孩子链表;
特点:找孩子容易,找双亲难;
孩子兄弟表示法:用二叉链表作为存储结构,两个指针域分别指向第一个孩子结点和兄弟结点;
特点:找孩子容易,找兄弟容易,找双亲难;
(2)树和二叉树互转
树转二叉树:兄弟相连留长子。
二叉树转树:左孩右右连双亲,去掉原来右孩线。
(3)森林和二叉树互转
森林转二叉树:树变二叉根相连。
二叉树转森林:去掉全部右孩线,孤立二叉再还原。
(4)树的遍历
先根遍历:先根,再遍历哥子树;
后根遍历:先遍历各子树,后根;
层次遍历:自上而下,自左向右;
(5)森林的遍历
先序遍历:对森林中的每一棵树都进行先根遍历;
中序遍历:对森林中的每一棵树都进行后根遍历;
5、二叉排序树BST(左<根<右)
根据左<根<右这个特性,按中序遍历可以得到一个递增序列,要会查找、构造(插入)和删除。
删除:叶子结点:直接删除;
只有左子树或右子树:直接用左子树或右子树替代即可;
既有左子树又有右子树:将右子树中最左下结点(直接后继)替代或左子树的最右下结点(直接前驱)替代即可;
查找长度:在查找过程中,对比关键字的次数(反映了时间复杂度和二叉树的高度有关,而我们知道n个结点的最小高度为,所以时间复杂度最小为O(
),故引入AVL)
平均查找长度ASL(要会算) = 结点查找长度之和 / 结点个数
6、平衡二叉树AVL
平衡因子 = 左子树高 - 右子树高;
插入:调整第一个不平衡结点。
怎么调整:LL右旋;RR左旋;LR先左旋后右旋;RL先右旋后左旋;
查找效率:时间复杂度或ASL = O()
7、哈夫曼树(最优二叉树:WPL最小)
(1)基本概念
结点的路径长度:两结点间路径的分支数。
树的路径长度:从根到各个结点的路径长度之和。
【注意】:结点数目相同的二叉树中,完全二叉树是路径长度最短的二叉树,但路径长度最短的二叉树不一定是完全二叉树。
权:树中的结点被赋予某个含义的数值。
带权路径长度:从根结点到该结点之间的路径长度与该结点的权的乘积。
树的带权路径长度:所有叶子结点的带权路径长度之和。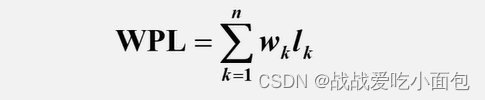
【注意】:满二叉树不一定是哈夫曼树,具有相同带权路径长度的哈夫曼树不唯一
(2)构造哈夫曼树
贪心算法:1.构造森林全是根;2.选用两小造新树;3.删除两小添新人;4.重复2、3剩单根。
特点:哈夫曼树中的结点的度数为0或2,没有度为1的结点;
包含n个叶子结点的哈夫曼树中共有2n - 1个结点(因为要经过n-1次合并,所以新增n-1个度为2的结点,最初的n个结点都为叶子结点)。
(3)哈夫曼编码
方法:出现频率越大,离根越近;左分支为0,右分支为1。
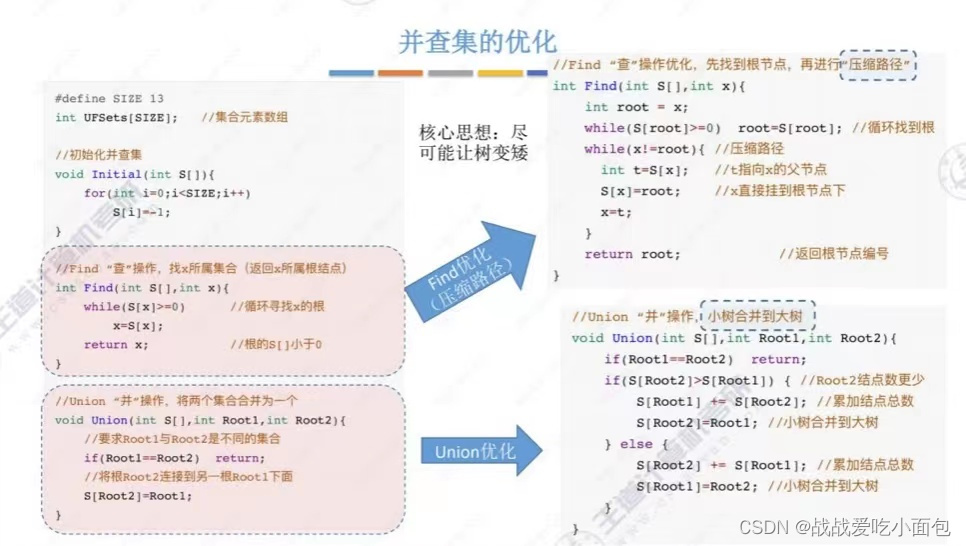
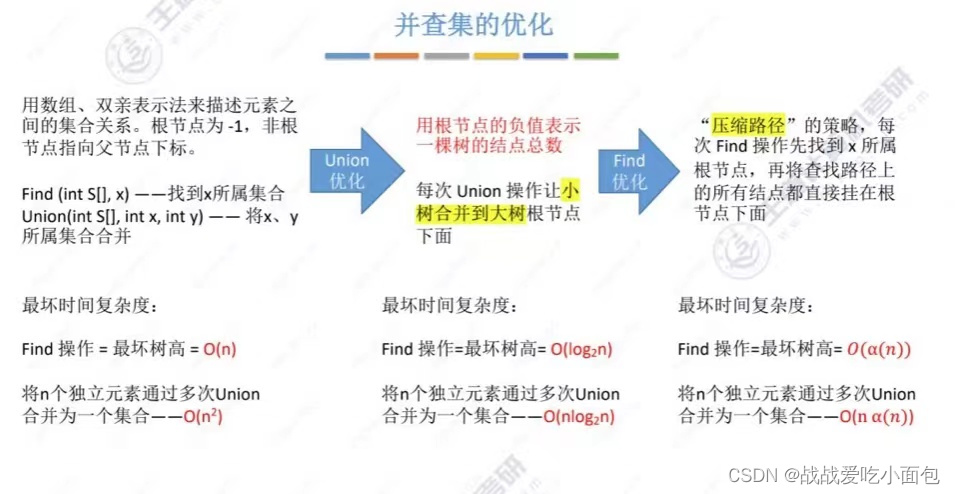
8、并查集
一种【集合】的逻辑关系,主要有“并” 和 “查”两个操作。
一个集合类似于树,多个集合类似于森林,故利用树的知识来实现。
“并”操作:将一棵树变成另一棵树的子树即可;
“查”操作:判断一个元素(结点)属于哪个集合(树),追溯其根结点即可;
判断两个元素(结点)是否属于同一个集合(树),追溯两个根节点比较一下即可。
鉴于树的三种存储方式,使用双亲表示法最妥当:
“查”:找双亲,这个本身就是双亲表示法的特点;
"并":只需将一颗树的根节点的parent指向另一颗树的根节点即可。















 157
157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









