







前言
这几天安装Hadoop2.9.2,参考了很多网上的博客,但是自己有不少地方没看懂,然后掉进了不少坑。所以整理了一下安装的步骤,以后再搭建的时候可以回来看看,也希望给其它小伙伴在搭建环境的时候可以更加高效快速。如果有做的不对的地方,请大家指出。还有,文章的最后有些安装过程中遇到的尚未解决的问题,希望大家可以帮忙解决一下。😃😃😃
还有,我为了偷懒,下面全部操作都是以root用户操作,如果你想使用其他用户,要先在第五步拍摄快照之前创建一个用户,比如 useradd hadoop。然后在搭建完全分布式的ssh免密登录slave时,是使用你创建的用户进行免密操作,之后的操作都是在你创建的用户上进行。
目录
1. 固定IP
- 点击虚拟机的 编辑——虚拟网络编辑器
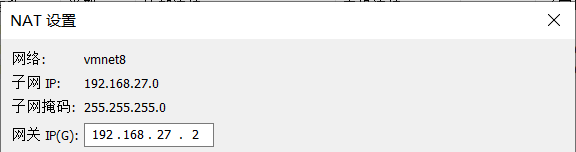
- 点击 VMnet8 那一栏,点击 NAT设置

- 记住子网掩码和网关IP
- 输入 vim /etc/sysconfig/network-scripts/ifcfg-ens33,修改红框部分,注意IPADDR与子网的网段要一致

- 输入 systemctl restart network
- 输入 ifconfig 查看,ping 外网


2. IP和主机名映射
- 输入 hostname 查看主机名

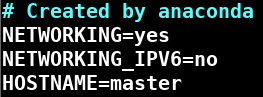
- 输入 vim /etc/sysconfig/network 修改主机映射文件
- 输入 ifconfig 查看IP
- 输入 vim /etc/hosts 增加IP和主机名的映射

3. 关闭防火墙和Selinux
- 输入 systemctl status firewalld.service 查看防火墙状态
- 输入 systemctl stop firewalld.service 关闭防火墙
- 输入 systemctl disable firewalld.service 关闭防火墙自启
- 输入 vim /etc/sysconfig/selinux,将 SELINUX=enforcing 改为 SELINUX=disabled
4. 安装JDK
- 将JDK安装包放在 /opt 目录下,
输入 tar -zxvf jdk-8u241-linux-x64.tar.gz,解压完毕有 jdk1.8.0_241 文件夹。 - 输入 vim /etc/profile,添加下面的环境变量

- 输入 source /etc/profile
- 输入 java -version 检验

5. 拍摄快照
拍摄快照(后面搭建完全分布式模式需要用)(注意虚拟机要处于关机状态拍摄的快照才能克隆)
6. 安装Hadoop
- 进入Hadoop安装包所在目录,输入 tar -zxvf hadoop-2.9.2.tar.gz -C /opt,解压完毕有 hadoop-2.9.2 文件夹。
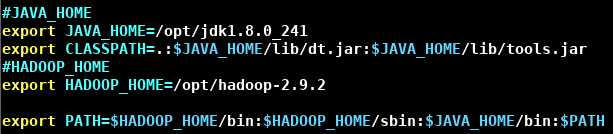
- 输入 vim /etc/profile,添加下面的环境变量
- 输入 source /etc/profile
- 输入 hadoop version 检验


7. 单机模式
完成上面的操作,Hadoop就处于单机模式,可以按官方给定的例子测试(该步骤可以省略)。
例子1:
将 $HADOOP_HOME/etc/hadoop 目录下的所有xml文件复制到input文件夹,查找文件内dfs开头的字符串,将结果放到output文件夹(output文件夹不可以预先创建,如果存在会报FileAlreadyExistsException)
mkdir input
cp etc/hadoop/*.xml input
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar grep input output 'dfs[a-z.]+'
cat output/*
例子2:
创建一个文件夹,mkdir wcinput。
在文件夹内写一个文件,vim wc.input
touch touch
window window
sun sun sun sun sun
phone
hadoop hadoop hadoop
进入wcinput文件夹,输入 hadoop jar /opt/hadoop-2.9.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount . wcoutput
查看生成的文件 cat wcoutput/part-r-00000
hadoop 3
phone 1
sun 5
touch 2
window 2
8. 伪分布式模式
启动HDFS
- 输入 vim etc/hadoop/hadoop-env.sh,修改 JAVA_HOME 变量,将其改为Java的安装目录($HADOOP_HOME/etc/hadoop/下)


- 配置 core-site.xml($HADOOP_HOME/etc/hadoop/下)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.9.2/data/tmp</value>
</property>
</configuration>
- 配置 hdfs-site.xml($HADOOP_HOME/etc/hadoop/下)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<!-- replication 是数据副本数量,默认为3-->
</property>
</configuration>
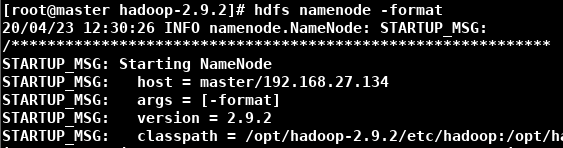
- 进入Hadoop安装目录,输入 bin/hdfs namenode -format,格式化NameNode。(第一次格式化时不会出现问题,以后如果格式化出现提示是否重新格式化,则可能有数据未清理,则需要清理后再格式化)(格式化NameNode会产生新的集群ID,导致NameNode和DataNode的集群ID不一致,NameNode和DataNode之间不能通信,集群找不到以前的数据。所以,格式化NameNode时要先删除data数据和log日志(上面自己配置的存储数据的路径)再格式化)(下面是格式化开始和结束的样子)
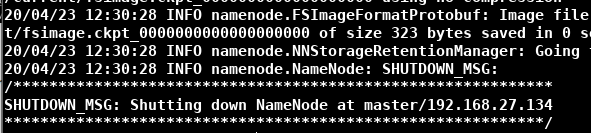
- 输入 sbin/hadoop-daemon.sh start namenode,启动NameNode

- 输入 sbin/hadoop-daemon.sh start datanode,启动DataNode

- 输入 jps,查看是否有NameNode和DataNode
- 在浏览器输入 http://master:50070/,如果显示下面的网页则HDFS启动成功

测试:
- 输入 bin/hdfs dfs -mkdir /tmp,在HDFS / 下创建目录

- 输入 hdfs dfs -put wcinput/wc.input /tmp,将本地文件上传到HDFS

- 输入 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /tmp/wc.input /tmp/output
- 输入 hdfs dfs -cat /tmp/output/part-r-00000 查看文件内容

启动YARN
- 输入 vim etc/hadoop/yarn-env.sh,修改 JAVA_HOME 变量,将其改为Java的安装目录($HADOOP_HOME/etc/hadoop/下)


- 配置 yarn-site.xml($HADOOP_HOME/etc/hadoop/下)
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>
- 输入 vim etc/hadoop/mapred-env.sh,修改 JAVA_HOME 变量,将其改为Java的安装目录($HADOOP_HOME/etc/hadoop/下)

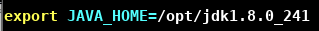
- 输入 mv etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml,将mapred-site.xml.template 重命名为mapred-site.xml
- 配置 mapred-site.xml($HADOOP_HOME/etc/hadoop/下)
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 输入 sbin/yarn-daemon.sh start resourcemanager 启动ResourceManager

- 输入 sbin/yarn-daemon.sh start nodemanager 启动NodeManager

- 输入 jps,查看是否有ResourceManager和NodeManager
- 在浏览器输入 http://master:8088/,查看网页是否可以正常显示

测试
- 输入 hdfs dfs -rm -r /tmp/output 删除HDFS的/tmp/output
- 输入 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /tmp/wc.input /tmp/output

- 浏览器打开 http://master:8088/,可以看到刚才执行的操作的信息

配置历史服务器
历史服务器可以查看程序的历史运行情况。
- 在 mapred-site.xml 添加下面的配置
<property>
<!-- history server address -->
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
- 输入 sbin/mr-jobhistory-daemon.sh start historyserver 启动历史服务器

- 输入 jps 查看是否有JobHistoryServer
- 到浏览器 http://master:8088/ 查看


配置日志聚集
日志聚集:应用运行完成之后,将程序运行日志信息上传到HDFS上,可以方便查看程序运行详情,方便开发调试。(该步骤可以省略)
开启日志聚集需要重新启动NameManager,ResourceManager,HistoryManager。
-
输入 sbin/mr-jobhistory-daemon.sh stop historyserver,sbin/yarn-daemon.sh stop nodemanager,sbin/yarn-daemon.sh stop resourcemanager 关闭NameManager,ResourceManager,HistoryManager。
-
配置 yarn-site.xml,添加下面配置
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!-- 日志保留7天 -->
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
- 输入 sbin/yarn-daemon.sh start resourcemanager,sbin/yarn-daemon.sh start nodemanager,sbin/mr-jobhistory-daemon.sh start historyserver 启动NameManager,ResourceManager,HistoryManager。
9. 完全分布式模式
在搭建前先依次关闭yarn和dfs,输入 sbin/stop-yarn.sh,sbin/stop-dfs.sh,sbin/mr-jobhistory-daemon.sh stop historyserver。
克隆2个slave
- 点击虚拟机上方的管理快照按钮。(注意该快照是在关机状态拍的)



修改信息(两个slave)
注意:修改信息这个步骤你有多少个slave就要操作多少次
-
修改MAC地址



-
将生成的MAC地址写入 /etc/sysconfig/network-scripts/ifcfg-ens33 文件,同时修改IP地址
-
输入命令 uuidgen,将生成的UUID写入ifcfg-ens33


-
输入 vim /etc/sysconfig/network 修改HOSTNAME
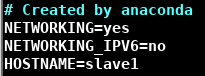
-
输入 vim /etc/hostname 修改主机名
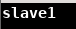
-
输入 vim /etc/hosts 修改映射

-
输入 systemctl restart network 重启网络服务
-
输入 reboot 重启
-
输入 ping www.sina.com 检查能否ping成功
-
输入 ping master 检查能否ping成功
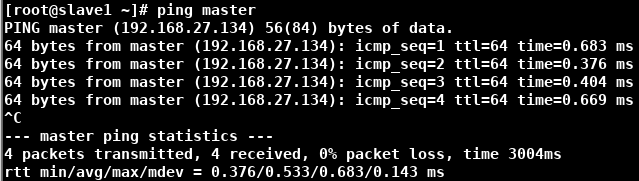
主节点复制数据到从节点
scp -r $pdir/$fname $user@$host:$pdir/$fname
命令 递归 要复制的文件路径/名称 目的用户@主机名:目的路径/名称
scp可以实现服务器与服务器之间的数据拷贝。
有三种方式
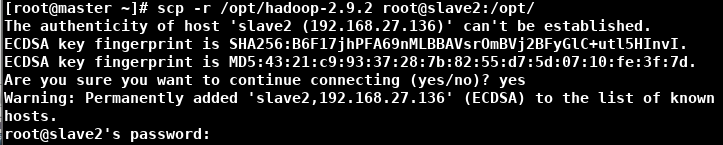
1. scp -r /opt/hadoop-2.9.2 root@slave1:/opt/(在master操作)
2. scp -r root@master:/opt/hadoop-2.9.2 ./(在slave1操作)
3. scp -r root@master:/opt/hadoop-2.9.2 root@slave2:/opt/(在slave1操作)
-
在master节点输入 scp -r /opt/hadoop-2.9.2 root@slave1:/opt/
-
在master节点输入 scp -r /opt/hadoop-2.9.2 root@slave2:/opt/


-
在master节点输入 scp -r /etc/profile root@slave1:/etc/profile
-
在master节点输入 scp -r /etc/profile root@slave2:/etc/profile
-
在slave1输入 source /etc/profile
-
在slave2输入 source /etc/profile
ssh免密登录

- 输入 cd 返回master节点root的家目录,输入 ls -al,发现有一个 .ssh 文件夹,输入 cd .ssh
- 输入 ssh-keygen -t rsa 生成公钥和私钥(中间按三个Enter)


- 在master节点输入 ssh-copy-id slave1,ssh-copy-id slave2,在slave1和slave2的.素数文件夹会产生authorized_key文件夹


- 在master节点输入 ssh-copy-id master,因为自己访问自己也要输密码,然后去authorized_key查找公钥

- 上面的操作分别在slave1和slave2做一次
编写集群分发脚本xsync
- 在 /usr/local/bin 目录下创建 xsync 文件:vim /usr/local/bin/xsync
#!/bin/sh
# 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args...;
exit;
fi
# 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
# 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
# 获取当前用户名称
user=`whoami`
# 循环
for((host=1; host<=2; host++)); do
echo "$pdir/$fname->$user@slave$host:$pdir"
echo ==================slave$host==================
rsync -rvl $pdir/$fname $user@slave$host:$pdir
done
#Note:这里的slave对应自己主机名,需要做相应修改。另外,for循环中的host的边界值
rsync主要用于备份和镜像,具有速度快、避免复制相同内容和支持符号链接的优点。rsync和scp的区别是,rsync只对差异文件更改,scp是将所有文件复制。
rsync -rvl $pdir/$fname $user@$host:$pdir/$fname
命令 参数 要复制的文件路径/名称 目的用户@主机名:目的路径/名称
-r是递归,-v是显式复制过程,-l是拷贝符号链接
2. 输入 chmod 777 /usr/local/bin/xsync 给文件添加执行权限
集群配置
| master | slave1 | slave2 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| Yarn | NodeManager | ResourceManager NodeManager | NodeManager |
- 配置 core-site.xml($HADOOP_HOME/etc/hadoop/下)
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.9.2/data/tmp</value>
</property>
- 输入 vim etc/hadoop/hadoop-env.sh,修改 JAVA_HOME 变量,将其改为Java的安装目录($HADOOP_HOME/etc/hadoop/下)
- 配置 hdfs-site.xml($HADOOP_HOME/etc/hadoop/下)
<property>
<name>dfs.replication</name>
<value>3</value>
<!-- replication 是数据副本数量,默认为3-->
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:50090</value>
</property>
- 输入 vim etc/hadoop/yarn-env.sh,修改 JAVA_HOME 变量,将其改为Java的安装目录
- 配置 yarn-site.xml($HADOOP_HOME/etc/hadoop/下)
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>slave1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>slave1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>slave1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>slave1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>slave1:8088</value>
</property>
<!-- Site specific YARN configuration properties -->
- 输入 vim etc/hadoop/mapred-env.sh,修改 JAVA_HOME 变量,将其改为Java的安装目录($HADOOP_HOME/etc/hadoop/下)
- 输入 mv etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml,将mapred-site.xml.template 重命名为mapred-site.xml
- 配置 mapred-site.xml($HADOOP_HOME/etc/hadoop/下)
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 输入 xsync /opt/hadoop-2.9.2/etc 在集群上同步配置文件
- 到slave节点查看分发情况
启动集群
注意:NameNode和ResourceManager如果不是在同一台机器,不能在NameNode上启动Yarn,应该在ResourceManager所在的集群上启动Yarn。简单来说,在配置了NameNode的机器上启动dfs,在配置了ResourceManager的集群上启动Yarn。
-
在master节点配置 $HADOOP_HOME/etc/hadoop/下的slaves文件,输入 vim etc/hadoop/slaves(注意不能有空格和空行!!!)

-
输入 xsync etc/hadoop/slaves 在集群上同步slaves文件
-
在三个节点的hadoop安装目录上输入 rm -rf data/ logs/ 删除以前运行产生的数据和日志目录(这一步一定要做)
-
master节点(NameNode所配置的地方)进入Hadoop安装目录,输入 hdfs namenode -format,格式化NameNode。(正常格式化开始和结束的样子在上面第八步有)
-
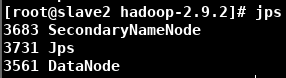
激动人心的时刻到了!!!在master节点(NameNode所配置的地方)输入 sbin/start-dfs.sh


-
在slave1节点(ResourceManager所配置的地方)输入 sbin/start-yarn.sh

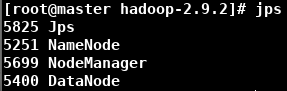
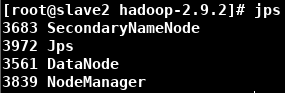
-
在浏览器输入 http://master:50070/,检查 Datanode Information(有可能出现DataNode不够三个)输入 hdfs fsck -locations 查看Number of data-nodes是否等于配置的DataNode数


-
在浏览器输入 http://slave1:8088/

集群测试
- 输入 hdfs dfs -put wcinput/wc.input / 上传一个小文件
- 输入 hdfs dfs -put /opt/jdk-8u241-linux-x64.tar.gz / 上传一个大文件



数据分别存放在三个节点,路径如下:

- 输入 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wc.input /output


9. 总结
集群启动/停止方式总结
- 各个服务组件逐一启动/停止
- 分别启动/停止HDFS组件
hadoop-daemon.sh start/stop namenode/datanode/secondarynamenode - 分别启动/停止Yarn组件
yarn-daemon.sh start/stop resourcemanager/nodemanager
- 分别启动/停止HDFS组件
- 各个模块分开启动/停止(配置好ssh)(常用)
- 整体启动/停止HDFS(配置了NameNode的节点)
start-dfs.sh/stop-dfs.sh - 整体启动/停止Yarn(配置了ResourceManager的节点)
start-yarn.sh/stop-yarn.sh
- 整体启动/停止HDFS(配置了NameNode的节点)
- 全部启动/停止
- start-all.sh/stop-all.sh
遇到的问题
- hadoop-env.sh里面的JAVA_HOME原本=${JAVA_HOME},我在/etc/profile已经配置好了JAVA_HOME。脚本运行时可以引用该环境变量,为什么还需要手动修改hadoop-env.sh中的JAVA_HOME为显式路径?(未解决)
- ifconfig查询到的ip与网卡配置文件中的ip不一致。原本克隆出来的IP地址为192.168.27.138,我想将它固定为192.168.27.135。修改/etc/sysconfig/network-scripts/ifcfg-ens33为BOOTPROTO=static,IPADDR=192.168.27.135,systemctl restart network之后,IP变为192.168.27.135。重启虚拟机后,又变回来了,ifconfig显示的是192.168.27.138,但另一台虚拟机可以同时ping成功192.168.27.135和192.168.27.138。ip addr的ens33有两个IP地址。(未解决)
- Replication与Availability不一致,Replication=3与Availability只有一个,hdfs fsck -locations的Number of data-nodes=1。后来发现是我的IP错误引起的(就是上面那个问题,后来我只好固定IP为192.168.27.138)
下面是这个问题的其它原因及解决方法:
1. Hadoop datanode正常启动,但是Live nodes中却缺少节点的问题:data目录重复,修改路径
2. Live datanodes节点显示不全:修改data路径
3. hadoop 3.x Replication与Availability不一致:之前没有删除data目录,删除之后格式化NameNode
4. 发现hadoop搭建环境是Availability:只有一个(即只有一个节点启动而已):删除data和logs目录格式化
5. hadoop集群不管怎么启动在hadoop管理界面都看到只有一个datanode:克隆虚拟机,导致多节点的DataNode的datanodeUuid和storageID相同,修改分别修改它们的ID - 搭建Hadoop所遇过的坑
参考其它安装博客
尚硅谷Hadoop教程(hadoop框架精讲)
Hadoop安装与配置详细教程
Hadoop安装与配置
Hadoop三种模式安装教程(详解)
hadoop2.9.2安裝















 3595
3595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









