






SparkShuffle
- reduceByKey会将上一个RDD中的每一个key对应的所有value聚合成一个value,然后生成一个新的RDD,元素类型是<key,value>对的形式,这样每一个key对应一个聚合起来的value。
- 问题:
- 聚合之前,每一个key对应的value不一定都是在一个partition中,也不太可能在同一个节点上,因为RDD是分布式的弹性的数据集,RDD的partition极有可能分布在各个节点上。
- 如何聚合?
- Shuffle Write:上一个stage的每个map task就必须保证将自己处理的当前分区的数据相同的key写入一个分区文件中,可能会写入多个不同的分区文件中。
- Shuffle Read:reduce task就会从上一个stage的所有task所在的机器上寻找属于自己的那些分区文件,这样就可以保证每一个key所对应的value都会汇聚到同一个节点上去处理和聚合。
SortShuffle
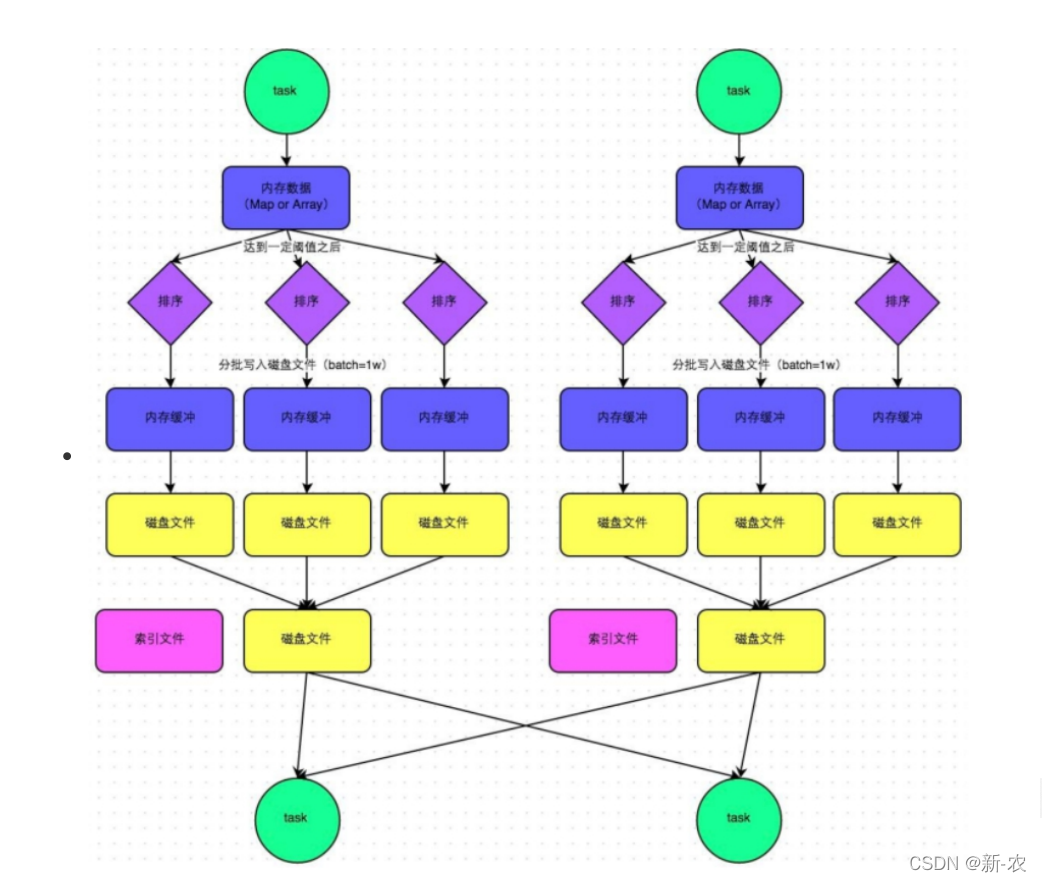
1、普通机制
- 执行流程
1、map task 的计算结果会写入到一个内存数据结构里面,内存数据结构默认是 5M 。
2、在 shuffle 的时候会有一个定时器,不定期的去估算这个内存结构的大小,当内存结构中的 数据超过 5M 时,比如现在内存结构中的数据为 5.01M ,那么他会申请 5.01*2-5=5.02M 内存给内存数据结构。
3、如果申请成功不会进行溢写,如果申请不成功,这时候会发生溢写磁盘。
4、在溢写之前内存结构中的数据会进行排序分区
5、然后开始溢写磁盘,写磁盘是以 batch 的形式去写(批量),一个 batch 是1万条数据。
6、map task 执行完成后,会将这些 磁盘小文件 合并成一个大的磁盘文件,同时生成一个 索引文件 。
7、reduce task 去 map 端拉取数据的时候,首先解析索引文件,根据索引文件再去拉取对应的数据。- 生成文件个数
产生磁盘小文件的个数: 2*M(map task的个数)
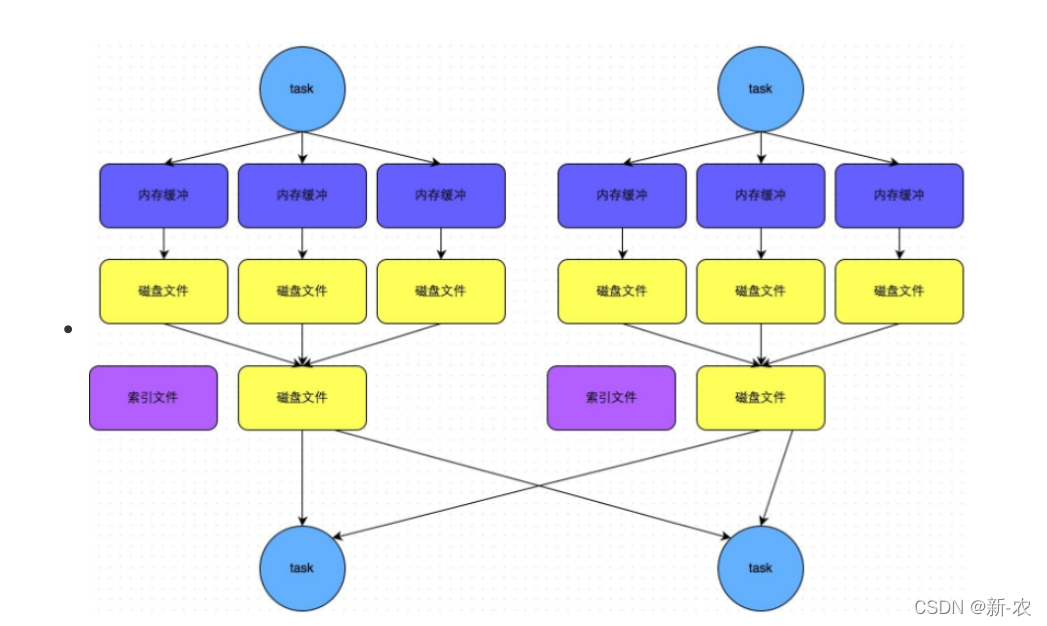
2、bypass机制
- bypass 运行机制的触发条件如下:
1、shuffle reduce task 的数量小于 spark.shuffle.sort.bypassMergeThreshold 的参数
值。这个值默认是 200 。
2、不需要进行 map 端的预聚合,比如 groupBykey , join 。- 生成文件个数
产生的磁盘小文件为: 2*M(map task的个数) 。
Shuffle文件寻址
1、名词解释
- MapOutputTracker
MapOutputTracker 是 Spark 架构中的一个模块,是一个主从架构。管理磁盘小文件的地址。
MapOutputTrackerMaster 是主对象,存在于 Driver 中。
MapOutputTrackerWorker 是从对象,存在于 Excutor 中。- BlockManager
BlockManager :块管理者,是 Spark 架构中的一个模块,也是一个主从架构。
BlockManagerMaster ,主对象,存在于Driver中。
BlockManagerWorker ,从对象,存在于Excutor中。
1. BlockManagerMaster 会在集群中有用到广播变量和缓存数据或者删除缓存数据的时候,通知BlockManagerSlave 传输或者删除数据。
2. BlockManagerWorker ,从对象,存在于 Excutor 中。
3. BlockManagerWorker 会与 BlockManagerWorker 之间通信。
无论在 Driver 端的 BlockManager 还是在 Excutor 端的 BlockManager 都含有四个对象:
1. DiskStore :负责磁盘的管理。
2. MemoryStore :负责内存的管理。
3. · :负责连接其他的 BlockManagerWorker 。
4. BlockTransferService :负责数据的传输。
2、Shuffle 文件寻址流程
1、当map task 执行完成后,会将task的执行情况和磁盘小文件的地址 封装到 MapStatus 对象中,然后由MapOutputTrackerWorker对象向Driver中的MapOutputTrackerMaster汇报
2、在所有的 map task任务执行完毕后,Driver中就掌握了所有的磁盘小文件的地址
3、在reduce task执行之前,会通过Excutor中的MapOutputTrackerWorker向Driver端的MapOutputTrackerMaster获取磁盘小文件的地址。
4、获取到磁盘小文件的地址后,会通过BlockManager中的ConnectionManager连接数据所在节点上的ConnectionManager,然后,通过 BlockTransferService进行数据的传输
5、BlockTransferService默认启动5个task去节点拉取数据。默认情况下,5个task拉取数据量不能超过48M.
至于详细的 任务调度 :可点击查看
over 感谢观看!















 3469
3469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









