







Fayson的github: https://github.com/fayson/cdhproject
推荐关注微信公众号:“Hadoop实操”,ID:gh_c4c535955d0f
1 文档编写目的
在上一篇文章《6.1.0-如何将ORC格式且使用了DATE类型的Hive表转为Parquet表》中主要介绍了非分区表的转换方式,本篇文章Fayson主要针对分区表进行介绍。
内容概述
1.准备测试数据及表
2.Hive ORC表转Parquet
3.总结
测试环境
1.RedHat7.4
2.CM和CDH版本为6.1.0
2 Hive ORC表转Parquet表
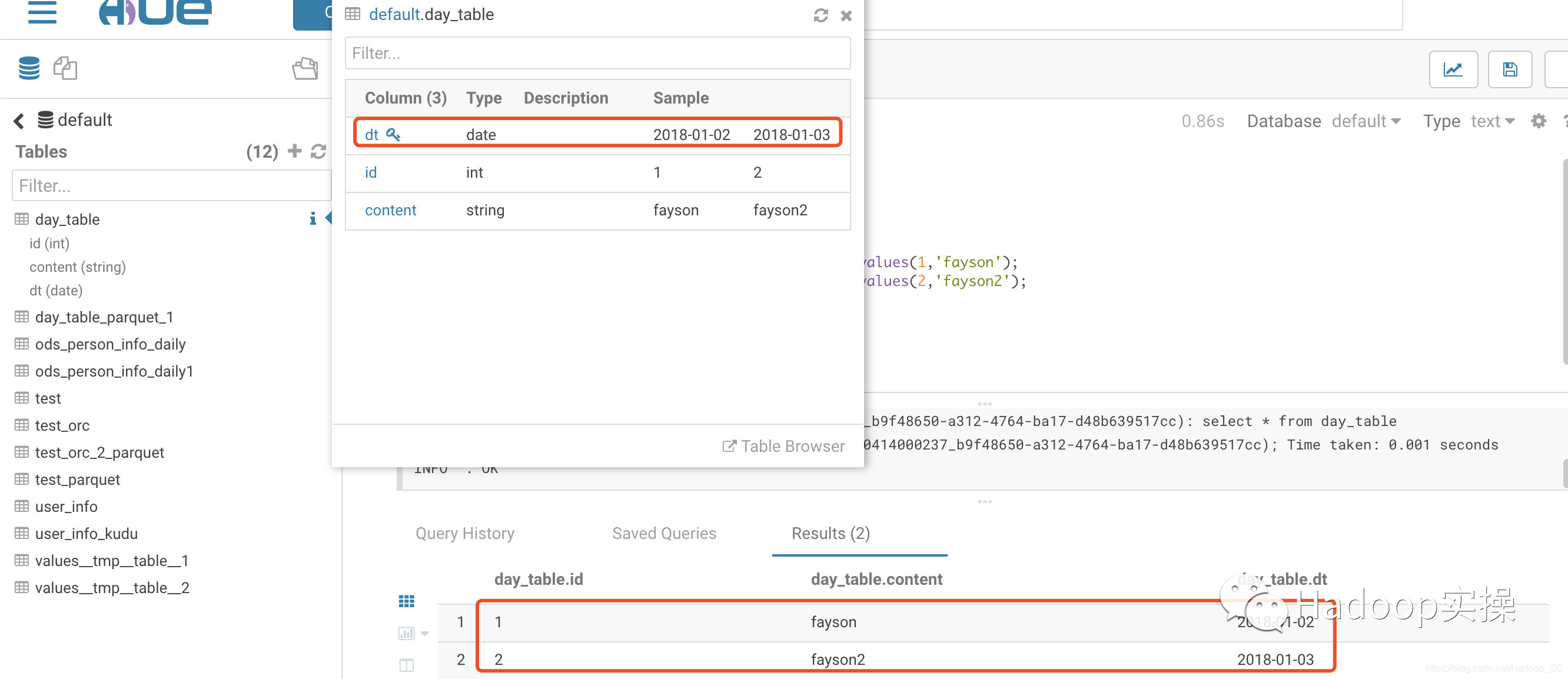
1.创建一个使用DATE类型作为分区字段的表,并插入测试数据
create table day_table (id int, content string)
partitioned by (dt date)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS ORC;
insert into day_table PARTITION(dt = '2018-01-02') values(1,'fayson');
insert into day_table PARTITION(dt = '2018-01-03') values(2,'fayson2');
select * from day_table;
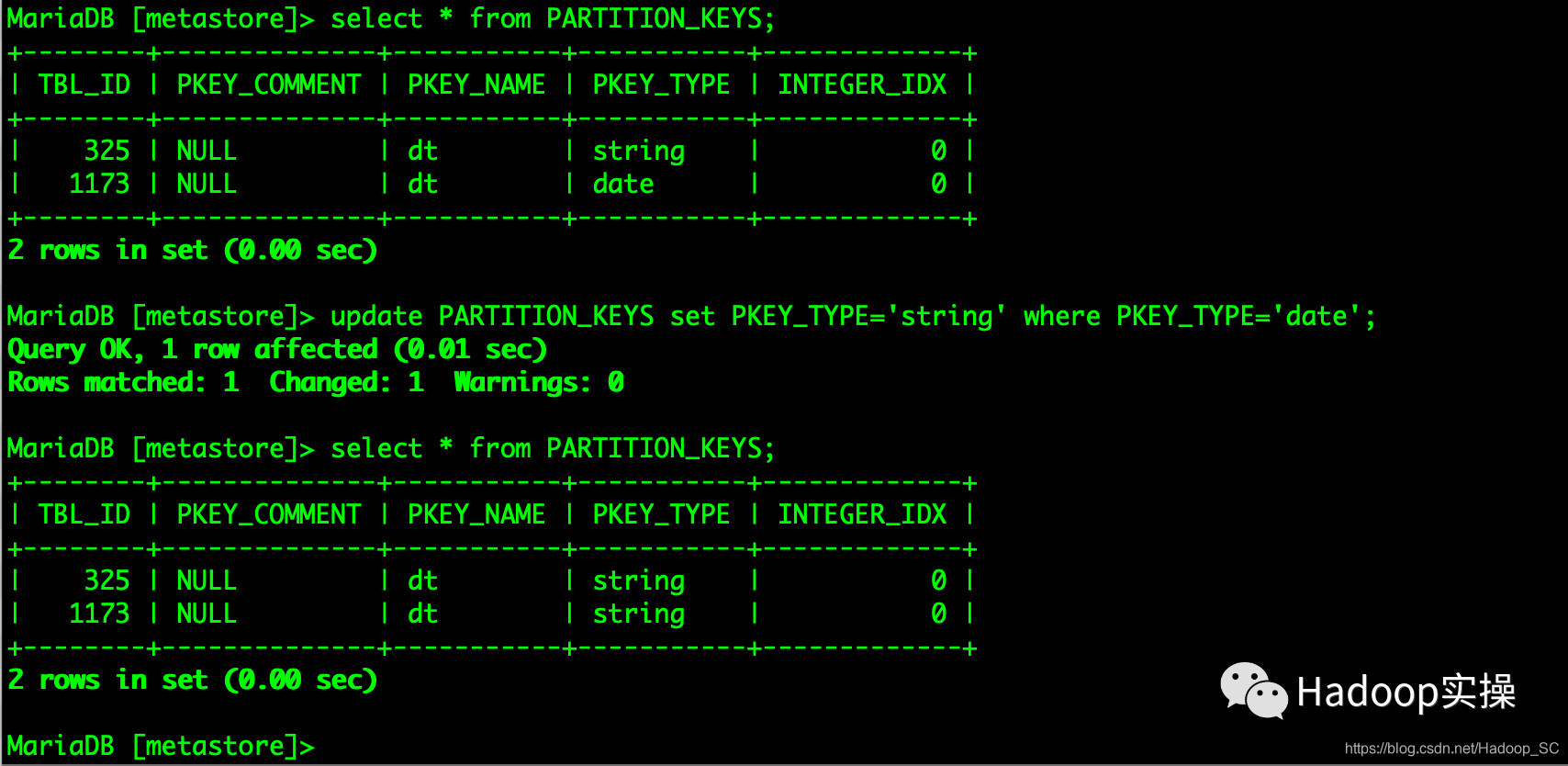
2.登录Hive的元数据库,在数据库中将所有Hive表中分区为DATE类型的数据修改为STRING
MariaDB [metastore]> select * from PARTITION_KEYS;
MariaDB [metastore]> update PARTITION_KEYS set PKEY_TYPE='string' where PKEY_TYPE='date';
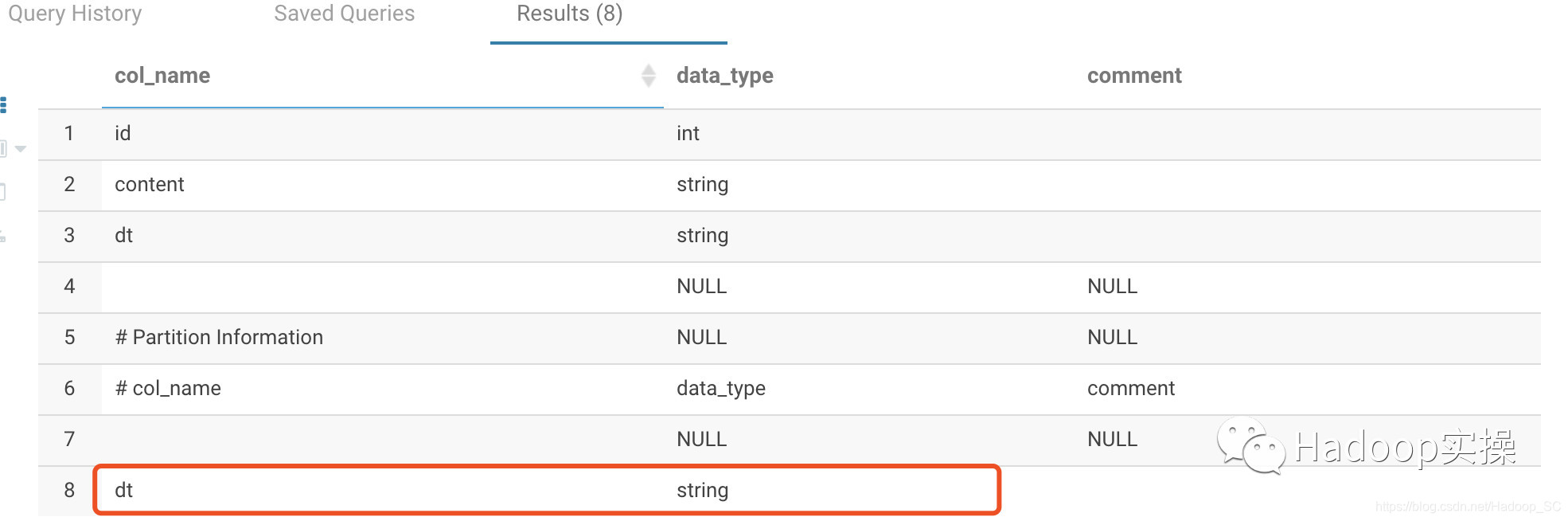
查看day_table表的DATE类型字段是已修改为STRING
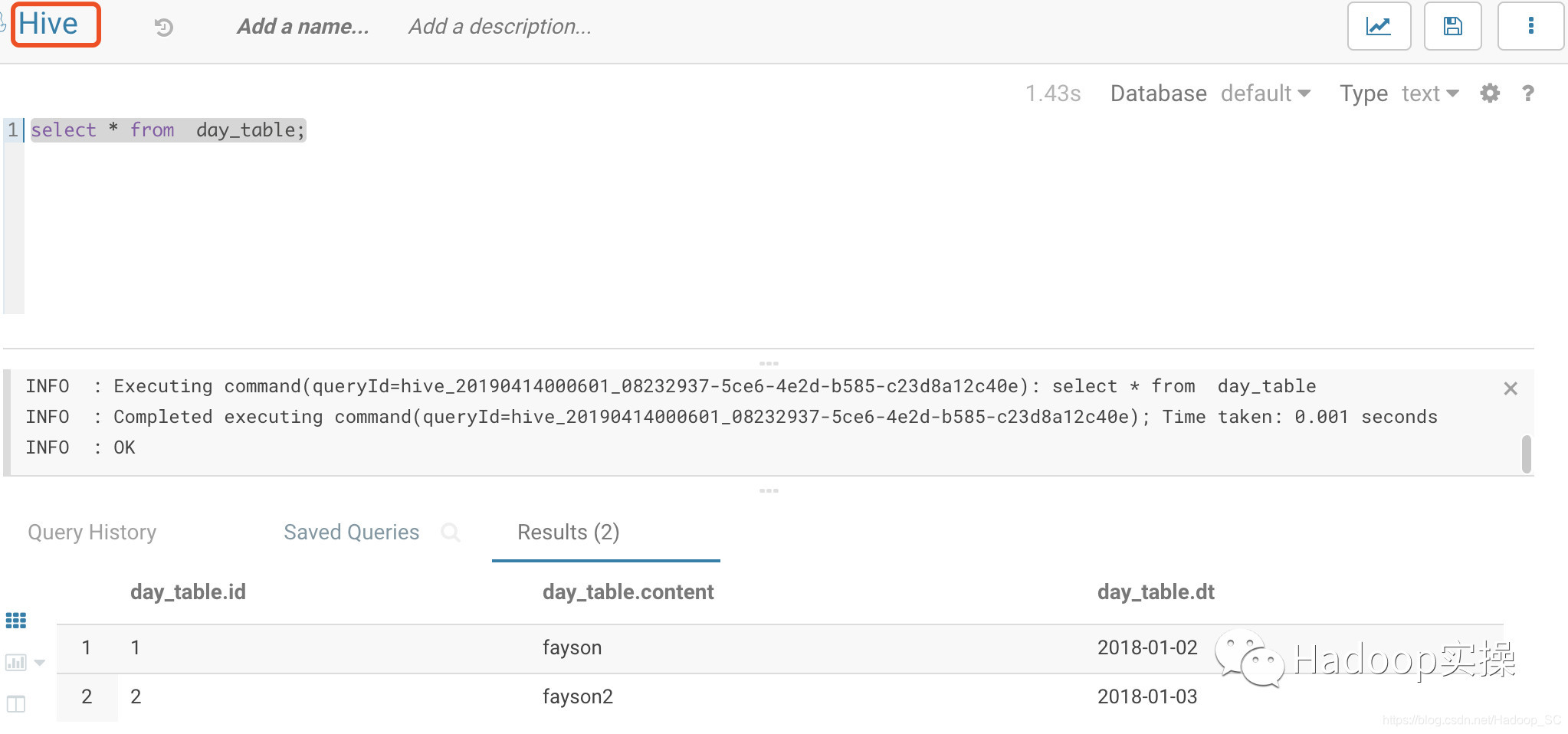
使用Hive可以正常查询day_table表数据
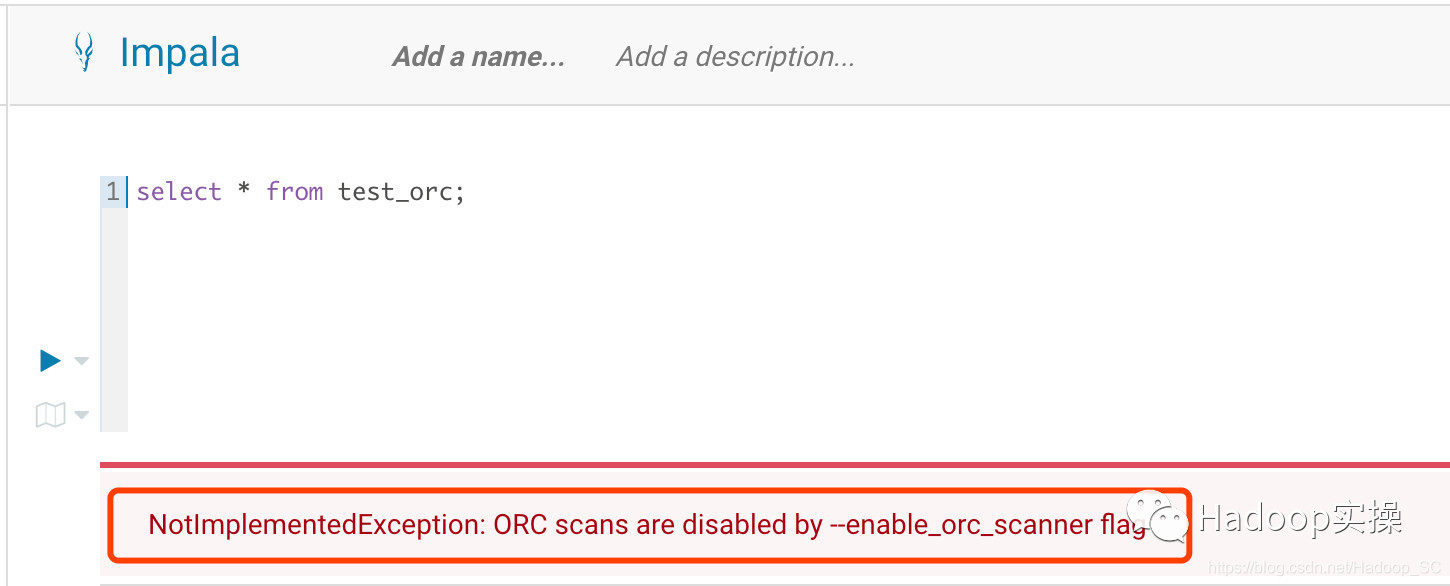
使用Impala查询提示“ORC scans are disabled by --enable_orc_scanner flag”
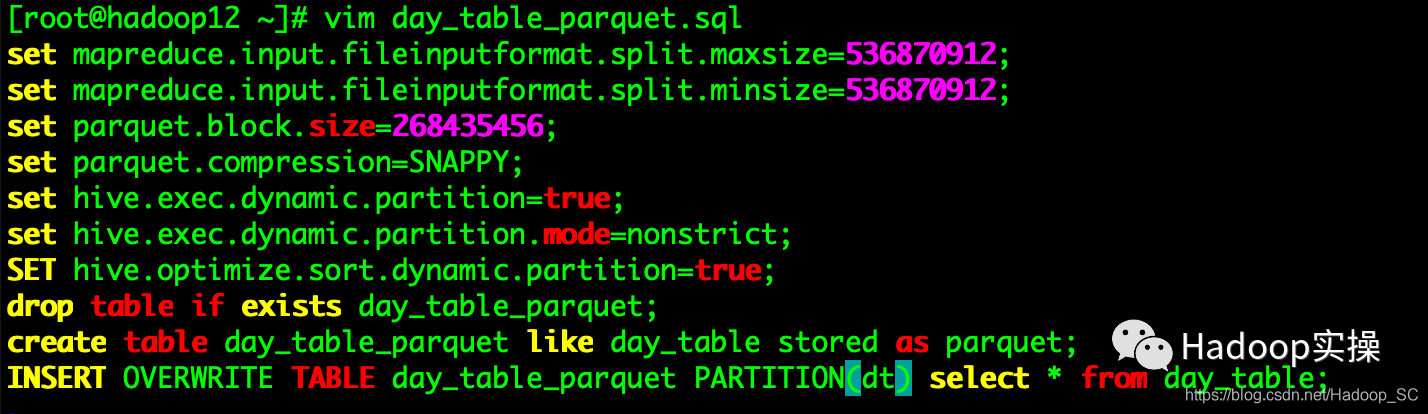
3.准备Hive SQL脚本将test_orc表转为Parquet格式的表
[root@hadoop12 ~]# vim day_table_parquet.sql
set mapreduce.input.fileinputformat.split.maxsize=536870912;
set mapreduce.input.fileinputformat.split.minsize=536870912;
set parquet.block.size=268435456;
set parquet.compression=SNAPPY;
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
SET hive.optimize.sort.dynamic.partition=true;
drop table if exists day_table_parquet;
create table day_table_parquet like day_table stored as parquet;
INSERT OVERWRITE TABLE day_table_parquet PARTITION(dt) select * from day_table;
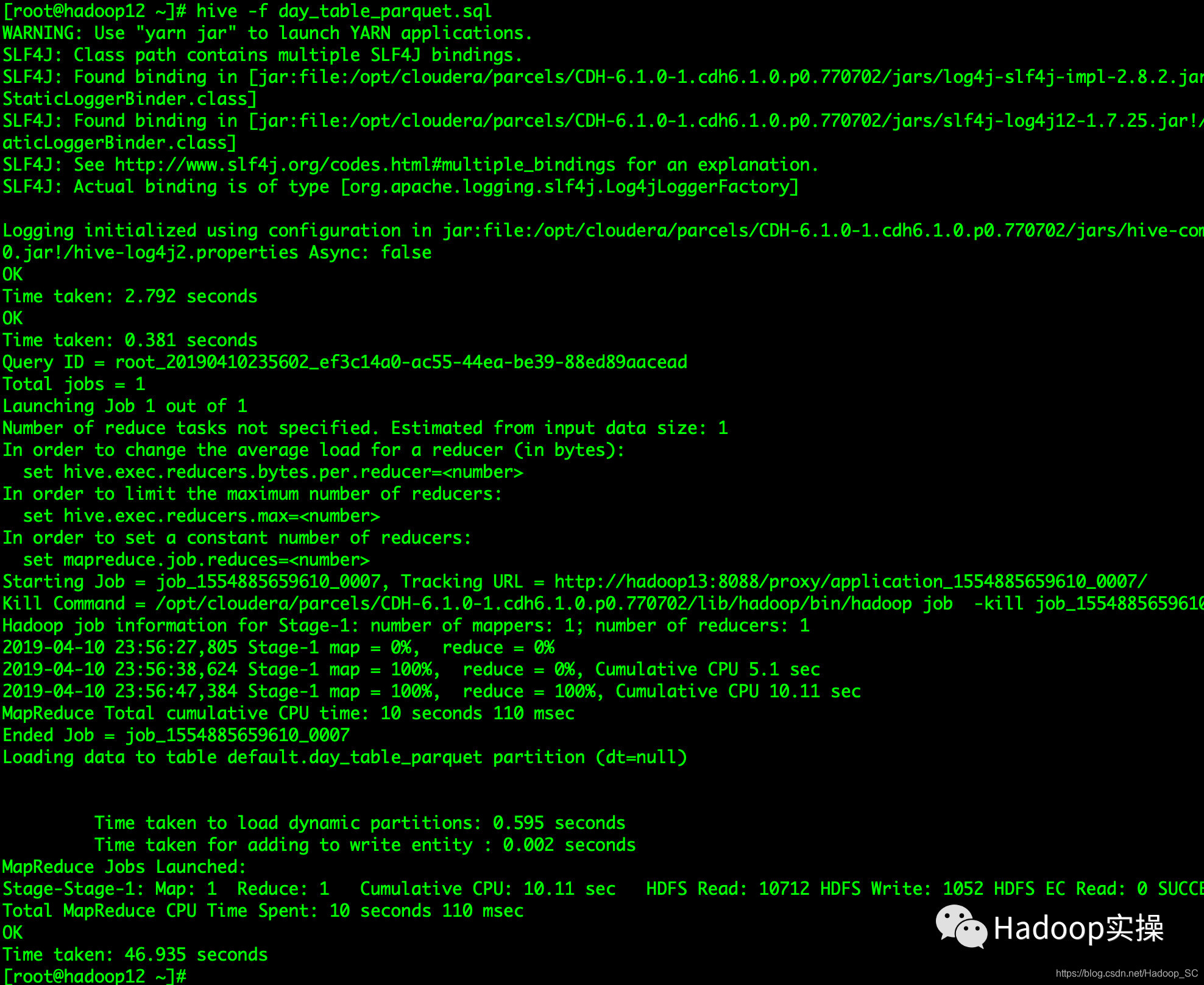
4.在命令行使用hive命令执行day_table_parquet.sql脚本
[root@hadoop12 ~]# hive -f test_parquet.sql
5.查看day_table_parquet表正常,格式转为parquet且访问正常

使用Impala访问day_table_parquet表
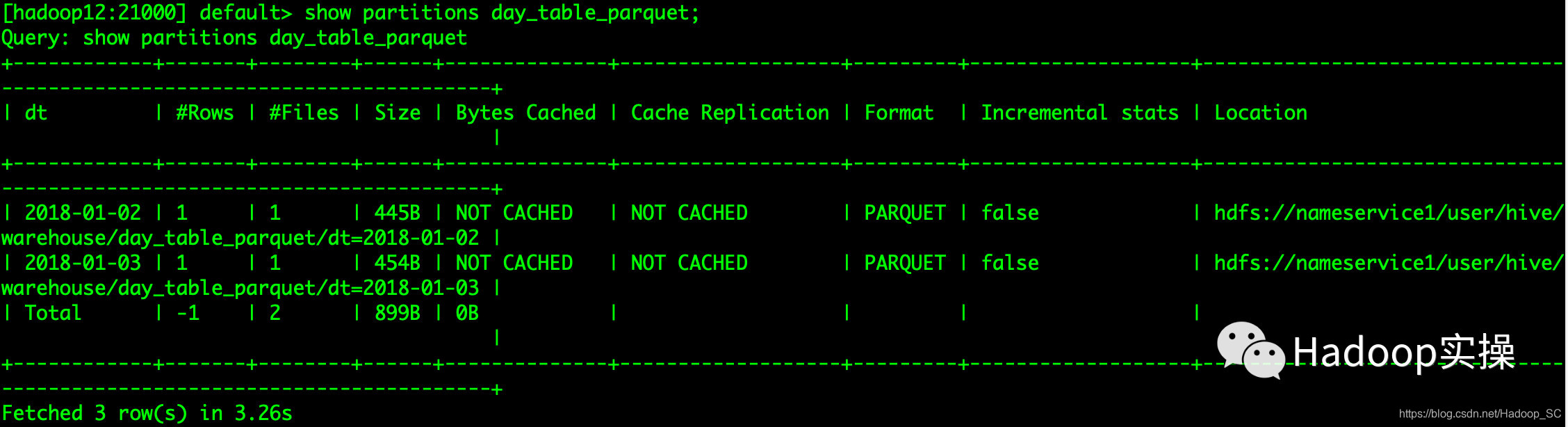
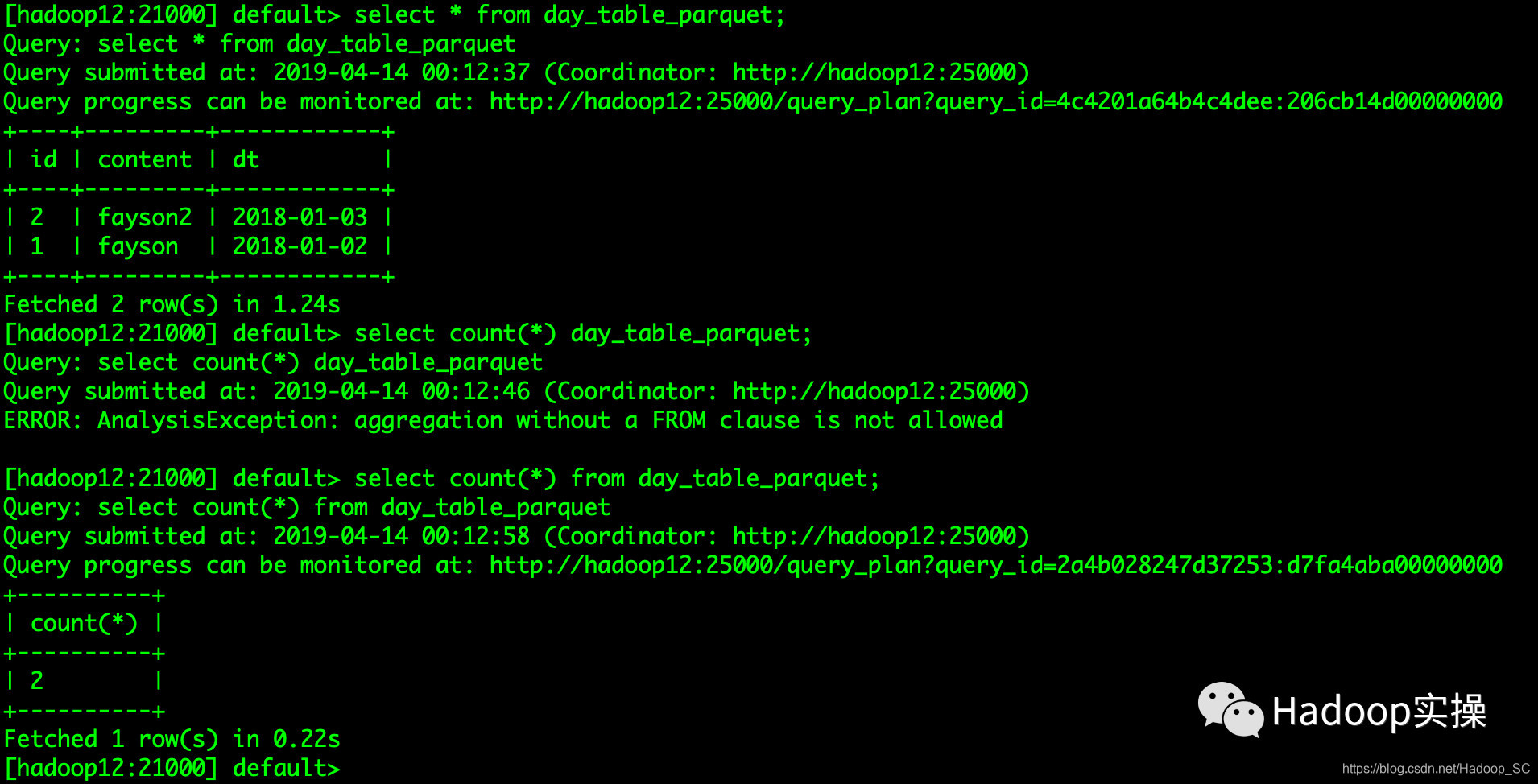
分区数与原表分区数一致,且数据可以正常查询
3 总结
1.Hive对ORC格式的表没有做严格的数类型校验,因此在统一的修改了Hive元数据库的DATE类型为STRING类型后,ORC格式的表依然可以正常查询。
2.在C6版本中其实已经支持了ORC格式的表,但默认是禁用的,可以通过在Impala Daemon的高级配置中增加–enable_orc_scanner参数来启用,由于C6版本目前刚支持ORC格式,是否存在问题和风险有待验证。
3.Impala默认是不支持DATE类的,同时Impala对Parquet或ORC文件中的数据类型有严格的校验,因此在将Hive元数据库中DATE类型修改为STRING类型后查询依然会报“Unsupported type ‘DATE’”
4.Hive元数据库中的PARTITION_KEYS表中主要存储Hive表分区字段信息,这里介绍的转换方式比较暴力,但是爽啊!!!

















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









