







 这篇学习笔记介绍了关系型数据库MySQL的基础知识,包括数据库设计、实体关系图、关系模式和查询语法。内容涵盖如何使用SQL查询特定数据,如通过WHERE、BETWEEN、IN、LIKE等操作符筛选数据,以及如何格式化和排序查询结果。笔记还涉及了聚合函数、子查询和连接操作,并提供了实际的练习题来巩固学习。
这篇学习笔记介绍了关系型数据库MySQL的基础知识,包括数据库设计、实体关系图、关系模式和查询语法。内容涵盖如何使用SQL查询特定数据,如通过WHERE、BETWEEN、IN、LIKE等操作符筛选数据,以及如何格式化和排序查询结果。笔记还涉及了聚合函数、子查询和连接操作,并提供了实际的练习题来巩固学习。
Managing Big Data with MySQL学习笔记
Intro
SQL: 关系型数据库( MySQL, Teradata)
By the end of this course, you will know how to:
-
Describe the structure of relational databases;
-
Interpret and create entity-relationship diagrams and relational schemas that describe the contents of specific databases;
-
Write queries that retrieve and sort data that meet specific criteria, and retrieve such data from MySQL and Teradata databases that contain over 1 million rows of data;
-
Execute practices that limit the impact of your queries on other coworkers;
-
Summarize rows of data using aggregate functions, and segment aggregations according to specified variables;
-
Combine and manipulate data from multiple tables across a database;
-
Retrieve records and compute calculations that are dependent on dynamic data features, and translate data analysis questions into SQL queries.
Week 1
How Relational Databases Help Solve Those Problems
关系型数据库的基本概念是 将数据集拆分为单独的数据片段或者子集 每一个数据子集都有一个主题, 这个主题在逻辑上将数据记录和 这个子集相绑定。在检索信息时,数据库只会和某些子集交互 这些子集提供了你想要的数据 而不是和整个数据库交互这一策略确保了数据只需要 尽可能少的空间去存储,同时让检索变快。

- 单个表应表示数据集的最小逻辑部分
- 表中的每一列 都必须表示唯一的 信息类别 (各种记录)
- 表中的每一行也必须表示该信息的唯一实例 (各种记录对应的数据域)
- 键(key)的值在不同列中唯一
- 表中列的顺序或 行的顺序是无关紧要的 这将允许数据库按任意的, 它认定是最快的 顺序或样式将它们拉到一起
Database Design Tools
数据库设计和模型架构
- Entity-Relationship Diagram
- Relational Schemas
Entity-Relationship Diagram
ERDPlus
这些表是通过一个或 多个具有相同值的列连接起来的。 通过这些列(的值),我们可以把不同表中的行数据关联起来。

-
实体(矩形)

正方形表示实体。 这些体现你在数据库中所保存数据的种类。 每个正方形是一个种类。 最后实现数据库的时候,每个实体大概率会成为表。双矩形表示
Weak Entity -
属性(椭圆)

每个数据种类 也就是实体需要记录的数据的一些具体的方面。 属性一般会体现在实体的 列。 实体关系图中的每一个属性至少要连接到某一个实体。 并且,根据集合理论,每个属性在实体中 必须唯一。
每一条收集到的某一个实体的数据, 称为该实体的实例 Entity Instance。 实体的实例可以看成是数据表中的行。
实体中最重要的属性在每个实例都拥有 唯一的值 正式名称叫做唯一属性 Unique Attribute。 也有的时候称之为唯一键或者唯一标识符。是每一行数据具有不同唯一值的列, 每个实体必须至少有一个属性作为唯一键或 标识符。用加下划线表示。
可以被其他属性组合重新创建的属性用 ( ) 修饰 Composite Attribute。
Partial Key == 虚线 == 修饰这个属性无法identify它从属的entity。必须结合其他属性才能完成identify
- 实体之间的关系(菱形)
每个实体或 类别必须与数据库中的至少一个其他实体相关。 您使用菱形和线条来表述这些关系。 菱形里填写关系的本质

接近矩形的符号表示实例的最大数目 这个数是实体可以和其他实体 相关联的实例的最大数字 与矩形距离较远的符号则表示 实体A中可以与实体B关联的最小的实例数目。
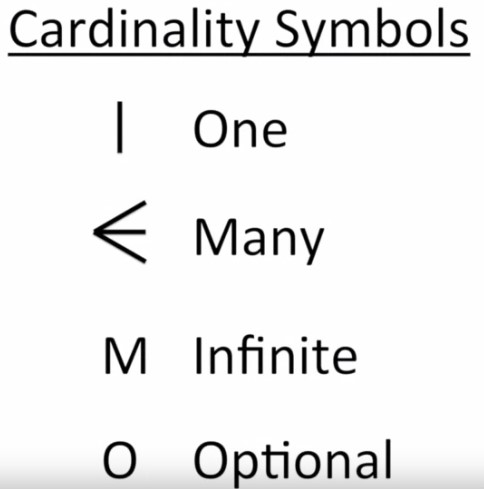
Relational Schemas


Components of Relational Schema:
- Table
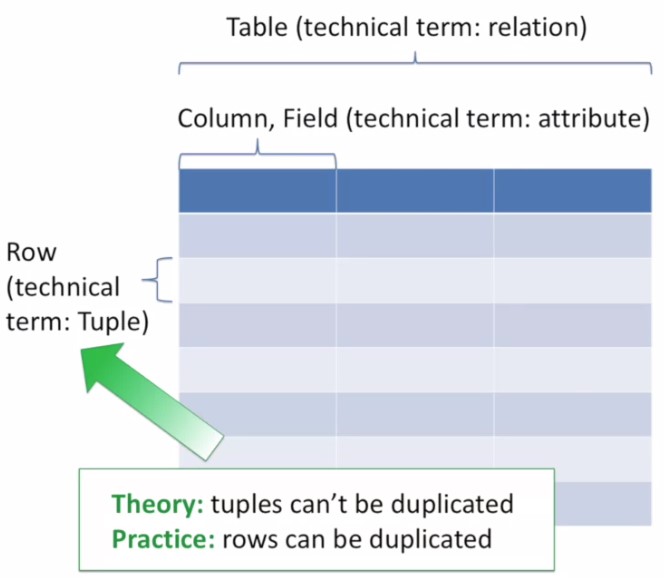
row and column without order.
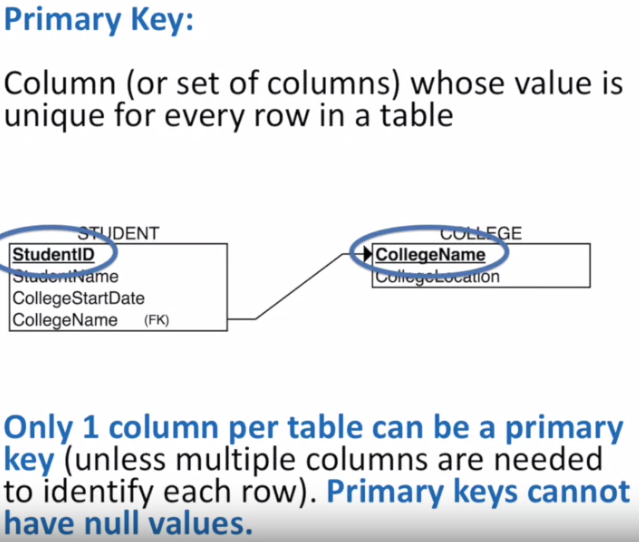
- Primary key
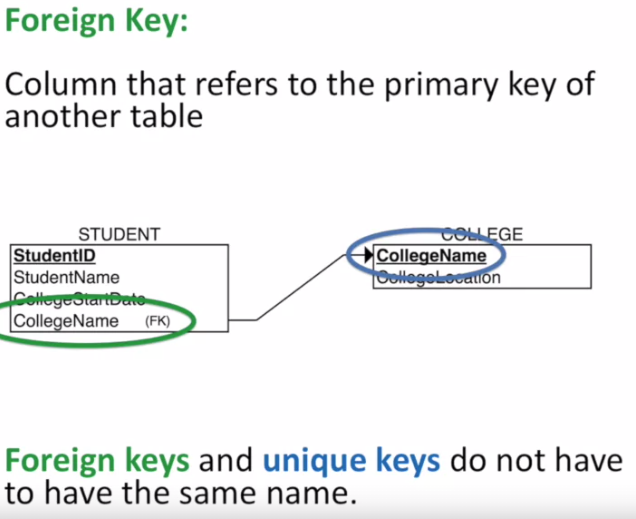
- Foreign key
Link table to another table.
Week 2
Query Syntax
DQL: Data Query Language 数据查询语言
SELECT 查询数据库讯息
跟在SELECT后面的子句,包含你想要的数据和数据库的细节 细节包括你想要的具体数据以及它的格式。这些细节由6个SQL关键字按特定顺序来指定 按顺序,这些关键字是:
SELECT (required), FROM (required), WHERE, GROUP, HAVING, ORDER ;
去描述你想要什么数据

SUM(database.sales)
"."句点表示数据库中的具体细节。句点出现在数据库名和表名之间 或者表名和列名之间 告诉数据库你到底需要哪个表或列
NULL 没有数据
Exercise 1: Look at data (SHOW & SELECT)
SHOW
- SHOW tables:db中有多少个表 – 返回所有名字
- SHOW columns FROM (enter table name here);
SHOW columns FROM (enter table name here) FROM (enter database name here);
SHOW columns FROM databasename.tablename :展示表内容。DESCRIBE 表名称有同样的效果
SELECT
用来取得数据,需要提供两个信息:
- 什么数据
- 从哪里取
SELECT breed FROM dogs;
LIMIT: 显示前5行
SELECT breed FROM dogs LIMIT 5;
OFFSET LIMIT: 10 rows of data will be returned, starting at Row 6.
SELECT breed
FROM dogs LIMIT 10 OFFSET 5;
or
FROM dogs LIMIT 5, 10;
显示多列
SELECT breed, breed_type, breed_group FROM dogs LIMIT 5, 10;
取所有数据
SELECT * FROM reviews LIMIT 5, 10;
显示运算过的结果:make new derivations of individual columns using “+” for addition, “-” for subtraction, “*” for multiplication, or “/” for division
SELECT median_iti_minutes / 60
FROM dogs LIMIT 5, 10;
Exercise 2: Select specific data (WHERE)
选取所有free_start_user = 1的users
SELECT user_guid FROM users WHERE free_start_user=1;
选取所有weight在10-50之间的dogs
SELECT dog_guid, weight FROM dogs WHERE weight BETWEEN 10 AND 50;
# OR AND
WHERE dog_fixed=1 OR dna_tested=1;
WHERE dog_fixed=1 AND dna_tested!=1;
IN
SELECT dog_guid, breed FROM dogs WHERE breed IN ("golden retriever","poodle");
LIKE
SELECT dog_guid, breed FROM dogs WHERE breed LIKE ("s%");
s%: bread must start with “s”, can have any number of letter after
%s: bread must end with “s”, can have any number of letter before
%s%: bread contain an “s” somewhere in its name, can have any number of letter after and before
Time-related data
DATE format YYYY-MM-DD
DATETIME format: YYYY-MM-DD HH:MI:SS
TIMESTAMP format: YYYY-MM-DD HH:MI:SS 2013-02-07 02:50:52
YEAR format YYYY or YY
DAYNAME
返回time stamp对应的星期几
SELECT dog_guid, created_at FROM complete_tests WHERE DAYNAME(created_at)="Tuesday"
DAY
返回对应每个月的几号
SELECT dog_guid, created_at FROM complete_tests WHERE DAY(created_at) > 15 # 每个月15号以后的
比较具体日期
SELECT dog_guid, created_at FROM complete_tests WHERE created_at > '2014-02-04'
TIMEDIFF: 两个time stamp之间的时间间隔
DATEDIFF: 两个日期查了多少天
IS NULL & IS NOT NULL
返回所有某个field值NULL(NOT NULL)的所有行
SELECT user_guid FROM users WHERE free_start_user IS NULL;
Select the Dog ID, test name, and subcategory associated with each completed test for the first 100 tests entered in October, 2014
%sql SELECT dog_guid, test_name, subcategory_name FROM complete_tests WHERE YEAR(created_at) = 2014 AND MONTH(created_at) = 10 LIMIT 100;
Exercise 3: Formatting Selected Data
AS
Use AS to change the titles of the columns in your output
SELECT start_time AS "exam start time" FROM exam_answers
输出值的名字就变成了AS的指定值
DISTINCT
Use DISTINCT to remove duplicate rows 使输出值没有重复(将会包括一次NULL(如果有NULL))
SELECT DISTINCT breed FROM dogs;
When the DISTINCT clause is used with multiple columns in a SELECT statement, the combination of all the columns together is used to determine the uniqueness of a row in a result set. 多行组合决定是否唯一
SELECT DISTINCT state, city FROM users;
ORDER BY
Use ORDER BY to sort the output of your query
ORDER BY clause will come after everything else in the main part of your query, but before a LIMIT clause.
SELECT DISTINCT breed FROM dogs ORDER BY breed;
SELECT DISTINCT breed FROM dogs ORDER BY breed DESC
和LIMIT组合使用用来求Top 10 or Last 10
SELECT DISTINCT user_guid, median_ITI_minutes FROM dogs ORDER BY median_ITI_minutes LIMIT 5
# 最少的五个
利用AS进行新的排序
SELECT DISTINCT user_guid, (median_ITI_minutes * 60) AS median_ITI_sec
FROM dogs
ORDER BY median_ITI_sec DESC
LIMIT 5
多行组合排序
SELECT DISTINCT user_guid, state, membership_type
FROM users
WHERE country="US"
ORDER BY state ASC, membership_type ASC
每个排序标准用“,”隔开。前排序第一个再排序第二个…
Export your query results to a text file
- 将query结果放入一个变量储存
variable_name_of_your_choice = %sql [your full query goes here];
breed_list = %sql SELECT DISTINCT breed FROM dogs ORDER BY breed;
- 变量储存为.csv文件
the_output_name_you_want.csv('the_output_name_you_want.csv')
breed_list.csv('breed_list.csv')
- 清理文件
REPLACE(str,from_str,to_str)
Returns the string str with all occurrences of the string from_str replaced by the string to_str. REPLACE() performs a case-sensitive match when searching for from_str.
用to_str 取代 from_str
SELECT DISTINCT breed, REPLACE(breed,'-','') AS breed_fixed
FROM dogs ORDER BY breed_fixed
# 将单词之间的“-”换成空格
但是会将除开头“-”以外的连字符同样删除
TRIM
SELECT DISTINCT breed, TRIM(LEADING '-' FROM breed) AS breed_fixed
# 只删除开头的“-”
FROM dogs ORDER BY breed_fixed;
Viewpoint interface for Teradata Queries
TERADATA SYSTEM ACCESS
Your Teradata login is: DUKESQLMOOC33863 Your
Teradata password is: ZE73cgt$ Your login and password will expire on
July 18, 2021
MySQl Code
求各科目平均分大于60的学生学号和平均成绩
https://blog.csdn.net/qq_43824618/article/details/104630693
https://www.cnblogs.com/sea-stream/p/11305668.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









