







Bag-of-Words vs. Graph vs. Sequence in Text Classification: Questioning
the Necessity of Text-Graphs and the Surprising Strength of a Wide MLP
标题有点标题党了,就是有关ACL2022一篇论文的一些笔记,按自己的理解写的,比较粗糙,细节建议阅读原文,有错误欢迎指出。
Bag-of-Words?Graph?Sequence
文章将当前主流Text Classification领域的模型分为三类,即Bag-of-Words,Graph,Sequence
BoW-based models
Bag-of-Words也就是词袋模型,BoW-based models就是基于BoW做词向量编码的模型,文章中给的定义是:
These models count the occurrence of all tokens in the input sequence, while disregarding word position and order, and then rely on word embeddings and fully connected feedforward layer(s).
翻译一下,BoW将输入的一个序列(或者说一句话)中各个词按出现次数进行向量化编码,但是不考虑单词顺序与位置,模型对语义的学习完全依赖于word embedding和FC层。
BoW
这篇文章的例子还挺合适的,这里搬运一下:
“John likes to watch movies, Mary likes movies too”
“John also likes to watch football games”
两个句子组成的词表为
[‘also’, ‘football’, ‘games’, ‘john’, ‘likes’, ‘mary’, ‘movies’, ‘to’, ‘too’, ‘watch’]
因此,他们通过BoW方式进行的向量表示为

Graph-based models
2019年 TextGCN首次将GNN运用于文本分类领域,取得了当时来看很好的性能,此后也有许多GNN在文本分类领域应用的变体。文章将此类模型成为Graph-based models(很直白)。
需要注意的是TextGCN需要根据词表(vocabulary)与语料库(corpus)建图,空间复杂度O(N^2),N是词表与语料库的size之和。
Sequence-based models
文章将各种Transformer-based(比如各种Bert)和LSTM-based模型都归为Sequence-based models,因为都是这些模型按照序列方式进行特征学习的。
其中Bert一类Transfomer-based model的运算开销为O(L^2),L是输入序列的长度(主要还是由于Attention引入的,也有不少将Attention复杂度降低的方法,这里先不展开说了)
可以看出BoW-based models是最简单的,只需要简单的BoW编码然后用MLP Train就行了。
实验部分
目的
这篇文章就是假设BoW-based models也可以跟其他两类方法一样有效(主打的就是一个反直觉实验),然后稍微质疑了一下一些Graph-based model。进行了一系列实验来验证。实验用不同的随机初始化参数重复了5次,取Accuracy的平均值与标准差。
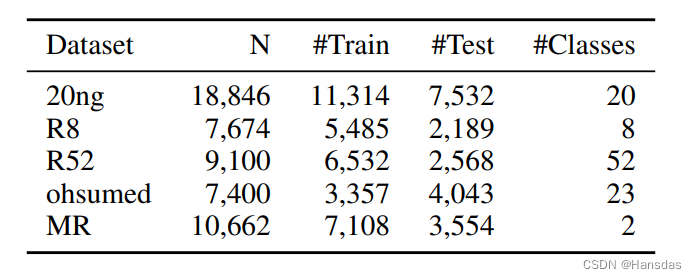
数据集
数据集包括20ng, R8, R52, ohsumed, and MR,数据集特征信息如下图
对比模型
文章比较了16种方法:
- 8种 BoW-based models :fast text之类的经典方法。此外,这里文章还一个WideMLP进行实验,也就是一个很宽(文中说是1024个神经元)且只有一个隐藏层的MLP,跟几种向量化表达方法组合:
- BoW 前面说过了,这里不多说了;
- TF-IDF加权,考虑词频和逆文本频率加权来强调句中各个单词的重要程度,单纯的BoW单纯靠词频可能会搞错一句话的重点;
- GloVe:简单理解成考虑到语料库全局、局部特征的Vector Representation。
- 3种 Sequence-based models:Bert一类的方法也是用fine-tuning的方式比较
- 5种 Graph-based models
Inductive Setup & Transductive Setup
- Inductive Setup:test数据在训练前的预处理阶段是作为可见数据处理的,这显然是不合适的(基本上跑分冲榜Test数据甚至valid,跟Train数据都是要分开的,在Test之前使用了Test数据就像是作弊了),但也是TextGCN中使用的方法,因此文章对这块有讨论实验(攻击性有点强了)
- Transductive Setup:test数据直到测试阶段之前都是不可见的。这也是BoW-based 和 sequence-based models的setup(也是大部分ML Model的Setup)
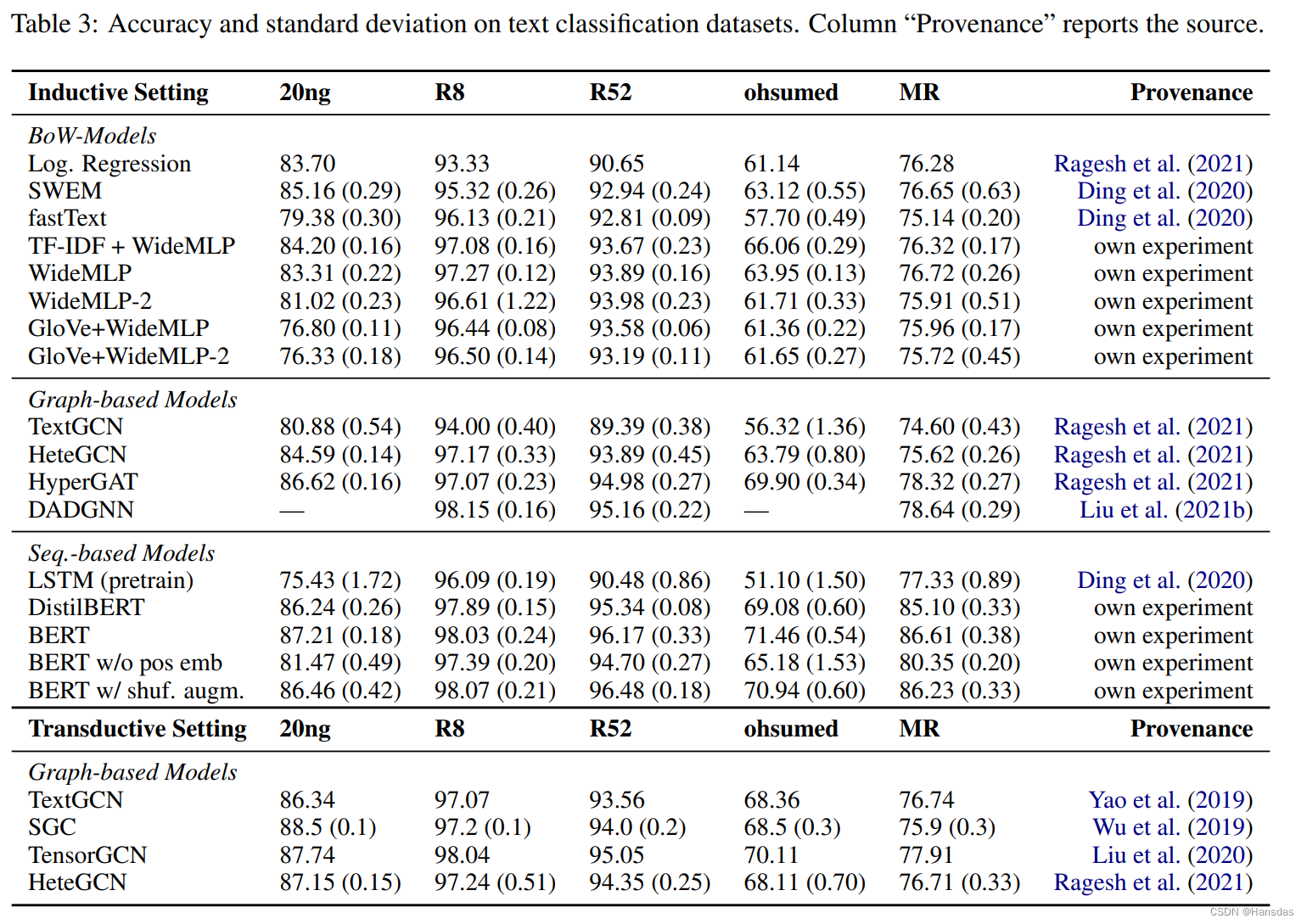
实现结果
性能(Accuracy + 标准差)
-
Inductive Setting(Test数据不可见)下跟Transductive Setting(Test数据可见)下的Graph-based Models,显然Inductive Setting下,即preprocessing中不能使用Test数据时,Graph-based模型性能有很大的下降(特别是TextGCN),甚至有时不如BoW-Models的一些相对simple方法;
-
BoW-based Models中,WideMLP还是取得最好的性能(WideMLP就是层数更多的WideMLP);
- 并且实验结果中看出 GloVe这种pretrained的embedding对于MLP有明显不利的影响。文章引用了一个经典文章来解释:
A possible explanation is that already a single hidden layer is sufficient to approximate any compact function to an arbitrary degree of accuracy depending on the width of the hidden layer
可能因为单个隐藏层已经足以以任意精度逼近任何紧致函数,这取决于隐藏层的宽度 -
一些Bert总体表现还是比较好的,文章对于positional embedding还做了ablation,加之WideMLP+TF-IDF/GloVe的对比说明位置信息、词频的重要性
参数量与耗时
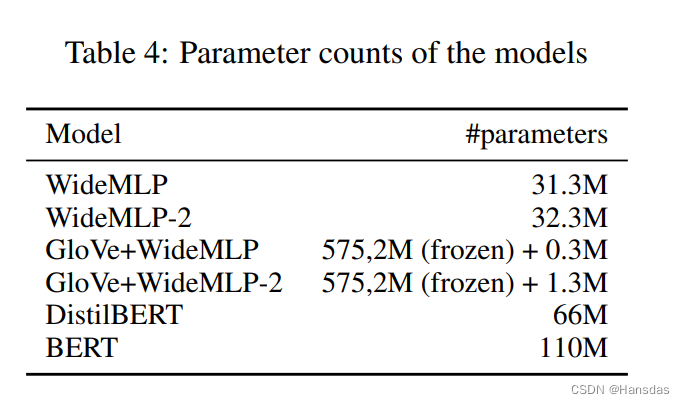
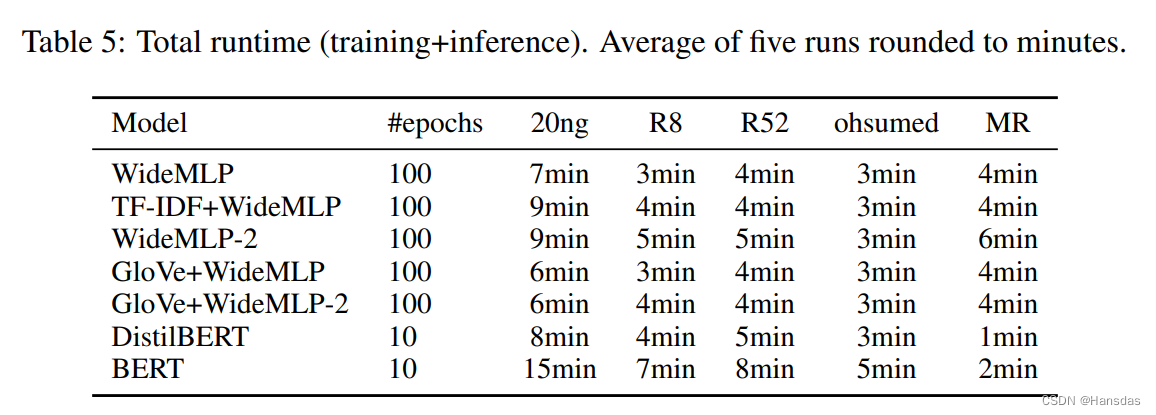
可以看出:
- 除了MR数据集,MLP只需要一小部分参数,并且在训练和推理的组合时间上更快。文章还提到,随着Batch的增加,MLP的速度可以进一步提高
- Transformer-based的方法由于Attention O(L^2)的运算复杂度,在长序列数据运算时会更慢
- Graph-based models不仅需要计算Graph,还需要训练GNN,而标准的GNN中,所建的图是需要占用GPU显存的,前面提到图的空间复杂度很高,这就意味着需要占用大量的显存,这会导致我们用GPU训练时batch size受限,导致训练效率较低
结论
基本上实验能证明前面文章的假设,即一个wide MLP也可以作为一个性能较好的文本分类BaseLine,并且要优于一些由文本合成graph的模型(同等的inductive setting下)。















 8341
8341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









