







select 语句的语法格式如下:
select 字段列表
from 数据源
[where 条件表达式]
[group by 分组字段[ having 条件表达式]]
[order by 排序字段 [asc|desc]]
- 字段列表用于指定检索字段;
- from子句用于指定检索的数据源;
- where子句用于指定记录的过滤条件;
- group by子句用于对检索的数据进行分组;
- having子句通常和group by子句一起使用,用于过滤分组后的统计信息;
- order by子句用于对检索的数据进行排序处理,默认为升序asc。
执行顺序:from → \rightarrow →on → \rightarrow →outer join → \rightarrow →where → \rightarrow →group by → \rightarrow →cute|rollup → \rightarrow →having → \rightarrow →select → \rightarrow →distinct → \rightarrow →order by → \rightarrow →top
select字段列表
*:字段列表为数据源的全部字段;表名.*:多表查询时,指定某个表的全部字段;- 字段列表可以指定为需要显示的若干个字段:
- 可以包含字段名、表达式,字段名之间使用逗号分隔,顺序可以根据需要任意指定;
- 可以为字段列表中的字段名或表达式指定别名,中间使用
as关键字分隔(as可省略)。
示例:
select version() as 版本号,now() 服务器当前时间,pi(),1+2,null=null,null is null
谓词distinct、limit
1. distinct过滤select结果集中的重复记录
语法格式:
distinct 字段名
示例:
select distinct department_name from classes;
2. limit查询某几行记录
limit语法格式:
select 字段列表
from 数据源
limit [start,]length;
- start表示从第几行记录开始(第一行start为0),length表示检索多少行记录。
limit+offset语法格式:
select 字段列表
from 数据源
limit length offset start;
示例:
select * from table limit 2,1;
//跳过2条取出1条数据,limit后面是从第2条开始读,读取1条信息,即读取第3条数据
select * from table limit 2 offset 1;
//从第1条(不包括)数据开始取出2条数据,limit后面跟的是2条数据,offset后面是从第1条开始读取,即读取第2,3条
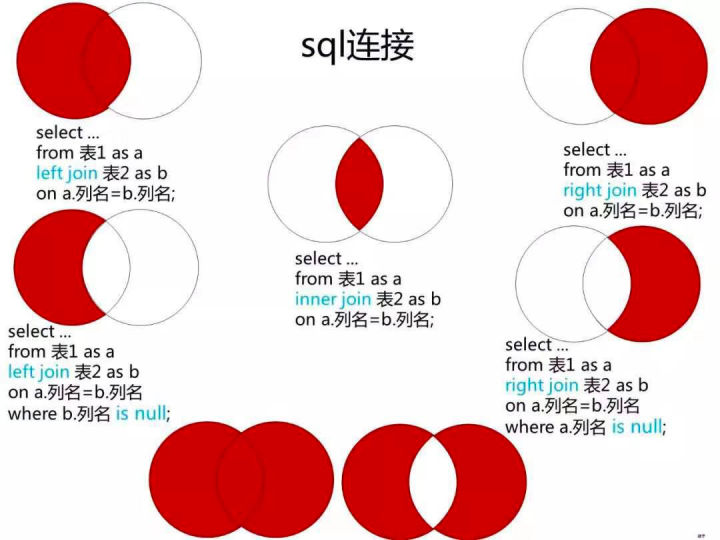
from指定多个数据源—表连接
指定多张数据库表的连接条件的方法:
- where子句中指定;
- from子句中使用join运算。
from子句的语法格式:
from 表名1 [连接类型] join 表名2 on 表1和表2之间的连接条件
内连接inner
内连接将两个表中满足指定连接条件的记录连接成新的结果集,并舍弃所有不满足连接条件的记录。语法格式:
from 表名1 [连接类型] join 表名2 on 表1和表2之间的连接条件
示例:检索分配有班级的学生(学生表和班级表都有)
select student_no,student_name,student_contact,student.class_no,class_name,department_name
from student join classes on student.class_no=classes.class_no
外连接
只过滤一个表,对另一个表的记录不过滤。
left左外连接
查询结果集中包含表1的全部记录,按指定的条件与表2连接,表2中不存在满足连接条件的记录,则结果集中表2相应字段为null。
from 表名1 left join 表名2 on 表1和表2之间的连接条件
示例:检索所有学生对应的班级信息。
select student_no,student_name,student_contact,student.class_no,class_name,department_name
from student left join classes on student.class_no=classes.class_no
right右外连接
查询结果集中包含表2的全部记录,按指定的条件与表1连接,表1中不存在满足连接条件的记录,则结果集中表1相应字段为null。
from 表名1 right join 表名2 on 表1和表2之间的连接条件
示例:检索所有班级的学生信息。
select student_no,student_name,student_contact,student.class_no,class_name,department_name
from student right join classes on student.class_no=classes.class_no
full完全外连接
两个表的所有记录都会出现在结果集中,MySQL中暂不支持完全连接(2014.06)。
多表连接
from 表名1 [连接类型] join 表名2 on 表1和表2之间的连接条件
[连接类型] join 表3 on 表2和表3之间的连接条件
where子句过滤结果集
where 条件表达式
条件表达式是一个布尔表达式,满足布尔表达式为真的记录将被包含在结果集中。
1. 使用单一的条件过滤结果集
表达式1 比较运算符 表达式2
- 表达式1、表达式2可以是一个字段名、常量、变量、函数,甚至是子查询。
- 比较运算符:
=(等于)、>(大于)、>=(大于等于)、<(小于)、<=(小于等于)、<>(不等于)、!=(不等于)、!<(不小于)、!>(不大于)
2. is NULL运算符
表达式 is[ not] NULL
- 判断表达式的值是否为空置NULL。
- NULL是一个不确定的数,不能使用比较运算符与NULL进行比较。(NULL=NULL的结果为NULL)
3. 使用逻辑运算符
使用逻辑运算符可以将多个查询条件组合起来。
非(!)
!布尔表达式
- 单目运算符
- 与布尔表达式的值相反
与(and)
布尔表达式1 and 布尔表达式2
- 当连个布尔表达式的值均为true时,整个逻辑表达式的值才为true
between…and…
表达式 [not ]between 起始值 and 终止值
- 用于判断一个表达式的值是否位于指定的取值范围内(包含起始值和终止值)
或(or)
布尔表达式1 or 布尔表达式2
- 当连个布尔表达式的值均为false时,整个逻辑表达式的值才为false
substring()
substring(源字符串,子串起始位置,子串长度)
- 字符串函数,返回一个源字符串的子串
in运算符
表达式 [not] in (数学集合)
- 用于判断一个表达式的值是否位于一个离散的数学集合内
- 数学集合:一些离散的数值型的数,若干个字符串,一个select语句的查询结果集
使用like进行模糊查询
字符串表达式 [not] like 模式
- 用于判断一个字符串是否与给定的模式相匹配。
- 字符序设置为gbk_chinese_ci/gb2312_chinese_ci,模式匹配时英文字母不区分大小写;字符序设置为gbk_bin/gb2312_bin,模式匹配时英文字母区分大小写。
- 模式是一种特殊的字符串,包含普通字符串和通配符。
| 通配符 | 功能 |
|---|---|
| % | 匹配零个或多个字符组成的任意字符串 |
| _ | 匹配任意一个字符 |
转义字符‘\’
使用escape关键字自定义一个转义字符:
select * from new_student where student_name like '%!_%' escape '!';
使用order by子句对结果集排序
order by 字段名1 [asc|desc] [...,字段名n [asc|desc]]
- 使结果集中的记录按照一个或多个字段的值进行排序
- 默认排序方式为升序asc
- MySQL总是将NULL当做最小值处理
使用group by子句对记录分组统计
group by 字段列表[ having 条件表达式] [with rollup]
- 将查询结果按照某个字段(或多个字段)进行分组(字段值相同的记录作为一个分组),通常与聚合函数一起使用。
- 单独使用group by子句对记录进行分组时,仅仅显示分组中的某一条记录(字段值相同的记录作为一个分组)。
group by子句与聚合函数
聚合函数用于对一组值进行计算并返回一个汇总值。
count()
- 用于统计结果集中记录的行数;
- 统计时忽略NULL值。
示例:
select count(choose_no) 参加考试的人数, count(choose_no)-count(score) 缺考学生人数, (count(choose_no)-count(score))/count(choose_no)*100 缺考百分比
from choose where couse_no=1
sum()
- 对数值型字段的值累加求和;
- 统计时忽略NULL值。
avg()
- 对数值型字段的值求平均值;
- 统计时忽略NULL值。
min()、max()
- 用于统计数值型字段值的最大值与最小值;
- 统计时忽略NULL值。
group by子句通常与聚合函数一起使用:使用聚合函数可以对每个组内的数据进行信息统计。示例:
- 统计每个班的学生人数
select class_name,count(student_no)
from classes left join student on studengt.class_no=classes.class_no
group by classes.class_no;
- 统计每个学生已经选修多少门课程,以及该生的最高分、最低分、总分及平均成绩,
select student.student_no,student_name,count(course_no),max(score),min(score),sum(score),avg(score)
from student left join choose on student.student_no=choose.student_no
group by student.student_no;
group by子句与having子句
having 条件表达式
- having子句用于设置分组或聚合函数的过滤筛选条件,通常与group by子句一起使用,从分组的结果中再进行筛选。
- 条件表达式是一个逻辑表达式,用于指定分组后的筛选条件。
group by子句与group_concat()函数
group_concat()函数的功能:
- 将集合中的字符串连接起来,此时与字符串连接函数contact()函数的功能类似。
- 按照分组字段,将另一个字段的值(NULL值除外)使用逗号连接起来。示例:
select class_name 班级名,group_concat(studengt_name) 学生名单,contact(student_name) 部分名单
from classes left join student on student.class_no=classes.class_no
group by classes.class_no;
查询结果:
±---------------------±---------------±------------+
| 班级名
\qquad\quad
| 学生名单
\quad
|部分名单|
±---------------------±----------------±-----------+
| 2012自动化1班 | 张三,李四 |张三
\quad
|
| 2012自动化2班 | 马六,田七 |马六
\quad
|
| 2012自动化3班 | 王五
\qquad
|王五
\quad
|
| 2012自动化4班 | NULL
\qquad
|NULL
\quad
|
±---------------------±----------------±------------+
group by子句与with rollup选项
- 有时对各个组进行汇总运算时,需要在分组后加入一条汇总记录,可通过with rollup选项实现。
示例:统计每个班的学生人数,并在查询结果集的最后一条记录后附上所有班级的总人数。
select classes.class_no,count(student_no)
from classes left join student on student.class_no=classes.class_no
group by classes.class_no with rollup;
union合并结果集
select 字段列表1 from table1
union [all]
select 字段列表2 from table2
- 将多个select语句的查询结果集组合成一个结果集;
- 字段列表1与字段列表2的字段个数,且具有相同的数据类型;
- 多个结果集合并后会产生一个新的结果集,该结果集中的字段名与字段列表1中的字段名对应;
- union与union all区别:
- 使用union时,MySQL会筛选掉select结果集中重复的记录,结果集合并后会对新产生的结果集进行排序运算,效率稍低;
- 使用unoin all时,MySQL会直接合并两个结果集,效率高于union。
子查询
如果一个select语句能够返回单个值或一列值,且该select语句嵌套咋另一个SQL语句中,那么称该select语句为“子查询”(内层查询),包含子查询的SQL语句称为“主查询”(外层查询)。
- 子查询一般用在主查询的where子句或having子句中,与比较运算符或逻辑云算符一起构成where筛选条件或having筛选条件;
- 子查询分为相关子查询和非相关子查询:
- 非相关子查询:子查询中仅使用了自己定义的数据源。非相关子查询独立于主查询,子查询总共执行一次,执行完毕后将值传递给主查询;
- 相关子查询:子查询中使用了主查询的数据源。主查询的执行与相关子查询的执行相互依赖。
子查询与比较运算符
如果子查询返回单个值,则可以将一个表达式的值与子查询的结果集进行比较。
子查询与in运算符
用于将一个表达式的值与子查询返回的一列值进行比较,如果表达式的值是此列中的任何一个值,则条件表达式的结果为true,否则为false。
示例:检索没有申请选修课的教师的信息
select * from teacher where teacher_no
not in (
select teacher.teacher_no from course where course.teacher_no=teacher.teacher_no
);
子查询与exists逻辑运算符
用于检测子查询的结果集是否包含记录。如果结果集中至少包含一条记录,则返回true,否则为false。在exists前面加上not时,与上述结果恰恰相反。
示例:检索没有申请选修课的教师的信息
select * from teacher
where not exists (
select * from course where course.teacher_no=teacher_no
);
子查询与any运算符
表达式 比较运算符 any(子查询)
- 通过比较运算符将表达式的值与子查询中的一列值逐一进行比较,若某次的比较结果为true,则整个表达式的值为true,否则为false。
子查询与all运算符
表达式 比较运算符 all(子查询)
- 通过比较运算符将表达式的值与子查询中的一列值逐一进行比较,若每次的比较结果为true,则整个表达式的值为true,否则为false。
题目实例
组合两个表
无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息:FirstName, LastName, City, State。
- 表连接
select FirstName, LastName, City, State
from Person left join Address
on Person.PersonId = Address.PersonId
;
第二高的薪水
如果不存在第二高的薪水,那么查询应返回 null。
- order by与limit
SELECT
(SELECT DISTINCT
Salary
FROM
Employee
ORDER BY Salary DESC
LIMIT 1 OFFSET 1) AS SecondHighestSalary
;
超过经理收入的员工
- where指定连接条件
SELECT
a.Name AS 'Employee'
FROM
Employee AS a,
Employee AS b
WHERE
a.ManagerId = b.Id
AND a.Salary > b.Salary
;
- join指定连接条件
SELECT
a.NAME AS Employee
FROM Employee AS a JOIN Employee AS b
ON a.ManagerId = b.Id
AND a.Salary > b.Salary
;
查找重复的电子邮箱
- 使用group by和临时表
select Email from
(
select Email, count(Email) as num
from Person
group by Email
) as statistic
where num > 1
;
- 使用group by和having子句
select Email
from Person
group by Email
having count(Email) > 1;
从不订购的客户
- 子查询与in运算符
select customers.name as 'Customers'
from customers
where customers.id not in
(
select customerid from orders
);
上升的温度
- 查找与之前(昨天的)日期相比温度更高的所有日期的 Id。
SELECT
weather.id AS 'Id'
FROM
weather
JOIN
weather w ON DATEDIFF(weather.RecordDate, w.RecordDate) = 1
AND weather.Temperature > w.Temperature
;
超过5名学生的课
- group by与子查询
SELECT
class
FROM
(SELECT
class, COUNT(DISTINCT student) AS num
FROM
courses
GROUP BY class) AS temp_table
WHERE
num >= 5
;
- group by 与having子句
SELECT
class
FROM
courses
GROUP BY class
HAVING COUNT(DISTINCT student) >= 5
;
大的国家
- where子句与or
SELECT
name, population, area
FROM
world
WHERE
area > 3000000 OR population > 25000000
;
- where子句与union(速度更快)
SELECT
name, population, area
FROM
world
WHERE
area > 3000000
UNION
SELECT
name, population, area
FROM
world
WHERE
population > 25000000
;
有趣的电影
- mod取余
select *
from cinema
where mod(id, 2) = 1 and description != 'boring'
order by rating DESC
;
- %取余
select *
from cinema
where description!='boring' and id%2=1
order by rating desc;
重新格式化部门表
- if
SELECT
id,
MIN(IF(`month` = 'Jan', revenue, NULL)) AS Jan_Revenue,
MIN(IF(`month` = 'Feb', revenue, NULL)) AS Feb_Revenue,
MIN(IF(`month` = 'Mar', revenue, NULL)) AS Mar_Revenue,
MIN(IF(`month` = 'Apr', revenue, NULL)) AS Apr_Revenue,
MIN(IF(`month` = 'May', revenue, NULL)) AS May_Revenue,
MIN(IF(`month` = 'Jun', revenue, NULL)) AS Jun_Revenue,
MIN(IF(`month` = 'Jul', revenue, NULL)) AS Jul_Revenue,
MIN(IF(`month` = 'Aug', revenue, NULL)) AS Aug_Revenue,
MIN(IF(`month` = 'Sep', revenue, NULL)) AS Sep_Revenue,
MIN(IF(`month` = 'Oct', revenue, NULL)) AS Oct_Revenue,
MIN(IF(`month` = 'Nov', revenue, NULL)) AS Nov_Revenue,
MIN(IF(`month` = 'Dec', revenue, NULL)) AS Dec_Revenue
FROM
Department
GROUP BY id;
- case…when
SELECT id,
SUM(CASE WHEN month='Jan' THEN revenue END) AS Jan_Revenue,
SUM(CASE WHEN month='Feb' THEN revenue END) AS Feb_Revenue,
SUM(CASE WHEN month='Mar' THEN revenue END) AS Mar_Revenue,
SUM(CASE WHEN month='Apr' THEN revenue END) AS Apr_Revenue,
SUM(CASE WHEN month='May' THEN revenue END) AS May_Revenue,
SUM(CASE WHEN month='Jun' THEN revenue END) AS Jun_Revenue,
SUM(CASE WHEN month='Jul' THEN revenue END) AS Jul_Revenue,
SUM(CASE WHEN month='Aug' THEN revenue END) AS Aug_Revenue,
SUM(CASE WHEN month='Sep' THEN revenue END) AS Sep_Revenue,
SUM(CASE WHEN month='Oct' THEN revenue END) AS Oct_Revenue,
SUM(CASE WHEN month='Nov' THEN revenue END) AS Nov_Revenue,
SUM(CASE WHEN month='Dec' THEN revenue END) AS Dec_Revenue
FROM department
GROUP BY id
ORDER BY id;
分数排名
如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
select a.Score as Score,
(select count(distinct b.Score) from Scores b where b.Score >= a.Score) as 'Rank'
from Scores a
order by a.Score DESC;
select score,
dense_rank() over(order by Score desc) as 'Rank'
from Scores;
窗口函数rank, dense_rank, row_number的区别:
select *,
rank() over (order by 成绩 desc) as ranking,
dense_rank() over (order by 成绩 desc) as dese_rank,
row_number() over (order by 成绩 desc) as row_num
from 班级

部门工资最高的员工
找出每个部门工资最高的员工。
SELECT
Department.name AS 'Department',
Employee.name AS 'Employee',
Salary
FROM
Employee
JOIN
Department ON Employee.DepartmentId = Department.Id
WHERE
(Employee.DepartmentId , Salary) IN
( SELECT
DepartmentId, MAX(Salary)
FROM
Employee
GROUP BY DepartmentId
)
;
部门工资前三高的所有员工
SELECT
d.Name AS 'Department', e1.Name AS 'Employee', e1.Salary
FROM
Employee e1
JOIN
Department d ON e1.DepartmentId = d.Id
WHERE
3 > (SELECT
COUNT(DISTINCT e2.Salary)
FROM
Employee e2
WHERE
e2.Salary > e1.Salary
AND e1.DepartmentId = e2.DepartmentId
)
;
连续出现的数字
查找所有至少连续出现三次的数字。
SELECT DISTINCT
l1.Num AS ConsecutiveNums
FROM
Logs l1,
Logs l2,
Logs l3
WHERE
l1.Id = l2.Id - 1
AND l2.Id = l3.Id - 1
AND l1.Num = l2.Num
AND l2.Num = l3.Num
;
体育馆的人流量
X 市建了一个新的体育馆,每日人流量信息被记录在这三列信息中:序号 (id)、日期 (visit_date)、 人流量 (people)。
请编写一个查询语句,找出人流量的高峰期。高峰期时,至少连续三行记录中的人流量不少于100。
SELECT distinct a.*
FROM stadium as a,stadium as b,stadium as c
where ((a.id = b.id-1 and b.id+1 = c.id) or
(a.id-1 = b.id and a.id+1 = c.id) or
(a.id-1 = c.id and c.id-1 = b.id))
and (a.people>=100 and b.people>=100 and c.people>=100)
order by a.id;
行程和用户
查出 2013年10月1日 至 2013年10月3日 期间非禁止用户的取消率。
取消率的计算方式如下:(被司机或乘客取消的非禁止用户生成的订单数量) / (非禁止用户生成的订单总数)。
SELECT
request_at as 'Day', round(avg(Status!='completed'), 2) as 'Cancellation Rate'
FROM
trips t JOIN users u1 ON (t.client_id = u1.users_id AND u1.banned = 'No')
JOIN users u2 ON (t.driver_id = u2.users_id AND u2.banned = 'No')
WHERE
request_at BETWEEN '2013-10-01' AND '2013-10-03'
GROUP BY
request_at
- MySQL中,round函数用于数据的四舍五入:round(x,d) ,x指要处理的数,d是指保留几位小数,默认d为0。
《MySQL数据库基础与实例教程》——孔祥盛















 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









