






在重看GIoU的motivation时,我有这样一句话:
当GT框与预测框不重叠时,框无论向哪个方向移动IoU始终是0,无法优化
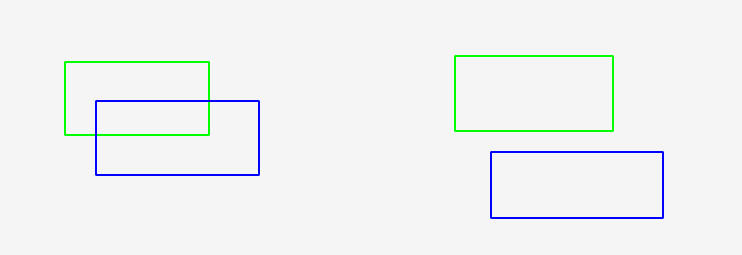
也就是如下的这个操作,左图有重叠,IoU大于0,右图无重叠,IoU始终为0
无法优化,意思是梯度为0吧,所以梯度based优化方法都无法使用,我在计算IoU的过程中哪个部分会导致loss为0呢?
仅仅是因为IoU始终为0而导致IoU的梯度就为0了吗?
(这是显然的,无论Box向哪个方向进行微小移动,IoU都是定值0,也就是在该邻域中始终为定值,显然梯度为0)
但是在代码层面,这个无法优化的部分是由哪个组件产生的呢?
先说结论,是clip 操作导致的,clip之后相当于可学习参数被一个常数替代,故而无法求导,下边儿做个实验看看IoU为0时,其梯度为0的对比实验
1. 代码实验一
先放一个计算IoU的函数,如果不是做检测的,无需关注具体实现,只要知道中间有一步clip操作即可
import torch
def box_area(boxes: torch.Tensor) -> torch.Tensor:
"""
Computes the area of a set of bounding boxes, which are specified by their
(x1, y1, x2, y2) coordinates.
Args:
boxes (Tensor[N, 4]): boxes for which the area will be computed. They
are expected to be in (x1, y1, x2, y2) format with
``0 <= x1 < x2`` and ``0 <= y1 < y2``.
Returns:
Tensor[N]: the area for each box
"""
# boxes = _upcast(boxes)
return (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
def box_iou(boxes1, boxes2):
area1 = box_area(boxes1)
area2 = box_area(boxes2)
lt = torch.maximum(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
rb = torch.minimum(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
wh = (rb - lt).clip(min=0) # [N,M,2]
inter = wh[:, :, 0] * wh[:, :, 1] # [N,M]
union = area1[:, None] + area2 - inter
iou = inter / union
return iou, union
# 此处的预测框是可学习参数
pred_box = torch.tensor([0.3, 0.3, 0.6, 0.6])[None]
pred_box.requires_grad = True
# 这是GT值
GT_box = torch.tensor([0.0, 0.0, 1.0, 1.0])[None]
# 学习率,每次朝着负梯度方向移动 0.001 的比例
lr = 0.001
for _ in range(10000):
iou, _ = box_iou(pred_box, GT_box)
loss = 1 - iou.sum()
print(loss)
loss.backward()
with torch.no_grad():
pred_box -= pred_box.grad * lr
print(pred_box.grad)
pred_box.grad = None # 手动清除该 Tensor 梯度
pred_box 与 GT_box 都是 x1y1x2y2 的坐标,看代码坐标二者显然有重叠,所以loss可以下降,最后 pred_box 移动至 GT_box
而如果我将 pred_box 改为与 GT_box 无重叠的
# pred_box = torch.tensor([0.3, 0.3, 0.6, 0.6])[None]
pred_box = torch.tensor([10.3, 10.3, 10.6, 10.6])[None] # 就是这一步改成没有重叠的
pred_box.requires_grad = True
GT_box = torch.tensor([0.0, 0.0, 1.0, 1.0])[None]
lr = 0.001
for _ in range(10000):
iou, _ = box_iou(pred_box, GT_box)
loss = 1 - iou.sum()
print(loss)
loss.backward()
with torch.no_grad():
pred_box -= pred_box.grad * lr
print(pred_box.grad)
pred_box.grad = None # 手动清除该 Tensor 梯度
打印梯度,可以看到梯度始终为0
tensor([[0., 0., 0., 0.]])
本实验只是验证了两box不重叠时存在梯度为0,无法优化的现象,接下来通过一个小实验,来验证clip会导致梯度为0的现象
2. 代码实验二
pred_box_wo_clip = torch.tensor([0.3, 0.3, -3, -3])
pred_box_wo_clip.requires_grad = True
GT_box = torch.tensor([1.0, 1.0, 1.0, 1.0])
lr = 0.0001
for _ in range(35000):
pred_box = torch.clip(pred_box_wo_clip, min=-1)
loss = ( (GT_box - pred_box)**2 ).sum()
print(loss)
loss.backward()
with torch.no_grad():
pred_box_wo_clip -= pred_box_wo_clip.grad * lr
print(pred_box_wo_clip.grad)
pred_box_wo_clip.grad = None # 手动清除该 Tensor 梯度
运行代码,可以看到由于后两维梯度为0,而前两维可以正常求导
tensor([-1.4000, -1.4000, 0.0000, 0.0000])
数学中这样的clip操作被称作 hard 硬截断
3. 回忆
这让我想到一年前和锐哥做比赛,有个求反余弦的操作,然后反向求角度的操作,大概是酱紫的:
cos = xxxx # 这里拿到角度的cos值
theta = arccos(cos)
由于那个求反余弦角度函数显然只会接受(-1, 1)的输入,若不在这个范围内,直接返回NaN。由于cos的数值精度误差问题,有时会返回1.000001,然后我就直接clip为1了,之后得到角度。
当时用的是DDPG,不论我们怎么调,他就是啥都学不会,始终朝着一个方向转动。一个可能的原因是因为这里用了clip导致梯度传回去始终是0,所以无法优化?
但是 不是这里… 真破大防了… 翻了一下去年的博客,那个操作是numpy做的,所以也就和梯度没什么事儿了,不知道我当时程序里还有没有clip操作了[捂脸笑哭]
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









