









在上一节 小白的web优化之路 一、使用redis来缓存信息 中 我们提到使用redis来缓存列表信息来提高访问速度,但是,上一节中只是简单的获取一页的数据,在实际中,我们可能有成千上百页的数据,那么该如何使用redis来加快列表的访问速度呢?
方法就是:
1、判断有无缓存,若无缓存,从数据库中直接获取一千条数据,然后缓存到redis中。
2、根据请求从redis中的列表中获取每页的数据。
3、当然,当数据有更新时,应该清除缓存,保证数据的实时性。
流程图为:
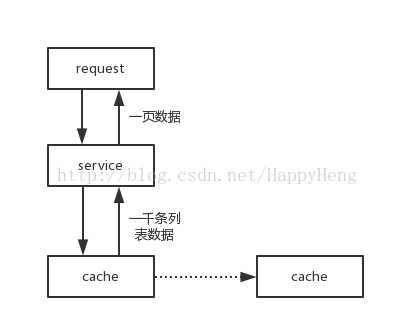
一、其中核心代码为:
Controller:
package com.happyheng.controller;
import com.alibaba.fastjson.JSON;
import com.happyheng.dao.ArticleDao;
import com.happyheng.model.Article;
import com.happyheng.model.Page;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.util.StringUtils;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import redis.clients.jedis.Jedis;
import java.util.List;
/**
*
* Created by happyheng on 17/5/18.
*/
@RestController
@RequestMapping("/testList")
public class TestListController {
private static final String KEY_CACHE_THOUSAND_ARTICLE_LIST = "article_thousand_list";
@Autowired
private ArticleDao articleDao;
@RequestMapping("/getArticleList")
public List<Article> getArticleList(Page page) throws Exception{
// 判断页数以及数量是否超标
int pageIndex = page.getPageIndex();
int pageSize = page.getPageSize();
if (pageIndex <= 0 || pageSize <= 0){
return null;
}
if (pageIndex * pageSize > ArticleDao.PAGE_MAX_NUM){
return null;
}
// 从redis中获取1000条数据
Jedis jedis = new Jedis("localhost");
String articleThousandListStr = jedis.get(KEY_CACHE_THOUSAND_ARTICLE_LIST);
List<Article> articleList;
if (StringUtils.isEmpty(articleThousandListStr)){
// 如果没有,从数据库中直接取出1000条, 并将其缓存到redis中
articleList = articleDao.getThousandArticleListFromdb();
jedis.set(KEY_CACHE_THOUSAND_ARTICLE_LIST, JSON.toJSONString(articleList));
jedis.expire(KEY_CACHE_THOUSAND_ARTICLE_LIST, 60);
} else {
// 将String反序列化为Article列表
articleList = JSON.parseArray(articleThousandListStr, Article.class);
}
// 从列表中选出指定的列表数据
List<Article> result = articleList.subList((pageIndex-1) * pageSize, pageIndex * pageSize);
return result;
}
}
ArticleDao:
package com.happyheng.dao;
import com.happyheng.model.Article;
import org.springframework.stereotype.Service;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
/**
*
*
* Created by happyheng on 17/5/7.
*/
@Service
public class ArticleDao {
public static final int PAGE_MAX_NUM = 1000;
public List<Article> getThousandArticleListFromdb() throws Exception{
String sql = "SELECT * FROM article ORDER BY create_time DESC LIMIT 0, " + PAGE_MAX_NUM;
Class.forName("com.mysql.jdbc.Driver");
Connection mConnection = DriverManager.getConnection("jdbc:mysql://localhost:3306/optimize_db", "root", "mytestcon");
Statement statement = mConnection.createStatement();
ResultSet resultSet = statement.executeQuery(sql);
try {
List<Article> list = new ArrayList<>();
//注意指针刚开始是-1位置,这行next()方法,会先判断下一个位置有没有,如果有,指向下一个位置。
while (resultSet.next()) {
Article article = new Article();
article.setId(resultSet.getLong("id"));
article.setTitle(resultSet.getString("title"));
article.setContent(resultSet.getString("content"));
article.setCreate_time(resultSet.getString("create_time"));
list.add(article);
}
return list;
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
resultSet.close();
statement.close();
mConnection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
return null;
}
}
即先从redis中取序列化后的1000条数据,如果没有,在从数据库中取出1000条数据,并序列化存储到redis中。
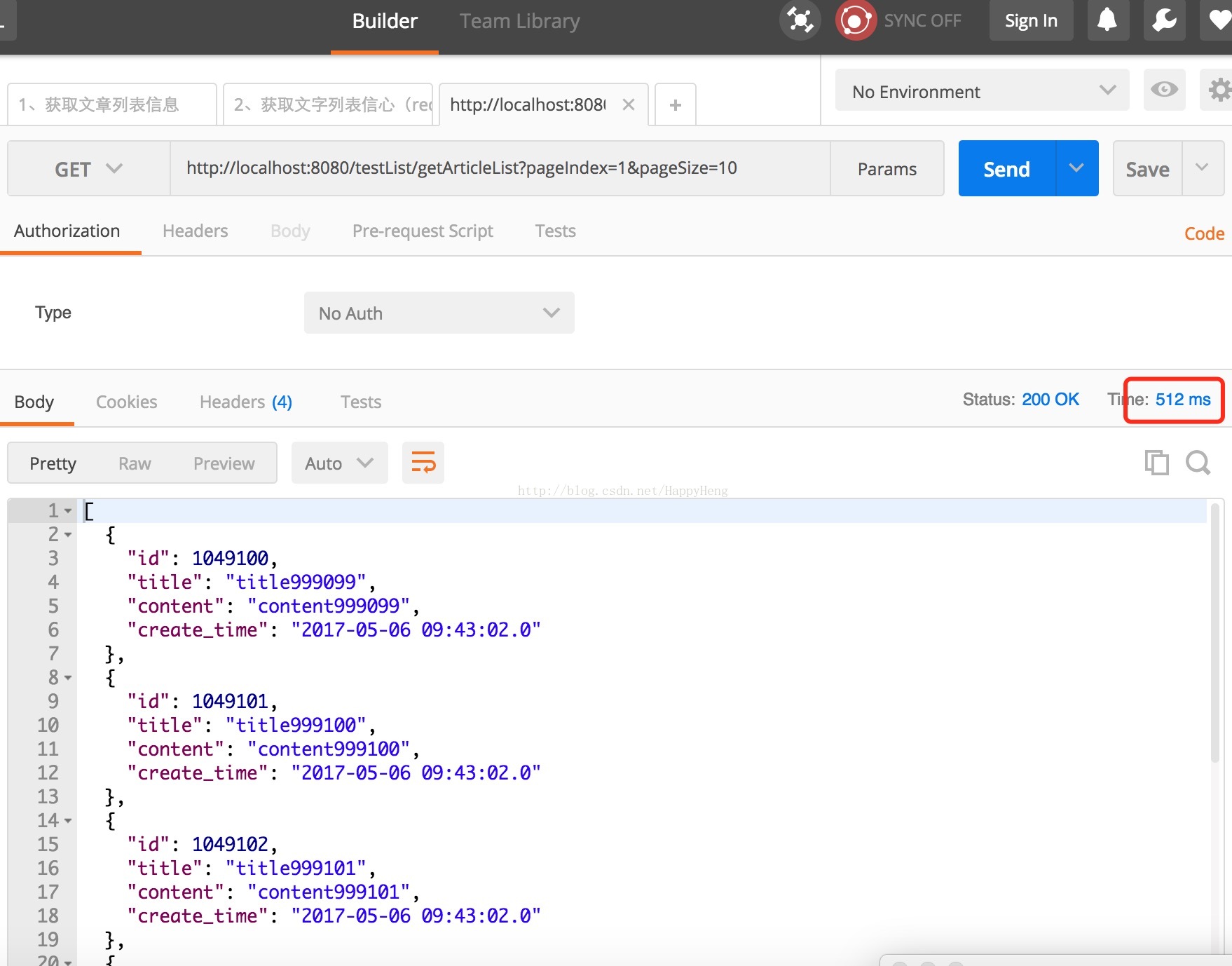
二、访问之前与访问之后的速度比较:
1、之前:
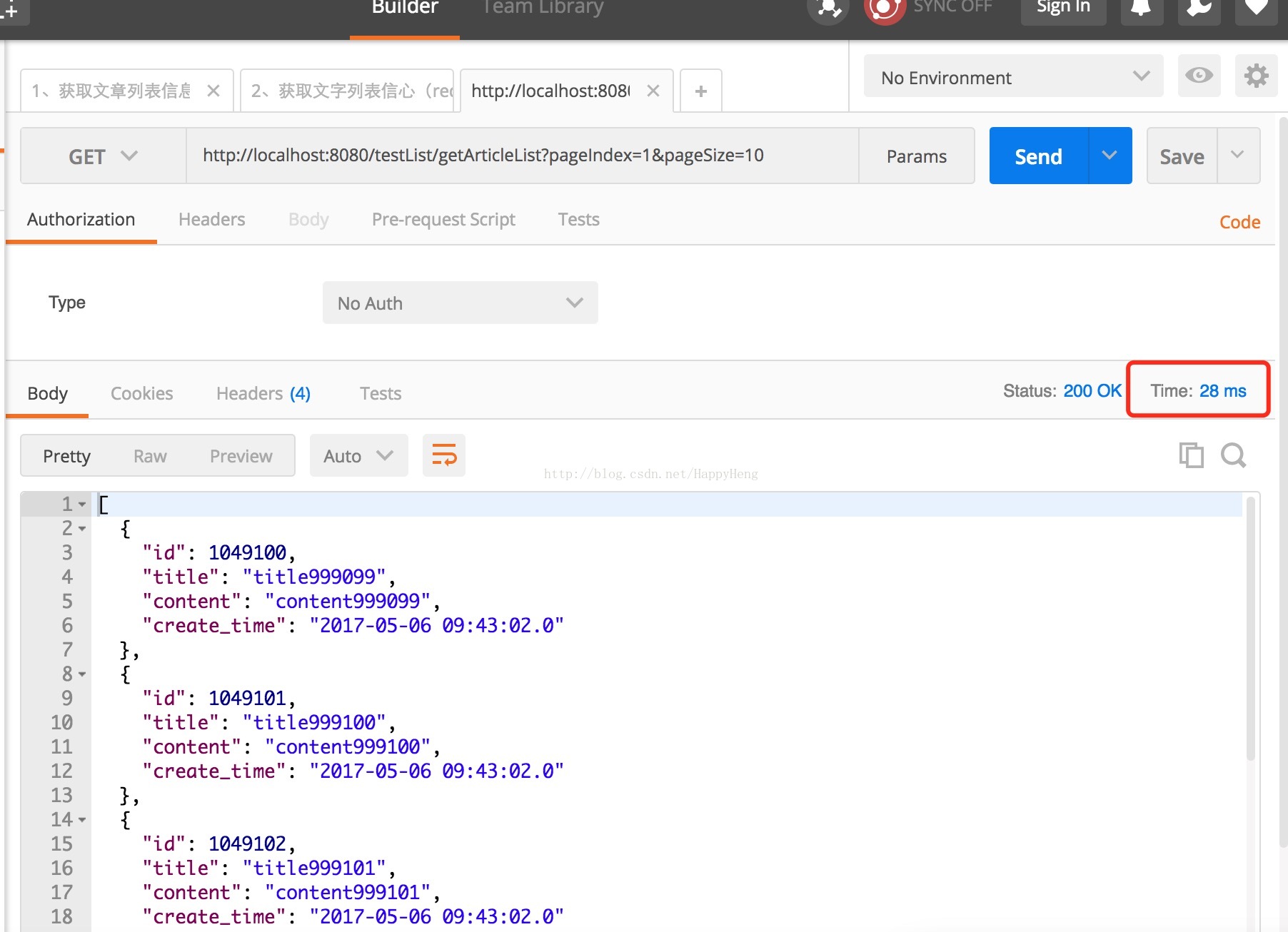
2、之后:
三、源码以及测试数据脚本
示例代码已放到github上,此工程为项目中的 web-optimize-redis 工程,地址为 项目源码地址
其中测试写入数据库的Python脚本为:
import pymysql
import time
# 1.获取连接对象
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='mytestcon', db='optimize_db', charset='utf8')
cursor = conn.cursor()
# 2.测试插入数据
rangeNum = 1000000
for i in range(rangeNum):
print('执行了' + str(i/rangeNum))
title = 'title' + str(i)
content = 'content' + str(i)
dateStr = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
cursor.execute('INSERT INTO article (title, content, create_time) VALUES (%s, %s , %s)', (title, content, dateStr))
# 提交
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
下一篇中,会介绍使用MQ来优化我们的web项目: 小白的web优化之路 三、使用MQ来实现事务异步处理















 3283
3283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









