







1 Word2vec
**
Word2vec模型是简单化的神经网络。既然是神经网络,就有对应的输入层,隐层与输出层。输入就是上边提到的One-Hot Vector,隐层没有激活函数,只是线性的单元。输出层维度跟输入层一样,用的是Softmax回归。
word2vec主要包含两个模型:CBOW和skip-gram,以及两种高效训练的方法:负采样(negative sampling)和层序softmax(hierarchical softmax)。
CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
1.1 CBOW模型
BOW是一种基于迭代的、学习word vectors的方法。
它的思想是:给定一个中心词的上下文单词,预测这个中心词是是什么。例如:{“the”,“cat”,"?", “over”,“the”,“puuddle”},预测“?”是哪个词。
1.2 Skim-gram模型
kip-gram是给定input word来预测上下文。所谓一个单词的上下文是指在其窗口中出现的词(一般情况窗口的size选5左右,即这个中心词的前5个词和后5个词,上下文词一共是10个词)。
2 梯度优化
我们的损失函数 J(θ) J(\theta)J(θ) 需要最小化
使用的方法为:梯度下降
对于当前 θ \thetaθ ,计算 J(θ) J(\theta)J(θ) 的梯度
然后小步重复朝着负梯度方向更新方程里的参数α=(step size) or (learning rate)
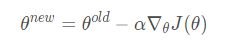
更新唯一的参数 θ: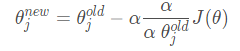














 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









