







索引类型
1.
B-tree
索引
注
:
名叫
btree
索引
,
大的方面看
,
都用的平衡树
,
但具体的实现上
,
各引擎稍有不同
,
比如
,
严格的说
,NDB
引擎
,
使用的是
T-tree
Myisam,innodb
中
,
默认用
B-tree
索引
但抽象一下
---B-tree
系统
,
可理解为
”
排好序的快速查找结构
”
.
2 hash
索引
在
memory
表里
,
默认是
hash
索引
, hash
的理论查询时间复杂度为
O(1)
hash
函数计算后的结果
,
是随机的
,
如果是在磁盘上放置数据
,
比主键为
id
为例
,
那么随着
id
的增长
, id
对应的行
,
在磁盘上随机放置
.
左前缀原则
在多列上建立索引后
,
查询哪个列
,
索引都将发挥作用
误
:
多列索引上
,
索引发挥作用
,
需要满足左前缀要求
.
以
index(a,b,c)
为例
,
| 语句 | 索引是否发挥作用 |
| Where a=3 | 是,只使用了a列 |
| Where a=3 and b=5 | 是,使用了a,b列 |
| Where a=3 and b=5 and c=4 | 是,使用了abc |
| Where b=3 / where c=4 | 否 |
| Where a=3 and c=4 | a列能发挥索引,c不能 |
| Where a=3 and b>10 and c=7 | A能利用,b能利用, C不能利用 |
| 同上,where a=3 and b like ‘xxxx%’ and c=7 | A能用,B能用,C不能用 |
filesort 二次排序
一般而言,分组统计要先按分组字段,有序排列
用临时表来排序
联合索引反而快了,主键索引反而慢了 ----》 聚簇索引,索引覆盖 , innodb与myisam索引的区别
innodb的次索引指向对主键的引用
myisam的次索引和主索引 都指向物理行
Myisam
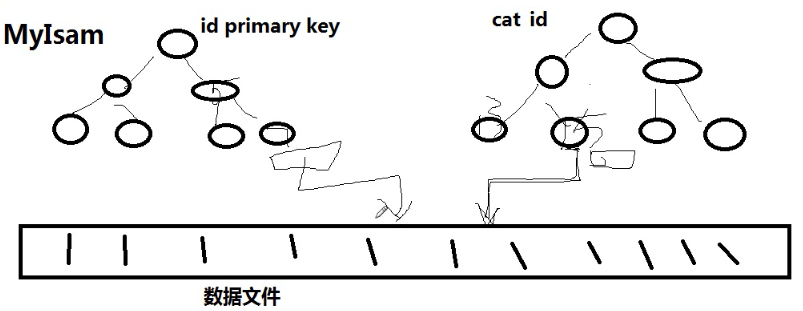
存在物理行中。。。。。。
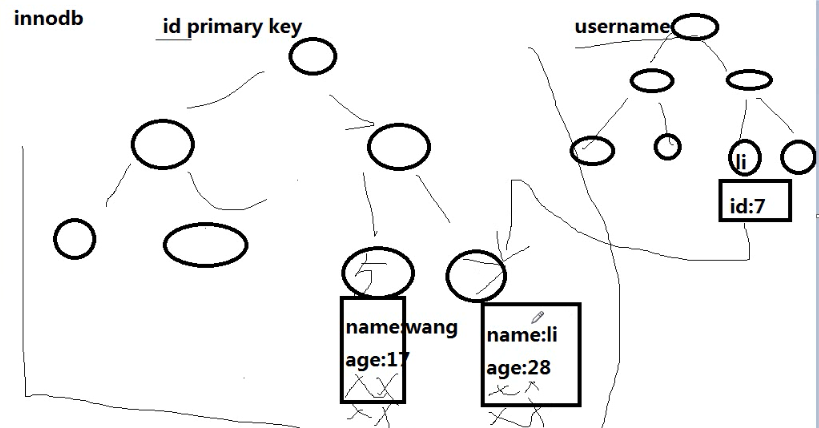
主键索引 普通索引
i
nnodb的主索引文件上,直接存放该行数据,称为聚簇索引,次索引指向对主键的应用;
myisam中,主索引和次索引,都指向物理行
注意
:innodb
来说
,
1:
主键索引 既存储索引值
,
又在叶子中存储行的数据
2:
如果没有主键
,
则会
Unique key
做主键
3:
如果没有
unique,
则系统生成一个内部的
rowid
做主键
.
4:
像
innodb
中
,
主键的索引结构中
,
既存储了主键值
,
又存储了行数据
,
这种结构称为
”
聚簇索引
”
高性能索引策略
0:
对于
innodb
而言
,
因为节点下有数据文件
,
因此节点的分裂将会比较慢
.
对于
innodb
的主键
,
尽量用整型
,
而且是递增的整型
.
如果是无规律的数据
,
将会产生的页的分裂
,
影响速度
.
实验innodb 顺序和乱序的执行效率

索引覆盖
:
索引覆盖是指
如果查询的列恰好是索引的一部分
,
那么查询只需要在索引文件上进行
,
不需要回行到磁盘再找数据
.
这种查询速度非常快
,
称为
”
索引覆盖
”

如果有
Using index则说明是索引覆盖
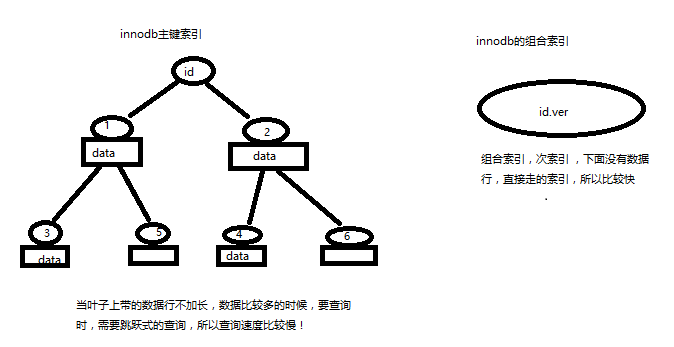
innodb沿着主键走,因为是在叶子上,如果挂的数据比较多的情况下,查询数据跨的块太多,所以查询的比较慢,但是如果在innodb上是复合索引的话,id.ver 是二级索引,是次索引,所以是按照所以来走,因此查询的比较快,不是主键索引的话,就没有下面的数据块,只取id,不需要去id下面的数据。因为myisam是存在磁盘上,所以两者差别很小。
索引的长度和区分度是相互矛盾的,索引长度越长,区分度越高,所以应该,分析数据,寻找最合适的位置。

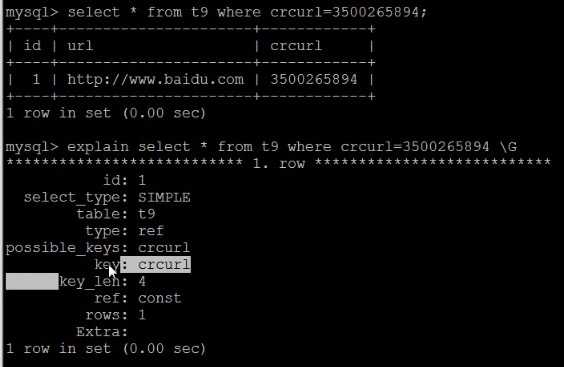
用crc函数来构造伪哈希列
把字符串的列,转成整形,来降低索引的长度,从而提高查询效率















 3378
3378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









