






目录

希望各位大佬能多多点赞关注收藏,有了你们的支持,我也能更有动力的向你们学习不是(手动狗头)!!!
1.使用线程池的目的
在知道线程池之前,每当我们需要一个线程完成任务的时候都需要“new”一个Thread对象,然后使用各种方式将run方法给到thread,方法大致有以下几种:
1.构造一个类继承Thread方法,然后直接构造出这个类的对象实现向上转型。
class MyThread extends Thread{
@Override
public void run() {
System.out.println("第一种方法");
}
}
public class demo3 {
public static void main(String[] args) throws InterruptedException {
Thread t=new MyThread();
t.start();
}
}2.构造一个类实现Runnable接口,然后将这个类的实例传给Thread。
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("第二种方法");
}
}
public class demo3 {
public static void main(String[] args) throws InterruptedException {
Thread t2=new Thread(new MyRunnable());
t2.start();
}
}3.直接写一个继承于Thread匿名内部类。
public class demo3 {
public static void main(String[] args) throws InterruptedException {
Thread t3=new Thread() {
@Override
public void run() {
System.out.println("第三种方法");
}
};
t3.start();
}
}4.在构造Thread时传入一个实现Runnable接口的匿名内部类。
public class demo3 {
public static void main(String[] args) throws InterruptedException {
Thread t4=new Thread(new Runnable() {
@Override
public void run() {
System.out.println("第四种方法");
}
});
t4.start();
}
}5.直接用lambda表达式完成操作。(比较推荐)
public class demo3 {
public static void main(String[] args) throws InterruptedException {
Thread t5=new Thread(()-> {
System.out.println("第五种方法");
});
}
}但是无论是其中哪一种都不能避开要调用系统api在系统内核中添加一个线程。所以这是一个“内核态”+“用户态”的操作。因为系统内核要管理很多东西,不一定会直接来帮你完成添加内核操作,这样会使得运行速度会慢一些。所以为了实现纯用户态的操作,有大佬就提出了线程池这种思想(当然不只有线程池,还有各种池,就比如jdbc那还有个连接池)。大致上就是我提前把这些线程创建好,当用户想要调用的时候直接从线程池里面取就好了,线程用完了也不会立马删除,而是先放回线程池中过一会再删除。如图:
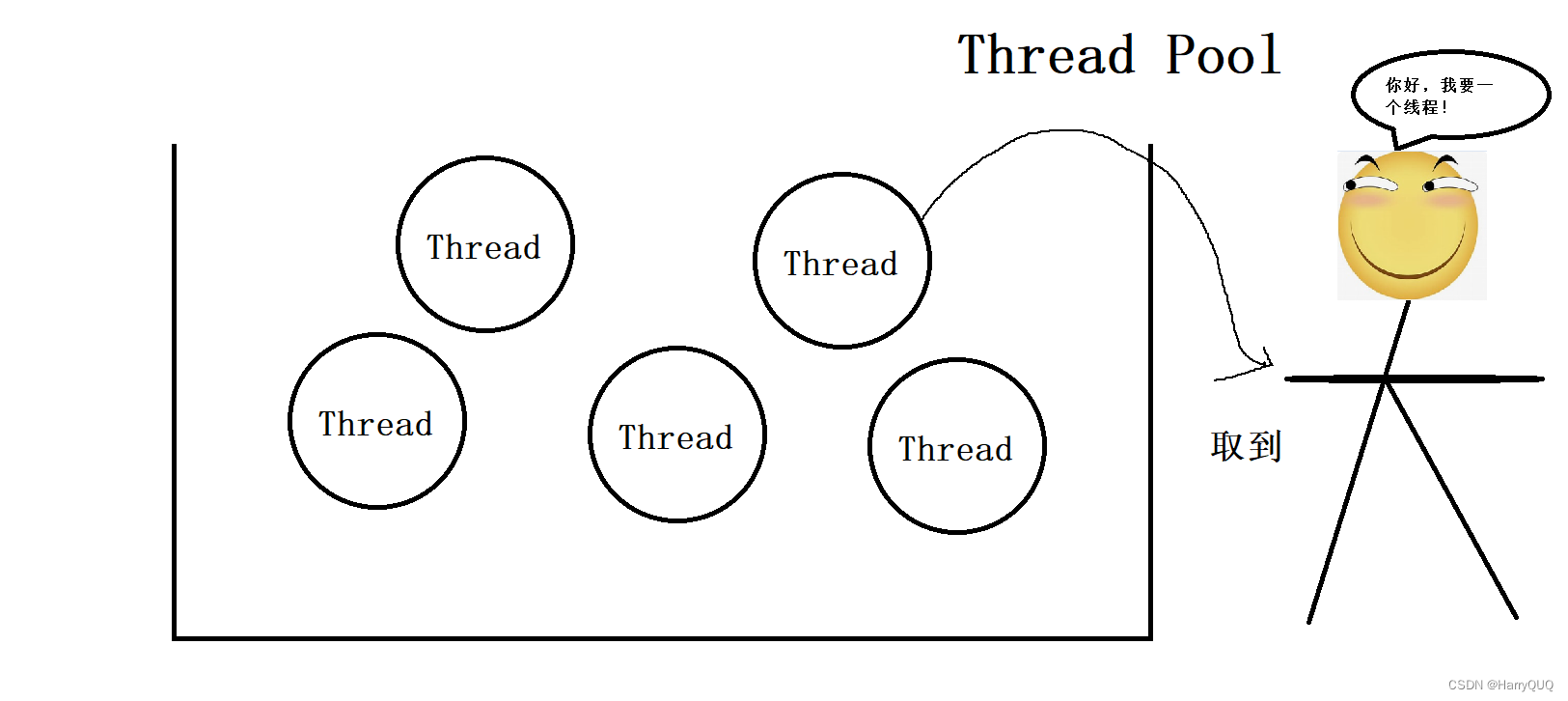
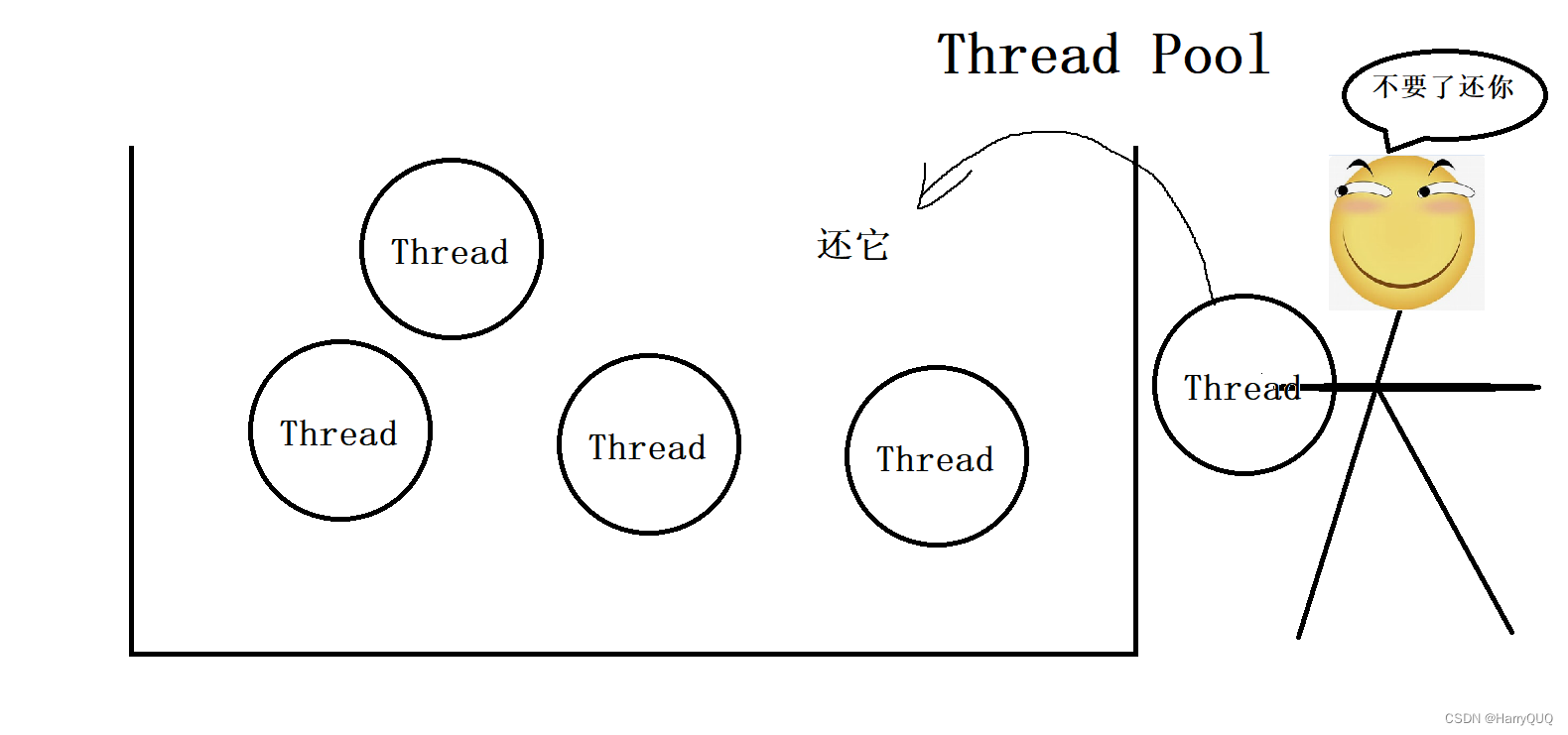
说完了线程池的大致原理,那么我们来使用以下线程池。
2.线程池的使用及原理
在java中为线程池提供了一个叫ThreadPoolExecutor类他继承于AbstractExecutorService而这个抽象类实现了ExecutorService接口。作为Java用户我们为了降低耦合,我们可以使用ExecutorService通过向上转型来接收ThreadPoolExecutor的实例。在Java中提供了四种类型的线程池,分别是
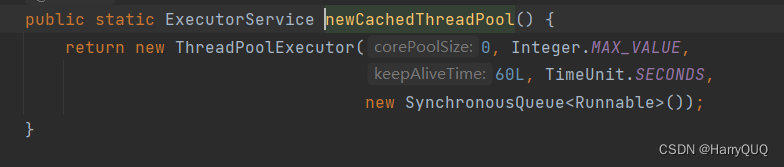
1.newCachedThreadPool(创建一个带缓存的线程池,缓存的意思是线程池用完了线程可以保留一段时间,并且这个线程池可以扩容)PS:以下的源码部分可以待我后面讲到再看
2.newFixedThreadPool(创建一个固定大小的线程池,他无法扩容并且没有缓存线程功能,但是他也不会减少线程,因为固定的那几个线程都是核心线程(这个后面会讲到))

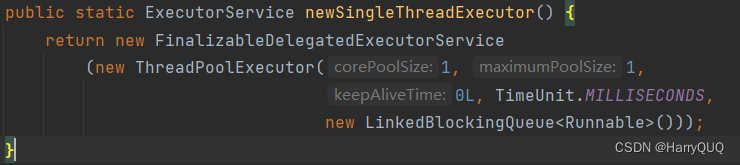
3.newSingleThreadExecutor(创建一个单个线程的线程池(平时不怎么用用))
4.newScheduleThreadPool(这个相当于是一个用多个线程来完成任务的timer)

以上的方法都来自于Executors类,这样做就是实现了工厂模式,目的是更好的构造某个类,就比如我要构造一个点,我可以用极坐标来表示,也可以用笛卡尔坐标系来表示,那构造方法就是public Point (double p,double l) {}和 public Point(double x,double y)() {},构成重写的要求是形式参数要有所不同,但是它们都是double类无法构成重写,所以我们只能用不同的方法来弥补Java重写的缺陷。
这几种线程池都可以使用类似的方法去实例,代码如下:
public class demo1 {//线程池的使用
public static void main(String[] args) throws InterruptedException {
ExecutorService service1=Executors.newCachedThreadPool();
ExecutorService service2=Executors.newFixedThreadPool(4);
ExecutorService service3=Executors.newSingleThreadExecutor();
ExecutorService service4=Executors.newScheduledThreadPool(2);
}
}在实例完ExecutorService之后,我们可以调用它的submit方法来给线程池添加任务,代码如下:
public class demo1 {//线程池的使用
public static void main(String[] args) throws InterruptedException {
ExecutorService service1=Executors.newCachedThreadPool();
ExecutorService service2=Executors.newFixedThreadPool(4);
ExecutorService service3=Executors.newSingleThreadExecutor();
ExecutorService service4=Executors.newScheduledThreadPool(2);
service1.submit(()-> {
System.out.println("newCachedThreadPool");
});
}
}
我们可以看到线程池还在运行,我们可以通过shutdown方法来结束线程池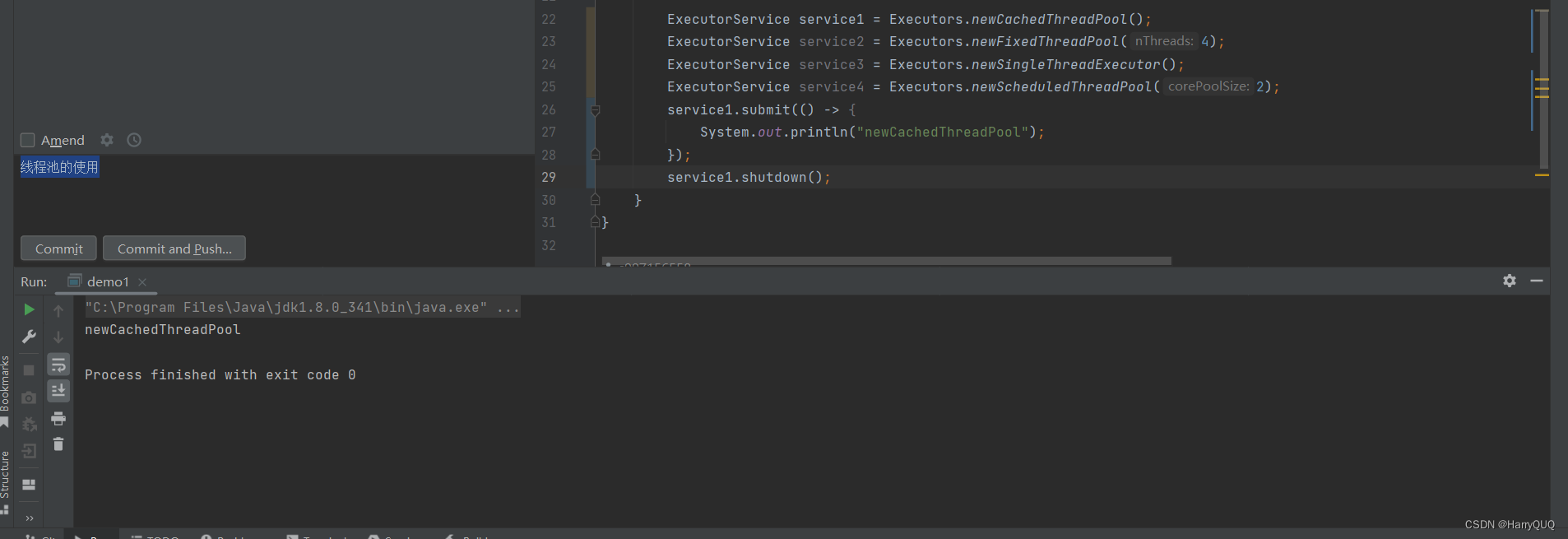
这里我们就只用newCachedPool举例,其他的用法都大差不差,各位兄台可以去试试。
那如果我们都是用Java给的方法来操作就会显得过于局限了,所以接下来我们要就要去了解上图源码中构造线程池的方法。
可以看到源码中用的是ThreadPoolExecutor(线程池构造器),我们在Java中找到它的四种不同的构造方法,如图
但事实上这些构造方法就是6种参数中的5种到7种,我们这里只要了解了参数最多的构造方法也就基本上了解了所有的构造方法。

我们现在来按照顺序了解它的七个参数:
1.corePoolSize:核心线程数量。
2.maximumPoolSize:最大线程数量
(这里我们把核心线程数量和最大线程数量一起讲,其中核心线程数量就是不会因为线程没被用到而销毁的,而除了核心线程其他的线程是会因为没有被用到而销毁的,我们这里可以用合同制教师和编制内教师来打比方,在某学校有一个学校某一年招了很多学生师资紧缺就招来了一群合同制教师来弥补空挡,而当这三年过去了师资不紧缺时,这些合同制的员工就闲下来了,校方就可以把他们辞退,但是不同的是编制内教师就算请产假休息很久也会因为法律留在学校不会被开除。其中核心线程就是编制内教师,其余线程就是合同制教师)
3.时间长度
4.时间单位,可以从TimeUnit里面取
5.放Runnable的队列
6.线程工厂,也就是能从中获取线程
7.当线程源源不断的被创建,超出线程数量时的拒绝策略。
(这里我们重点讲拒绝策略:Java中的拒绝策略一共有四种(都继承了ThreadPoolExecutor)
3.生动讲解拒绝策略:
1.AbortPolicy(当超出最大线程数时抛出RejectedExecutionException(拒绝执行异常))
2.CallerRunsPolicy(当超出最大线程数时,让添加任务的线程执行任务)
3.DiscardOlderstPolicy(丢弃最老的任务)
4.DiscardPolicy(丢弃刚刚要加入的任务)
这里我们做个比喻,比如我将今天都安排满了,此时我的朋友叫我去改论文,我心想“我已经这么累了还要改论文”,我心态崩了,今天什么事情都做不了,这就是AbortPolicy
又比如我这次心态不崩了但是我也懒得改,我就让我朋友帮我改一下论文,这就是CallerRunsPolicy
那再比如我很想改论文,但是我今天的行程又是满的,咋办呢,我就丢弃掉最早的任务然后去改论文,这就是DiscardOldestPolicy
那最后比如我不想改论文,我朋友也不想改,那干脆都别改,我当作没听见,继续完成原来的安排,这就是DiscardPolicy。
)
4.自己实现一个简单的线程池
既然我们都已经知道了线程池的使用方式和原理,那我们可以自己去写一个简单的线程池。
首先我们知道线程池不就是一个放线程的池子么,所以我们先写出这个放线程的池子,但是线程中又要有操作,所以我们在写池子之前要写一个放Runnable的队列,这里我们使用阻塞队列,阻塞队列没有任务时会自动等待,任务过多时也会等待取走,虽然不是上述4中拒绝策略中的一种,但是也算是一种下策嘛嘿嘿嘿,毕竟只是简单的实现代码如下:
class MyThreadPool {
BlockingQueue<Runnable> queue=new ArrayBlockingQueue<>(10);
public MyThreadPool(int n) {
for (int i = 0; i <n ; i++) {
int id=i;
Thread T=new Thread(()-> {
try {
queue.take();
System.out.println("执行线程"+i);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t.start;
}
}
}这时候我们要想怎么添加任务呢?其实很简单,就是把任务offer到队列中,那我们开写代码!
public void submit(Runnable task) {
queue.put(task);//把task添加到阻塞队列中
}这里是线程池总代码:
class MyThreadPool {
BlockingQueue<Runnable> queue=new ArrayBlockingQueue<>(10);
public MyThreadPool(int n) {
for (int i = 0; i <n ; i++) {
int id=i;
Thread t=new Thread(()-> {
try {
queue.take();
System.out.println("执行线程"+id);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t.start();
}
}
public void submit(Runnable task) throws InterruptedException {
queue.put(task);
}
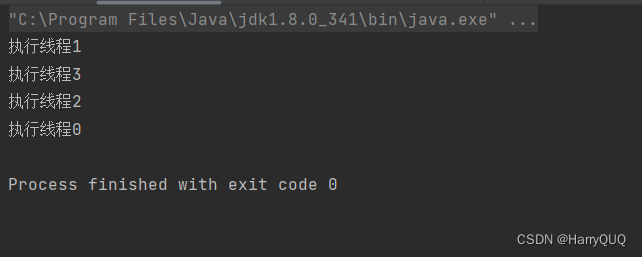
}我们试着去执行一下试试
public class demo4 {
public static void main(String[] args) throws InterruptedException {
MyThreadPool myThreadPool = new MyThreadPool(4);
myThreadPool.submit(() -> {
});
myThreadPool.submit(() -> {
});myThreadPool.submit(() -> {
});myThreadPool.submit(() -> {
});
}
}
那这样我们自己的线程池就写完啦,是不是so eazy!!妈妈再也不用担心我们不会线程池啦!!!
5.线程数的决定方法
我们前面讲了ThreadPoolExecutor,其中要自定义线程数量。如果线程数少了那代码执行效率就慢了,如果线程数太多就会增加CPU调度时间也会导致代码运行速度变慢,但是线程如何决定呢?总不可能凭空捏造吧。我们cpu上有写我们的物理核心数和逻辑核心数:
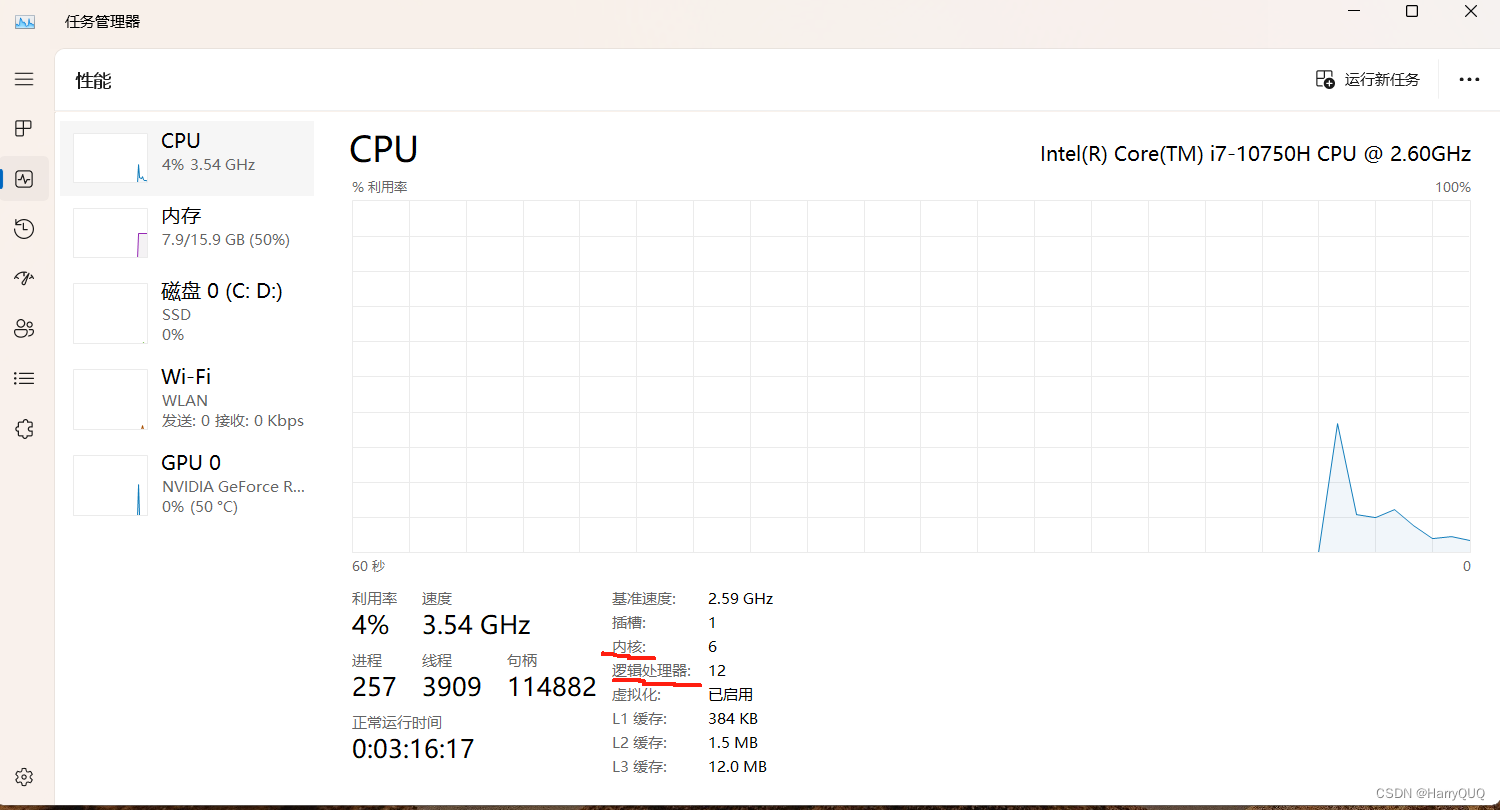
这里我们要参考逻辑核心数,逻辑核心数越多,相同情况下线程数也就越多,但是我们还是不好确定线程的数量,网上有说是逻辑核心数的某某倍的,实际上是错的,线程我们必须通过实践去得出最佳数量。因为一个线程的代码执行有两大类,一种是CPU密集型,一种是IO密集型,因为CPU操作相对于IO操作快了很多,所以在执行IO操作的时候CPU相对来讲是有很长的等待时间的,所以就会出现核心休息的情况,假设全都是CPU密集型代码那么线程数就必须等于逻辑核心数,若不是则可以大于逻辑核心数,我们一个代码不可能全是CPU密集型或是IO密集型所以就必须去实践找出最佳核心数。
6.总结
上述就是本篇文章的所有内容了,都看到这了别忘了给鄙人一个点赞收藏加关注哦~~~谢谢啦!!!















 637
637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









