







在Linux 文本日常使用中,需要用到很多小工具来实现事半功倍的效果,因此,推荐三款常用的文本处理小工具:cut、sort、uniq三种。
命令:cut

使用说明:
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。
如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
参数:
-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
-c :以字符为单位进行分割。
-d :自定义分隔符,默认为制表符。
-f :与-d一起使用,指定显示哪个区域。
-n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的
范围之内,该字符将被写出;否则,该字符将被排除
示例:
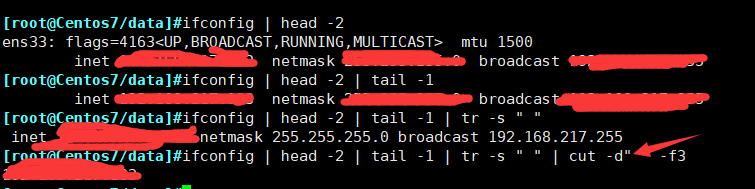
一:找出ifconfig命令结果中本机的ip地址
文本排序
命令:sort
Linux sort命令用于将文本文件内容加以排序。
sort可针对文本文件的内容,以行为单位来排序。
语法
sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][–help][–verison][文件]
参数说明:
-b 忽略每行前面开始出的空格字符。
-c 检查文件是否已经按照顺序排序。
-d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
-f 排序时,将小写字母视为大写字母。
-i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
-m 将几个排序好的文件进行合并。
-M 将前面3个字母依照月份的缩写进行排序。
-n 依照数值的大小排序。
-u 意味着是唯一的(unique),输出的结果是去完重了的。
-o<输出文件> 将排序后的结果存入指定的文件。
-r 以相反的顺序来排序。
-t<分隔字符> 指定排序时所用的栏位分隔字符。
+<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
--help 显示帮助。
--version 显示版本信息。
示例:
查出分区空间使用率的最大百分值


查出用户UID最大值的用户名、UID以及shell类型

统计当前连接本机的每个远程机IP的连接数,并按从大到小排序

命令:wc 解释(Word count)
Linux wc命令用于计算字数。
利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
语法
wc [-clw][--help][--version][文件...]
参数:
-c或--bytes或--chars 只显示Bytes数。
-l或--lines 只显示行数。
-w或--words 只显示字数。
--help 在线帮助。
--version 显示版本信息。
示例:
查出/tmp的权限,以数字方式显示
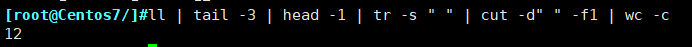















 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









