







SEP 20 2018 CHRISTIE KOEHLER
This is the fourth and final post in the series Building Resilient Infrastructure with Nomad (Part 1, Part 2, Part3). In this series we explore how Nomad handles unexpected failures, outages, and routine maintenance of cluster infrastructure, often without operator intervention.
In this post we’ll explore how Nomad’s design and use of the Raft consensus algorithm provides resiliency against data loss and how to recover from outages.
We’ll assume a production deployment, with the recommended minimum of 3 or 5 Nomad servers. For information deploying a Nomad cluster in production, see Bootstrapping a Nomad Cluster.
You’ll recall from Post 2 in this series, that a Nomad cluster is composed of nodes running the Nomad agent, either in server or client mode. Clients are responsible for running tasks, while servers are responsible for managing the cluster. Client nodes make up the majority of the cluster, and are very lightweight as they interface with the server nodes and maintain very little state of their own. Each cluster has usually 3 or 5 server mode agents and potentially thousands of clients.
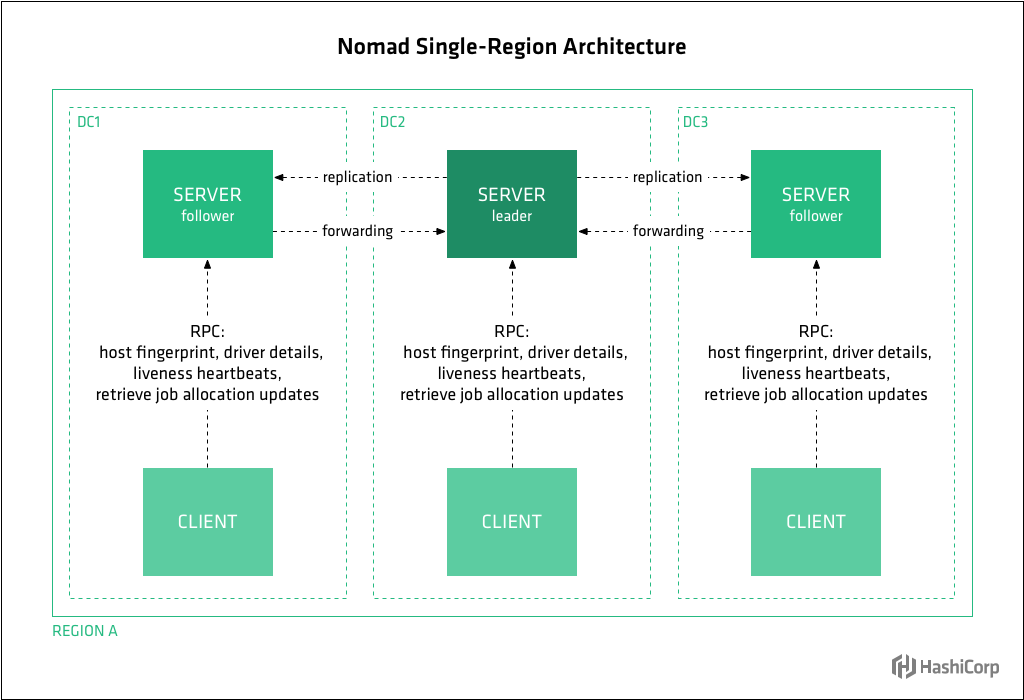
Nomad models infrastructure as regions and datacenters. Regions may contain multiple datacenters. For example the “us” region might have a “us-west” and “us-east” datacenter. Nomad servers manage state and make scheduling decisions for the region to which they are assigned.
Nomad and Raft
Nomad uses a consensus protocol based on the Raft algorithm to provide data consistency across server nodes within a region. Ra
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 145
145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









