







 这篇博客介绍了Java8中Map接口的实现,特别是HashMap和TreeMap。HashMap使用Hash算法存储数据,允许一个null键,时间复杂度为O(1),非线程安全。TreeMap基于红黑树,保证排序,时间复杂度为O(logn),同样非线程安全。Set接口的实现如HashSet依赖于HashMap。文章探讨了它们的内部结构、操作原理和常见用法。
这篇博客介绍了Java8中Map接口的实现,特别是HashMap和TreeMap。HashMap使用Hash算法存储数据,允许一个null键,时间复杂度为O(1),非线程安全。TreeMap基于红黑树,保证排序,时间复杂度为O(logn),同样非线程安全。Set接口的实现如HashSet依赖于HashMap。文章探讨了它们的内部结构、操作原理和常见用法。
本人大二学生党,最近研究JDK源码,顺便复习一下数据结构与算法的知识,所以就想写这些系列文章。这是[Java Collection源码+算法+数据结构]系列的第一篇,首先看一下Collection的所有架构:
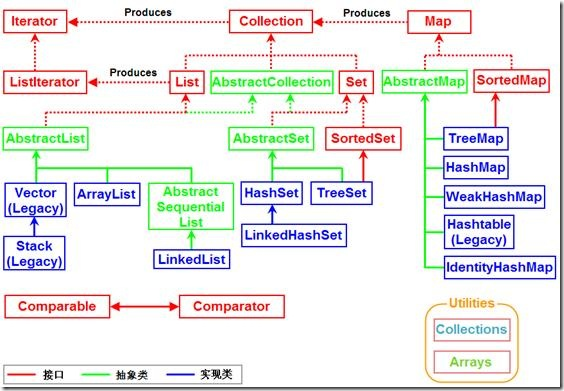
看到出来Map的地位是很重要的,所以先来研究一哈Map咯。
Map简介与基本用法
An object that maps keys to values. A map cannot contain duplicate keys; each key can map to at most one value.
说白了,Map就是键值对咯。而Map维护一个KeySet(没重复的值) Values (表面是一个Collection,也就是可以重复)EntrySet 三个对象。Map这个类里面有个Map.Entry的接口,实现这个接口,就表明需要维护上面3个对象。HashMap利用其内部类Node来存储键值对。
Map即其实现类的一些特性:
Map:对于所有实现Map的类,key不能重复,但value可以重复HashMap:key,value可以为null(注意要满足Map所满足的条件,即只能有一个null的key)。同时采用Hash来存储数据。同时HashMap是线程不安全的 。在JDK源码里面说,HashMap的get,put的时间复杂度为常量,也就是O(1)。TreeMap:采用红黑树来存储每个信息,同时通过Comparator来进行排序。当Comparator定义了null的比较的时候,才可以添加null的key,否则报错。TreeMap是线程不安全的。由于TreeMap对数据要进行排序,所以牺牲了一些性能,get puts时间复杂度为O(log),也就是树的高度。LinkedHashMap:继承HashMap,拥有HashMap的性质,但是内部的bucket采用链表存储数据(什么是bucket下面会进行说明),所以插入,删除数据比较轻便,但查找就比较耗时间了,但是迭代访问还是快些。(拓展一哈:LinkedHashMap的构造函数提供了accessOrder参数,true 表示按照insertion-order 插入顺序排序,false表示按照access-order,即LRU进行排序)
对于上面的线程安全要特别说明一哈:fast-fail是针对这种情况的,具体怎么地见下文。
Map使用这种方式遍历最快哦(参考文献)。
Map<String, String> map = ...
for (Map.Entry<String, String> entry : map.entrySet())
{
System.out.println(entry.getKey() + "/" + entry.getValue());
}但是遍历删除元素只能有这个办法:
Iterator iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, Integer> item = (Map.Entry<Integer, Integer>) iterator.next();
if (item.getValue() > 30)
iterator.remove();
}Then,看看Map的一些常见的用法:
@Test
public void testNormal() {
Map<String, String> map = new HashMap<>();
System.out.println(map.put("1", "111")); //null
System.out.println(map.putIfAbsent("1", "222")); //111 => 在覆盖的时候才会是原来的
System.out.println(map.put("3", "333")); //null
System.out.println(map.get("1")); //222
System.out.println(map.get("4")); //null
System.out.println(map.remove("3")); //333 => 有映射关系才会返回value
System.out.println(map.remove("4")); //null
}我们总结一下Map接口里面的方法
put:如果该Map中没有该key对应的key-value映射关系时,建立key-value映射关系,并返回null;如果该Map中有了该key对应的key-value映射关系时,就会用现在的value替换原来的value,并返回原来的value。get:如果该Map中没有该key对应的key-value映射关系时,返回null,否则返回key映射的value。remove():如果该Map中没有该key对应的key-value映射关系时,返回null,否则移除这个key-value映射,并返回value。putIfAbsent:和put一样,就是有一点:如果该Map中有了该key对应的key-value映射关系时,不会进行替换操作,并且返回原来的value。源码见下:
default V putIfAbsent(K key, V value) {
V v = get(key);
if (v == null) {
v = put(key, value);
}
return v;
}还有一些比较基本的用法:
Map<Integer, Integer> map = new HashMap<>();
map.put(1, 111);
map.put(2, 222);
map.put(3, 333);
map.put(4, 444);
map.put(5, 555);
map.compute(5, new BiFunction<Integer, Integer, Integer>() {
@Override
public Integer apply(Integer key, Integer value) {
return key * value;
}
});
map.forEach((key, value) -> System.out.println(key + " " + value));上面的代码执行效果:
1 111
2 222
3 333
4 444
5 2775当改为这样的代码之后:
map.compute(6, new BiFunction<Integer, Integer, Integer>() {
@Override
public Integer apply(Integer key, Integer value) {
return key * value;
}
});居然出错了:
java.lang.NullPointerException
at MapTest$1.apply(MapTest.java:42)
at MapTest$1.apply(MapTest.java:39)
at java.util.HashMap.compute(HashMap.java:1188)
at MapTest.testCompute(MapTest.java:39)
所以我们再看看 compute的源码:
default V compute(K key,BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
V oldValue = get(key);
V newValue = remappingFunction.apply(key, oldValue);
if (newValue == null) {
// delete mapping
if (oldValue != null || containsKey(key)) {
// something to remove
remove(key); // 若BiFunction返回Null,就会把原来的key-value移除
return null;
} else {
// nothing to do. Leave things as they were.
return null;
}
} else {
// add or replace old mapping
put(key, newValue);
return newValue;
}
}之后执行那行代码中,可以看到,在BiFunction里面的2个参数,就是compute的第一个参数对应的key-value的键值对,所以在执行key*value的时候就出错了,对于compute,它的用处是:对于一个存在的key-value进行计算,然后返回新的value值,替换原来的value。
还有最后一个小的用法:
@Test
public void testMerge() {
Map<Integer, Integer> map = new HashMap<>();
map.put(1, 111);
map.put(2, 222);
map.put(3, 333);
map.put(4, 444);
map.put(5, 555);
//当key存在返回 1234 不存在就返回 key * value
map.merge(7, 1234, (key, value) -> key * value);
map.forEach((key, value) -> System.out.println(key + " " + value));
}上面说的很清楚看看merge源码
default V merge(K key, V value,BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
Objects.requireNonNull(value);
V oldValue = get(key);
V newValue = (oldValue == null) ? value :
remappingFunction.apply(oldValue, value);
if(newValue == null) {
remove(key); // 若BiFunction返回Null,就会把原来的key-value移除
} else {
put(key, newValue);
}
return newValue;
}注意:remove(key); // 若BiFunction返回Null,就会把原来的key-value移除这行代码。
HashMap
这个算是本文的重点了。先上一个图(图片来源),等下要说:

看下类声明:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable可以看出,HashMap实现了Map接口,并且继承了AbstractMap。这个类大家可以自己看,没什么难度,就是比较繁琐。
其次我们了解HashMap的第一个成员变量:
private static final long serialVersionUID = 362498820763181265L;
transient Node<K,V>[] table;
transient Set<Map.Entry<K,V>> entrySet;
transient int size;
transient int modCount;好吧,我承认,这个serialVersionUID和HashMap实现没有什么太大的关系,但是我们还是要说一哈,下面四个属性,就是用来存储HashMap的数据的。但是transient关键字就限制了这些变量不能被序列化,这可怎么办呢?别慌,有解决方案:
private void writeObject(java.io.ObjectOutputStream s) throws IOException;
private void readObject(java.io.ObjectInputStream s) throws IOException,ClassNotFoundException;这2个方法里面,就主动的将HashMap序列化啦。在writeObject里面会调用这个方法:
// Called only from writeObject, to ensure compatible ordering.
void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {
Node<K,V>[] tab;
if (size > 0 && (tab = table) != null) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
s.writeObject(e.key);
s.writeObject(e.value);
}
}
}
}也就说明,把Node的键值对都拆开去序列化。
下面第二个变量:
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;DEFAULT_INITIAL_CAPACITY :默认的bucket的默认容量,也就是HashMap里面的数组的默认的个数。
MAXIMUM_CAPACITY:能够存储数据的最大个数。
注意:MUST be a power of two.这是为啥?等下再说咯。。。。。
既然,HashMap是使用hash算法来的,那么我们先看看怎么实现的:
- 首先当我们
put一个对象进去后,首先将key进行hash,然后再对这个hash进行掩码运算,将32位的hash值映射到一个个的bucket上;最后在这个bucket里面存放这个数据的value。 - 如果这个地方有存放其他对象了,也就是说明这2个对象的hash值相等,这里用链地址法来解决冲突。
put方法调用后,首先进行hash
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length); //计算 hash & table.length - 1的交运算 => i为在数组的索引
//顺着一个Bucket遍历链表 然后把新的数据插到链表末段
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//覆盖原来的值
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}下面看看hash函数(其实这么多位运算我也不是很懂)hash算法产生的不是定长的int类型,但是和length - 1求并之后,会映射在数组之上,,所以会把这些数据存在一个length的数组之上:
final int hash(Object k) {
int h = 0;
if (useAltHashing) {
if (k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h = hashSeed;
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}然后还有一个函数也是很重要的:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}在indexFor这个函数里面,计算hash与length - 1的交运算,正好就把hash映射在[0,length - 1)的所有空间之上,这是掩码的知识,可以看Mask,
由于length正好是2的n次幂,所有正好可以一一映射过去,即减少了hash地址的冲突。下面这个例子很好的说明了这一点(来源):
当 length 总是 2 的倍数时,h & (length-1)将是一个非常巧妙的设计:假设 h=5,length=16, 那么 h & length - 1 将得到 5;如果 h=6,length=16, 那么 h & length - 1 将得到 6 ……如果 h=15,length=16, 那么 h & length - 1 将得到 15;但是当 h=16 时 , length=16 时,那么 h & length - 1 将得到 0 了;当 h=17 时 , length=16 时,那么 h & length - 1 将得到 1 了……这样保证计算得到的索引值总是位于 table 数组的索引之内。

扩容:
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;这2个属性用来控制HashMap的bucket的数量,当bucket的负载超过一个阈值时就会扩充,而这个阈值就是 capacity * loadFactor,下面我们看看怎么put的:
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
//当数据容量大于阈值的时候,就resize
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
/**
* Like addEntry except that this version is used when creating entries
* as part of Map construction or "pseudo-construction" (cloning,
* deserialization). This version needn't worry about resizing the table.
*
* Subclass overrides this to alter the behavior of HashMap(Map),
* clone, and readObject.
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}在上面可以看到threshold,而阈值的创建在构造函数和resize函数里面,当 threshold < capacity * loadFactor,就会把threshold与capacity扩大为原来的2倍。注意是扩大2倍哦。
threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);那么怎么扩容呢?就是这样。。因为扩容相当的消耗时间,所以一个好的负载因子是非常重要的。为什么说消耗时间呢?因为如果rehash的话,就会重新计算Map所有的元素重新计算hash,然后重新插入到新的bucket里面去。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() && (newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
transfer(newTable, rehash);
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}最后补充一点:在Java8里面,当一个bucket的数据太多(>= 6)的时候(也就是说很多元素的hash值都是一样的时候,链表就会变为红黑树)。
fast-fail机制
我们知道java.util.HashMap不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了 map,那么将抛出 ConcurrentModificationException,这就是所谓 fail-fast 策略。
这一策略在源码中的实现是通过 modCount 域,modCount 顾名思义就是修改次数,对 HashMap 内容(当然不仅仅是HashMap才会有,其他例如 ArrayList 也会)的修改都将增加这个值(大家可以再回头看一下其源码,在很多操作中都有 modCount++这句),那么在迭代器初始化过程中会将这个值赋给迭代器的 expectedModCount。
HashIterator() {
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
}
}if (modCount != expectedModCount)
throw new ConcurrentModificationException();在 HashMap的 API 中指出:
由所有 HashMap 类的“collection 视图方法”所返回的迭代器都是快速失败的:在迭代器创建之后,如果从结构上对映射进行修改,除非通过迭代器本身的 remove 方法,其他任何时间任何方式的修改,迭代器都将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就会完全失败,而不冒在将来不确定的时间发生任意不确定行为的风险。
注意,迭代器的快速失败行为不能得到保证,一般来说,存在非同步的并发修改时,不可能作出任何坚决的保证。快速失败迭代器尽最大努力抛出 ConcurrentModificationException。因此,编写依赖于此异常的程序的做法是错误的,正确做法是:迭代器的快速失败行为应该仅用于检测程序错误。
TreeMap
个人感觉,既然了解Map,TreeMap还是很简单的。TreeMap采用红黑树来实现了树(所以内部实现了排序),可以调用下面一些方法:
public NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive,K toKey, boolean toInclusive)
public Set<K> keySet()
public NavigableSet<K> descendingKeySet()
public NavigableMap<K,V> headMap(K toKey, boolean inclusive)
public NavigableMap<K,V> tailMap(K fromKey, boolean inclusive)
public K firstKey()
public K lastKey()LinkedHashMap
继承HashMap,拥有HashMap的性质,但是内部的bucket采用链表存储数据,所以插入,删除数据比较轻便,但查找就比较耗时间了,但是迭代访问还是快些。(拓展一哈:LinkedHashMap 的构造函数提供了accessOrder参数,true 表示按照insertion-order 插入顺序排序,false表示按照access-order,即LRU进行排序)
大家可以参考这里:http://wiki.jikexueyuan.com/project/java-collection/linkedhashmap.html
Set
Set就是靠Map实现的,Set存储的是Map的key。Set的value用占位符来表示。
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();Set也分了几种,HashSet,LinkedHashSet,TreeSet。对应上面的几种Map。对于 HashSet 中保存的对象,请注意正确重写其 equals 和 hashCode 方法,以保证放入的对象的唯一性。
邮箱:1906362072@qq.com















 1928
1928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









