






对象拷贝
61. 为什么要使用克隆?
想对一个对象进行处理,又想保留原有的数据进行解释下来的操作,就需要克隆了,Java 语言中克隆针对的是类的实例。
62. 如何实现对象克隆?
有两种方式:
1)实现 Cloneable 接口并重写 Object 类中的 clone() 方法;
2)实现 Serializable 接口,通过对象的序列化和反序列话实现克隆,可以真正的实现深度克隆,代码如下:
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class MyUtil {
private MyUtil() {
throw new AssertionError();
}
@SuppressWarnings("unchecked")
public static <T extends Serializable> T clone(T obj) throws Exception {
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bout);
oos.writeObject(obj);
ByteArrayInputStream bin = new ByteArrayInputStream(bout.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bin);
return (T) ois.readObject();
// 说明:调用ByteArrayInputStream或ByteArrayOutputStream对象的close方法没有任何意义
// 这两个基于内存的流只要垃圾回收器清理对象就能够释放资源,这一点不同于对外部资源(如文件流)的释放
}
}下面是测试代码:
import java.io.Serializable;
/**
* 人类
* @author nnngu
*
*/
class Person implements Serializable {
private static final long serialVersionUID = -9102017020286042305L;
private String name; // 姓名
private int age; // 年龄
private Car car; // 座驾
public Person(String name, int age, Car car) {
this.name = name;
this.age = age;
this.car = car;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Car getCar() {
return car;
}
public void setCar(Car car) {
this.car = car;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + ", car=" + car + "]";
}
}
/**
* 小汽车类
* @author nnngu
*
*/
class Car implements Serializable {
private static final long serialVersionUID = -5713945027627603702L;
private String brand; // 品牌
private int maxSpeed; // 最高时速
public Car(String brand, int maxSpeed) {
this.brand = brand;
this.maxSpeed = maxSpeed;
}
public String getBrand() {
return brand;
}
public void setBrand(String brand) {
this.brand = brand;
}
public int getMaxSpeed() {
return maxSpeed;
}
public void setMaxSpeed(int maxSpeed) {
this.maxSpeed = maxSpeed;
}
@Override
public String toString() {
return "Car [brand=" + brand + ", maxSpeed=" + maxSpeed + "]";
}
}class CloneTest {
public static void main(String[] args) {
try {
Person p1 = new Person("郭靖", 33, new Car("Benz", 300));
Person p2 = MyUtil.clone(p1); // 深度克隆
p2.getCar().setBrand("BYD");
// 修改克隆的Person对象p2关联的汽车对象的品牌属性
// 原来的Person对象p1关联的汽车不会受到任何影响
// 因为在克隆Person对象时其关联的汽车对象也被克隆了
System.out.println(p1);
} catch (Exception e) {
e.printStackTrace();
}
}
}注意:基于序列化和反序列化实现的克隆不仅仅是深度克隆,更重要的是通过泛型限定,可以检查出要克隆的对象是否支持序列化,这项检查是编译器完成的,不是在运行时抛出异常,这种是方案明显优于使用Object类的clone方法克隆对象。让问题在编译的时候暴露出来总是好过把问题留到运行时。
63. 深拷贝和浅拷贝的区别是什么?
- 浅拷贝只是复制了对象的引用地址,两个对象指向同一个内存地址,所以修改其中任意的值,另一个值都会随之变化,这就是浅拷贝(例:assign())
- 深拷贝是将对象及值复制过来,两个对象修改其中任意的值另一个值不会改变,这就是深拷贝(例:JSON.parse()和JSON.stringify(),但是此方法无法复制函数类型 )
Java Web
64. jsp 和 servlet 有什么区别?
- jsp 经编译后就变成了 Servlet 。(JSP 的本质就是 Servlet,JVM 只能识别 Java 的类,不能识别 JSP 的代码,Web 容器将 JSP 的代码编译成 JVM 能够识别的 Java 类)
- jsp 更擅长表现于页面显示,servlet 更擅长于逻辑控制。
- Servlet 中没有内置对象,Jsp中的内置对象都是必须通过 HttpServletRequest 对象,HttpservletResponse 对象以及 HttpServlet 对象得到。
- Jsp 是 Servlet 的一种简化,使用 Jsp 只需要完成程序员输出到客户端的内容,Jsp 中的 Java 脚本如何镶嵌到一个类中,由 Jsp 容器完成。而 Servlet 则是个完整的 Java 类,这个类的 Service 方法用于生成对客户端的响应。
65. jsp 有哪些内置对象?作用分别是什么?
Jsp有9个内置对象:
- request:封装客户端的请求,其中包含来自GET或POST请求的参数;
- response:封装服务器对客户端的相应;
- pageContext:通过该对象可以获取其他对象;
- session:封装用户会话的对象;
- application:封装服务器运行环境的对象;
- out:输出服务器响应的输出流对象;
- config:Web应用的配置对象;
- page:JSP页面本身(相当于 Java 程序中的 this);
- exception:封装页面抛出异常的对象。
66. 说一下 jsp 的 4 种作用域?
JSP的四种作用域包括 page、request、session 和 application,具体来说:
- page 代表与一个页面相关的对象和属性。
- request 代表与 Web 客户机发出的一个请求相关性的对象和属性。一个请求可能跨越多个页面,涉及多个 Web 组件;需要在页面显示的临时数据可以置于此作用域。
- session 代表与某个用户与服务器建立的一次会话相关的对象和属性。跟某个用户相关的数据应该放在用户自己的 session 中。
- application 代表与整个 Web 应用程序相关的对象和属性,它实质上是个跨越整个 Web 应用程序,包括多个页面、请求和会话的一个全局作用域。
67. session 和 cookie 有什么区别?
- 由于 HTTP 协议是无状态协议,所以服务端要记录用户的状态时,就需要用某种机制来识别具体的用户,这个机制就是 Session。典型的场景比如购物车,当你点击下单按钮时,由于 HTTP 协议无状态,所以并不知道是那个用户操作的,所以服务端要为特定的用户创建了特定的 Session,用于标识这个用户,并且跟踪用户,这样才知道购物车里面有几本书。这个 Session 是保存在服务端的,有一个唯一标识。在服务端保存 Session 的方法很多,内存、数据库、文件都有。集群的时候也要考虑 Session 的转移,在大型的网址,一般会有专门的 Session 服务器集群,用来保存用户会话,这个时候 Session 信息都是放在内存的,使用一些缓存服务比如 Memcached 子类的来放 Session。
- 思考一下服务端如何识别特定的客户?这个时候 Cookie 就登场了。每次 HTTP 请求的时候,客户端都会发送相应的 Cookie 信息到服务端。实际上大多数的应用都是 Cookie 来实现 Session 跟踪的,第一次创建 Session 的时候,服务端会在 HTTP 协议中告诉客户端,需要在 Cookie 里面记录一个 Session ID,以后每次请求把这个会话 ID 发送到服务器,我就知道你是谁了。有人问,如果客户端的浏览器禁用了 Cookie 怎么办?一般这种情况下,会使用一种叫做 URL 重写的技术来进行会话跟踪,即每次 HTTP 交互,URL 后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。
- Cookie 其实还可以用在一些方便用户的场景下,设想你某次登录过一个网站,下次登录的时候不想再次输入账号了,怎么办?这个信息可以写到 Cookie 里面,访问网站的时候,网站页面的脚本可以读取这个信息,就自动帮你把用户名给填了,能方便一下用户。这也是 Cookie 名称的由来,给用户一点甜头。所以,总结一下:Session 是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;Cookie 是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现 Session 的一种方式。
68. 说一下 session 的工作原理?
其实 session 是一个存在服务器上的类似于一个散列表格的文件。里面存有我们需要的信息,在我们需要用的时候可以从里面取出来。类似于一个大号的 map,里面的键存储的是用户的 sessionid。这时就可以从中取出对应的值了。
69. 如果客户端禁止 cookie 能实现 session 还能用吗?
Cookie 与 Session,一般认为是两个独立的东西,Session 采用的是在服务器端保持状态的方案,而 Cookie 采用的是在客户端保持状态的方案。但为什么禁用 Cookie 就不嗯能够得到 Session 呢?因为 Session 是用 Session ID 来确定当前对话所对应的服务器 Session,而 Session ID 是通过 Cookie 来传递的,禁用 Cookie 相当于失去了 Session ID,也就得不到 Session 了。
假定用户关闭 Cookie 的情况下使用 Session,其实现途径有以下几种:
- 设置 php.ini 配置文件中的 ''session.use_trans_sid = 1'',或者编译时打开了 ''--enable-trans-sid'' 选项,让 PHP 自动跨页传递 Session ID。
- 手动通过URL 传值、隐藏表单传递 Session ID。
- 用文件、数据库等形式保存 Session ID,在跨页过程中手动调用。
70. spring mvc 和 struts 的区别是什么?
1. 拦截机制的不同
Struts2 是类级别的拦截,每次请求就会创建一个 Action,和 Spring 整合时 Struts2 的 ActionBean 注入作用域是原型模式 prototype,然后通过 setter,getter 吧 request 数据注入到属性。Struts2 中,一个 Action 对应一个 request,response 上下文,在接收参数时,可以通过属性接收,这说明属性参数是让多个方法共享的。Struts2 中 Action 的一个方法可以对应一个 url,而其类属性却被所有方法共享,这也就无法用注解或其他方式标识其属性方法了,只能设计为多利。
SpringMVC 是方法级别的拦截,一个方法对应一个 Request 上下文,所以方法直接基本上是独立的,独享 request,response 数据。而每个方法同时又何一个 url 对应,参数的传递是直接注入到方法中的,是方法独有的。处理结果通过 ModeMap 返回给框架。在 Spring 整合时,SpringMVC 的 Controller Bean 默认是单例模式 Singleton,所以默认对所有的请求,只会创建一个 Controller,有应为没有共享的属性,所以是线程安全的,如果要改变默认的作用域,需要添加 @Scope 注解修改。
Struts2 有自己的拦截 Interceptor 机制,SpringMVC 这是用的是独立的 Aop 方式,这样导致 Struts2 的配置文件还是比 SpringMVC 大。
2. 底层的框架不同
Struts2 采用 Filter(StrutsPrepareAndExecuteFilter )实现,SpringMVC(DispatcherServlet )则采用 Serlet 实现。Filter在容器启动之后即初始化;服务停止以后坠毁,晚于 Servlet。servlet 在调用时初始化,优先于 Filter 调用,服务停止后销毁。
3. 性能方面
Struts2 是类级别的拦截,北侧请求对应实例一个新的 Action,需要加载所有的属性值注入,SpringMVC 实现了零配置,由于 SpringMVC 基于方法的拦截,有加载一次单例模式 bean 注入。所以,SpringMVC开发效率和性能高于 Sturts2.
4. 配置方面
Spring MVC 和 Spring 是无缝的。从这个项目的管理和安全性上也比 Struts2 高。
71. 如何避免 sql 注入?
- PreparedStatement(简单又有效的方法)
- 使用正则表达式过滤传入的参数
- 字符串过滤
- JSP 中调用该函数检查是否包含非法字符
- JSP 页面判断代码
72. 什么是 XSS 攻击,如何避免?
XSS 攻击 又称 CSS,全称 Cross Site Script(跨站脚本攻击),其原理是攻击者向有 XSS 漏洞的网站中输入而已的 HTML 代码,当用户浏览该网站时,这段 HTML 代码会自动执行,从而达到攻击的目的。XSS 攻击类似于 SQL 注入攻击,SQL 注入攻击中以 SQL 语句作为用户输入,从而达到查询/修改/删除数据的目的,而在 XSS 攻击中,通过插入恶意脚本,实现对用户浏览器的控制,获取用户的一些信息。XSS 是 Web 程序中常见的漏洞,XSS 属于被动式并且用于客户端的攻击方式。
XSS 防范的总体思路是:对输入(和 URL 参数)进行过滤,对输出进行编码。
73. 什么是 CSRF 攻击,如何避免?
CSRF(Cross-site request forgery)也被称为 noe-click attack 或者 session riding,中文全称是叫跨站请求伪造。一般来说,攻击者通过伪造用户的浏览器的请求,向访问一个用户自己曾经认证访问过的网站发送出去,使目标网站接受并误以为是用户的真实操作而去执行命令。常用于盗取账号、转账、发送虚假消息等。攻击者利用网站对请求的验证漏洞而实现这样的攻击行为,网站能够确认请求来源于用户的浏览器,却不能验证请求是否源于用户的真实意愿下的操作行为。
1)如何避免:
1. 验证 HTTP Refere 字段
HTTP 头中的 Referer 字段记录了该 HTTP 请求的来源地址。在通常情况下,访问一个受限页面的请求来源于同一个网站,而如果黑客要对其实施 CSRF 攻击,他一般只能在自己的网站构造请求。因此,可以通过验证 Referer 值来防御 CSRF 攻击。
2. 使用验证码
关键操作页面加上验证码,后台收到请求后通过判断验证码可以防御 CSRF 。但这种方法对用户不太友好。
3. 在请求地址中添加 token 并验证
CSRF 攻击之所以能够成功,是因为黑客可以完全伪造用户的请求,该请求中所有的用户验证信息都是存在于 cookie 中,因此黑客可以在不知道这些验证信息的情况下直接利用用户自己的 cookie 来通过安全验证。要抵御 CSRF,关键在于请求中放入黑客所不能伪造的信息,并且该信息不存在于 cookie 之中。可以在 HTTP 请求中没有 token 或者 token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。这种方法要比检查 Refere 要安全一些,token 可以在用户登录后产生并放于 session 之中,然后在每次请求时把 token 从 session 中拿出,与请求中的 token 进行比对,但这种方法的难点在于如何把 token 以参数的形式加入请求。
对于 GET 请求,token 将附在请求地址之后,这样 URL 就变成 http://url?csrftoken=tokenvalue。
而对于 POST 来说,要在 form 的最后加上 <input type="hidden" name="csrftoken" value="tokenvalue"/>,这样就可以吧 token 以参数的形式加入请求了。
4. 在 HTTP 头中自定义属性并验证
这种方法也是使用 token 并进行验证,和上一种方法不同的是,这里并不是把 token 以参数的形式置于 HTTP 请求之中,而是把它放到 HTTP 头中自定义属性里。通过 XMLHttpRequest 这个类,可以一次性给所有该类加上 csrftoken 这个 HTTP 头属性,并把 token 值放入其中。这样解决了上种方法在请求中加入 token 的不便,同时,通过 XMLhttpRequest 请求的地址不会被记录到浏览器的地址栏,也不用担心 token 会透过 Referer 泄露到其他网站中去。
异常
74. throw 和 throws 的区别?
throws 是用来声明一个方法可能抛出的所有异常信息,throws 是将异常声明但是不处理,而是将异常往上传,谁调用就交给谁去处理。而 throw 则是指抛出一个具体的异常类型。
75. final、finally、finalize 有什么区别?
- final 可以修饰类,变量、方法,修饰类表示该类不能被继承,修饰方法表示方法不能被重写,修饰变量表示该变量是一个常量不能被重新赋值。
- finally 一般作用在 try-catch 代码块中,在处理该异常的时候,通常我们将一定要执行的方法 finally 代码块中,表示不管是否出现异常,改代码块都会执行,一般用来存放一些关闭资源的代码。
- finalize 是一个方法,属于 Object 类中的一个方法,而 Object 类是所有类的父类,该方法一般由垃圾回收器来调用,当我们调用 System 的 gc() 方法的时候,有垃圾回收器调用 finalize(),回收垃圾。
76. try-catch-finally 中哪个部分可以省略?
答:catch 可以省略
原因:
更为严格的说法其实是:try 只适合处理运行时异常,try-catch 适合处理运行时异常+普通异常。也就是说,如果你只用 try 去处理普通异常却不加以 catch处理,编译是不通过的,因为编译器硬性规定,普通异常如果选择捕获,则必须用 catch 显示声明以便进一步处理。而运行时异常在编译时没有如此规定,所以 catch 可以省略,你加上 caych 编译器也觉得无可厚非。
理论上,编译器看任何代码都不顺眼,都觉得可能有潜在的问题,所以你即使对所有代码加上 try,代码在运行期也只不过是在正常运行的基础上加一成皮。但是你一旦对一段代码加上 try,就等于显示地承诺编译器,对这段代码可能抛出的异常进行捕获而非向上抛出处理。如果是普通异常,编译器要求必须用 catch 捕获以便进一步处理;如果运行时异常,捕获然后丢弃并且 +finally 扫尾处理,或者加上 catch 捕获以便进一步处理。
至于加上 finally,则是不管有没有捕获异常,都要进行的''扫尾''处理。
77. try-catch-finally 中,如果 catch 中 retrun 了,finally 还会执行吗?
答:会执行,在 retrun 前执行。
代码示例1:
/*
* java面试题--如果catch里面有return语句,finally里面的代码还会执行吗?
*/
public class FinallyDemo2 {
public static void main(String[] args) {
System.out.println(getInt());
}
public static int getInt() {
int a = 10;
try {
System.out.println(a / 0);
a = 20;
} catch (ArithmeticException e) {
a = 30;
return a;
/*
* return a 在程序执行到这一步的时候,这里不是return a 而是 return 30;这个返回路径就形成了
* 但是呢,它发现后面还有finally,所以继续执行finally的内容,a=40
* 再次回到以前的路径,继续走return 30,形成返回路径之后,这里的a就不是a变量了,而是常量30
*/
} finally {
a = 40;
}
// return a;
}
}执行结果:30
代码示例2:
/*
* java面试题--如果catch里面有return语句,finally里面的代码还会执行吗?
*/
public class FinallyDemo2 {
public static void main(String[] args) {
System.out.println(getInt());
}
public static int getInt() {
int a = 10;
try {
System.out.println(a / 0);
a = 20;
} catch (ArithmeticException e) {
a = 30;
return a;
/*
* return a 在程序执行到这一步的时候,这里不是return a 而是 return 30;这个返回路径就形成了
* 但是呢,它发现后面还有finally,所以继续执行finally的内容,a=40
* 再次回到以前的路径,继续走return 30,形成返回路径之后,这里的a就不是a变量了,而是常量30
*/
} finally {
a = 40;
return a; //如果这样,就又重新形成了一条返回路径,由于只能通过1个return返回,所以这里直接返回40
}
// return a;
}
}执行结果:40
78. 常见的异常类有哪些?
- NullPointerException:当应用程序试图访问空对象时,则抛出该异常。
- SQLExecption:提供关于数据库访问错误或其他错误信息的异常。
- IndexOutOfBoundsException:指示某排序
- NumberFormatExceptin:指示某排序索引(例如对数组、字符串或向量的排序)超出范围时,抛出该异常。
- FileNotFoundException:当试图打开指定路径名表示的文件失败时,抛出异常。
- IOException:当发生某种I/O异常时,抛出此异常。此类是失败或中断的I/O操作生成的异常的通用类。
- ClassCastException:当发生某种I/O异常时,抛出此异常。
- ArrayStoreException:试图将错误类型的对象储存到一个对象数组时抛出的异常。
- IllegalArgumentException:抛出的异常表明向方法传递了一个不合法或不正确的参数。
- ArithmeticException:当出现异常的运算条件时,抛出此异常。例如,一个整数''除以零''是,抛出此类的一个实例。
- NegativeArraySizeException:如果应用程序试图创建大小为负的数组,则抛出该异常。
- NoSuchMethodException:无法找到某一特定方法时,抛出该异常。
- SecurityException:由安全管理器抛出的异常,指示存在安全侵犯。
- UnsupportedOperationException:当不支持请求的操作时,抛出该异常。
- RuntimeExceptionRuntimeException:是那些可能在Java虚拟机正常运行期间抛出的异常的超类。
网络
79. http 响应码 301 和 302 代表的是什么?有什么区别?
答:301,302都是 HTTP 状态的编码,的都代表着某个 URL 发生了转移。
区别:
- 301 redirect:301 代表永久性转移(Permanently Moved)。
- 302 redirect:302 代表暂时性转移(Temporarily Moved)。
80. forward 和 redirect 的区别?
Forward 和 Redirect 代表了两种请求转发方式:直接转发和间接转发。
直接转发方式(Forward),客户端和浏览器只发出一次请求,Servlet、HTML、Jsp 或其它信息资源,由第二个信息资源响应该请求,在请求对象 request 中,保存的对象对于每个信息资源是共享的。
间接转发方式(Redirect)实际是两次 HTTP 请求,服务器端在响应第一次请求的时候,让浏览器再向另外一个 URL 发出请求,从而达到转发的目的。
举个通俗的例子:
直接转发就相当于:“A找B借钱,B说没有,B去找C借,借到借不到都会把消息传递给A”;
间接转发就相当于:"A找B借钱,B说没有,让A去找C借"。
81. 简述 tcp 和 udp 的区别?
- TCP 面向连接(如打电话要先拨号建立连接);UDP 是无连接的,即发送数据之前不需要建立。
- TCP 提供可靠的服务。也就是说,通过TCP 连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP 尽最大努力,既不保证可靠交付。
- TCP 通过校验和,重传控制,序号表示,滑动窗口,确认应答实现可靠传输。如掉包时的重发控制,还可以对次序乱掉的分包进行顺序控制。
- UDP 具有较好是实时性,工作效率比 TCP 高,适用于高速传输和实时性有较高的通信或广播通信。
- 每一条 TCP 连接只能是点到点的,UDP 支持一对一,一对多,多对一和多对多的交互通信。
- TCP 对系统资源要求较多,UDP 对系统资源要求较小
82. tcp 为什么要三次握手,两次不行吗?为什么?
为了实现可靠数据传输,TCP 协议的通信双方,都必须维护一个序列号,以标识发送出去的数据包中,那些是已经被对方收到的。三次握手的过程既是通信双方互相告知序列号起始值,并确认对方已经收到序列号的起始值的必经步骤。
如果只是两次握手,至多只有连接方发起的序列号能被确认,另一方的序列号则得不到确认。
83. 说一下 tcp 粘包是怎么产生的?
①.发送方产生粘包
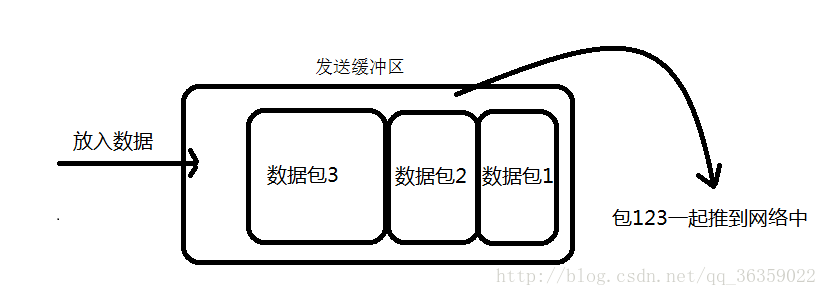
采用TCP协议传输数据的客户端与服务器经常是保持一个长连接的状态(一次连接发一次数据不存在粘包),双方在连接不断开的情况下,可以一直传输数据;但当发送的数据包过于的小时,那么TCP协议默认的会启用Nagle算法,将这些较小的数据包进行合并发送(缓冲区数据发送是一个堆压的过程);这个合并过程就是在发送缓冲区中进行的,也就是说数据发送出来它已经是粘包的状态了。
②. 接收方产生粘包
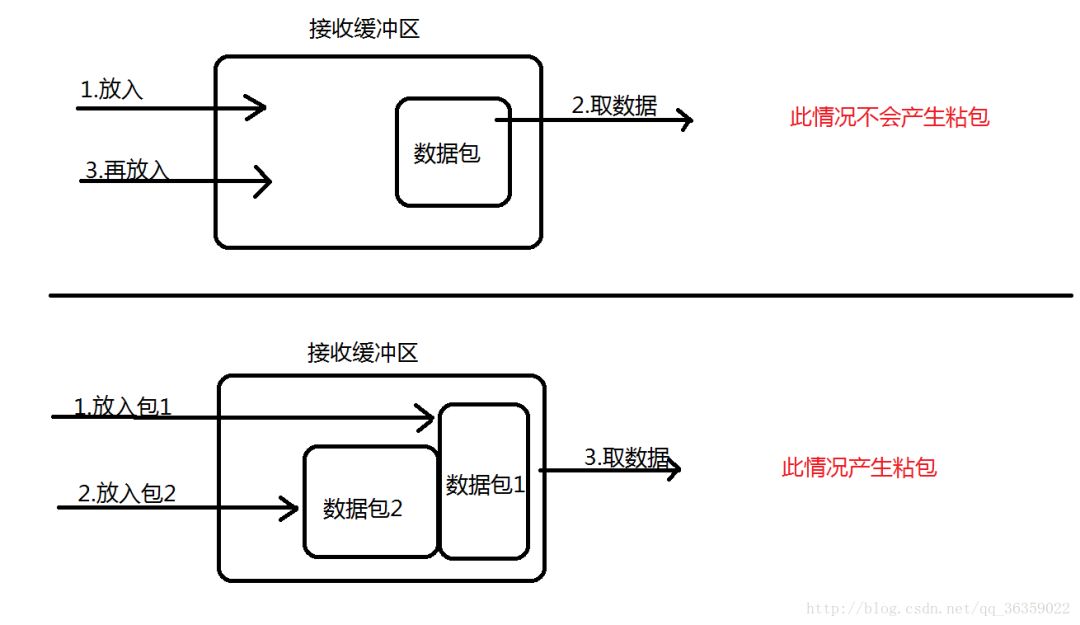
接收方采用TCP协议接收数据时的过程是这样的:数据到底接收方,从网络模型的下方传递至传输层,传输层的TCP协议处理是将其放置接收缓冲区,然后由应用层来主动获取(C语言用recv、read等函数);这时会出现一个问题,就是我们在程序中调用的读取数据函数不能及时的把缓冲区中的数据拿出来,而下一个数据又到来并有一部分放入的缓冲区末尾,等我们读取数据时就是一个粘包。(放数据的速度 > 应用层拿数据速度)
84. OSI 的七层模型都有哪些?
-
应用层:网络服务与最终用户的一个接口。
-
表示层:数据的表示、安全、压缩。
-
会话层:建立、管理、终止会话。
-
传输层:定义传输数据的协议端口号,以及流控和差错校验。
-
网络层:进行逻辑地址寻址,实现不同网络之间的路径选择。
-
数据链路层:建立逻辑连接、进行硬件地址寻址、差错校验等功能。
-
物理层:建立、维护、断开物理连接。
85. get 和 post 请求有哪些区别?
- GET 在浏览器回退时是无害的,而 POST 会再次提交请求。
- GET 产生的 URL 地址可以被 Bookmark,而 POST 不可以。
- GET 请求会被浏览器主动 cache,而 POST 不会,除非手动设置。
- GET 请求只能进行 url 编码,而 POST 支持多种编码形式。
- GET 请求参数会被完整保留在浏览器历史记录里,而 POST 中的参数不会被保留。
- GET 请求在 URL 中传送的参数是有长度限制的,而POST没有。
- 对参数的数据类型,GET 只接受 ASCLL 字符,而 POST 没有限制。
- GET 比 POST 更不安全,因为参数直接暴露在 URL 上,所以不能用来传递敏感信息。
- GET 参数通过 URL 传递,POST 放在 Request body 中。
86. 如何实现跨越?
方式一:图片 ping 或 script 标签跨域
图片ping 常用于跟踪用户点击页面或动态广告曝光次数。
script标签 可以得到从其他来源数据,这也是 JSONP 依赖的根据。
方式二:JSONP 跨域
JSONP(JSON with Padding)是数据格式JSON的一种“使用模式”,可以让网页从别的网域要数据。根据 XmlHttpRequest 对象受到同源策略的影响,而利用 <script>元素的这个开放策略,网页可以得到从其他来源动态产生的JSON数据,而这种使用模式就是所谓的 JSONP。用JSONP抓到的数据并不是JSON,而是任意的JavaScript,用 JavaScript解释器运行而不是用JSON解析器解析。所有,通过Chrome查看所有JSONP发送的Get请求都是js类型,而非XHR。
缺点:
-
只能使用Get请求
-
不能注册success、error等事件监听函数,不能很容易的确定JSONP请求是否失败
-
JSONP是从其他域中加载代码执行,容易受到跨站请求伪造的攻击,其安全性无法确保
方式三:CORS
Cross-Origin Resource Sharing(CORS)跨域资源共享是一份浏览器技术的规范,提供了 Web 服务从不同域传来沙盒脚本的方法,以避开浏览器的同源策略,确保安全的跨域数据传输。现代浏览器使用CORS在API容器如XMLHttpRequest来减少HTTP请求的风险来源。与 JSONP 不同,CORS 除了 GET 要求方法以外也支持其他的 HTTP 要求。服务器一般需要增加如下响应头的一种或几种:
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
Access-Control-Max-Age: 86400跨域请求默认不会携带Cookie信息,如果需要携带,请配置下述参数:
"Access-Control-Allow-Credentials": true
// Ajax设置
"withCredentials": true方式四:window.name+iframe
window.name通过在iframe(一般动态创建i)中加载跨域HTML文件来起作用。然后,HTML文件将传递给请求者的字符串内容赋值给window.name。然后,请求者可以检索window.name值作为响应。
-
iframe标签的跨域能力;
-
window.name属性值在文档刷新后依旧存在的能力(且最大允许2M左右)。
每个iframe都有包裹它的window,而这个window是top window的子窗口。contentWindow属性返回<iframe>元素的Window对象。你可以使用这个Window对象来访问iframe的文档及其内部DOM。
<!--
下述用端口
10000表示:domainA
10001表示:domainB
-->
<!-- localhost:10000 -->
<script>
var iframe = document.createElement('iframe');
iframe.style.display = 'none'; // 隐藏
var state = 0; // 防止页面无限刷新
iframe.onload = function() {
if(state === 1) {
console.log(JSON.parse(iframe.contentWindow.name));
// 清除创建的iframe
iframe.contentWindow.document.write('');
iframe.contentWindow.close();
document.body.removeChild(iframe);
} else if(state === 0) {
state = 1;
// 加载完成,指向当前域,防止错误(proxy.html为空白页面)
// Blocked a frame with origin "http://localhost:10000" from accessing a cross-origin frame.
iframe.contentWindow.location = 'http://localhost:10000/proxy.html';
}
};
iframe.src = 'http://localhost:10001';
document.body.appendChild(iframe);
</script>
<!-- localhost:10001 -->
<!DOCTYPE html>
...
<script>
window.name = JSON.stringify({a: 1, b: 2});
</script>
</html>方式五:window.postMessage()
HTML5新特性,可以用来向其他所有的 window 对象发送消息。需要注意的是我们必须要保证所有的脚本执行完才发送 MessageEvent,如果在函数执行的过程中调用了它,就会让后面的函数超时无法执行。
下述代码实现了跨域存储localStorage:
<!--
下述用端口
10000表示:domainA
10001表示:domainB
-->
<!-- localhost:10000 -->
<iframe src="http://localhost:10001/msg.html" name="myPostMessage" style="display:none;">
</iframe>
<script>
function main() {
LSsetItem('test', 'Test: ' + new Date());
LSgetItem('test', function(value) {
console.log('value: ' + value);
});
LSremoveItem('test');
}
var callbacks = {};
window.addEventListener('message', function(event) {
if (event.source === frames['myPostMessage']) {
console.log(event)
var data = /^#localStorage#(\d+)(null)?#([\S\s]*)/.exec(event.data);
if (data) {
if (callbacks[data[1]]) {
callbacks[data[1]](data[2] === 'null' ? null : data[3]);
}
delete callbacks[data[1]];
}
}
}, false);
var domain = '*';
// 增加
function LSsetItem(key, value) {
var obj = {
setItem: key,
value: value
};
frames['myPostMessage'].postMessage(JSON.stringify(obj), domain);
}
// 获取
function LSgetItem(key, callback) {
var identifier = new Date().getTime();
var obj = {
identifier: identifier,
getItem: key
};
callbacks[identifier] = callback;
frames['myPostMessage'].postMessage(JSON.stringify(obj), domain);
}
// 删除
function LSremoveItem(key) {
var obj = {
removeItem: key
};
frames['myPostMessage'].postMessage(JSON.stringify(obj), domain);
}
</script>
<!-- localhost:10001 -->
<script>
window.addEventListener('message', function(event) {
console.log('Receiver debugging', event);
if (event.origin == 'http://localhost:10000') {
var data = JSON.parse(event.data);
if ('setItem' in data) {
localStorage.setItem(data.setItem, data.value);
} else if ('getItem' in data) {
var gotItem = localStorage.getItem(data.getItem);
event.source.postMessage(
'#localStorage#' + data.identifier +
(gotItem === null ? 'null#' : '#' + gotItem),
event.origin
);
} else if ('removeItem' in data) {
localStorage.removeItem(data.removeItem);
}
}
}, false);
</script>注意Safari一下,会报错:
Blocked a frame with origin “http://localhost:10001” from accessing a frame with origin “http://localhost:10000“. Protocols, domains, and ports must match.
避免该错误,可以在Safari浏览器中勾选开发菜单==>停用跨域限制。或者只能使用服务器端转存的方式实现,因为Safari浏览器默认只支持CORS跨域请求。
方式六:修改document.domain跨子域
前提条件:这两个域名必须属于同一个基础域名!而且所用的协议,端口都要一致,否则无法利用document.domain进行跨域,所以只能跨子域
在根域范围内,允许把domain属性的值设置为它的上一级域。例如,在”aaa.xxx.com”域内,可以把domain设置为 “xxx.com” 但不能设置为 “xxx.org” 或者”com”。
现在存在两个域名aaa.xxx.com和bbb.xxx.com。在aaa下嵌入bbb的页面,由于其document.name不一致,无法在aaa下操作bbb的js。可以在aaa和bbb下通过js将document.name = 'xxx.com';设置一致,来达到互相访问的作用。
方式七:WebSocket
WebSocket protocol 是HTML5一种新的协议。它实现了浏览器与服务器全双工通信,同时允许跨域通讯,是server push技术的一种很棒的实现。相关文章,请查看:WebSocket、WebSocket-SockJS
需要注意:WebSocket对象不支持DOM 2级事件侦听器,必须使用DOM 0级语法分别定义各个事件。
方式八:代理
同源策略是针对浏览器端进行的限制,可以通过服务器端来解决该问题
DomainA客户端(浏览器) ==> DomainA服务器 ==> DomainB服务器 ==> DomainA客户端(浏览器)
87. 说一下 JSONP 实现原理?
jsonp 即 json+padding,动态创建script标签,利用script标签的src属性可以获取任何域下的js脚本,通过这个特性(也可以说漏洞),服务器端不在返货json格式,而是返回一段调用某个函数的js代码,在src中进行了调用,这样实现了跨域。
设计模式
88. 所以现在你熟系的设计模式?
89. 简单工厂和抽象工厂有什么区别?
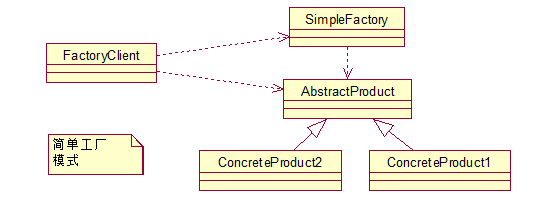
简单工厂模式:
这个模式本身很简单而且使用在业务较简单的情况下。一般用于小项目或者具体产品很少扩展的情况(这样工厂类才不用经常更改)。
它由三种角色组成:
-
工厂类角色:这是本模式的核心,含有一定的商业逻辑和判断逻辑,根据逻辑不同,产生具体的工厂产品。如例子中的Driver类。
-
抽象产品角色:它一般是具体产品继承的父类或者实现的接口。由接口或者抽象类来实现。如例中的Car接口。
-
具体产品角色:工厂类所创建的对象就是此角色的实例。在java中由一个具体类实现,如例子中的Benz、Bmw类。
来用类图来清晰的表示下的它们之间的关系:
抽象工厂模式:
先来认识下什么是产品族: 位于不同产品等级结构中,功能相关联的产品组成的家族。
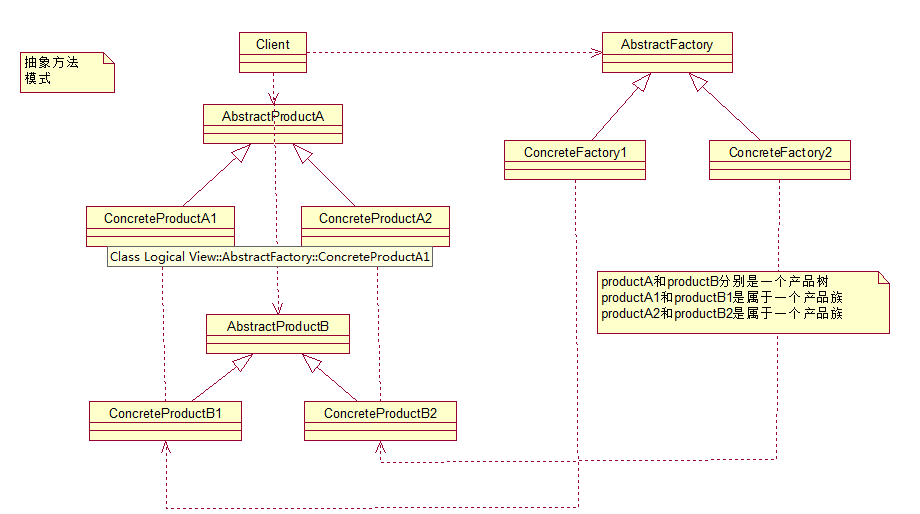
图中的BmwCar和BenzCar就是两个产品树(产品层次结构);而如图所示的BenzSportsCar和BmwSportsCar就是一个产品族。他们都可以放到跑车家族中,因此功能有所关联。同理BmwBussinessCar和BenzBusinessCar也是一个产品族。
可以这么说,它和工厂方法模式的区别就在于需要创建对象的复杂程度上。而且抽象工厂模式是三个里面最为抽象、最具一般性的。抽象工厂模式的用意为:给客户端提供一个接口,可以创建多个产品族中的产品对象。
而且使用抽象工厂模式还要满足一下条件:
-
系统中有多个产品族,而系统一次只可能消费其中一族产品
-
同属于同一个产品族的产品以其使用。
来看看抽象工厂模式的各个角色(和工厂方法的如出一辙):
-
抽象工厂角色: 这是工厂方法模式的核心,它与应用程序无关。是具体工厂角色必须实现的接口或者必须继承的父类。在java中它由抽象类或者接口来实现。
-
具体工厂角色:它含有和具体业务逻辑有关的代码。由应用程序调用以创建对应的具体产品的对象。在java中它由具体的类来实现。
-
抽象产品角色:它是具体产品继承的父类或者是实现的接口。在java中一般有抽象类或者接口来实现。
-
具体产品角色:具体工厂角色所创建的对象就是此角色的实例。在java中由具体的类来实现。
Spring / SpringMVC
90. 为什么要使用 spring?
1.简介
-
目的:解决企业应用开发的复杂性
-
功能:使用基本的JavaBean代替EJB,并提供了更多的企业应用功能
-
范围:任何Java应用
简单来说,Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架。
2.轻量
从大小与开销两方面而言Spring都是轻量的。完整的Spring框架可以在一个大小只有1MB多的JAR文件里发布。并且Spring所需的处理开销也是微不足道的。此外,Spring是非侵入式的:典型地,Spring应用中的对象不依赖于Spring的特定类。
3.控制反转
Spring通过一种称作控制反转(IoC)的技术促进了松耦合。当应用了IoC,一个对象依赖的其它对象会通过被动的方式传递进来,而不是这个对象自己创建或者查找依赖对象。你可以认为IoC与JNDI相反——不是对象从容器中查找依赖,而是容器在对象初始化时不等对象请求就主动将依赖传递给它。
4.面向切面
Spring提供了面向切面编程的丰富支持,允许通过分离应用的业务逻辑与系统级服务(例如审计(auditing)和事务(transaction)管理)进行内聚性的开发。应用对象只实现它们应该做的——完成业务逻辑——仅此而已。它们并不负责(甚至是意识)其它的系统级关注点,例如日志或事务支持。
5.容器
Spring包含并管理应用对象的配置和生命周期,在这个意义上它是一种容器,你可以配置你的每个bean如何被创建——基于一个可配置原型(prototype),你的bean可以创建一个单独的实例或者每次需要时都生成一个新的实例——以及它们是如何相互关联的。然而,Spring不应该被混同于传统的重量级的EJB容器,它们经常是庞大与笨重的,难以使用。
6.框架
Spring可以将简单的组件配置、组合成为复杂的应用。在Spring中,应用对象被声明式地组合,典型地是在一个XML文件里。Spring也提供了很多基础功能(事务管理、持久化框架集成等等),将应用逻辑的开发留给了你。
所有Spring的这些特征使你能够编写更干净、更可管理、并且更易于测试的代码。它们也为Spring中的各种模块提供了基础支持















 1861
1861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









