







查找的概念:
在一些(有序的/无序的)数据元素中,通过一定的方法找出与给定关键字相同的数据元素的过程叫做查找。也就是根据给定的某个值,在查找表中确定一个关键字等于给定值的记录或数据元素。
平均查找长度:
公式: A S L = ∑ i = 1 n p i c i ASL = \sum_{i=1}^{n}p_ic_i ASL=∑i=1npici
其中 p i p_i pi表示查找这个元素的概率, c i c_i ci表示查找到了这个元素的比较次数
通常查找长度还分为成功和失败俩种
A S L 失 败 ASL_{失败} ASL失败 和 A S L 成 功 ASL_{成功} ASL成功
查找的方式:
1. 顺序查找
主要思想:
将查找值顺序逐个与结点值进行比较,相等即为查找成功,否则查找失败.
因此代码也是非常简单的
//假设 变量:x 为带查找的数
int Sqsearch(FIND[], int len, int x)//其中FIND为查找的数组,len为该数组的长度
{
int i = 0;
while(i < len && FIND[i] != x)//当前值和x不匹配
i++;
if(i >= n) return 0;//没有找到
return i + 1;//返回逻辑序号
}
时间复杂度:O(n)
查找成功平均长度: A S L 成 功 = n + 1 2 ASL_{成功} = \frac{n +1}{2} ASL成功=2n+1
查找失败平均长度: A S L 失 败 = n 2 ASL_{失败} = \frac{n}{2} ASL失败=2n
2. 二分查找(折半查找)
因为又叫做折半查找,因此思路就显而易见了,那就是每次比较中间的值和待查找值的大小,然后更新范围,最后确定这个待查找数的具体位置。
注意:因为是通过比较来确定范围,因此这个序列是被要求为有序的
\\在数组FIND中查找, 待查找的数:x, 数组长度:len
int BinSearch(FIND [], int len, int x)
{
int l = 0, r = len - 1;
while(l <= r)
{
int mid = l + (r - l) / 2;//防止溢出,等问题的出现
if(x > FIND[mid]) //因为待查找的数大,所以更新到右半部分
l = mid + 1;
else if(x == FIND[mid]) return mid;
else r = mid - 1; //此时x小于中间值FIND[mid],所以更新到左半部分
}
return -1;//没有找到
}
时间复杂度: l o g 2 n log_2n log2n
折半查找的平均查找长度可以使用 二叉判定树来求解
假设存在列表
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| C i C_i Ci | 3 | 4 | 2 | 3 | 4 | 1 | 3 | 4 | 2 | 3 | 4 |
其中
C
i
C_i
Ci为查找这个需要比较的次数,因此可以得到一个二叉判定树:

因为是二叉树,所以查找不到的数,我们可以把这些树中儿子节点的空出来计算就是他们的查找失败的平均查找长度了
这里只介绍查找成功的平均查找长度:
A S L 成 功 = 1 n ∑ t i m e s ∗ d e e p t h ASL_{成功} = \frac{1}{n} \sum{times} *{deepth} ASL成功=n1∑times∗deepth
其中 times 为查找的某个数比较的次数,deepth为这个数的深度;
例如在上图中, 3 和 9 都是比较 2 次,因此可以直接算出 2 * 2(times 和 deepth都是2)
将找不到的补充出来就可以得到公式
A S L 失 败 = 1 n ∑ f i a l s ∗ d e e p t h ASL_{失败} = \frac{1}{n} \sum{fials} *{deepth} ASL失败=n1∑fials∗deepth
其中 fails 表示找不到数的个数,就是当前某一层的数的空子树之和, deepth非空的数的那一层
例如 1 4 7 10 那一层有4个空子树,那么fials = 4, deepth = 3
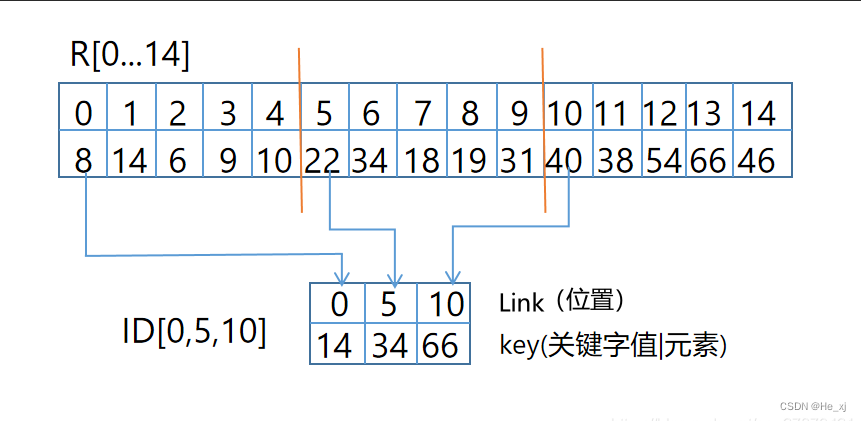
3. 分块查找
分块查找是结合二分查找和顺序查找的一种改进方法。在分块查找里有索引表和分块的概念。
索引表就是帮助分块查找的一个分块依据,其实就是一个数组,用来存储每块的最大存储值,也就是范围上限;分块就是通过索引表把数据分为几块。
基本思想:
(1)把表长为n的线性表分成m块,前m-1块记录个数为 t = n / m t=n/m t=n/m,第m块的记录个数小于等于t;
(2)在每一块中,结点的存放不一定有序,但块与块之间必须是分块有序的;
(3)为实现分块检索,还需建立一个索引表。索引表的每个元素对应一个块,其中包括该块内最大关键字值和块中第一个记录位置的指针。
在每需要增加一个元素的时候,我们就需要首先根据索引表,知道这个数据应该在哪一块,然后直接把这个数据加到相应的块里面,而块内的元素之间本身不需要有序。因为块内无须有序,所以分块查找特别适合元素经常动态变化的情况。
分块查找只需要索引表有序,当索引表比较大的时候,可以对索引表进行二分查找,锁定块的位置,然后对块内的元素使用顺序查找。这样的总体性能虽然不会比二分查找好,却比顺序查找好很多,最重要的是不需要数列完全有序。
typedef struct{
KeyType key;
int link;
}IdxType;
//分两步,先找到所在的块,然后在块中查找
int IdxSearch(IdxType I[], int b, int R[], int len, int k)
{
int s = (n + b - 1) / b; //s 为每个块的元素个数,为 n/b 向下取整
int l = 0, r = b - 1; // b 为块的个数, 使用二分查找来找到数k所在的分块
while(l <= r)
{
int mid = l + (r - l) / 2;
if(I[mid].key >= k) r = mid - 1;
else l = mid + 1;
}
i = I[r + 1].link;
while(i <= I[r + 1].link + s - 1 && R[i] != k)
++i;
if(i <= I[r + 1].link + s - 1) return i + 1;//如果索引值没有越界 返回他的逻辑位置
return -1; //找不到
}
假设分成z块 时间复杂度O(logz + n/z)
查找成功的平均查找长度

4. 树表的查找
二叉排序树:
对于线性查找而言,当查找的数据发生了变化,进行修改的开销是很大的,因此线性查找适合静态查找。对于动态查找而言,用树结构来制作查找表会更为合适,因为动态地操作树结构的结点,开销远比顺序表小得多。
所谓二叉搜索树,也可以称之为二叉排序树,就是基于树结构建立的查找表。对于二叉排序树需要满足一下 3 个条件:
- 左子树为空树或所有的结点值均小于其根结点的值;
- 右子树为空树或所有的结点值均大于其根结点的值;
- 左右子树也统统都是二叉排序树。
同时由于本质上是二叉树,且满足以上性质,因此对一个二叉排序树进行中序遍历,将会得到一个有序序列。例如如图所示二叉排序树:

中序遍历可以得到序列:1 2 3 4 5 6 7
那么就可以求出他的平均查找长度(和二叉判定树类似)
A S L 成 功 = ( 1 + 2 ∗ 2 + 3 ∗ 3 + 4 ) / 6 = 3 ASL_{成功} = (1 + 2 * 2 + 3 * 3 + 4) / 6 = 3 ASL成功=(1+2∗2+3∗3+4)/6=3
A S L 失 败 = ( 2 + 5 ∗ 3 + 2 ∗ 4 ) / 8 = 3.125 ASL_{失败} = (2 + 5 * 3 + 2 * 4) / 8 = 3.125 ASL失败=(2+5∗3+2∗4)/8=3.125
接下来可以看这个博客树表的查找
5. 哈希表的查找
直接摆烂
找到了一个很详细的博客,感觉挺不错的
来自博客园的博客
哈希表的查找
结束:
感谢你的阅读 :)
















 3318
3318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











