







 本文介绍了如何使用Python的Selenium库抓取看云网站中由JavaScript生成的电子书链接。首先,解析首页获取最大页码,然后逐页抓取书籍链接,进入书籍详情页判断是否可下载并下载所有格式。通过Chrome浏览器驱动模拟用户操作,通过XPath定位元素进行点击。文章还提到了在爬取过程中可能遇到的问题及解决方案。
本文介绍了如何使用Python的Selenium库抓取看云网站中由JavaScript生成的电子书链接。首先,解析首页获取最大页码,然后逐页抓取书籍链接,进入书籍详情页判断是否可下载并下载所有格式。通过Chrome浏览器驱动模拟用户操作,通过XPath定位元素进行点击。文章还提到了在爬取过程中可能遇到的问题及解决方案。
简介
我最近在看关于计算机的一些书籍,发现了这个电子书清单:计算机开放电子书汇总, 和大家分享一下. 我在下载其中的书籍时被导向了这个很好的计算机电子书网站KanCloud看云,里面有非常多的实用的编程方面的电子书,很多是该网站自己用html生成的,格式多样,包括pdf,epub,mobi. 在此表示感谢,强烈推荐.
于是,我准备用之前的静态网页爬虫来批量下载,发现书籍的链接是javascript生成的,而且难以解析(我还会写一篇抓取可以解析js的网站的博客). 这时我们可以用selenium来模拟浏览器的动作,例如下拉或者点击button之类的. 然后在看云网站里模拟下载.
要得到一个可以稳健运行的爬虫, 需要考虑一些细节问题, 因此分两篇来说,本篇先给出一个示例,了解工作的过程.
任务简述
进入网站后,看云网站界面如下图所示:
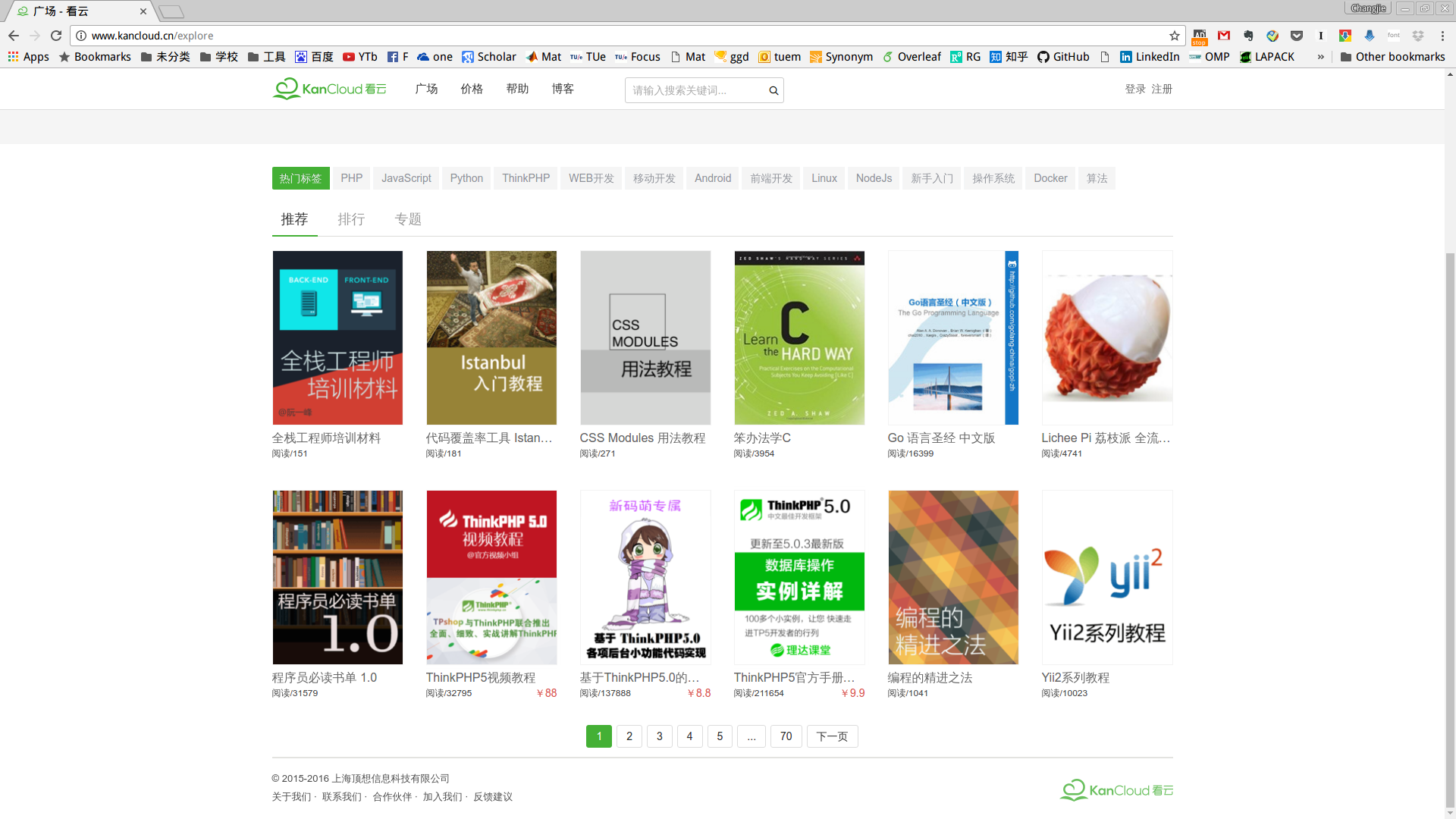
要下载全部电子书,我们需要抓取70个page, 每个page有12本书,每本书有一个单独的页面,而且有的书籍不提供下载,有的可以下载多种格式.
因此, 我们的任务如下:
1. 解析首页,得到最大页码
2. 解析单个页面,得到该页书籍链接列表
3. 进入书籍页
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3158
3158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









