







一、TANE算法介绍
1.1. 函数依赖定义:
若对于R(U)的任意两个可能的关系r1、r2,若r1[x]=r2[x],则r1[y]=r2[y],或者若r1[y]不等于r2[y],则r1[x]不等于r2[x],称X决定Y,或者Y依赖X。
我们考虑的中心任务:给定一个关系,找到r中所有的最小的非平凡依赖关系
1.2. 近似函数依赖
如何定义依赖项相似性,我们使用的定义是基于需要从关系r中删除,X->A才在r中成立的最小元组数(基于…的数量)。用需要删除的最小元组数,除以r的阶,即r中元组数表示近似的程度,比值越小,说明近似依赖性越高

该算法关于属性数量的最坏情况下的时间复杂度是指数级的。然而,对于元组的数量,时间复杂度只是线性的(前提是依赖关系集不会随着元组数量的增加而变化)。线性,使得TANE特别适合与大量元组的关系。
我们的搜索策略:
- 计算关于属性集的重要信息:划分
- 根据信息,得出依赖关系
二、划分和依赖关系
2.1. 划分
如果所有同意X的元组也同意A,则依赖项X→A成立。这句话的等价说法是,如果若对于R(U)的任意两个可能的关系r1、r2,若r1[X]=r2[X],则r1[A]=r2[A],则依赖项X→A成立
等价类概念
属性集X的某一等价类[t]X是指在给定关系实例中,所有与元组t在X上取值相等的元组的集合。
划分概念
属性集X上的划分的 π x \pi _{x} πx的含义是在给定关系实例r中,X的所有等价类的集合。
这就是说 π x \pi _{x} πx是一组不相交的元组的集合(等价类)的集合。这样, 每个集合(等价类)内部的元组在属性集X中的取值是相等的,并且,这些集合的并集就等于关系实例r。
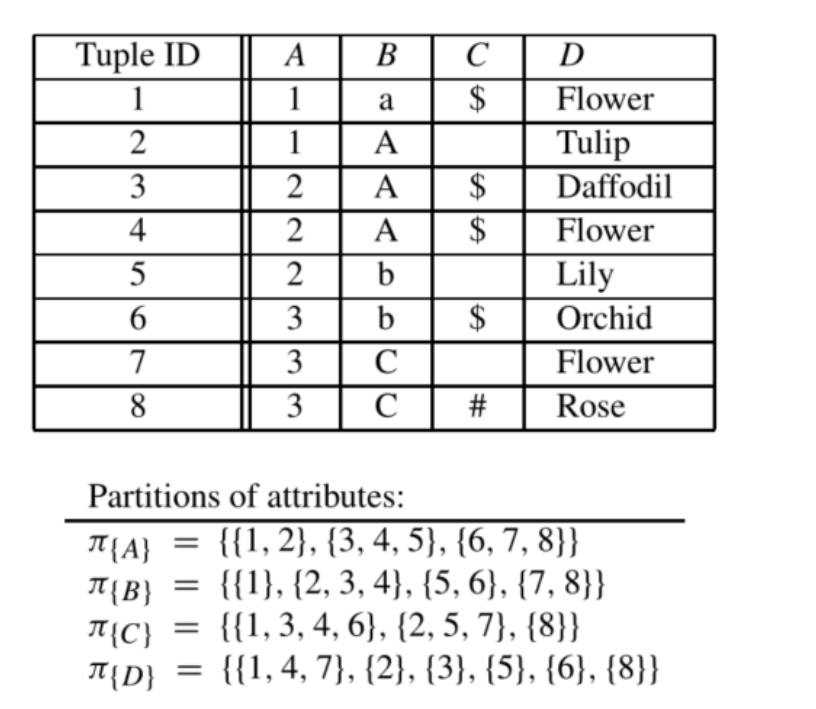
2.2. 划分细化
划分细化的概念几乎直接给出了函数依赖关系。如果π{X}中的每个等价类都是π{A}相应唯一一个等价类的子集,那么分区π{X}细化另一个划分π{A}。
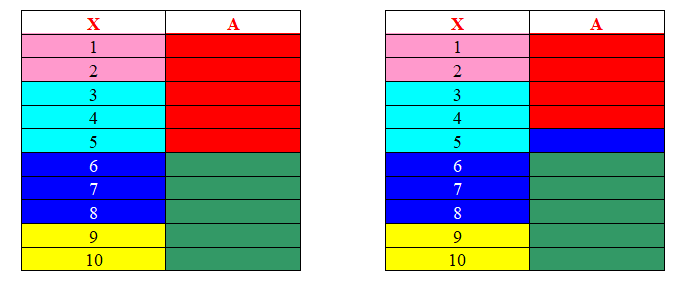
如果每一种着色代表着一个等价类的话,着色相同则代表取值相同,则左图π{X}细化了π{A},但右图由于元组5的存在,所以π{X}并非细化了π{A}
引理2.1
当且仅当划分π{X}细化划分π{A}时,函数依赖X->A成立。因为π{X}中每一个等价类都是π{A}的相应等价类的子集,因此,认同X成立的元组也都认同A成立。
引理2.2
当且仅当|π{X}|=|π{XU{A}}|时,函数依赖X->A成立。
证明:属性集每多一个属性就多一个约束条件,所以对XU{A}划分所得结果必是对X所划分的结果的子集,即π{XU{A}}天然是对π{X}的细化。除非π{XU{A}}与π{X}相等,否则不可能有相同数量的等价类。
二者相等说明什么:认同X成立的元组也都认同A成立。
2.3. 近似依赖
error e (X->A)是需要从关系r中删除,使得X->A在r中成立的最小元组的比例。可以根据π{X}、π{XU{A}}来计算e,πX任何等价类c都是πXU{A}的一个或多个等价类c1、c2,…的并集,要使得X->A成立,保留一个等价类,其余ci中的所有元组全部删除。对于上图而言,保留的一个等价类是{3,4},删除5元组。
因此,要删除的最小元组数是c的大小减去ci中最大的大小。ํ对πX的所有等价类求和,得到要删除的元组总数。
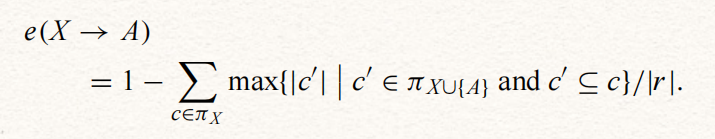
理解:删除的最小元组数是c的大小减去ci中最大的数量。下图中,最大的为5678,数量为4,因此最小删除元组数为9-4=5,即删除的是3491011

三、搜索
3.1. 搜索策略
要找到所有最小的非平凡依赖关系,TANE的工作原理如下。它从单个属性集开始搜索,然后逐级通过集合包含格来搜索更大的属性集。当算法处理集合X时,它测试形式为X \ {A} -> A的依赖关系,其中A∈X。这保证了只考虑非平凡的依赖关系1。算法由从小到大的方向可以用来保证只有最小的依赖关系得到输出。它还可以用于有效地精简搜索空间(参见图2)。
一种类似的大小搜索策略,即水平算法,已成功地应用于许多数据挖掘应用。除了有效的剪枝外,水平算法的效率还是基于使用以前层次的结果来减少每个层次的计算。
在本节中,我们考虑了搜索的不同方面,包括TANE中水平算法的有效剪枝标准,以及分区的快速计算。这两个任务都可以通过使用来自以前级别的信息来有效地解决。根据本节中提供的材料,在第4节中给出了精确的算法。
3.2. 简化搜索空间
3.2.1. Rhs候选
TANE通过格子工作,直到找到保持的最小依赖关系。为了测试潜在依赖项X \ {A}→A的最小值,我们需要知道Y \ {A}→A对于X的某个真子集Y是否成立。我们把这个信息存储在Y的右边候选的集合C(Y)中。

对于给定的集合X,如果A∈C(X),则A不依赖于X的任何真子集(∵A不依赖X)。更准确地说,某一集X的初始rhs候选项的集合为C(X) = R\ C ( X ) ‾ \overline{C(X)} C(X), C ( X ) ‾ \overline{C(X)} C(X)={A ∈ X | X \{A} → A holds}。
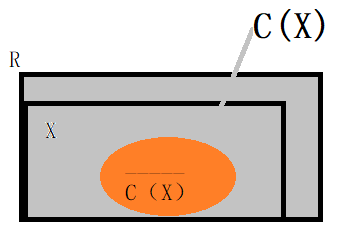
C ( X ) ‾ \overline{C(X)} C(X)为X中满足X\A->A的属性集合。
①A∉C(X)即A∈ C ( X ) ‾ \overline{C(X)} C(X):A属于X,且A依赖X
②A∈C(X):A不属于X或A属于X,但A不依赖X(X\A->A不成立)。
要找到最小的依赖项,只需测试依赖项X \ {A}→A,其中A ∈ X 且对所有B ∈ X,有A ∈ C(X \ {B})。目的是保证,对于X的真子集Y,Y \ {A}→A不成立。
已知A ∈ X 对于所有B属于X,可以拆分成:
①B!=A,A ∈ C(X \ {B}) ⟹ \L
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6774
6774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











