






目录
github地址在本文最后
任务描述
任务描述
(1)目标检测任务:船只检测
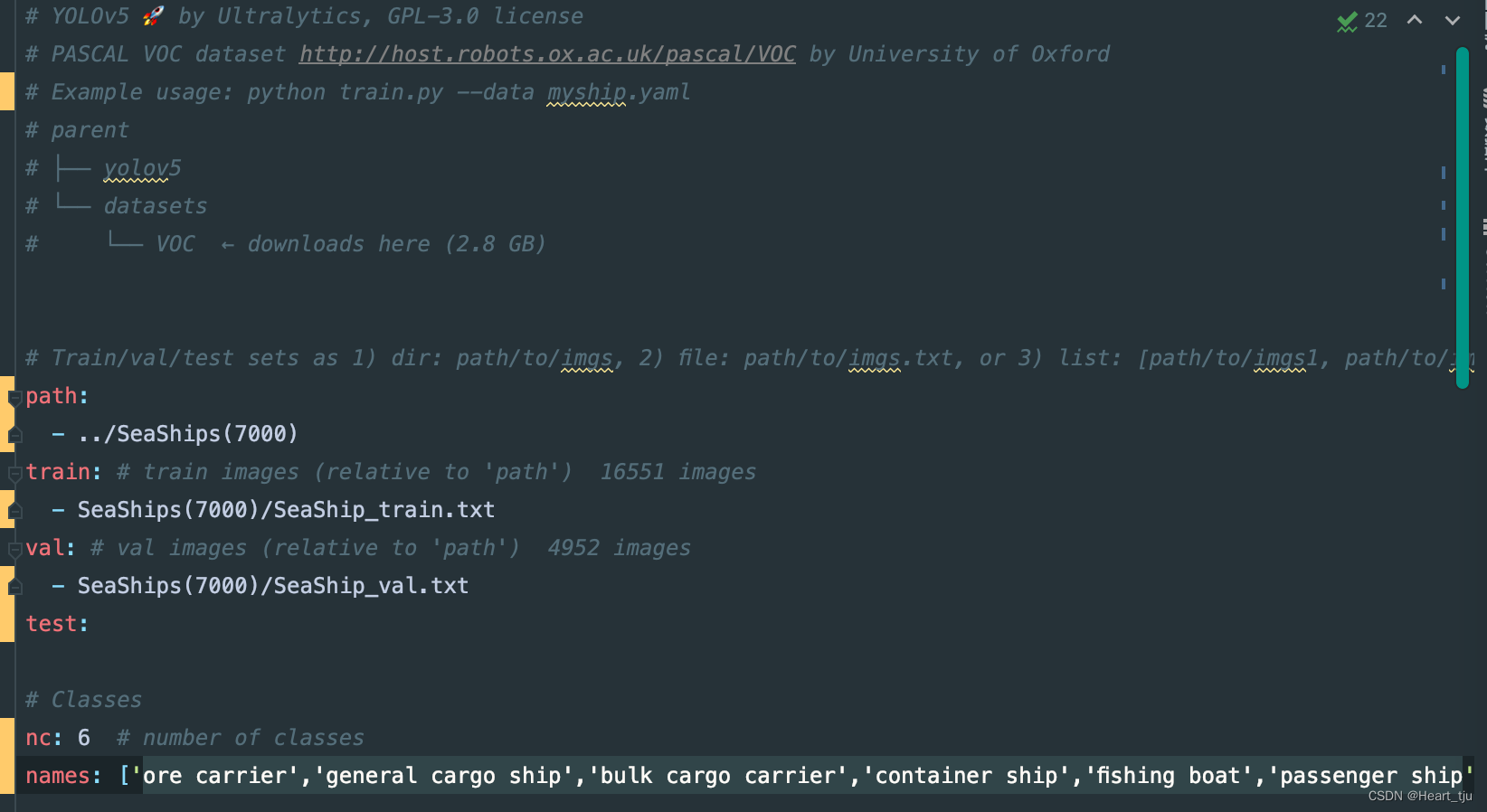
任务:训练模型,解决海上船舶目标的分类和检测(mAP>90%)
数据:SeaShips数据集(7000)
(2)云服务搭建
任务:实现一个基于HTTP的AI服务,API支持输入图片链接,返回图片中船舶的类别及检测框等信息
(3)web展示
任务:实现一个web页面,可以通过在文本框中输入图片链接,请求步骤2中的HTTP服务,把包含的船舶类别及检测框绘制在图片上并呈现出来
实验环境
本人是在AutoDL网站是租用的服务器,具体信息如下

一、目标检测任务:船只检测
1.数据集
该版本数据集共有7000张图片,图片分辨率均为1920*1080,分为六类船只,主要是一些内河航道中船只的图片。

我根据链接把数据集下载到本地,其基本结构如上
1.对数据集的预处理
该数据集共有3个文件夹,其中Annotations文件夹内是每张图片的标签,每个图片对应一个xml文件来存储标签,所以要将xml文件中的内容转为txt文件,每张照片对应一个txt文件,txt文件命名与照片命名一致,如00xxxx.jpg对应的标签文件为00xxxx.xml,我们要将00xxxx.xml文件转为00xxxx.txt文件。
xml文件给出了每一个目标的类别,以及对应的bounding box的左上角和右下角的坐标,对应的均为1920*1080分辨率。
所以:转成txt文件要求是,一张照片对应一个txt文件,一个txt文件每一行对应一个船只目标,每一行五个数,第一个是类别,0~5分别代表六类船只,剩下的四个数依次为bounding box中心点的x和y坐标,然后是框的width和height,所有的数据均为归一化后的数据,x和width要除以1920,y和height要除以1080.
根据如上的要求,我写了一个python文件,进行简单的操作,进行转换
但是要注意的是:
本次实验我需要部署的是yolo v5模型,而它本身是需要类似coco的数据集格式才能使用,所以我们需要所有图片全部放在JPEGImages文件夹下,所有标签全部放在labels文件夹下,然后这两个文件下放在同一个文件夹下。
PS:我一开始就没有注意格式,所以部署yolo模型的时候出现了不少奇怪的bug
2.标注自己的数据集
使用LabelImg 标记图片
标记图片就是对图片中的待识别目标进行标记,如果识别的目标时猫、狗,那就用方块标记出猫或狗,它们的标签分别为cat、dog。标记完成后,生成与原文件名相同的.xml文件。(正在学习)
2、部署yolo模型
git地址:GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install修改cfg文件
cfg文件里面定义了网络框架,代码中建立模型就是根据cfg文件建立的,cfg文件夹内的cfg文件对应不同的网络架构,yolov5,yolov5-spp,yolov5-tiny,复杂度和精确度依次下降,原始yolo含有255个输出,[4 box coordinates + 1 object confidence + 80 class confidences]*3,乘3是因为yolov5在3个尺度上进行预测。因为这里只有6类船只,因此搜索filters=255,将255改为 33=(4+1+6)*3 即可。
修改data文件夹
打开文件夹可看到有.data .names .txt三种类型文件。.data文件定义了类别数量classes,修改为6。第二行train=,这里改为一个txt文件的路径,这个txt文件里面是训练集所有图片的路径,每一行是一张图片的路径。
进行训练
python train.py --epochs 100 --cfg models/yolov5s.yaml --data data/myship.yaml --weights yolov5s.pt --batch-size 32
该命令通过指定数据集、批量大小、图像大小以及预训练,在定义的数据集上进行训练
预训练的权重是从最新的 YOLOv5s 版本自动下载的。

训练结果
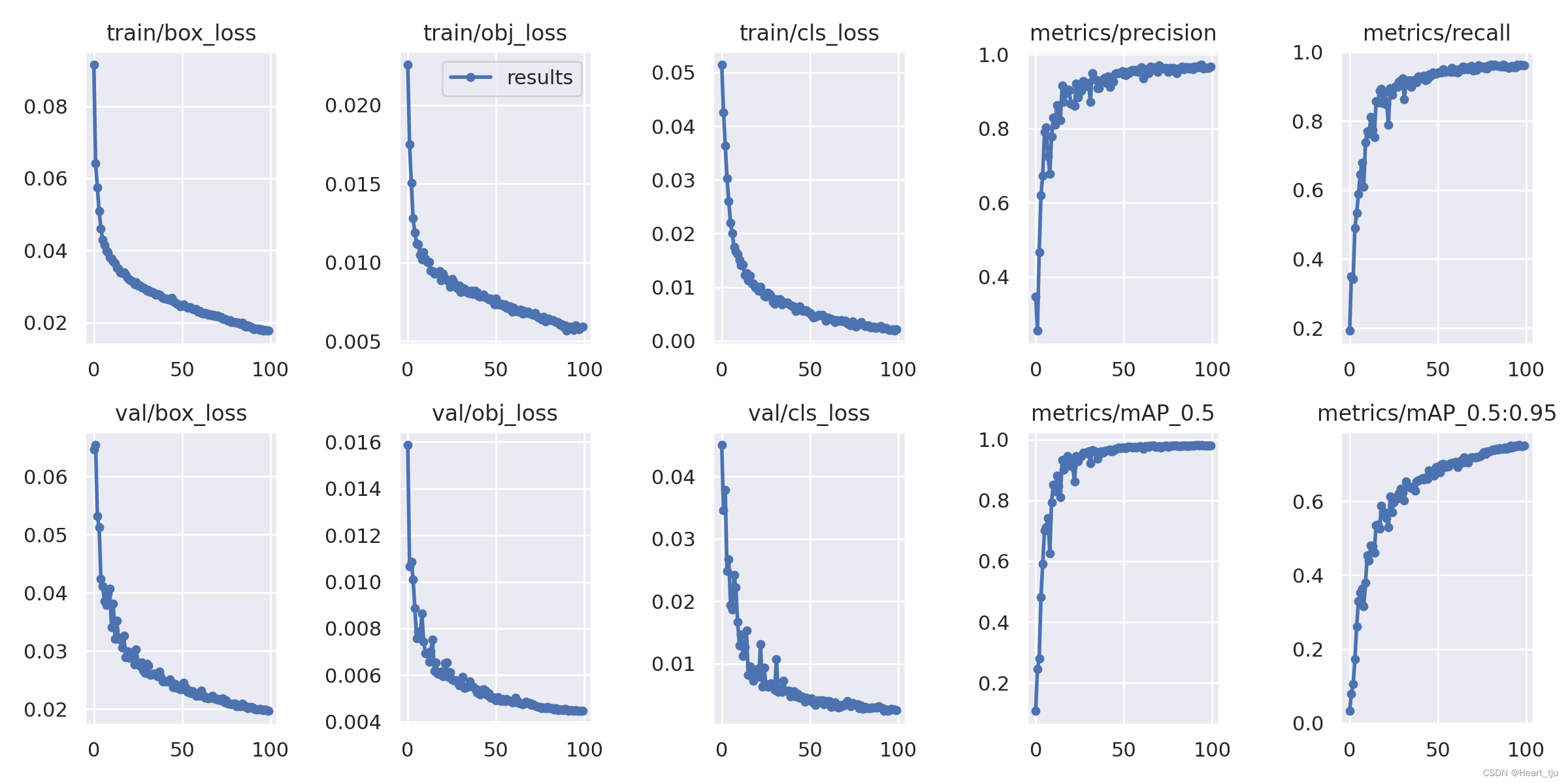

' 
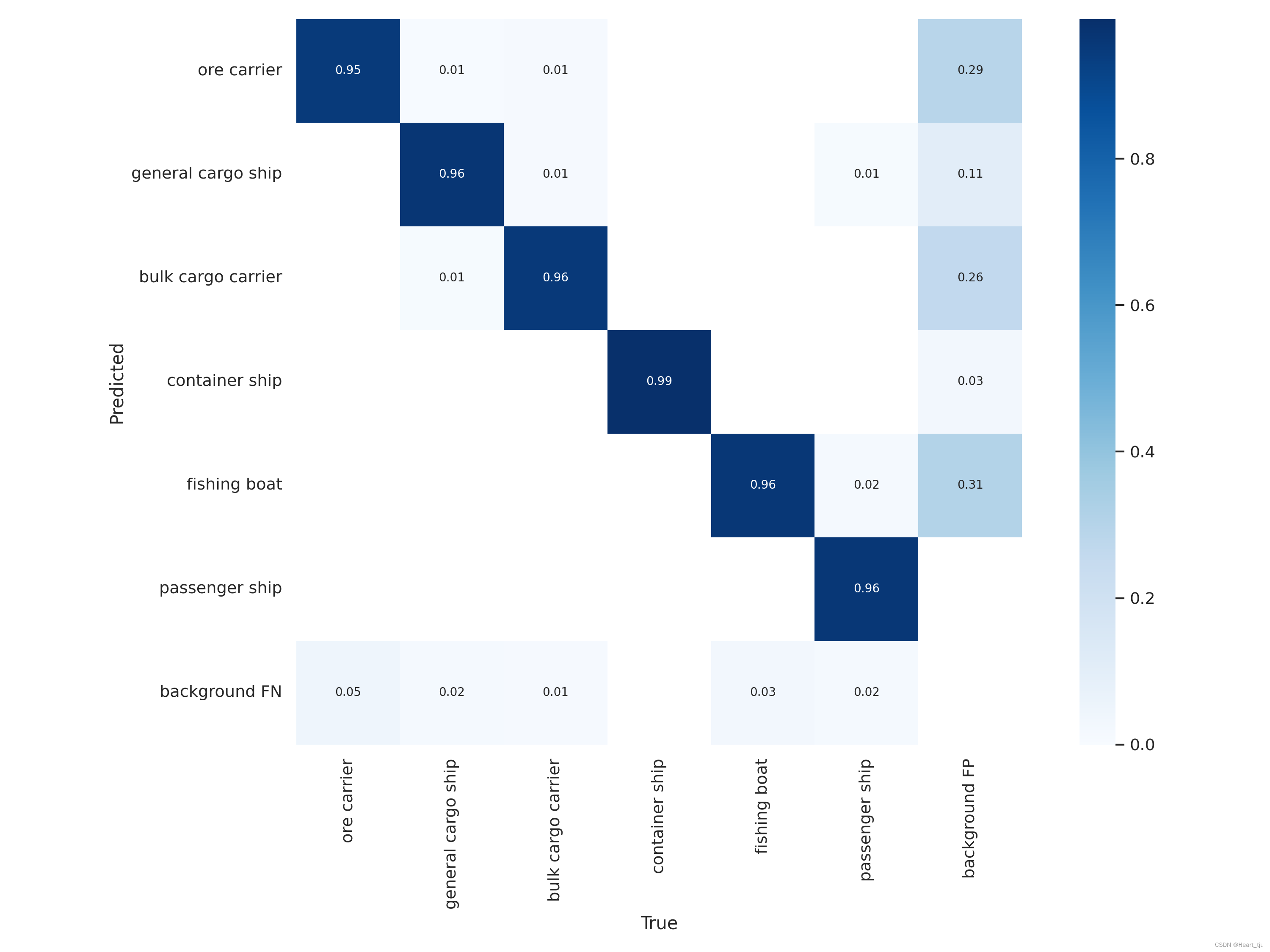
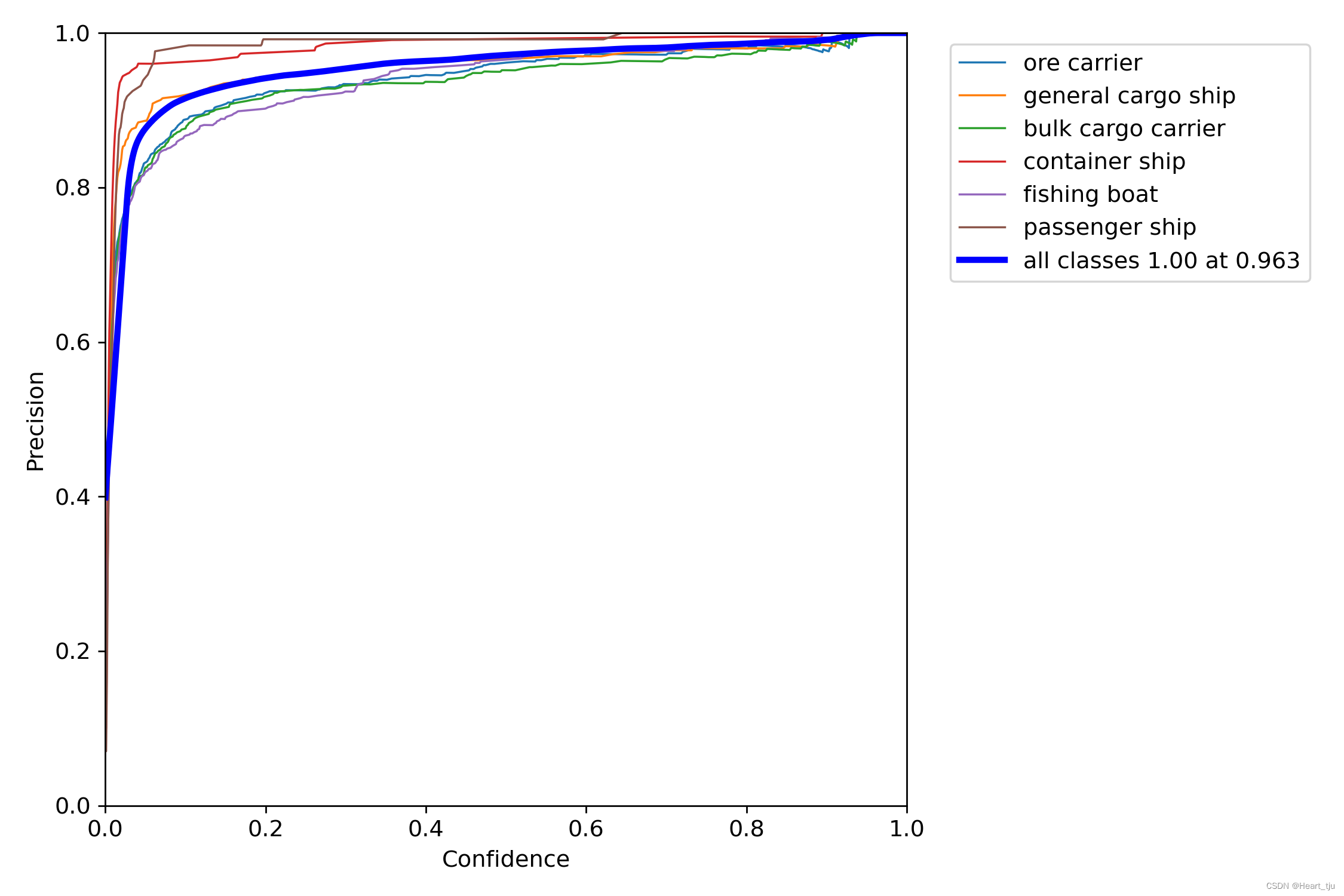 二、基于flask的web服务
二、基于flask的web服务
Flask是一种用python实现轻量级的web服务,也称为微服务,其灵活性较强而且效率高,在深度学习方面,也常常用来部署B/S模型。本项目中,我就基于flask实现web服务api接口,使用的是在SeaShip上训练好的权重文件(best.pt)
其中:
static、templates以及app.py是参与flask架构的相关文件
此外,我还对detect,py自行进行了修改,添加了DetectAPI类方便我进行图片识别
主要文件如下
app.py
import cv2
import time
from flask import Flask, request, Response,render_template
import json
import detect
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
app = Flask(__name__)
basedir = os.path.abspath(os.path.dirname(__file__))#basedir:D:\\yolov5\\yolov5
class_names = ['ore carrier','general cargo ship','bulk cargo carrier','container ship','fishing boat','passenger ship']
file_name = ['jpg','jpeg','png']
@app.route('/images', methods= ['POST'])
def get_image():
image = request.files["images"]
path = basedir + "\\data\\images"
image_name = image.filename
file_path = path + image.filename
image.save(file_path)
Path = 'yolov5/data/images'
if image_name.split(".")[-1] in file_name:
detect_api = detect.DetectAPI(exist_ok=True)
img = cv2.imread(file_path)
cv2.imwrite(os.path.join(path, 'test.jpg'), img)
label = detect_api.run()
with open("runs/detect/myexp/test.jpg", 'rb') as f:
image = f.read()
resp = Response(image, mimetype='image/jpeg')
try:
return resp
#return Response(response=lable, status=200, contenetype='text/html;charset=utf-8')
except:
return render_template('index1.html')
@app.route('/')
def upload_file():
return render_template('index1.html')
if __name__ == '__main__':
app.run(debug=True, host='127.0.0.1', port=5000)index1.html
<!doctype html>
<html lang="pt-BR">
<head>
<!-- Required meta tags -->
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<!-- Bootstrap CSS -->
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css"
integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous">
<link rel="stylesheet" href="{{ url_for('static', filename='style.css') }}">
<link rel='stylesheet' href='../static/style1.css'>
<script src='../static/client.js'></script>
<title>yolo deepsort</title>
</head>
<body>
<div class="container">
<nav class="navbar navbar-expand-sm bg-primary navbar-dark justify-content-center">
<ul class="navbar-nav">
<li class="nav-item">
<a class="nav-link" href="index1.html" type = "submit">YoloV5</a>
</li>
</ul>
</nav>
</div>
<div>
<div class='center'>
<div class='title'>SeaShip Detection Platform</div>
<div class='content'>
<div class='no-display'>
<form action = "/images" method = "POST"
enctype = "multipart/form-data">
<input id='file-input'
class='no-display'
type='file'
name='images'
accept='image/png,image/jpeg,image/jpg,video/mp4,video/avi'
onchange='showPicked(this)'>
</div>
<button class='choose-file-button' type='button' onclick='showPicker()'>Upload file</button>
<div class='upload-label'>
<label id='upload-label'>No file chosen</label>
</div>
<div>
<img id='image-picked' class='no-display' alt='Chosen Image' height='250'>
<video autoplay="autoplay" id='image-picked1' class='no-display' alt='Chosen Image' height='250'>
</div>
<div class='analyze'>
<button id="analyze-button" class="analyze-button" type = "submit">Analyze</button>
</div>
</form>
</div>
</div>
</div>
</body>
</html>detect.py(部分)推理:
class DetectAPI:
def __init__(self, weights='weights/best.pt', data='data/myship.yaml', imgsz=None, conf_thres=0.25,
iou_thres=0.45, max_det=1000, device='0', view_img=False, save_txt=False,
save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False,
visualize=False, update=False, project='runs/detect', name='myexp', exist_ok=False, line_thickness=3,
hide_labels=False, hide_conf=False, half=False, dnn=False):
if imgsz is None:
self.imgsz = [640, 640]
self.weights = weights
self.data = data
self.source = 'data/images'
self.imgsz = [640, 640]
self.conf_thres = conf_thres
self.iou_thres = iou_thres
self.max_det = max_det
self.device = device
self.view_img = view_img
self.save_txt = save_txt
self.save_conf = save_conf
self.save_crop = save_crop
self.nosave = nosave
self.classes = classes
self.agnostic_nms = agnostic_nms
self.augment = augment
self.visualize = visualize
self.update = update
self.project = project
self.name = name
self.exist_ok = exist_ok
self.line_thickness = line_thickness
self.hide_labels = hide_labels
self.hide_conf = hide_conf
self.half = half
self.dnn = dnn
def run(self):
source = str(self.source)
save_img = not self.nosave and not source.endswith('.txt') # save inference images
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.txt') or (is_url and not is_file)
if is_url and is_file:
source = check_file(source) # download
# Directories
save_dir = increment_path(Path(self.project) / self.name, exist_ok=self.exist_ok) # increment run
(save_dir / 'labels' if self.save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
device = select_device(self.device)
model = DetectMultiBackend(self.weights, device=device, dnn=self.dnn, data=self.data)
stride, names, pt, jit, onnx, engine = model.stride, model.names, model.pt, model.jit, model.onnx, model.engine
imgsz = check_img_size(self.imgsz, s=stride) # check image size
# Half
self.half &= (
pt or jit or onnx or engine) and device.type != 'cpu' # FP16 supported on limited backends with CUDA
if pt or jit:
model.model.half() if self.half else model.model.float()
# Dataloader
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt)
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
model.warmup(imgsz=(1, 3, *imgsz)) # warmup
dt, seen = [0.0, 0.0, 0.0], 0
for path, im, im0s, vid_cap, s in dataset:
t1 = time_sync()
im = torch.from_numpy(im).to(device)
im = im.half() if self.half else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if self.visualize else False
pred = model(im, augment=self.augment, visualize=visualize)
t3 = time_sync()
dt[1] += t3 - t2
# NMS
pred = non_max_suppression(pred, self.conf_thres, self.iou_thres, self.classes, self.agnostic_nms,
max_det=self.max_det)
dt[2] += time_sync() - t3
# Second-stage classifier (optional)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + (
'' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if self.save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=self.line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
mylabel = []
# Write results
for *xyxy, conf, cls in reversed(det):
if self.save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if self.save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or self.save_crop or self.view_img: # Add bbox to image
c = int(cls) # integer class
label = None if self.hide_labels else (
names[c] if self.hide_conf else f'{names[c]} {conf:.2f}')
mylabel.append(str(label))
annotator.box_label(xyxy, label, color=colors(c, True))
if self.save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
# Print time (inference-only)
LOGGER.info(f'{s}Done. ({t3 - t2:.3f}s)')
# Stream results
im0 = annotator.result()
if self.view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path[i] != save_path: # new video
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path += '.mp4'
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer[i].write(im0)
# Print results
t = tuple(x / seen * 1E3 for x in dt) # speeds per image
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
if self.save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if self.save_txt \
else ''
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
if self.update:
strip_optimizer(self.weights) # update model (to fix SourceChangeWarning)
return mylabel最后的Mylabel返回检测的结果以及精度
展示效果
1、运行app.py
等待它返回url

访问返回的url进行操作
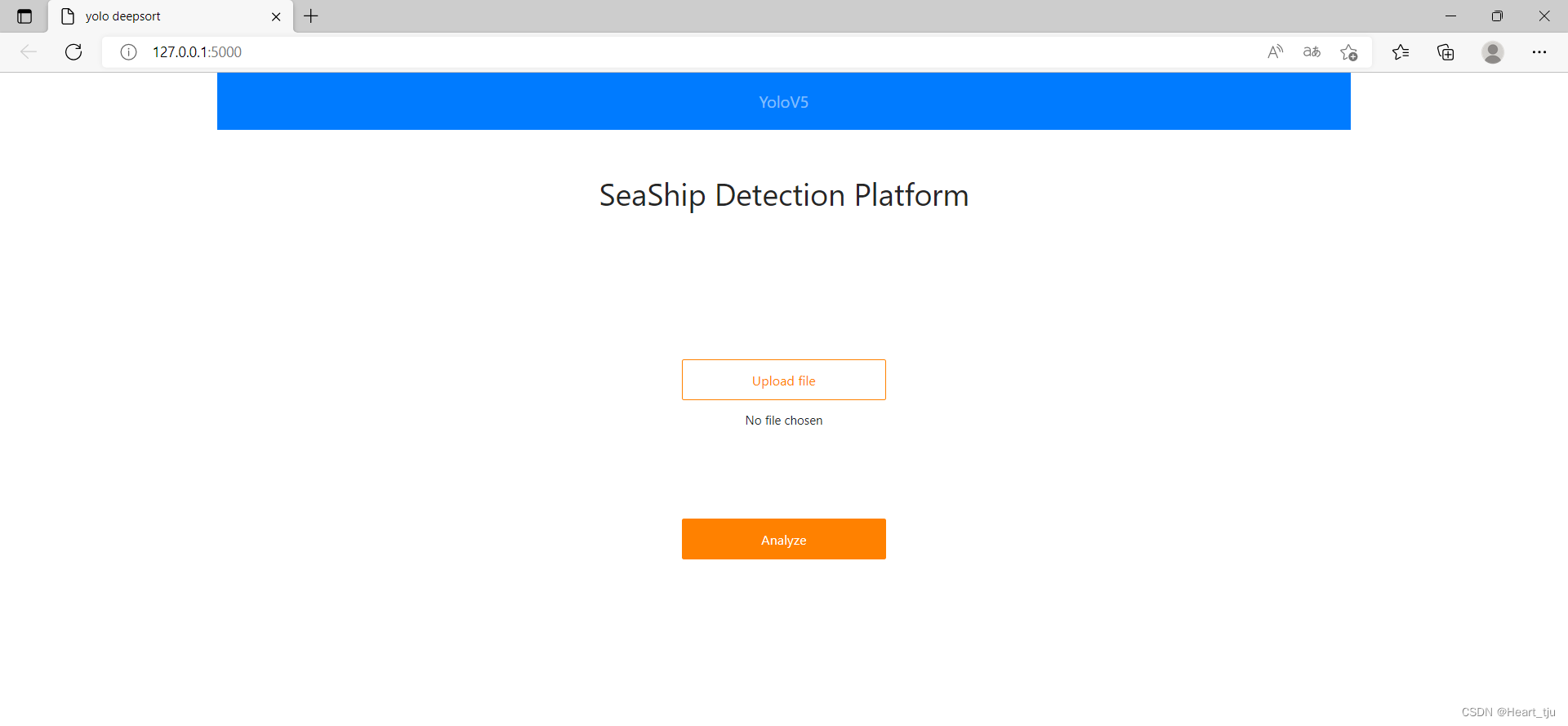 上传需要检测的图片
上传需要检测的图片
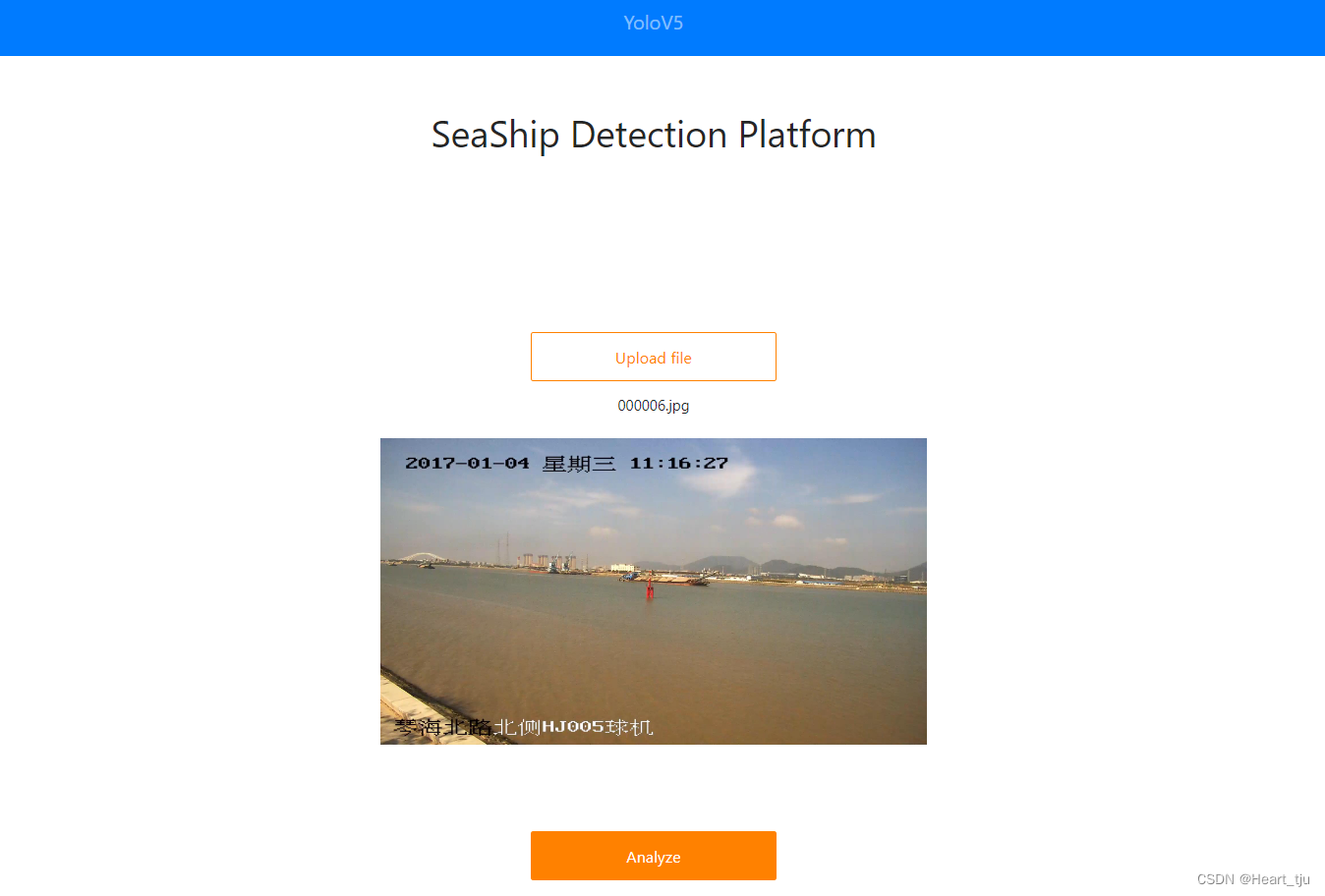
点击Analyze,便可进行分析得到结果了

并且在终端中也会又更加详细的信息:
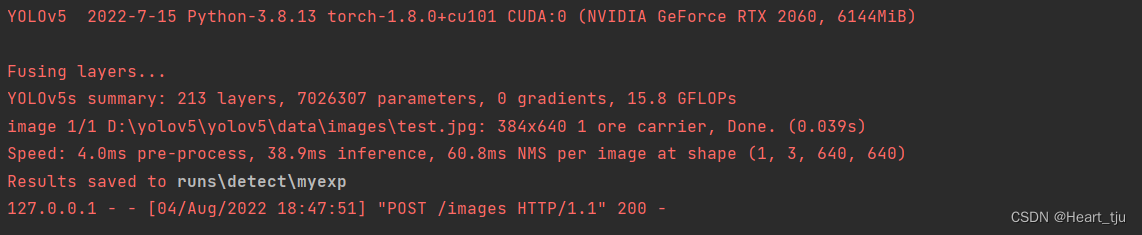
最后附上本次项目的github地址:(同时也欢迎大家对此项目进行讨论和建议):















 2151
2151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









