










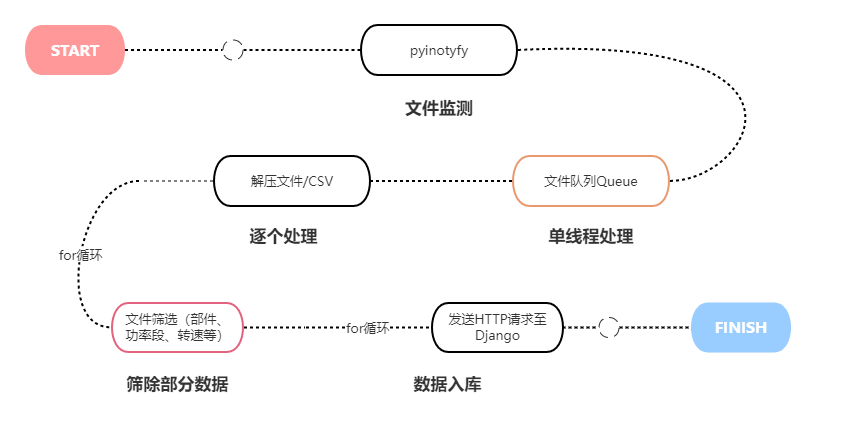
在接手这个项目之前,关于数据存储的代码逻辑如上图,看起来按部就班,也很合理。(本人觉得这就像个玩具车)
在最后一步发送HTTP request响应足够快的话,其实速度说不上快但稳定,可以接受。但偏偏第三季度了,数据量上来了,最后一步得到response的时间达到了2秒多(因为这个请求是往mysql里存储新数据,数据量很大的情况下,存储会慢很多),若是一个压缩包有一万条数据,那处理该文件的时间能达到6小时左右,每天可能有几十个这样的压缩包进入监测文件系统。(意思是 要用这个玩具车 去工地盖大楼了,无语......)
话说,对这样一个简单直接的逻辑,能想到几种优化方法?
批量插入数据,在最后一步HTTP请求中批量发送数据,批量入库,这样比一个请求创建一个文件相关的数据快多了。
BUT: 看了一下项目的代码,在HTTP请求发送后,入库的逻辑不是简单的创建一条数据,还会有:
关联关系表的数据创建。
非关联关系表的数据创建。
每条数据入库前需要检查是否符合配置要求,不符合需剔除。
需用规则表查寻规则信息,看情况为每条数据创建任务,并将任务记录在另一个表中。
每个入库请求执行完需要记录成功数量和失败原因。
所以批量入库会有不小的麻烦,但也不是不可能,只要考虑的全面一些。我怕麻烦,果断pass
多线程处理队列任务,在第二步中,仅用了单线程去处理队列(blocked)任务
由于GIL和blocked Queue等原因,多线程和单线程应该没差
多进程
需要考虑进程间通信等因素,说实话,我一直觉得,直接用Python的multiprocessing不是个好主意,除非你是大神,否则会遇到很多Errors,即使能跑起来,稳定性也会让你自我怀疑。
最简单的应该就是对最后一个for循环下手了,异步发送数据入库请求,不要一个等一个,就会快很多了,我觉得这个是最简单快速的处理方法。
首先,这样对原始逻辑的改动不大,又能实现目的,何乐而不为。
通常在Python中我们进行并发编程一般都是使用多线程或者多进程来实现的,对于计算型任务由于GIL的存在我们通常使用多进程来实现,而对于IO型任务我们可以通过线程调度来让线程在执行IO任务时让出GIL,从而实现表面上的并发。其实对于IO型任务我们还有一种选择就是协程,协程是运行在单线程当中的"并发",协程相比多线程一大优势就是省去了多线程之间的切换开销,获得了更大的运行效率。
重写的过程中(是的推翻重写,玩具就是玩具),看到了asyncio,之前从没用过,来学习一下。
asyncio异步I/O
asyncio是用来编写 并发 代码的库,使用async/await语法。asyncio被用作多个提供高性能 Python 异步框架的基础,包括网络和网站服务,数据库连接库,分布式任务队列等等。
asyncio可以实现单线程并发IO操作, 由于HTTP连接就是IO操作,因此可以用单线程+coroutine实现多用户的高并发支持。
asyncio实现了TCP、UDP、SSL等协议,aiohttp则是基于asyncio实现的HTTP框架。为了简化并更好地标识异步IO,从
Python3.5开始引入了新的语法async和await,可以让coroutine的代码更简洁易读。Eventloop
Eventloop可以说是asyncio应用的核心,是中央总控。Eventloop实例提供了注册、取消和执行任务和回调的方法。
把一些异步函数(就是任务,Task,一会就会说到)注册到这个事件循环上,事件循环会循环执行这些函数(但同时只能执行一个),当执行到某个函数时,如果它正在等待I/O返回,事件循环会暂停它的执行去执行其他的函数;当某个函数完成I/O后会恢复,下次循环到它的时候继续执行。因此,这些异步函数可以协同(Cooperative)运行:这就是事件循环的目标。
Coroutine
协程,又称微线程,纤程,英文名Coroutine。协程的作用是在执行函数A时可以随时中断去执行函数B,然后中断函数B继续执行函数A(可以自由切换)。但这一过程并不是函数调用,这一整个过程看似像多线程,然而协程只有一个线程执行。
协程(Coroutine)本质上是一个函数,特点是在代码块中可以将执行权交给其他协程
Future
它代表了一个「未来」对象,异步操作结束后会把最终结果设置到这个Future对象上。Future是对协程的封装,不过日常开发基本是不需要直接用这个底层Future类的。
Task
Eventloop除了支持协程,还支持注册Future和Task 2种类型的对象,那为什么要存在Future和Task这2种类型呢?先回忆前面的例子,Future是协程的封装,Future对象提供了很多任务方法(如完成后的回调、取消、设置任务结果等等),但是开发者并不需要直接操作Future这种底层对象,而是用Future的子类Task协同的调度协程以实现并发
最后一个循环的请求发送要提出来一个异步函数了,用async 修饰
async def send_request(data, semaphore):
async with semaphore:
async with ClientSession() as _session:
async with _session.post(url, data=data) as res:
if res.status == 200:
print("入库成功")
# content_type设置为None不去检查content type,可以避免response解析错误,因为下面调用了json
content = res.json(content_type=None, encoding="utf-8")
else:
# 或在此分类错误返回信息
print("入库失败")
content = {"error": "解析失败"}
# 请求的服务端是Django项目,一个请求就会创建一个连接,拿到结果后使用close可避免占用连接过多
res.close()
# 因为我的逻辑需要统计入库信息,所以要结果返回,若不需要结果,则不用返回
return content
常见错误
-
aiohttp message='Attempt to decode JSON with unexpected mimetype: text/html;
或者是另一种content type
application/json,都有可能遇到,
-
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
调用
async标记的函数时没有使用前缀 await 修饰 -
Too many connections
Django后端可能并发处理两个请求,会创建重复数据,解决方法是设置unique属性














 797
797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









