









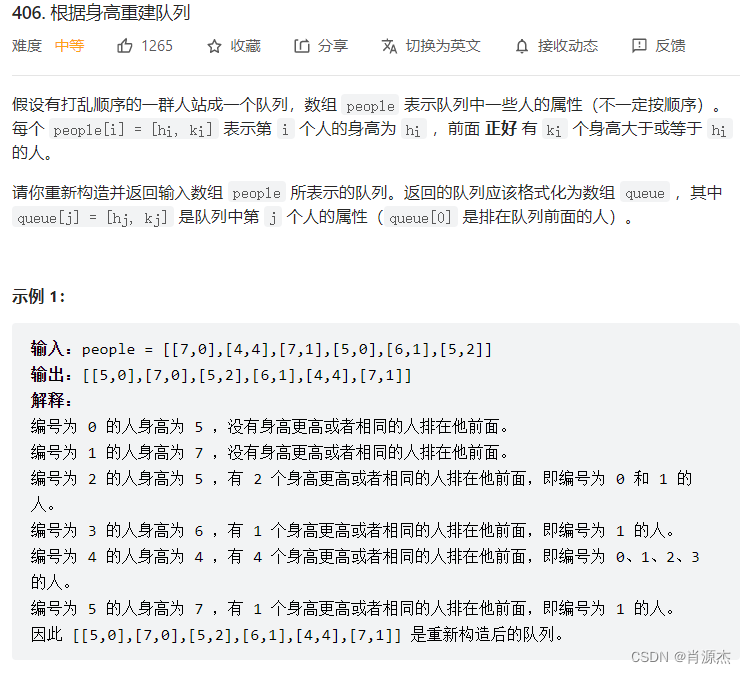

如何排序:
[[7,0],[4,4],[7,1],[5,0],[6,1],[5,2]]
我们先按从小到大来进行排列,当first相同时,second从大到小排列
[[4,4],[5,2],[5,0],[6,1],[7,1],[7,0]]
对于目标数组设为res,预处理n个空间,这里n为上面的数组的大小n == 6,按照sort以后的数组,按该顺序依次插入
res的获得顺序为:
- [[],[],[],[],[4,4],[]]
- [[],[],[5,2],[],[4,4],[]]
- [[5,0],[],[5,2],[],[4,4],[]]
- [[5,0],[],[5,2],[6,1],[4,4],[]]
- [[5,0],[],[5,2],[6,1],[4,4],[7,1]]
- [[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
解释:
[4,4] 4肯定是最小的,所以插入的地方前面应该要有second个空余的位置,(空余位置插入后肯定比4大,所以满足要求)
[5][2] 5是第二小的,插入时前面要有second个空余位置
以此类推
如何判断前面空余位置有几个?每次插入到的位置,将那个位置置为1,如:
- [[],[],[],[],[4,4],[]]
0,0,0,0,1,0 - [[],[],[5,2],[],[4,4],[]]
0,0,1,0,1,0
这样就可以使用前缀和来判断这个位置i之前有几个1,同时剩下几个0。
那这么每次插入都进行一次遍历并且要维护前缀和数组,时间复杂度O(n3);
考虑到插入时可以用二分的方法来进行优化,前缀和可以用树状数组来优化,时间复杂度O(n * log2n);
题目给的最大2000,暴力时间复杂度为6*109
优化后为 2000 * 12 * 12 约为 3 * 105
减少不是一点半点。
重载时:
引用传递的效率会更高,见435 无重叠区间
sort(people.begin(), people.end(), [](vector<int>a, vector<int>b) {
if (a[0] != b[0]) return a[0] < b[0];
else return a[1] > b[1];
});
//引用传递效率高
sort(people.begin(), people.end(), [](vector<int>&a, vector<int>&b) {
if (a[0] != b[0]) return a[0] < b[0];
else return a[1] > b[1];
});
code
class Solution {
public:
int n;
vector<int>tr;
vector<vector<int>> res;
int lowbit(int x) {
return x & (-x);
}
void add(int x, int v) {
for (int i = x; i <= n; i += lowbit(i)) tr[i] += v;
}
int query(int x) {
int res = 0;
for (int i = x; i; i -= lowbit(i)) res += tr[i];
return res;
}
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
n = people.size();
sort(people.begin(), people.end(), [](vector<int>a, vector<int>b) {
if (a[0] != b[0]) return a[0] < b[0];
else return a[1] > b[1];
});
tr.resize(n + 1);
res.resize(n);
for (auto p : people) {
int l = 0, r = n - 1;
while (l < r) {
int mid = (l + r) >> 1;
if (mid - query(mid + 1) >= p[1]) r = mid;
else l = mid + 1;
}
add(l + 1, 1);
res[l] = p;
}
return res;
}
};















 3285
3285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









