






lz77学习记录
引用[哔哩哔哩]
lz4学习记录
LZ4就是一个用16k大小哈希表储存字典并简化检索的LZ77
学习链接:link
LZ4算法的字典是一张哈希表。
HASH: 根据这个函数和查找关键字key,可以直接确定查找值所在位置,而不需要一个个比较。这样就“预先知道”key所在的位置,直接找到数据,提升效率。
字典的key是一个4字节的字符串,每个key只对应一个槽,槽里的value是这个字符串的位置。
LZ4没有待搜索缓存, 而是每次从输入文件读入四个字节, 然后在哈希表中查找这字符串对应的槽,下文称这个字符串为现在字符串。
如果已经到最后12个字符时直接把这些字符放入输出文件。
如果槽中没有赋值,那就说明这四个字节第一次出现, 将这四个字节和位置加入哈希表, 然后继续搜索。
如果槽中有赋值,那就说明我们找到了一个匹配值。
如果槽中的值加滑动窗口的大小<现在字符的位置,那就说明匹配项位置超出了这个块的大小,那程序将哈希槽中的值更新成现在字符串的位置。
LZ4会检查一下有没有发生过hash冲突。如果槽中值所在位置的4字节与现在字符串的不相同,那一定是发生了hash冲突。作者自己编的xxhash也是以高效著称,但还是不可避免的会有冲突。遇到冲突, 程序也将哈希槽中的值更新成现在字符串的位置
最后我们能确认这个匹配项是有效的,程序会继续看匹配字符串后续的字符是不是也相同。最后复制从上一个有效匹配项结束到本次有效匹配项开始前的所有字符到压缩文件,并加上本次有效匹配项的匹配序列。
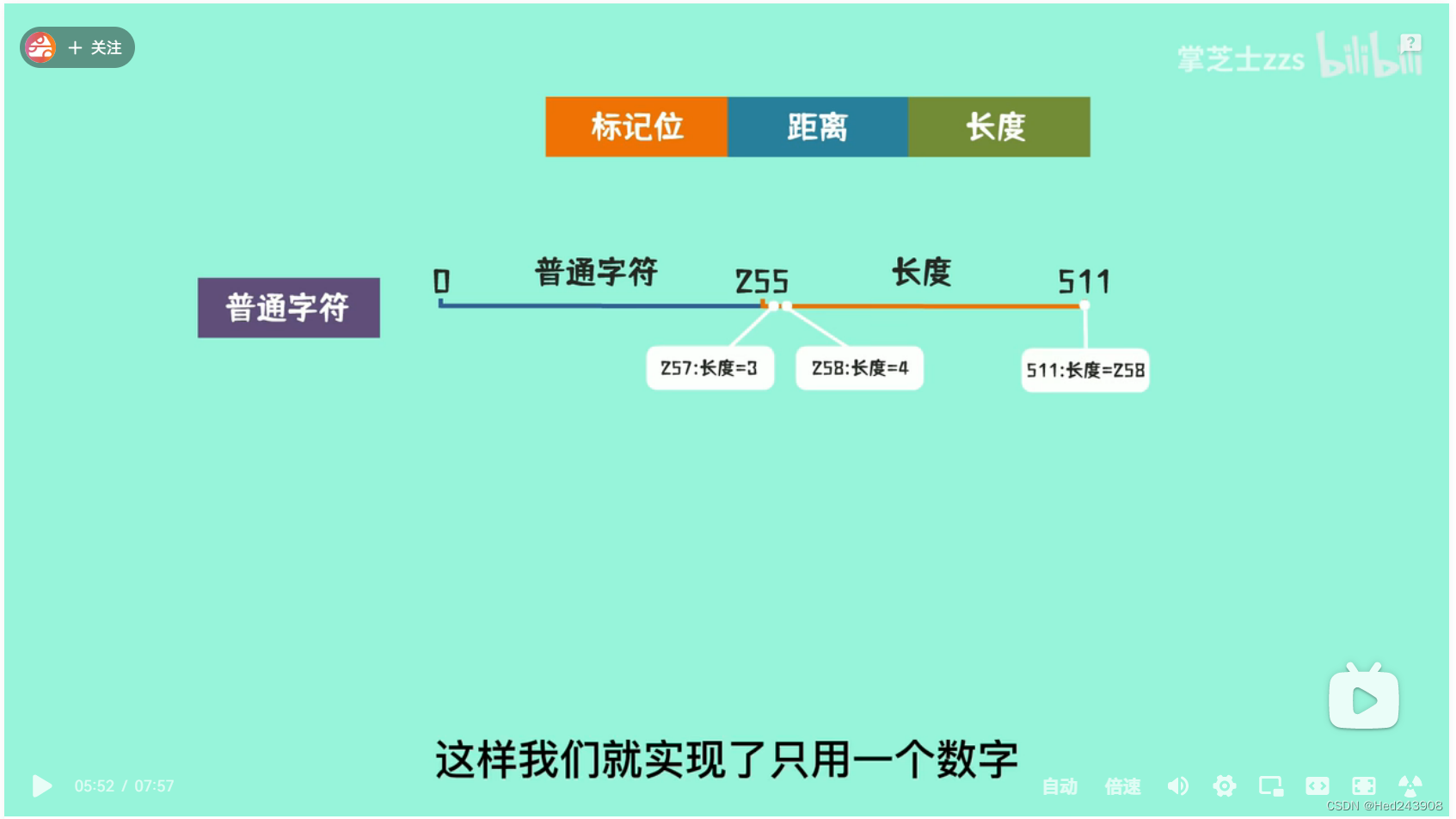
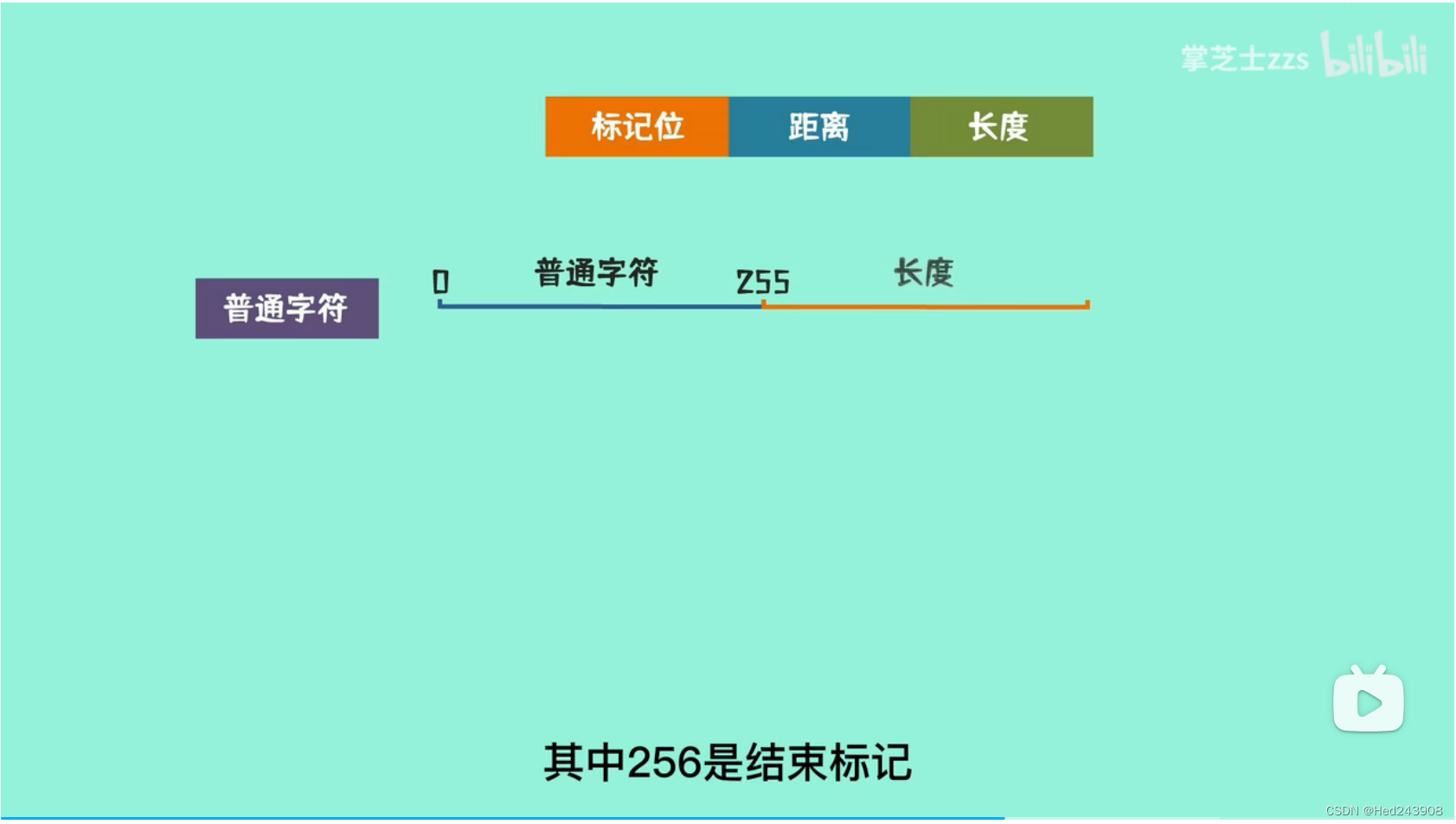
Collet 称LZ4输出的匹配单元为匹配序列(sequence),他们组成了LZ4的压缩文件。具体如下图:

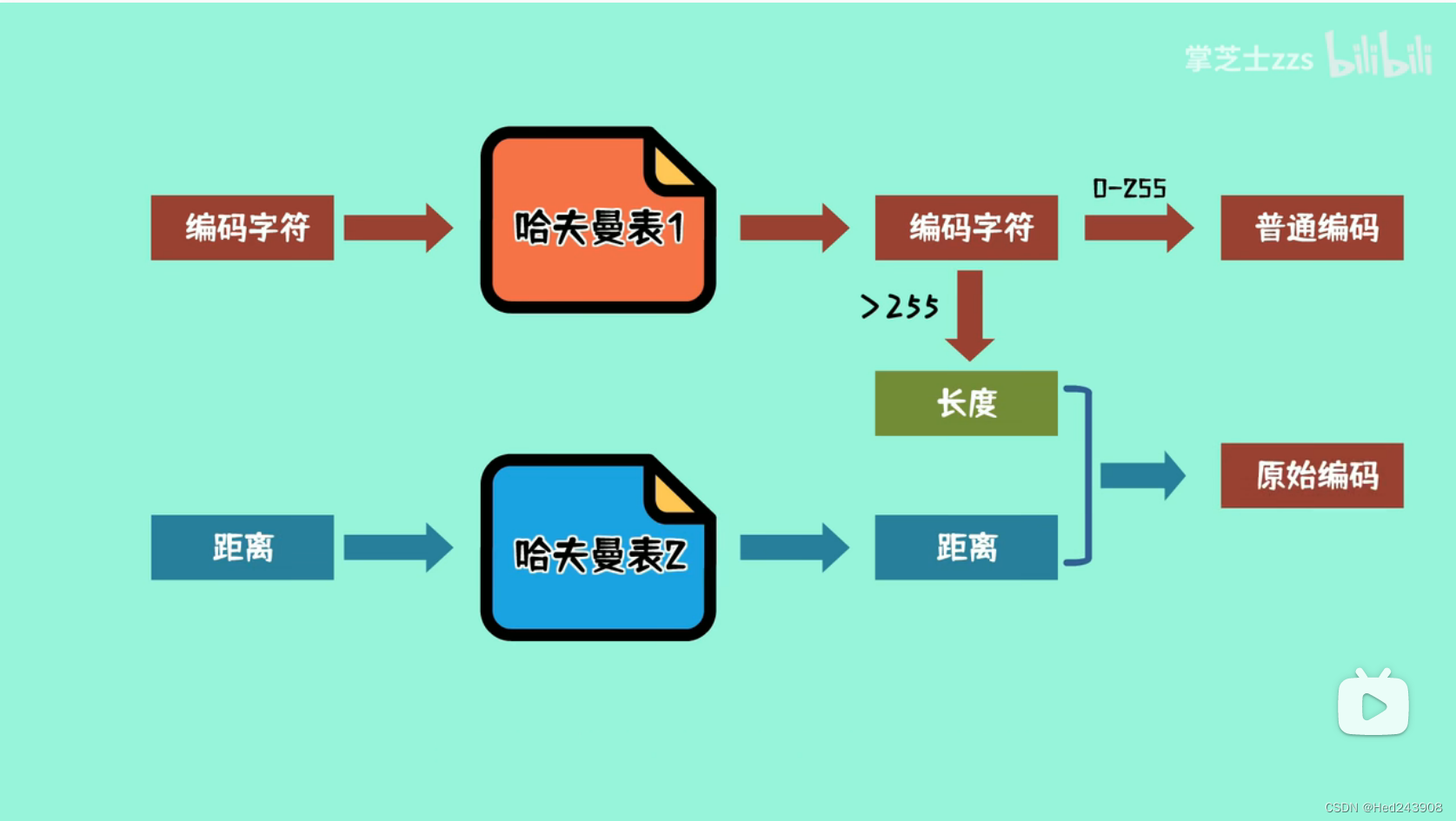
令牌(token)长为1字节,其中前4个字为字面长度(literal length),而其后4个字为匹配长度(match length)。前文中讲到会将上一个有效匹配项结束到本次有效匹配项开始前的所有字符复制到压缩文件,这些未经压缩的文件就是字面(literal),而他们的长度就是字面长度。
字面之后是偏差。和LZ77中偏差和匹配长度一样,偏差指的是现在字符串离它匹配项的长度,而匹配长度指的是现在字符串与字典中相同字符串的匹配长度。在解压是需要通过它来寻找需要复制的字符串和要复制的长度。偏差的大小是固定的。
图中literal length+和match length+ 是如果令牌中的字面或者匹配长度的4个字不够用了就在相应位置继续增加。4个字能表示0-15,再多的话就在增加一个字节,也就是大小加上255,直到字节中不满255。在匹配长度中,0代表4个字节。
最后12个字节在字面之后就结束了,因为它是直接被复制过去的。
哈希冲突
即不同key值产生相同的地址,H(key1)=H(key2)
比如我们上面说的存储3 6 9,p取3是
3 MOD 3 == 6 MOD 3 == 9 MOD 3
此时3 6 9都发生了hash冲突
哈希冲突的解决方案
不管hash函数设计的如何巧妙,总会有特殊的key导致hash冲突,特别是对动态查找表来说。
hash函数解决冲突的方法有以下几个常用的方法:
1.开放定制法
2.链地址法
3.公共溢出区法
建立一个特殊存储空间,专门存放冲突的数据。此种方法适用于数据和冲突较少的情况。
4.再散列法
准备若干个hash函数,如果使用第一个hash函数发生了冲突,就使用第二个hash函数,第二个也冲突,使用第三个……
重点了解一下开放定制法和链地址法
链接:引用














 120
120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









