









DBA经常会需要自己造些数据做测试,一般分为两类:一种是表占的储存量非常大,但行数可能并不多,主要用于备份类的测试;另一种表行数多,但表占的储存量可能并不大,主要用于sql优化类的测试。
如果可以,建议在插入数据时关归档、开并行,速度会更快。
一、 构造占大量存储空间的表
如果没有特别要求的话,最简单的方法就是直接往表里插文件,例如Oracle的安装包,一行就有几G的量。
建议不要用dd命令生成的文件,这种文件里面内容全是0,在备份时压缩比非常高(测试606G数据压缩后备份文件仅7.6G,开4个并行备份仅35分钟),但实际生产库不可能出现这种情况,测试得到的数据准确度非常低。
1. 将文件插入Oracle表
- 创建os目录并授权oracle访问
mkdir -p /data/dump
chown oracle.oinstall /data/dump- 在数据库中创建对应DIRECTORY并授权业务用户访问
CREATE OR REPLACE DIRECTORY DIR_FILE AS '/data/dump';
grant read,write on directory DIR_FILE to bakuser;

- 将需要插入的文件放在/data/dump目录下,这里是test.file,一个10M的文件
- 创建测试表
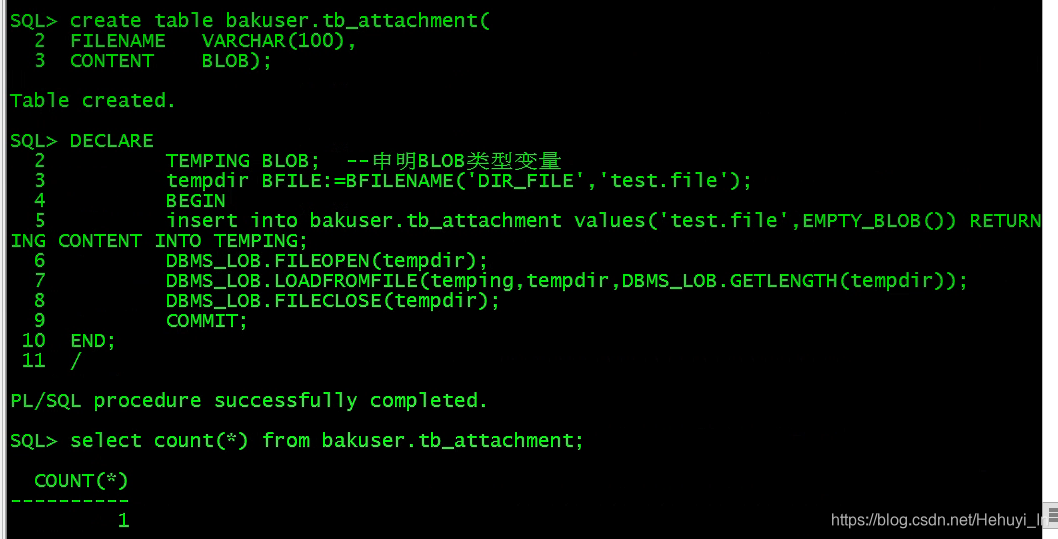
create table bakuser.tb_attachment(FILENAME VARCHAR(100),CONTENT BLOB);- 插入一行数据
DECLARE
TEMPING BLOB; --申明BLOB类型变量
tempdir BFILE:=BFILENAME('DIR_FILE','test.file');
BEGIN
insert into bakuser.tb_attachment values('test.file',EMPTY_BLOB()) RETURNING CONTENT INTO TEMPING;
DBMS_LOB.FILEOPEN(tempdir);
DBMS_LOB.LOADFROMFILE(temping,tempdir,DBMS_LOB.GETLENGTH(tempdir));
DBMS_LOB.FILECLOSE(tempdir);
COMMIT;
END;
/
2. 循环反复插入数据
可以直接insert也可以用并行
alter session force parallel dml;
insert into /*+ append parallel(4) */ bakuser.tb_attachment select /*+ parallel(4) */ * from bakuser.tb_attachment;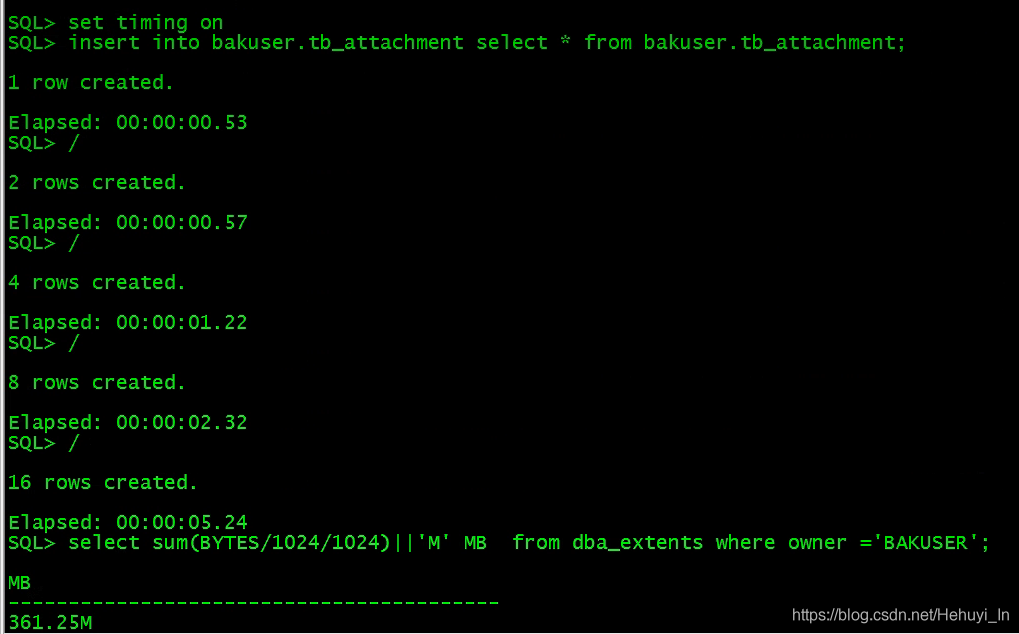
二、 构造具有大量行的表
1. 不需随机数据
用ctas创建一个表,然后反复查询自身并插入,数据量会呈指数级上升。
create table tmp as select * from dba_objects;
-- 反复执行下面语句直到数据量足够
insert into tmp select * from tmp;
commit;
-- 当数据量达到千万级时可使用并行
alter session force parallel dml;
insert into /*+ append parallel(4) */ tmp select /*+ parallel(4) */ * from tmp;
commit;2. 生成随机数据
select rownum as id,to_char(sysdate + rownum/24/3600,'yyyy-mm-dd hh24:mi:ss') as inc_datetime,trunc(dbms_random.value(0,100)) as random_id,dbms_random.string('x',20) random_string
from dual
connect by level <= 10;
ID INC_DATETIME RANDOM_ID RANDOM_STRING
---------- ------------------- ---------- --------------------------------------------------------------------------------
1 2009-12-08 19:43:14 76 GWMU280MIVBKKOCZV620
2 2009-12-08 19:43:15 34 GNV88O6TDHD3TWC5GWI5
3 2009-12-08 19:43:16 77 LI6H4O5IAHQIMO4B0WMH
4 2009-12-08 19:43:17 99 LP7XP49I0YOJIYSJDQZO
5 2009-12-08 19:43:18 55 V3284X9RXW4UZI8BQMO3
6 2009-12-08 19:43:19 16 T0OA52UAOGHL1TT46H25
7 2009-12-08 19:43:20 61 UY6RUOF7HWTO86942FLP
8 2009-12-08 19:43:21 25 JYXO4OPEW8J1CKVCPDJR
9 2009-12-08 19:43:22 10 DONU6W9QVQM3KJ2UG8LO
10 2009-12-08 19:43:23 76 J8DJLVNOUIZDXE4UXUJG
10 rows selected上面SQL利用Oracle语法的几个实用小技巧实现,均可按需修改
- 利用Oracle特有的connect by树形连接语法生成测试记录,level <= 10 表示要生成10条记录
- 利用rownum虚拟列生成递增的整数数据;
- 利用sysdate函数加一些简单运算来生成日期数据,本例中是每条记录的时间加1秒;
- 利用dbms_random.value函数生成随机的数值型数据,本例中是生成0到100之间的随机整数;
- 利用dbms_random.string函数生成随机的字符型数据,本例中是生成长度为20的随机字符串,字符串中可以包括字符或数字
要生成10万条测试记录表可以用如下SQL
create table myTestTable as
select rownum as id,
to_char(sysdate + rownum/24/3600, 'yyyy-mm-dd hh24:mi:ss') as inc_datetime,
trunc(dbms_random.value(0, 100)) as random_id,
dbms_random.string('x', 20) random_string
from dual
connect by level <= 100000;随机生成测试数据
-- 随机生成测试数据
update es_sms_customer set
sex=floor(dbms_random.value(0,3))
,name=dbms_random.string('A',6)
,id_card=111311198305100988 + floor(dbms_random.value(0,811311198305100988))
,house_phone='0'||floor(dbms_random.value(1000000001,80000000000))
,mobile=10000000000 + floor(dbms_random.value(3111111111,3999999999))
,fax='0'||floor(dbms_random.value(1000000001,80000000000))
,post_code=''||floor(dbms_random.value(100001,999999))
,email=dbms_random.string('L',6)||'@'||dbms_random.string('L',4)||'.com'
,qq=floor(dbms_random.value(10000001,999999999))
,addr=dbms_random.string('L',16)
,birth_day=birth_day+365*floor(dbms_random.value(1,50))
,occupation=floor(dbms_random.value(0,5))
,fixed_assets=floor(dbms_random.value(0,8))
,car_owner=floor(dbms_random.value(0,3))
,car_buy_time=birth_day+365*floor(dbms_random.value(1,50))
,car_brand=dbms_random.string('L',5)
,bui_name=dbms_random.string('L',5)
,car_price=floor(dbms_random.value(5,500))
,bui_area_count=floor(dbms_random.value(80,300))
,bui_addr=dbms_random.string('L',10)
,bui_post=''||floor(dbms_random.value(100001,999999))
,bui_manager=dbms_random.string('L',10)
,bui_developer=dbms_random.string('L',10)
where rownum<1000;参考
















 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











