









开发反馈测试环境突然连接不上了,没有报错,但一直无法连接。测试用sys用户可连接,system用户连接不上但没有报错,与开发描述现象一致。
检查alert日志发现一行报错,懵逼…不知道是啥
![]()
看了下等待事件,发现有很多异常,其中最异常是log file switch(archiving needed)
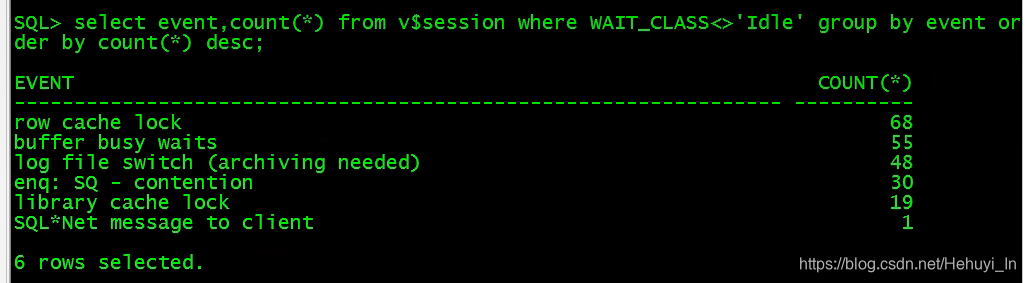
以为是归档空间满了,检查了下归档目录,发现权限不对…

改回正常权限
chown -R orauat.oinstall /archive等了一段时间后异常等待均消失,开发反馈能正常登录了
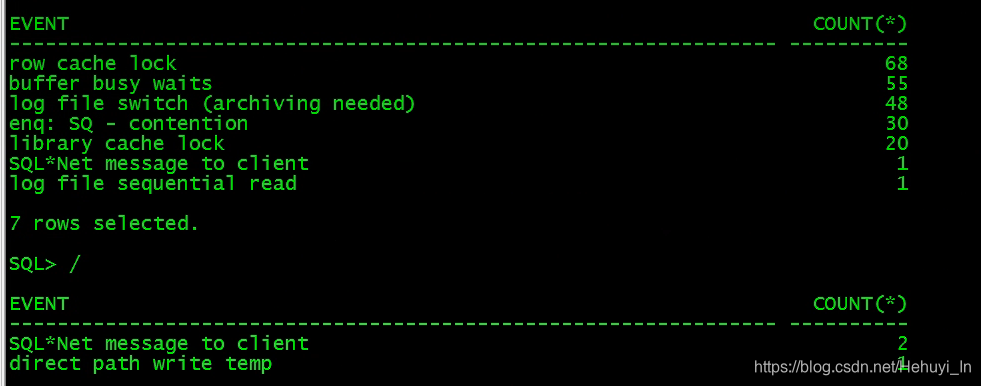
虽然问题处理了,但还是很好奇 minact-scn useg scan erroring out with error e12751 究竟是啥,根据 Alert Log Shows: "minact-scn: useg scan erroring out with error e:12751" Warning (文档 ID 1478691.1) :
这个问题与undo和MMON进程有关,它说明undo段scan由于 ORA-12751 报错失败了,而 ORA-12751 报错是由于MMON进程操作消耗CPU过高或执行时间过长(15分钟,为什么是15分钟,参考 Troubleshooting ORA-12751 "cpu time or run time policy violation" Errors (文档 ID 761298.1)),这个报错通常是由于系统负载过高导致的。
It is indicating that an undo segment scan has failed with an ORA-12751 error.
ORA-12751 "cpu time or run time policy violation"
ORA-12751 indicates that some part of MMON operation is either taking too much CPU or is taking too long to complete.
The messages are an indication of high load on the system as opposed to the cause of the problem.
对于11.2.0.2版本,有一个 Bug 11891463 : MINACT-SCN MASTER-STATUS MESSAGES WRITTEN TO MMON TRACE FILE 会导致此问题,参考 Minact-Scn Master-Status: Grec-Scn Messages In Trace File (文档 ID 1361567.1)
另外如果在数据库执行 ALTER SYSTEM SUSPEND; 语句,也会遇到此问题,需要用 ALTER SYSTEM RESUME; 来解。参考 Error 'minact-scn: useg scan erroring out with error e:12751' and 'WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK' After Backup Initiation (文档 ID 2020577.1)。
最后整理下这个报错产生的原因:
- 数据库打开归档,但归档目录权限设置错误,归档日志无法写入
- redo日志无法归档,出现大量 log file switch(archiving needed) 异常等待
- 进而导致大量其他异常等待事件
- 数据库被hang,用户登录时在等待library cache lock,因此无法登录但没有报错
- 等待越积越多导致系统负载过高,MMON进程相关操作无法在指定时间内完成,导致ORA-12751报错
- undo段scan由于 ORA-12751 报错失败,在日志里记下了 minact-scn useg scan erroring out with error e12751
变更操作还是要仔细谨慎,这要是个生产库就悲剧了。


















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











