










一、 为什么需要Checkpoint
1. 事务日志增多的问题
- WAL占用大量磁盘空间
- 故障恢复需要redo的WAL日志过多,速度太慢
因此,我们需要这样一个时间点
- 这个时间点之前的所有脏数据页已经落盘,因此:
- 这个时间点之前所有的WAL可以被删除,释放磁盘空间
- 故障恢复时,以这个时间点为起点,开始WAL的REDO操作,大大缩短恢复时间
这个时间点,就是检查点。
2. Checkpoint的主要作用
就是前面提到的那几点,后面我们会再具体看是怎么实现的
- 脏页刷入
- 删除旧WAL:创建检查点后此位置之前的WAL可以删除
- 故障恢复起点
由于代码中xlog和wal这俩一直混着用,下面写的时候基本也就按照代码里的叫法,它俩是一个东西。
二、 主要结构体
1. checkpoint
检查点XLog记录的结构体,我们暂时只会用到第一个变量,因此这里只记第一个。
// Body of CheckPoint XLOG records.
typedef struct CheckPoint
{
XLogRecPtr redo; /* next RecPtr available when we began to create CheckPoint (i.e. REDO start point) */
…
} CheckPoint;这个redo变量就是redo point,所谓的故障恢复起点(一般略早于检查点记录)。
redo point的特性是在它之前所有XLOG对应的数据都已经落盘。那么与其去找redo point不如构建redo point。怎么构建呢?
当前日志写入的位置为Insert->CurrBytePos,那么只要在这个时候将数据页面中的所有数据都落盘,那么在落盘完成之后,Insert->CurrBytePos之前的所有XLOG对应的数据都落盘了,Insert->CurrBytePos自然成为了redo point,数据页落盘的时其他的事务可以正常的开始或提交。这就是PostgreSQL实现checkpoint的核心思想。


2. ControlFileData
ControlFileData是控制文件的数据结构,包含很多信息,这里我们只看一些后面会用的。
typedef struct ControlFileData
{
/*
* System status data
*/
DBState state; /* 数据库状态 */
XLogRecPtr checkPoint; /* 最近一次chekpoint的位置 */
XLogRecPtr prevCheckPoint; /* 上一次chekpoint的位置 */
} ControlFileData;- state:数据库的状态,重启时可以通过state来判断之前数据库是否正常关闭,如果没有正常关闭,则进入恢复流程。
- checkPoint:最近一次checkpoint的位置。checkpoint实际就是上面提到的CheckPoint结构体,其中存放了redopoint。在checkpoint流程的最后,这个结构体中的数据会被作为一条XLOG写入日志文件并落盘。 而这条XLOG的LSN就会被记录在ControlFileData的checkPoint成员中。所以在恢复时,通过checkPoint就可以获取到CheckPoint结构体中的数据,从而得到redopoint。
- prevCheckPoint:在checkpoint的流程中也可能出现系统故障,所以checkPoint对应的数据不一定正确,所以pg使用prevCheckPoint来存放上一次chekpoint的位置,如果最近一次的chekpoint不靠谱,那么就从上一次的checkpoint开始恢复。
3. 控制文件中的redo点与检查点
执行pg_controldata命令,可以找到这两个位置:
-bash-4.2$ pg_controldata |grep checkpoint
...
Latest checkpoint location: 0/CA0B680
Latest checkpoint's REDO location: 0/CA0B648在后面我们会学习到,检查点创建的流程是:先记录redo point,再将脏页落盘,再更新控制文件(即ControlFile->checkPoint),记录检查点位置。这之间会有一个时间差,因此redo point一般略早于检查点记录,从上面也可以看出来确实是这样。
postgresql源码学习(32)—— 检查点④-核心函数CreateCheckPoint_Hehuyi_In的博客-CSDN博客
4. CheckpointerShmemStruct
checkpointer进程和其他后台进程之间通讯的共享内存结构,也是一个重要的数据结构。
typedef struct
{
pid_t checkpointer_pid; /* 检查点进程pid,未启动时为0 */
slock_t ckpt_lck; /* 自旋锁,用于保护ckpt_*成员变量 */
int ckpt_started; /* 计数器,开始一个新检查点时+1 */
int ckpt_done; /* 计数器,检查点完成后+1 */
int ckpt_failed; /* 计数器,创建检查点失败时+1 */
int ckpt_flags; /* 标记位,下面会提到 */
ConditionVariable start_cv; /* 当ckpt_started +1时触发的信号量 */
ConditionVariable done_cv; /* 当ckpt_done +1时触发的信号量*/
uint32 num_backend_writes; /* 计数器,用户进程缓存写的次数 */
uint32 num_backend_fsync; /* 计数器,用户进程fsync调用次数 */
int num_requests; /* current # of requests,当前请求数 */
int max_requests; /* 数组最大size */
CheckpointerRequest requests[FLEXIBLE_ARRAY_MEMBER]; //请求数组
} CheckpointerShmemStruct;
static CheckpointerShmemStruct *CheckpointerShmem;三、 何时触发Checkpoint
1. 主要标记位
以下标记位直接影响CreateCheckPoint及其附属函数的行为
/* These directly affect the behavior of CreateCheckPoint and subsidiaries
* 以下标记位直接影响CreateCheckPoint及其附属函数的行为 */
/* 停库时触发 */
#define CHECKPOINT_IS_SHUTDOWN 0x0001
/* 类似shutdown checkpoint,但在WAL故障恢复结束时触发 */
#define CHECKPOINT_END_OF_RECOVERY 0x0002
/* 尽快完成检查点,无需考虑IO使用情况,无视checkpoint_completion_target 参数 */
#define CHECKPOINT_IMMEDIATE 0x0004
/* 强制触发检查点,即使没有活跃的XLOG */
#define CHECKPOINT_FORCE 0x0008
/* 将所有页刷入磁盘,包括unlogged tables */
#define CHECKPOINT_FLUSH_ALL 0x0010
/* 以下参数对于RequestCheckpoint函数(下篇会学习)很重要 */
/* 检查点完成时才通知用户(否则,只告知检查点进程正在处理,然后通知用户) */
#define CHECKPOINT_WAIT 0x0020
/* 表明该检查点是由RequestCheckpoint函数创建的 */
#define CHECKPOINT_REQUESTED 0x0040
/* 以下参数指示了请求检查点的原因 */
/* XLOG日志达到一定数量 */
#define CHECKPOINT_CAUSE_XLOG 0x0080
/* 超时机制,默认值 checkpoint_timeout = 5min */
#define CHECKPOINT_CAUSE_TIME 0x0100 2. 总结检查点可能的触发条件:
- 停库(smart者fast模式)
- 数据库recovery完成
- 开始备份(pg_start_backup,也包括备份工具例如 pg_basebackup)
- 手动执行checkpoint命令
- 生成WAL日志达到一定数量,由几个参数共同决定(参考下面)
- 超时机制,默认值 checkpoint_timeout = 5min
- create 和drop database的时候(网上看到的)
- wal日志总大小超过参数max_wal_size设置(网上看到的)
// checkpointer.c GUC parameters
int CheckPointTimeout = 300;再来看看XLOG日志数量和超时机制的判断函数
四、 XLOG日志数量判断
1. XLogCheckpointNeeded函数
XLogCheckpointNeeded函数根据新增日志数量判断是否需要执行检查点,新增量超过CheckPointSegments时则需要,很简单的一个小函数。
/*
* Check whether we've consumed enough xlog space that a checkpoint is needed.
*
* new_segno indicates a log file that has just been filled up (or read
* during recovery). We measure the distance from RedoRecPtr to new_segno
* and see if that exceeds CheckPointSegments.
*/
static bool
XLogCheckpointNeeded(XLogSegNo new_segno)
{
XLogSegNo old_segno;
// 上次检查点对应的日志段ID
XLByteToSeg(RedoRecPtr, old_segno, wal_segment_size);
// 如果新的段ID增量超过了CheckPointSegments,则触发新检查点
if (new_segno >= old_segno + (uint64) (CheckPointSegments - 1))
return true;
return false;
}2. CalculateCheckpointSegments函数
CheckPointSegments的值由CalculateCheckpointSegments函数根据 max_wal_size_mb 和 checkpoint_completion_target 参数计算
/*
* Calculate CheckPointSegments based on max_wal_size_mb and
* checkpoint_completion_target.
*/
static void
CalculateCheckpointSegments(void)
{
double target;
target = (double) ConvertToXSegs(max_wal_size_mb, wal_segment_size) / (1.0 + CheckPointCompletionTarget);
/* round down */
CheckPointSegments = (int) target;
if (CheckPointSegments < 1)
CheckPointSegments = 1;
}ConvertToXSegs的定义为
#define ConvertToXSegs(x, segsize) XLogMBVarToSegs((x), (segsize))XLogMBVarToSegs的定义为
#define XLogMBVarToSegs(mbvar, wal_segsz_bytes) ((mbvar) / ((wal_segsz_bytes) / (1024 * 1024)))所以ConvertToXSegs(max_wal_size_mb, wal_segment_size)= max_wal_size_mb/wal_segment_size_bytes/(1024 * 1024),其实就是为了统一单位。
以默认参数为例,ConvertToXSegs(max_wal_size_mb, wal_segment_size)就是64。
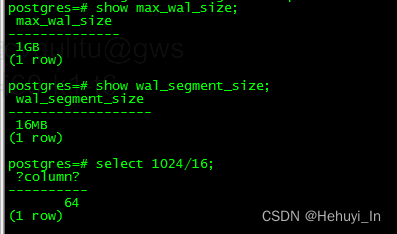
CheckPointCompletionTarget就是checkpoint_completion_target参数的值,默认0.9。
所以CheckPointSegments = int(64/(1+0.9)) = 33,也就是当生成日志数超过33个时,需要做检查点。
五、 超时机制的判断
这个判断在主入口函数CheckpointerMain(下篇会介绍),非常简单的一个判断。
now = (pg_time_t) time(NULL);
elapsed_secs = now - last_checkpoint_time;
if (elapsed_secs >= CheckPointTimeout)
continue; /* no sleep for us ... */这个if外层是一个死循环 for (;;),超时执行continue意味着开始了下一轮检查点处理。
参考
《PostgreSQL技术内幕:事务处理深度探索》第4章
《Postgresql修炼之道:从小工到专家》
postgresql checkpoint原理浅析-杨向博.pdf - 墨天轮文档
PostgreSQL的checkpoint简析_points
TDSQL | 《checkpoint 原理浅析》_Wandssss的博客-CSDN博客
PgSQL · 特性分析 · checkpoint机制浅析-阿里云开发者社区
PgSQL · 特性分析 · 谈谈checkpoint的调度 · 数据库内核月报 · 看云
https://blog.csdn.net/obvious__/article/details/119300225
postgresql源码学习(32)—— 检查点④-核心函数CreateCheckPoint_Hehuyi_In的博客-CSDN博客
















 3083
3083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











