









今晚跟cursor斗智斗勇一个小时,终于成功实现抓取《数据库内核月报》的需求,比起csdn过程坎坷不少,知识点也更多,也更充分体现了提示词、需求拆解和分析的重要性。
过程太长,先简单记录聊天过程,后续有时间再细化整理
一、 初始需求
你是一个Python爬虫专家,你需要生成一段Python代码,获取 http://mysql.taobao.org/monthly/ 中的所有文章链接,并将文档内容以markdown格式存放在本地taobao目录中。
其他注意事项:
1. 分辨页面渲染方式,避免链接抓取错误
2. 为提升获取效率,你应该考虑利用多线程及其他技术提效
3. 避免被反爬技术拦截
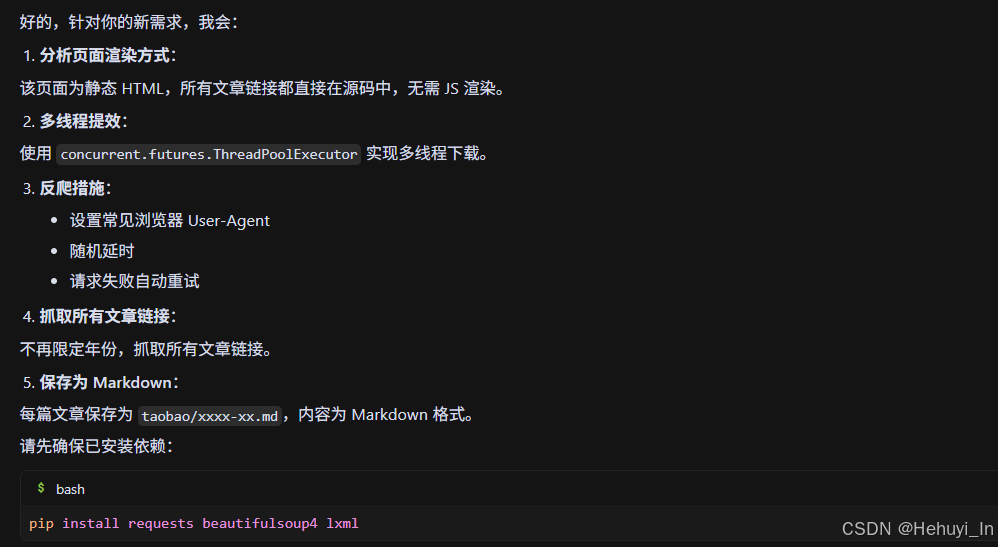
推荐代码如下:
import os
import re
import time
import random
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor, as_completed
BASE_URL = "http://mysql.taobao.org/monthly/"
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
SAVE_DIR = "taobao"
MAX_RETRIES = 3
THREADS = 8
os.makedirs(SAVE_DIR, exist_ok=True)
def get_with_retry(url, retries=MAX_RETRIES, **kwargs):
for i in range(retries):
try:
resp = requests.get(url, headers=HEADERS, timeout=10, **kwargs)
if resp.status_code == 200:
return resp
except Exception:
if i == retries - 1:
raise
time.sleep(random.uniform(1, 3))
return None
def get_all_links():
resp = get_with_retry(BASE_URL)
soup = BeautifulSoup(resp.text, "lxml")
links = []
for a in soup.select("a"):
href = a.get("href", "")
# 文章链接通常形如 202x-xx.html
if re.match(r"\d{4}-\d{2}\.html", href):
links.append(BASE_URL + href)
return links
def save_article(url):
try:
resp = get_with_retry(url)
soup = BeautifulSoup(resp.text, "lxml")
# 获取文章标题
title = soup.title.text.strip() if soup.title else url.split("/")[-1]
# 获取正文内容
content_div = soup.find("div", class_="content")
if not content_div:
content_div = soup.find("div", id="content")
content = content_div.get_text("\n", strip=True) if content_div else soup.get_text("\n", strip=True)
# 生成markdown内容
md_content = f"# {title}\n\n原文链接: [{url}]({url})\n\n---\n\n{content}"
# 文件名
filename = os.path.join(SAVE_DIR, url.split("/")[-1].replace(".html", ".md"))
with open(filename, "w", encoding="utf-8") as f:
f.write(md_content)
print(f"已保存: {filename}")
# 随机延时,防止被封
time.sleep(random.uniform(0.5, 1.5))
except Exception as e:
print(f"下载失败: {url},原因: {e}")
def main():
links = get_all_links()
print(f"共发现{len(links)}篇文章,开始下载...")
with ThreadPoolExecutor(max_workers=THREADS) as executor:
futures = [executor.submit(save_article, url) for url in links]
for future in as_completed(futures):
pass
print("全部下载完成。")
if __name__ == "__main__":
main()二、 共发现0篇文章
文章获取失败,提示“共发现0篇文章,开始下载”,分析原因并优化代码实现
问题分析:
- 你的爬虫代码之所以“共发现0篇文章”,很可能是因为页面源码中的文章链接格式与你的正则表达式不符,或者页面内容被重定向、反爬等原因影响,导致没有正确抓取到链接。
优化建议:
- 调试页面源码:直接打印页面源码的前几百字符,确认文章链接的真实格式。
- 放宽正则匹配:有些链接可能不是 202x-xx.html,而是 202x-xx/ 或其他格式。
- 检查编码和反爬:有些网站会根据 User-Agent 返回不同内容,或返回乱码。
调试代码片段(建议先运行,观察输出):
import requests
url = "http://mysql.taobao.org/monthly/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
resp = requests.get(url, headers=headers)
print(resp.status_code)
print(resp.apparent_encoding)
print(resp.text[:1000]) # 打印前1000字符请运行上面代码,贴出输出内容,这样我可以帮你精准调整正则和解析逻辑,确保能抓到所有文章链接。
如果你希望我直接给出更鲁棒的爬虫代码,也可以告知你希望的策略(比如:更宽松的正则、直接抓取所有以 .html 结尾的链接等)。
结果如下
D:\book_download\venv\Scripts\python.exe D:/book_download/book_download/book/ai_get_url.py
200
utf-8
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- <title>æ°æ®åºå æ ¸ææ¥</title> -->
<meta name="description" content="æ°æ®åºå æ ¸ææ¥, æ¥çé¿éäº PolarDB æ°æ®åºå æ ¸å¢éã">
<link rel="stylesheet" href="/monthly/css/typo.css">
<link rel="stylesheet" href="/monthly/css/animate.css">
<link rel="stylesheet" href="/monthly/css/main.css">
<link rel="canonical" href="http://mysql.taobao.org//monthly/">
<link rel="alternate" type="application/rss+xml" title="æ°æ®åºå æ ¸ææ¥" href="http://mysql.taobao.org//monthly/feed.xml" />
<link rel="stylesheet" href="//cdn.staticfile.org/highlight.js/8.3/styles/tomorrow.min.css">
<script src="/monthly/js/highlight.min.js"></script>
<!-- <link rel="stylesheet" href="/monthly/themes/tomorrow.css">
<script src="/monthly/highlight/highlight.pack.js"> -->
<script>hl
Process finished with exit code 0
感谢你提供的输出!
页面返回状态码 200,编码为 utf-8,且源码内容正常,但你贴出的只是前几行,还未包含文章链接部分。
不过,这已经说明页面没有被重定向或反爬拦截。
调试代码如下:
import requests
from bs4 import BeautifulSoup
url = "http://mysql.taobao.org/monthly/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, "lxml")
# 打印所有a标签的href
for a in soup.find_all("a"):
print(a.get("href"))请运行上面代码,把输出贴出来,这样我可以帮你精准写出能抓到所有文章链接的正则和爬虫代码。
调试代码返回结果如下
/monthly/
/monthly/2025/04
/monthly/2025/03
/monthly/2025/02
/monthly/2025/01
/monthly/2024/12
/monthly/2024/11
/monthly/2024/10...
import os
import re
import time
import random
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor, as_completed
BASE_URL = "http://mysql.taobao.org"
MONTHLY_URL = BASE_URL + "/monthly/"
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
SAVE_DIR = "taobao"
MAX_RETRIES = 3
THREADS = 8
os.makedirs(SAVE_DIR, exist_ok=True)
def get_with_retry(url, retries=MAX_RETRIES, **kwargs):
for i in range(retries):
try:
resp = requests.get(url, headers=HEADERS, timeout=10, **kwargs)
if resp.status_code == 200:
return resp
except Exception:
if i == retries - 1:
raise
time.sleep(random.uniform(1, 3))
return None
def get_all_article_links():
resp = get_with_retry(MONTHLY_URL)
soup = BeautifulSoup(resp.text, "lxml")
links = set()
for a in soup.find_all("a", href=True):
href = a["href"]
# 匹配 /monthly/YYYY/MM 目录
m = re.match(r"/monthly/(\d{4})/(\d{2})$", href)
if m:
links.add(BASE_URL + href)
return sorted(links)
def save_article(url):
try:
resp = get_with_retry(url)
soup = BeautifulSoup(resp.text, "lxml")
# 获取文章标题
title = soup.title.text.strip() if soup.title else url.split("/")[-2] + "-" + url.split("/")[-1]
# 获取正文内容
content_div = soup.find("div", class_="content")
if not content_div:
content_div = soup.find("div", id="content")
content = content_div.get_text("\n", strip=True) if content_div else soup.get_text("\n", strip=True)
# 生成markdown内容
md_content = f"# {title}\n\n原文链接: [{url}]({url})\n\n---\n\n{content}"
# 文件名
filename = os.path.join(SAVE_DIR, url.rstrip("/").split("/")[-2] + "-" + url.rstrip("/").split("/")[-1] + ".md")
with open(filename, "w", encoding="utf-8") as f:
f.write(md_content)
print(f"已保存: {filename}")
time.sleep(random.uniform(0.5, 1.5))
except Exception as e:
print(f"下载失败: {url},原因: {e}")
def main():
links = get_all_article_links()
print(f"共发现{len(links)}篇文章,开始下载...")
with ThreadPoolExecutor(max_workers=THREADS) as executor:
futures = [executor.submit(save_article, url) for url in links]
for future in as_completed(futures):
pass
print("全部下载完成。")
if __name__ == "__main__":
main()三、抓取目录链接而非文章内容
有两个问题
1. 你抓取的文章中文显示有乱码
05
MySQL · 5.7ä¼å · Metadata Lockåç³»ç»çä¼å
06
MySQL · 5.7ç¹æ§ · å¨çº¿Truncate undo log 表空é´
2. 你抓取的是每个目录中的文章链接,而非目录中实际的文章内容
你的反馈非常关键,下面针对两个问题详细分析并给出解决方案:
1. 中文乱码问题
原因分析:
- 乱码通常是因为 requests 没有正确识别网页编码,或者网页实际编码与 resp.text 的解码方式不一致。
- 该站点页面 <meta charset="utf-8">,但有时 requests 识别不准,需强制设定编码。
解决方法:
- 在获取响应后,强制设置 resp.encoding = 'utf-8',再用 resp.text。
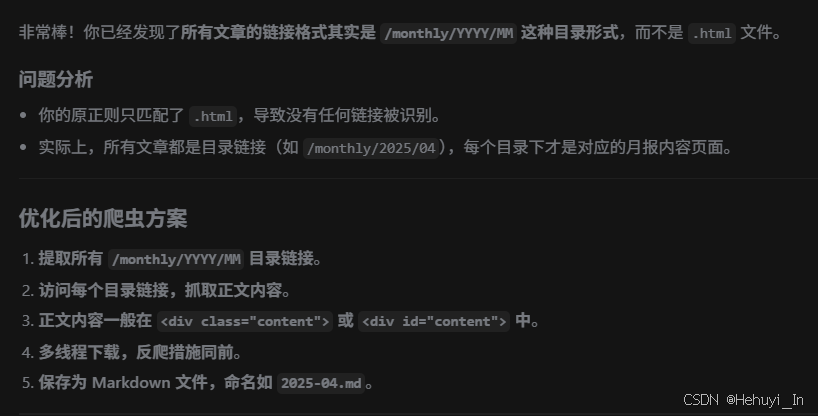
2. 抓取的是目录中的文章链接,而非实际文章内容
原因分析:
- 你现在抓到的是每个月的目录页(如 /monthly/2025/04),但实际内容在该目录页的正文部分(通常是 <div class="content">),而不是该页下的其他链接。
- 你只需抓取每个目录页的正文内容即可,无需再进入子链接。
- 只抓取每个 /monthly/YYYY/MM 目录页的正文内容。
- 强制设置编码,解决中文乱码。
import os
import re
import time
import random
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor, as_completed
BASE_URL = "http://mysql.taobao.org"
MONTHLY_URL = BASE_URL + "/monthly/"
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
SAVE_DIR = "taobao"
MAX_RETRIES = 3
THREADS = 8
os.makedirs(SAVE_DIR, exist_ok=True)
def get_with_retry(url, retries=MAX_RETRIES, **kwargs):
for i in range(retries):
try:
resp = requests.get(url, headers=HEADERS, timeout=10, **kwargs)
resp.encoding = 'utf-8' # 强制设定编码,防止中文乱码
if resp.status_code == 200:
return resp
except Exception:
if i == retries - 1:
raise
time.sleep(random.uniform(1, 3))
return None
def get_all_article_links():
resp = get_with_retry(MONTHLY_URL)
soup = BeautifulSoup(resp.text, "lxml")
links = set()
for a in soup.find_all("a", href=True):
href = a["href"]
# 匹配 /monthly/YYYY/MM 目录
m = re.match(r"/monthly/(\d{4})/(\d{2})$", href)
if m:
links.add(BASE_URL + href)
return sorted(links)
def save_article(url):
try:
resp = get_with_retry(url)
soup = BeautifulSoup(resp.text, "lxml")
# 获取文章标题
title = soup.title.text.strip() if soup.title else url.split("/")[-2] + "-" + url.split("/")[-1]
# 获取正文内容
content_div = soup.find("div", class_="content")
if not content_div:
content_div = soup.find("div", id="content")
if content_div:
content = content_div.get_text("\n", strip=True)
else:
content = soup.get_text("\n", strip=True)
# 生成markdown内容
md_content = f"# {title}\n\n原文链接: [{url}]({url})\n\n---\n\n{content}"
# 文件名
filename = os.path.join(SAVE_DIR, url.rstrip("/").split("/")[-2] + "-" + url.rstrip("/").split("/")[-1] + ".md")
with open(filename, "w", encoding="utf-8") as f:
f.write(md_content)
print(f"已保存: {filename}")
time.sleep(random.uniform(0.5, 1.5))
except Exception as e:
print(f"下载失败: {url},原因: {e}")
def main():
links = get_all_article_links()
print(f"共发现{len(links)}篇文章,开始下载...")
with ThreadPoolExecutor(max_workers=THREADS) as executor:
futures = [executor.submit(save_article, url) for url in links]
for future in as_completed(futures):
pass
print("全部下载完成。")
if __name__ == "__main__":
main()3. 需求再拆解
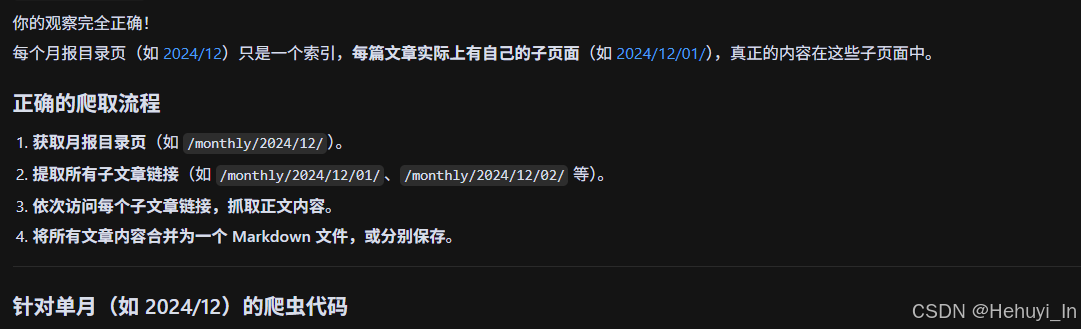
中文显示问题解决了,但抓取的仍然是目录下的文章标题而非文章内容。这样,你先尝试帮我获取 @http://mysql.taobao.org/monthly/2024/12/ 目录下的文章内容,还是以markdown格式保存 在taobao目录下

import os
import requests
from bs4 import BeautifulSoup
url = "http://mysql.taobao.org/monthly/2024/12/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
SAVE_DIR = "taobao"
os.makedirs(SAVE_DIR, exist_ok=True)
resp = requests.get(url, headers=headers, timeout=10)
resp.encoding = 'utf-8'
soup = BeautifulSoup(resp.text, "lxml")
# 获取标题
title = soup.find("h1")
md_content = f"# {title.text.strip() if title else '数据库内核月报'}\n\n原文链接: [{url}]({url})\n\n---\n\n"
# 获取所有条目(通常是h3或h2标题+后续内容)
for tag in soup.find_all(['h3', 'h2']):
# 只抓取以“# XX”开头的条目
if tag.text.strip().startswith("#"):
md_content += f"## {tag.text.strip()}\n\n"
# 收集该标题下的所有段落,直到下一个h3/h2
for sibling in tag.find_next_siblings():
if sibling.name in ['h3', 'h2']:
break
# 只抓正文段落和列表
if sibling.name in ['p', 'ul', 'ol', 'pre', 'blockquote']:
md_content += sibling.get_text("\n", strip=True) + "\n\n"
filename = os.path.join(SAVE_DIR, "2024-12.md")
with open(filename, "w", encoding="utf-8") as f:
f.write(md_content)
print(f"已保存: {filename}")还是有问题,你并没有打开目录中的子链接,例如第一篇文章打开后是 @http://mysql.taobao.org/monthly/2024/12/01/ ,你应该逐个打开链接并获取文章内容
import os
import re
import requests
from bs4 import BeautifulSoup
BASE_URL = "http://mysql.taobao.org"
MONTH_URL = "/monthly/2024/12/"
FULL_MONTH_URL = BASE_URL + MONTH_URL
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
SAVE_DIR = "taobao"
os.makedirs(SAVE_DIR, exist_ok=True)
def get_soup(url):
resp = requests.get(url, headers=HEADERS, timeout=10)
resp.encoding = 'utf-8'
return BeautifulSoup(resp.text, "lxml")
def get_article_links(month_url):
soup = get_soup(month_url)
links = []
for a in soup.find_all("a", href=True):
href = a["href"]
# 匹配 /monthly/2024/12/01/ 这种子文章链接
if re.match(r"/monthly/2024/12/\d{2}/$", href):
# 绝对化
if not href.startswith("http"):
href = BASE_URL + href
links.append(href)
return sorted(set(links))
def get_article_content(article_url):
soup = get_soup(article_url)
# 标题
h2 = soup.find("h2")
title = h2.text.strip() if h2 else article_url.split("/")[-2]
# 正文
content_div = soup.find("div", class_="content")
if not content_div:
content_div = soup.find("div", id="content")
content = content_div.get_text("\n", strip=True) if content_div else soup.get_text("\n", strip=True)
return f"## {title}\n\n原文链接: [{article_url}]({article_url})\n\n{content}\n\n---\n"
def main():
article_links = get_article_links(FULL_MONTH_URL)
print(f"共发现{len(article_links)}篇文章")
md_content = f"# 数据库内核月报 2024/12\n\n原文目录: [{FULL_MONTH_URL}]({FULL_MONTH_URL})\n\n---\n\n"
for link in article_links:
print(f"抓取: {link}")
md_content += get_article_content(link)
filename = os.path.join(SAVE_DIR, "2024-12.md")
with open(filename, "w", encoding="utf-8") as f:
f.write(md_content)
print(f"已保存: {filename}")
if __name__ == "__main__":
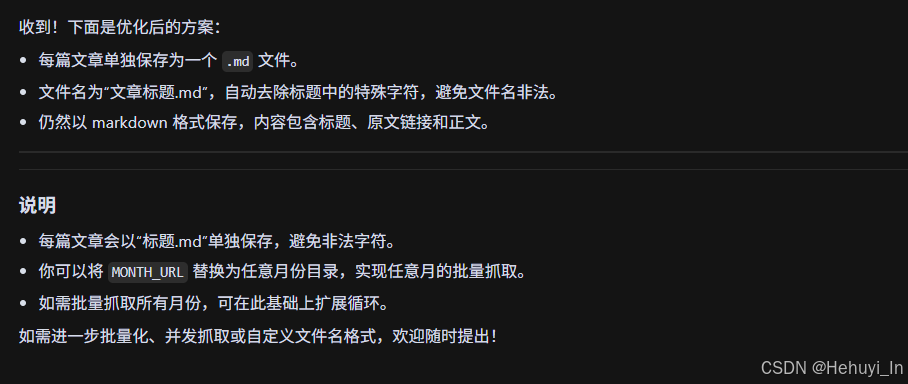
main()就是这样,干得漂亮~ 但你需要将每篇文章单独存放在 .md文件里,并以文章标题作为文件名,加油
import os
import re
import requests
from bs4 import BeautifulSoup
BASE_URL = "http://mysql.taobao.org"
MONTH_URL = "/monthly/2024/12/"
FULL_MONTH_URL = BASE_URL + MONTH_URL
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
SAVE_DIR = "taobao"
os.makedirs(SAVE_DIR, exist_ok=True)
def safe_filename(title):
# 只保留中英文、数字、下划线和横线
return re.sub(r'[\\/:*?"<>|]', '', title).strip()
def get_soup(url):
resp = requests.get(url, headers=HEADERS, timeout=10)
resp.encoding = 'utf-8'
return BeautifulSoup(resp.text, "lxml")
def get_article_links(month_url):
soup = get_soup(month_url)
links = []
for a in soup.find_all("a", href=True):
href = a["href"]
# 匹配 /monthly/2024/12/01/ 这种子文章链接
if re.match(r"/monthly/2024/12/\d{2}/$", href):
# 绝对化
if not href.startswith("http"):
href = BASE_URL + href
links.append(href)
return sorted(set(links))
def save_article(article_url):
soup = get_soup(article_url)
# 标题
h2 = soup.find("h2")
title = h2.text.strip() if h2 else article_url.split("/")[-2]
filename = safe_filename(title) + ".md"
# 正文
content_div = soup.find("div", class_="content")
if not content_div:
content_div = soup.find("div", id="content")
content = content_div.get_text("\n", strip=True) if content_div else soup.get_text("\n", strip=True)
md_content = f"# {title}\n\n原文链接: [{article_url}]({article_url})\n\n{content}\n"
filepath = os.path.join(SAVE_DIR, filename)
with open(filepath, "w", encoding="utf-8") as f:
f.write(md_content)
print(f"已保存: {filepath}")
def main():
article_links = get_article_links(FULL_MONTH_URL)
print(f"共发现{len(article_links)}篇文章")
for link in article_links:
save_article(link)
print("全部下载完成。")
if __name__ == "__main__":
main()

四、 格式化内容
内容ok,帮我再格式化一下里面的文本和代码,使其比较美观
import os
import re
import requests
from bs4 import BeautifulSoup
BASE_URL = "http://mysql.taobao.org"
MONTH_URL = "/monthly/2024/12/"
FULL_MONTH_URL = BASE_URL + MONTH_URL
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
SAVE_DIR = "taobao"
os.makedirs(SAVE_DIR, exist_ok=True)
def safe_filename(title):
# 只保留中英文、数字、下划线和横线
return re.sub(r'[\\/:*?"<>|]', '', title).strip()
def get_soup(url):
resp = requests.get(url, headers=HEADERS, timeout=10)
resp.encoding = 'utf-8'
return BeautifulSoup(resp.text, "lxml")
def get_article_links(month_url):
soup = get_soup(month_url)
links = []
for a in soup.find_all("a", href=True):
href = a["href"]
# 匹配 /monthly/2024/12/01/ 这种子文章链接
if re.match(r"/monthly/2024/12/\d{2}/$", href):
# 绝对化
if not href.startswith("http"):
href = BASE_URL + href
links.append(href)
return sorted(set(links))
def format_content(content_div):
md_lines = []
for elem in content_div.children:
if elem.name == 'pre':
# 代码块
code = elem.get_text("\n", strip=True)
md_lines.append(f'\n```\n{code}\n```\n')
elif elem.name in ['ul', 'ol']:
# 列表
for li in elem.find_all('li'):
md_lines.append(f'- {li.get_text(strip=True)}')
md_lines.append('')
elif elem.name == 'blockquote':
# 引用
quote = elem.get_text("\n", strip=True)
md_lines.append(f'> {quote}\n')
elif elem.name in ['h1', 'h2', 'h3', 'h4', 'h5', 'h6']:
# 标题
level = int(elem.name[1])
md_lines.append(f'\n{"#"*level} {elem.get_text(strip=True)}\n')
elif elem.name == 'p' or elem.name is None:
# 普通段落
text = elem.get_text("\n", strip=True)
if text:
md_lines.append(f'{text}\n')
return '\n'.join(md_lines)
def save_article(article_url):
soup = get_soup(article_url)
# 标题
h2 = soup.find("h2")
title = h2.text.strip() if h2 else article_url.split("/")[-2]
filename = safe_filename(title) + ".md"
# 正文
content_div = soup.find("div", class_="content")
if not content_div:
content_div = soup.find("div", id="content")
if content_div:
content = format_content(content_div)
else:
content = soup.get_text("\n", strip=True)
md_content = f"# {title}\n\n原文链接: [{article_url}]({article_url})\n\n{content}\n"
filepath = os.path.join(SAVE_DIR, filename)
with open(filepath, "w", encoding="utf-8") as f:
f.write(md_content)
print(f"已保存: {filepath}")
def main():
article_links = get_article_links(FULL_MONTH_URL)
print(f"共发现{len(article_links)}篇文章")
for link in article_links:
save_article(link)
print("全部下载完成。")
if __name__ == "__main__":
main()

五、 合并代码,实现初始需求
嗯,就是这样,结合以上思路,回到我们最开始的需求,帮我抓取获取 http://mysql.taobao.org/monthly/ 中的所有文章链接,并将文档内容以markdown格式存放在本地taobao目录中,其余要求不变
import os
import re
import time
import random
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor, as_completed
BASE_URL = "http://mysql.taobao.org"
MONTHLY_URL = BASE_URL + "/monthly/"
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
SAVE_DIR = "taobao"
THREADS = 8
os.makedirs(SAVE_DIR, exist_ok=True)
def safe_filename(title):
return re.sub(r'[\\/:*?"<>|]', '', title).strip()
def get_soup(url):
for _ in range(3):
try:
resp = requests.get(url, headers=HEADERS, timeout=10)
resp.encoding = 'utf-8'
if resp.status_code == 200:
return BeautifulSoup(resp.text, "lxml")
except Exception:
time.sleep(random.uniform(1, 2))
return None
def get_all_month_links():
soup = get_soup(MONTHLY_URL)
links = set()
for a in soup.find_all("a", href=True):
href = a["href"]
# 匹配 /monthly/YYYY/MM 目录
m = re.match(r"/monthly/(\d{4})/(\d{2})$", href)
if m:
links.add(BASE_URL + href + "/")
return sorted(links)
def get_article_links(month_url):
soup = get_soup(month_url)
links = []
if not soup:
return links
for a in soup.find_all("a", href=True):
href = a["href"]
# 匹配 /monthly/YYYY/MM/XX/ 这种子文章链接
m = re.match(r"/monthly/\d{4}/\d{2}/\d{2}/$", href)
if m:
if not href.startswith("http"):
href = BASE_URL + href
links.append(href)
return sorted(set(links))
def format_content(content_div):
md_lines = []
for elem in content_div.children:
if elem.name == 'pre':
code = elem.get_text("\n", strip=True)
md_lines.append(f'\n```\n{code}\n```\n')
elif elem.name in ['ul', 'ol']:
for li in elem.find_all('li'):
md_lines.append(f'- {li.get_text(strip=True)}')
md_lines.append('')
elif elem.name == 'blockquote':
quote = elem.get_text("\n", strip=True)
md_lines.append(f'> {quote}\n')
elif elem.name in ['h1', 'h2', 'h3', 'h4', 'h5', 'h6']:
level = int(elem.name[1])
md_lines.append(f'\n{"#"*level} {elem.get_text(strip=True)}\n')
elif elem.name == 'p' or elem.name is None:
text = elem.get_text("\n", strip=True)
if text:
md_lines.append(f'{text}\n')
return '\n'.join(md_lines)
def save_article(article_url):
soup = get_soup(article_url)
if not soup:
print(f"获取失败: {article_url}")
return
h2 = soup.find("h2")
title = h2.text.strip() if h2 else article_url.split("/")[-2]
filename = safe_filename(title) + ".md"
content_div = soup.find("div", class_="content")
if not content_div:
content_div = soup.find("div", id="content")
if content_div:
content = format_content(content_div)
else:
content = soup.get_text("\n", strip=True)
md_content = f"# {title}\n\n原文链接: [{article_url}]({article_url})\n\n{content}\n"
filepath = os.path.join(SAVE_DIR, filename)
with open(filepath, "w", encoding="utf-8") as f:
f.write(md_content)
print(f"已保存: {filepath}")
time.sleep(random.uniform(0.5, 1.2))
def main():
month_links = get_all_month_links()
print(f"共发现{len(month_links)}个月份")
all_article_links = []
for month_url in month_links:
article_links = get_article_links(month_url)
print(f"{month_url} 发现{len(article_links)}篇文章")
all_article_links.extend(article_links)
print(f"总共发现{len(all_article_links)}篇文章,开始下载...")
with ThreadPoolExecutor(max_workers=THREADS) as executor:
futures = [executor.submit(save_article, url) for url in all_article_links]
for future in as_completed(futures):
pass
print("全部下载完成。")
if __name__ == "__main__":
main()
六、 目录细化,抓取图片
干得漂亮~ 需求已基本实现,有一些优化项:
1. 帮我按照链接中的年份及月份创建子目录,并将对应月份的文章放入其中
2. 只需要抓取2024及2025年的文章
3. 如果文章中有表格、图片等,也需要抓取下来
import os
import re
import time
import random
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor, as_completed
from urllib.parse import urljoin, urlparse
BASE_URL = "http://mysql.taobao.org"
MONTHLY_URL = BASE_URL + "/monthly/"
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
SAVE_DIR = "taobao"
THREADS = 8
os.makedirs(SAVE_DIR, exist_ok=True)
def safe_filename(title):
return re.sub(r'[\\/:*?"<>|]', '', title).strip()
def get_soup(url):
for _ in range(3):
try:
resp = requests.get(url, headers=HEADERS, timeout=10)
resp.encoding = 'utf-8'
if resp.status_code == 200:
return BeautifulSoup(resp.text, "lxml")
except Exception:
time.sleep(random.uniform(1, 2))
return None
def get_all_month_links():
soup = get_soup(MONTHLY_URL)
links = set()
for a in soup.find_all("a", href=True):
href = a["href"]
# 只抓2024和2025年
m = re.match(r"/monthly/(2024|2025)/(\d{2})$", href)
if m:
links.add(BASE_URL + href + "/")
return sorted(links)
def get_article_links(month_url):
soup = get_soup(month_url)
links = []
if not soup:
return links
for a in soup.find_all("a", href=True):
href = a["href"]
# 匹配 /monthly/2024/12/01/ 这种子文章链接
m = re.match(r"/monthly/(2024|2025)/\d{2}/\d{2}/$", href)
if m:
if not href.startswith("http"):
href = BASE_URL + href
links.append(href)
return sorted(set(links))
def download_image(img_url, save_path):
try:
resp = requests.get(img_url, headers=HEADERS, timeout=10)
if resp.status_code == 200:
with open(save_path, 'wb') as f:
f.write(resp.content)
return True
except Exception:
pass
return False
def format_table(table):
rows = table.find_all('tr')
md = []
for i, row in enumerate(rows):
cols = row.find_all(['td', 'th'])
line = '| ' + ' | '.join(col.get_text(strip=True) for col in cols) + ' |'
md.append(line)
if i == 0:
md.append('|' + '---|' * len(cols))
return '\n'.join(md) + '\n'
def format_content(content_div, article_url, save_dir):
md_lines = []
for elem in content_div.children:
if elem.name == 'pre':
code = elem.get_text("\n", strip=True)
md_lines.append(f'\n```\n{code}\n```\n')
elif elem.name in ['ul', 'ol']:
for li in elem.find_all('li'):
md_lines.append(f'- {li.get_text(strip=True)}')
md_lines.append('')
elif elem.name == 'blockquote':
quote = elem.get_text("\n", strip=True)
md_lines.append(f'> {quote}\n')
elif elem.name in ['h1', 'h2', 'h3', 'h4', 'h5', 'h6']:
level = int(elem.name[1])
md_lines.append(f'\n{"#"*level} {elem.get_text(strip=True)}\n')
elif elem.name == 'p' or elem.name is None:
text = elem.get_text("\n", strip=True)
if text:
md_lines.append(f'{text}\n')
elif elem.name == 'table':
md_lines.append(format_table(elem))
elif elem.name == 'img':
img_src = elem.get('src')
if img_src:
img_url = urljoin(article_url, img_src)
img_name = os.path.basename(urlparse(img_url).path)
img_save_path = os.path.join(save_dir, img_name)
if download_image(img_url, img_save_path):
md_lines.append(f'\n')
# 处理段落内图片
for img in content_div.find_all('img'):
img_src = img.get('src')
if img_src:
img_url = urljoin(article_url, img_src)
img_name = os.path.basename(urlparse(img_url).path)
img_save_path = os.path.join(save_dir, img_name)
if download_image(img_url, img_save_path):
# 替换原img为markdown图片语法
img.replace_with(f'')
return '\n'.join(md_lines)
def save_article(article_url, year, month):
soup = get_soup(article_url)
if not soup:
print(f"获取失败: {article_url}")
return
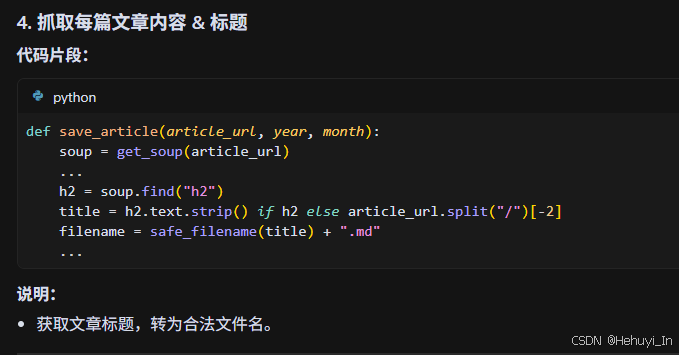
h2 = soup.find("h2")
title = h2.text.strip() if h2 else article_url.split("/")[-2]
filename = safe_filename(title) + ".md"
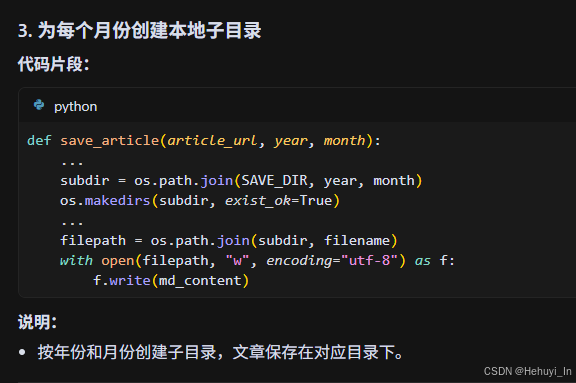
# 按年份和月份创建子目录
subdir = os.path.join(SAVE_DIR, year, month)
os.makedirs(subdir, exist_ok=True)
content_div = soup.find("div", class_="content")
if not content_div:
content_div = soup.find("div", id="content")
if content_div:
content = format_content(content_div, article_url, subdir)
else:
content = soup.get_text("\n", strip=True)
md_content = f"# {title}\n\n原文链接: [{article_url}]({article_url})\n\n{content}\n"
filepath = os.path.join(subdir, filename)
with open(filepath, "w", encoding="utf-8") as f:
f.write(md_content)
print(f"已保存: {filepath}")
time.sleep(random.uniform(0.5, 1.2))
def main():
month_links = get_all_month_links()
print(f"共发现{len(month_links)}个月份")
all_tasks = []
for month_url in month_links:
m = re.match(r".*/monthly/(2024|2025)/(\d{2})/", month_url)
if not m:
continue
year, month = m.group(1), m.group(2)
article_links = get_article_links(month_url)
print(f"{month_url} 发现{len(article_links)}篇文章")
for link in article_links:
all_tasks.append((link, year, month))
print(f"总共发现{len(all_tasks)}篇文章,开始下载...")
with ThreadPoolExecutor(max_workers=THREADS) as executor:
futures = [executor.submit(save_article, url, year, month) for url, year, month in all_tasks]
for future in as_completed(futures):
pass
print("全部下载完成。")
if __name__ == "__main__":
main()
嗯,图片不要单独保存,需要嵌入回.md文档里,这样方便用户查询
import os
import re
import time
import random
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor, as_completed
from urllib.parse import urljoin
BASE_URL = "http://mysql.taobao.org"
MONTHLY_URL = BASE_URL + "/monthly/"
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
SAVE_DIR = "taobao"
THREADS = 8
os.makedirs(SAVE_DIR, exist_ok=True)
def safe_filename(title):
return re.sub(r'[\\/:*?"<>|]', '', title).strip()
def get_soup(url):
for _ in range(3):
try:
resp = requests.get(url, headers=HEADERS, timeout=10)
resp.encoding = 'utf-8'
if resp.status_code == 200:
return BeautifulSoup(resp.text, "lxml")
except Exception:
time.sleep(random.uniform(1, 2))
return None
def get_all_month_links():
soup = get_soup(MONTHLY_URL)
links = set()
for a in soup.find_all("a", href=True):
href = a["href"]
m = re.match(r"/monthly/(2024|2025)/(\d{2})$", href)
if m:
links.add(BASE_URL + href + "/")
return sorted(links)
def get_article_links(month_url):
soup = get_soup(month_url)
links = []
if not soup:
return links
for a in soup.find_all("a", href=True):
href = a["href"]
m = re.match(r"/monthly/(2024|2025)/\d{2}/\d{2}/$", href)
if m:
if not href.startswith("http"):
href = BASE_URL + href
links.append(href)
return sorted(set(links))
def format_table(table):
rows = table.find_all('tr')
md = []
for i, row in enumerate(rows):
cols = row.find_all(['td', 'th'])
line = '| ' + ' | '.join(col.get_text(strip=True) for col in cols) + ' |'
md.append(line)
if i == 0:
md.append('|' + '---|' * len(cols))
return '\n'.join(md) + '\n'
def format_content(content_div, article_url):
md_lines = []
for elem in content_div.children:
if elem.name == 'pre':
code = elem.get_text("\n", strip=True)
md_lines.append(f'\n```\n{code}\n```\n')
elif elem.name in ['ul', 'ol']:
for li in elem.find_all('li'):
md_lines.append(f'- {li.get_text(strip=True)}')
md_lines.append('')
elif elem.name == 'blockquote':
quote = elem.get_text("\n", strip=True)
md_lines.append(f'> {quote}\n')
elif elem.name in ['h1', 'h2', 'h3', 'h4', 'h5', 'h6']:
level = int(elem.name[1])
md_lines.append(f'\n{"#"*level} {elem.get_text(strip=True)}\n')
elif elem.name == 'p' or elem.name is None:
text = elem.get_text("\n", strip=True)
if text:
md_lines.append(f'{text}\n')
elif elem.name == 'table':
md_lines.append(format_table(elem))
elif elem.name == 'img':
img_src = elem.get('src')
if img_src:
img_url = urljoin(article_url, img_src)
md_lines.append(f'\n')
# 处理段落内图片
for img in content_div.find_all('img'):
img_src = img.get('src')
if img_src:
img_url = urljoin(article_url, img_src)
img.replace_with(f'')
return '\n'.join(md_lines)
def save_article(article_url, year, month):
soup = get_soup(article_url)
if not soup:
print(f"获取失败: {article_url}")
return
h2 = soup.find("h2")
title = h2.text.strip() if h2 else article_url.split("/")[-2]
filename = safe_filename(title) + ".md"
subdir = os.path.join(SAVE_DIR, year, month)
os.makedirs(subdir, exist_ok=True)
content_div = soup.find("div", class_="content")
if not content_div:
content_div = soup.find("div", id="content")
if content_div:
content = format_content(content_div, article_url)
else:
content = soup.get_text("\n", strip=True)
md_content = f"# {title}\n\n原文链接: [{article_url}]({article_url})\n\n{content}\n"
filepath = os.path.join(subdir, filename)
with open(filepath, "w", encoding="utf-8") as f:
f.write(md_content)
print(f"已保存: {filepath}")
time.sleep(random.uniform(0.5, 1.2))
def main():
month_links = get_all_month_links()
print(f"共发现{len(month_links)}个月份")
all_tasks = []
for month_url in month_links:
m = re.match(r".*/monthly/(2024|2025)/(\d{2})/", month_url)
if not m:
continue
year, month = m.group(1), m.group(2)
article_links = get_article_links(month_url)
print(f"{month_url} 发现{len(article_links)}篇文章")
for link in article_links:
all_tasks.append((link, year, month))
print(f"总共发现{len(all_tasks)}篇文章,开始下载...")
with ThreadPoolExecutor(max_workers=THREADS) as executor:
futures = [executor.submit(save_article, url, year, month) for url, year, month in all_tasks]
for future in as_completed(futures):
pass
print("全部下载完成。")
if __name__ == "__main__":
main()
图片没有显示成功呢
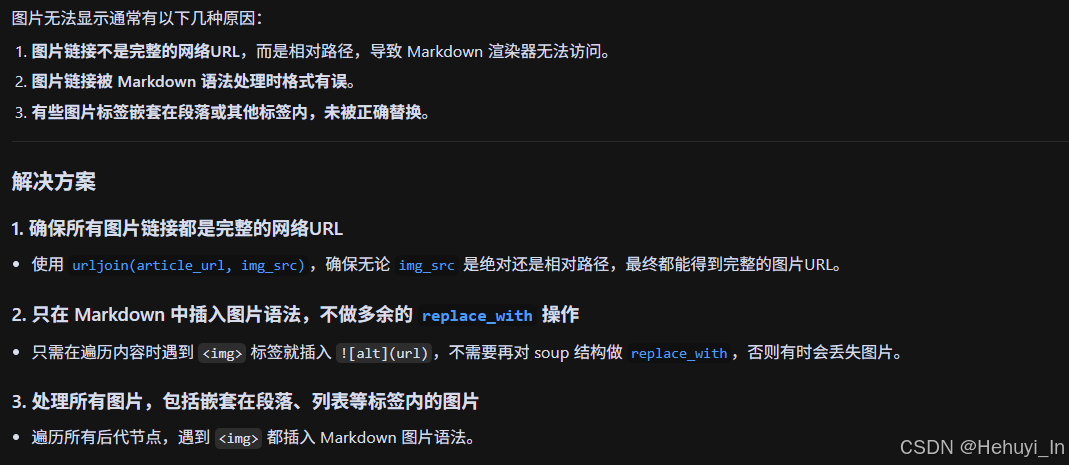

结合你这个优化思路,再优化下之前那段代码,使抓取的图片能在.md文件中直接展示
import os
import re
import time
import random
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor, as_completed
from urllib.parse import urljoin
BASE_URL = "http://mysql.taobao.org"
MONTHLY_URL = BASE_URL + "/monthly/"
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
SAVE_DIR = "taobao"
THREADS = 8
os.makedirs(SAVE_DIR, exist_ok=True)
def safe_filename(title):
# 只保留中英文、数字、下划线和横线
return re.sub(r'[\\/:*?"<>|]', '', title).strip()
def get_soup(url):
for _ in range(3):
try:
resp = requests.get(url, headers=HEADERS, timeout=10)
resp.encoding = 'utf-8'
if resp.status_code == 200:
return BeautifulSoup(resp.text, "lxml")
except Exception:
time.sleep(random.uniform(1, 2))
return None
def get_all_month_links():
soup = get_soup(MONTHLY_URL)
links = set()
for a in soup.find_all("a", href=True):
href = a["href"]
# 只抓2024和2025年
m = re.match(r"/monthly/(2024|2025)/(\d{2})$", href)
if m:
links.add(BASE_URL + href + "/")
return sorted(links)
def get_article_links(month_url):
soup = get_soup(month_url)
links = []
if not soup:
return links
for a in soup.find_all("a", href=True):
href = a["href"]
# 匹配 /monthly/2024/12/01/ 这种子文章链接
m = re.match(r"/monthly/(2024|2025)/\d{2}/\d{2}/$", href)
if m:
if not href.startswith("http"):
href = BASE_URL + href
links.append(href)
return sorted(set(links))
def format_table(table):
rows = table.find_all('tr')
md = []
for i, row in enumerate(rows):
cols = row.find_all(['td', 'th'])
line = '| ' + ' | '.join(col.get_text(strip=True) for col in cols) + ' |'
md.append(line)
if i == 0:
md.append('|' + '---|' * len(cols))
return '\n'.join(md) + '\n'
def format_content(content_div, article_url):
md_lines = []
for elem in content_div.children:
if elem.name == 'pre':
code = elem.get_text("\n", strip=True)
md_lines.append(f'\n```\n{code}\n```\n')
elif elem.name in ['ul', 'ol']:
for li in elem.find_all('li', recursive=False):
# 处理列表项中的图片
imgs = li.find_all('img')
for img in imgs:
img_src = img.get('src')
if img_src:
img_url = urljoin(article_url, img_src)
md_lines.append(f'')
text = li.get_text(" ", strip=True)
if text:
md_lines.append(f'- {text}')
md_lines.append('')
elif elem.name == 'blockquote':
quote = elem.get_text("\n", strip=True)
md_lines.append(f'> {quote}\n')
elif elem.name in ['h1', 'h2', 'h3', 'h4', 'h5', 'h6']:
level = int(elem.name[1])
md_lines.append(f'\n{"#"*level} {elem.get_text(strip=True)}\n')
elif elem.name == 'p' or elem.name is None:
# 处理段落中的图片
if hasattr(elem, 'find_all'):
imgs = elem.find_all('img')
for img in imgs:
img_src = img.get('src')
if img_src:
img_url = urljoin(article_url, img_src)
md_lines.append(f'')
text = elem.get_text("\n", strip=True)
if text:
md_lines.append(f'{text}\n')
elif elem.name == 'table':
md_lines.append(format_table(elem))
return '\n'.join(md_lines)
def save_article(article_url, year, month):
soup = get_soup(article_url)
if not soup:
print(f"获取失败: {article_url}")
return
h2 = soup.find("h2")
title = h2.text.strip() if h2 else article_url.split("/")[-2]
filename = safe_filename(title) + ".md"
# 按年份和月份创建子目录
subdir = os.path.join(SAVE_DIR, year, month)
os.makedirs(subdir, exist_ok=True)
content_div = soup.find("div", class_="content")
if not content_div:
content_div = soup.find("div", id="content")
if content_div:
content = format_content(content_div, article_url)
else:
content = soup.get_text("\n", strip=True)
md_content = f"# {title}\n\n原文链接: [{article_url}]({article_url})\n\n{content}\n"
filepath = os.path.join(subdir, filename)
with open(filepath, "w", encoding="utf-8") as f:
f.write(md_content)
print(f"已保存: {filepath}")
time.sleep(random.uniform(0.5, 1.2))
def main():
month_links = get_all_month_links()
print(f"共发现{len(month_links)}个月份")
all_tasks = []
for month_url in month_links:
m = re.match(r".*/monthly/(2024|2025)/(\d{2})/", month_url)
if not m:
continue
year, month = m.group(1), m.group(2)
article_links = get_article_links(month_url)
print(f"{month_url} 发现{len(article_links)}篇文章")
for link in article_links:
all_tasks.append((link, year, month))
print(f"总共发现{len(all_tasks)}篇文章,开始下载...")
with ThreadPoolExecutor(max_workers=THREADS) as executor:
futures = [executor.submit(save_article, url, year, month) for url, year, month in all_tasks]
for future in as_completed(futures):
pass
print("全部下载完成。")
if __name__ == "__main__":
main()终于终于,需求实现~
七、 执行效果
抓取成功~

文章效果
八、 最佳提示词总结
总结我们的对话,我应该给你什么样的提示词,能让你在第一次就生成这段目标代码呢
最佳提示词(Prompt)示例
你是一个Python爬虫专家。请帮我用Python编写一个高效的爬虫,要求如下:
- 目标网站:抓取 http://mysql.taobao.org/monthly/ 下2024和2025年所有月报文章。
- 目录结构:自动识别所有2024和2025年下的月份和文章链接,并按“年份/月份”创建本地子目录(如 taobao/2024/12/)。
- 内容保存:每篇文章内容以 markdown 格式单独保存为 .md 文件,文件名为文章标题,放在对应的子目录下。
- 内容格式:正文内容需美观排版,支持代码块、表格(转为markdown表格)、列表、引用等常见格式。
- 图片处理:文章中的图片在 markdown 文件中以原始网络URL嵌入(即 ),无需下载到本地,确保在md预览时可直接显示。
- 效率与反爬:支持多线程下载,设置User-Agent、随机延时、自动重试等反爬措施。
- 健壮性:遇到网络异常、页面结构变化等情况能自动跳过并继续。
- 依赖说明:请注明所需的第三方库。
请直接给出完整、可运行的Python代码。
这样写的好处
- 明确了目标范围(2024/2025年、所有月报、所有文章)
- 明确了目录结构和文件命名
- 明确了内容格式和图片处理方式
- 明确了效率和反爬要求
- 明确了健壮性和依赖
你可以根据实际需求增减细节,但只要覆盖上述要点,基本可以一次性获得你想要的高质量爬虫代码!
九、 知识点学习
为了实现这个需求,你的最终代码生成思路是什么样的呢,帮忙一步步列出。这段代码中的重点和难点分别是什么,涉及到哪些知识点?帮忙结合代码分析,我不太清楚你的步骤对应代码中的哪些内容
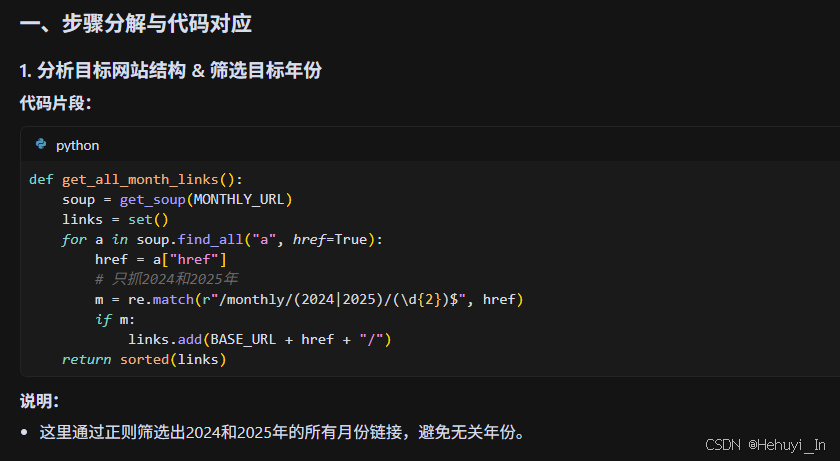
1. 步骤分解与代码对应
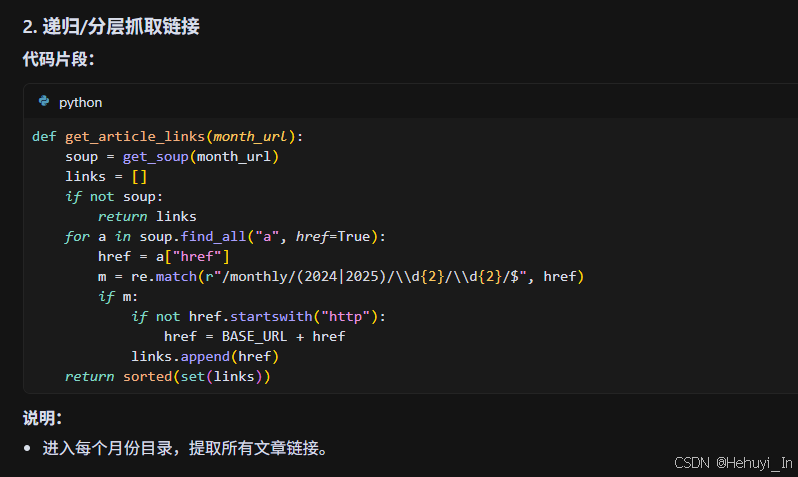
2. 重点与难点代码分析
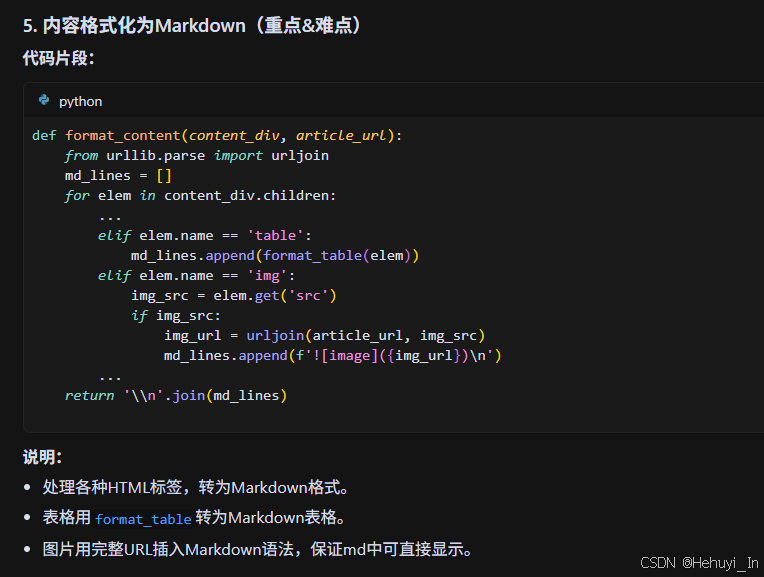
重点1:高质量内容解析与格式化
- format_content 函数负责将HTML正文转为美观的Markdown,兼容各种标签(段落、标题、代码块、表格、图片等)。
- format_table 函数将HTML表格转为Markdown表格。
难点1:图片URL处理
- 用 urljoin(article_url, img_src) 保证图片URL完整,插入 ,确保md中能直接显示图片。
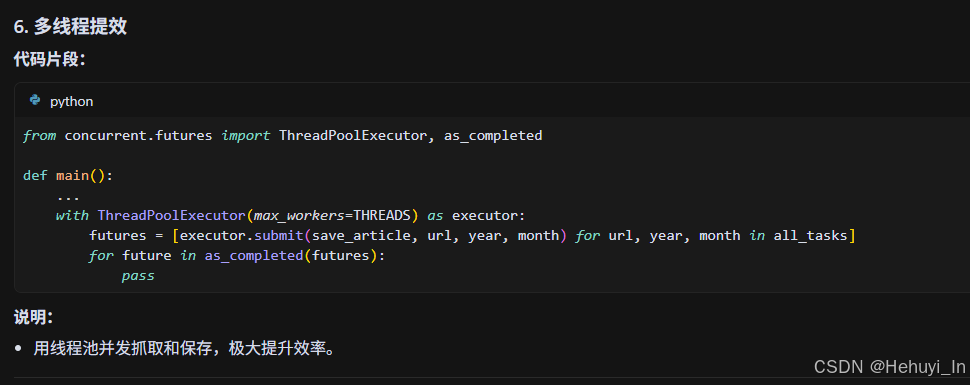
难点2:多线程与异常处理
- ThreadPoolExecutor 并发抓取,get_soup 内部自动重试,保证大批量抓取时的健壮性。
难点3:文件名合法性
- safe_filename 函数去除标题中的非法字符,避免文件保存出错。
3. 涉及知识点与代码位置
- requests/BeautifulSoup:所有网页请求与HTML解析相关函数
- 正则表达式:链接筛选、文件名处理
- os/path:目录和文件操作
- concurrent.futures:多线程并发
- Markdown语法:format_content、format_table等
- 异常处理:try/except、重试机制
4. 总结
- 你可以对照每个函数和代码块,理解它在整个流程中的作用。
- 重点和难点都在内容解析、图片处理、多线程和健壮性上,代码中都有明确实现。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











