



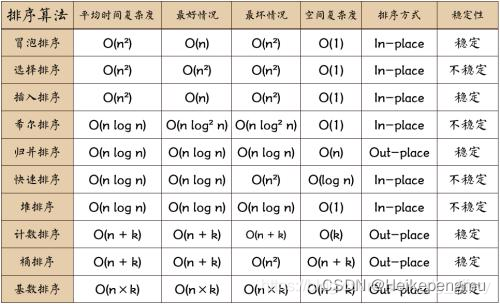
时空复杂度概述
首先o(1), o(n), o(logn), o(nlogn)是用来表示对应算法的时间复杂度,这是算法的时间复杂度的表示。不仅仅用于表示时间复杂度,也用于表示空间复杂度。
算法复杂度分为时间复杂度和空间复杂度。其作用:
时间复杂度是指执行这个算法所需要的计算工作量;
空间复杂度是指执行这个算法所需要的内存空间;
时间和空间都是计算机资源的重要体现,而算法的复杂性就是体现在运行该算法时的计算机所需的资源多少;
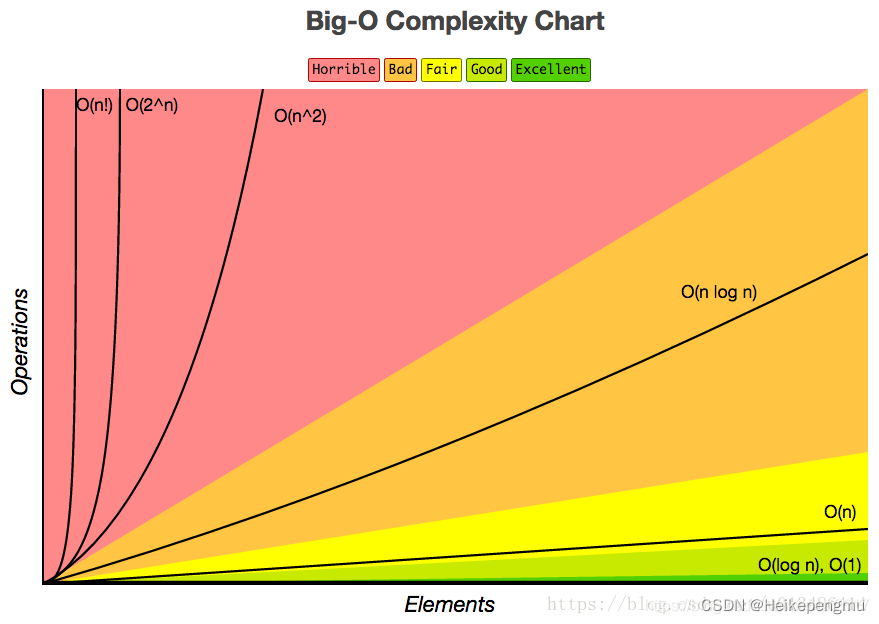
时间复杂度的优劣对比
常见的数量级大小:越小表示算法的执行时间频度越短,则越优;
O(1)<O(logn)<O(n)<O(nlogn)<O(n2)<O(n3)<O(2n)//2的n方<O(n!)<O(nn)//n的n方
O(1)解析
O(1)就是最低的时空复杂度了,也就是耗时/耗空间与输入数据大小无关,无论输入数据增大多少倍,耗时/耗空间都不变。 哈希算法就是典型的O(1)时间复杂度,无论数据规模多大,都可以在一次计算后找到目标(不考虑冲突的话),冲突的话很麻烦的,指向的value会做二次hash到另外一快存储区域。
通俗易懂的例子
什么是O(1)呢,就比如你是一个酒店的管理员,你负责管理酒店的钥匙,你很聪明,你把酒店的100把钥匙放在了100个格子里面存着,并且把格子从1~100进行了编号,有一天有客人来了,酒店老板说,给我拿10号房间的钥匙给我,你迅速从10号格子里面拿出钥匙给老板,速度非常快,这时候你就是一个电脑了,老板跟你说拿几号房房间的钥匙,你只需要看一眼就能知道钥匙在哪里。
O(n)解析
比如时间复杂度为O(n),就代表数据量增大几倍,耗时也增大几倍。
比如常见的遍历算法。要找到一个数组里面最大的一个数,你要把n个变量都扫描一遍,操作次数为n,那么算法复杂度是O(n)。链表遍历是典型的例子。
通俗易懂的例子
突然,有一天,你的老板给你说,你用100个箱子存100把钥匙,太浪费空间了,你能补能把钥匙上编号一下,然后把钥匙要用绳子穿起来,这样我们可以把这个放箱子的地方再装修一个房间出来。你想了一下,是啊,现在房价这么贵,这样能多赚点钱。所以你就不能通过上面的方法来找到钥匙了,老板跟你说,给我拿45号房间的钥匙出来,你就需要从100个钥匙里面挨个找45个房间的钥匙。
O(n^2) 解析
再比如时间复杂度O(n2),就代表数据量增大n倍时,耗时增大n的平方倍,这是比线性更高的时间复杂度。比如冒泡排序,就是典型的O(n2)的算法,对n个数排序,需要扫描n×n次。
用冒泡排序排一个数组,对于n个变量的数组,交换位置n2次数,所以复杂度是n2
通俗易懂的例子
随着经济发展越来越好,你的老板把酒店扩大了,有100层每一层有100个房间,你把每一层的钥匙穿在一起,然后一共就有100个用绳子穿起来的钥匙串。然后老板叫你找钥匙的时候,你先要找到楼层的编号,再对应找到房间的编号,所以大概对应的是这样的代码。
O(log n)解析
再比如O(log n),当数据增大n倍时,耗时增大log n倍(这里的log是以2为底的,比如,当数据增大256倍时,耗时只增大8倍,是比线性还要低的时间复杂度)。二分查找就是O(log n)的算法,每找一次排除一半的可能,256个数据中查找只要找8次就可以找到目标。
通俗易懂的例子
这个就像是有一百把钥匙,你突然觉得,我从头找是不是太慢了,我从中间找,比如我要找到23号的房间钥匙,我从中间切开,找到50编号的位置,然后23在150里面,我再把从中间切开变成25,然后23在125之间,我再切开变成12.5,然后23在12.5~25之间,依次找下去,直到找到钥匙。这种查找钥匙的方法的复杂度就是O(log^n)
O(n log n)解析
O(n log n)同理,就是n乘以log n,当数据增大256倍时,耗时增大256*8=2048倍。这个复杂度高于线性低于平方。归并排序就是O(n log n)的时间复杂度。

















 1727
1727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









