







目录
(1)yarn.nodemanager.resource.memory-mb
(2)yarn.nodemanager.resource.cpu-vcores
(3)yarn.scheduler.maximum-allocation-mb
(4)yarn.scheduler.minimum-allocation-mb
(1)map join——适用于大表 join 小表时存在数据倾斜的场景
(2)skew join——适用于大表 join 大表时存在数据倾斜的场景
(3)调整SQL语句——适用于大表 join 大表时存在数据倾斜的场景
2.使用order by必须有limit过滤——防止全局排序
一、计算资源调优
(一)Yarn资源配置——集群
1.Yarn配置说明
SQL跑得慢可能是资源没给够,需要多分配内存或CPU等资源。需要调整的Yarn参数均与CPU、内存等资源有关,核心配置参数如下:
(1)yarn.nodemanager.resource.memory-mb
该参数的含义是,一个NodeManager节点分配给Container使用的内存,默认为8G。该参数的配置,取决于NodeManager所在节点的总内存容量和该节点运行的其他服务的数量。例如服务器内存为128G,通常情况下可以配置为内存的1/2~2/3,也可以根据实际情况进行配置。内存设置过大,可能会导致yarn无法启动。
考虑上述因素,此处可将该参数设置为64G,如下:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>65536</value>
</property>(2)yarn.nodemanager.resource.cpu-vcores
该参数的含义是,一个NodeManager节点分配给Container使用的CPU核数。该参数的配置,同样取决于NodeManager所在节点的总CPU核数和该节点运行的其他服务。
考虑上述因素,此处可将该参数设置为16。CPU与内存一般情况下通常是1:4的配置关系。
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>16</value>
</property>(3)yarn.scheduler.maximum-allocation-mb
例如给mapper申请的内存是10G,yarn给Container的最大内存为8G,yarn给Conatiner的最小内存为4G,10<(8+4),这样就会导致mapper内存无法申请,因为超过了yarn给mapper内存的规定大小。最大值可以稍微调大,最小值可以稍微调小。
该参数的含义是,单个Container能够使用的最大内存。推荐配置如下:
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
</property>(4)yarn.scheduler.minimum-allocation-mb
该参数的含义是,单个Container能够使用的最小内存,推荐配置如下:
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>hadoop102 hadoop103 hadoop104的虚拟内存设置为16G,电脑实际内存为64G

(二)MapReduce资源配置
如果电脑内存是32G,那么集群的每个节点推荐设置为8G,三个节点,一共8*3=24G,要留一些内存给Windows

yarn-site.xml中的物理内存也要进行相应的修改,要<8G,例如调成6G=6*1024=6144

对应的最大最小内存也要查看是否超出范围

二、SQL执行计划调优
(一)Explain查看执行计划(终点)
Explain查看执行计划:一条SQL语句翻译成了几个map,几个reduce,map和reduce分别做了哪些事情。
1.基本语法
EXPLAIN [FORMATTED | EXTENDED | DEPENDENCY] query-sql注:FORMATTED、EXTENDED、DEPENDENCY关键字为可选项,各自作用如下。
- FORMATTED:将执行计划以JSON字符串的形式输出
- EXTENDED:输出执行计划中的额外信息,通常是读写的文件名等信息
- DEPENDENCY:输出执行计划读取的表及分区
常见的Operator及其作用如下:
- TableScan:表扫描操作,通常map端第一个操作肯定是表扫描操作
- Select Operator:选取操作
- Group By Operator:分组聚合操作
- Reduce Output Operator:输出到 reduce 操作
- Filter Operator:过滤操作
- Join Operator:join 操作
- File Output Operator:文件输出操作
- Fetch Operator 客户端获取数据操作
2.案例
explain select product_id,
count(*)
from order_detail
group by product_id;STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
""
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: order_detail
Statistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: product_id (type: string)
outputColumnNames: product_id
Statistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: count()
keys: product_id (type: string)
mode: hash
" outputColumnNames: _col0, _col1"
Statistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: string)
sort order: +
Map-reduce partition columns: _col0 (type: string)
Statistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: bigint)
Execution mode: vectorized
Reduce Operator Tree:
Group By Operator
aggregations: count(VALUE._col0)
keys: KEY._col0 (type: string)
mode: mergepartial
" outputColumnNames: _col0, _col1"
Statistics: Num rows: 6533388 Data size: 5880049219 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 6533388 Data size: 5880049219 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
""
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
""
explain dependency
select product_id,
count(*)
from order_detail
group by product_id;
{
"input_tables":[
{
"tablename":"db_hive2@order_info",
"tabletype":"MANAGED_TABLE"
}
],
"input_partitions":[
]
}
(二)分组聚合调优
1.优化说明
--启用map-side聚合
set hive.map.aggr=true;--用于检测源表数据是否适合进行map-side聚合。
检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;--用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;--map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;如果根据id分组是不切实际的,因为每行的id都不一样,按照表中重复的数据进行聚合,才有意义。
总结:group by 不重复的字段越小,越适合聚合,不重复的字段越大,越不适合聚合。
如果想让map去做更多的聚合,需要将hive.map.aggr.hash.min.reduction=0.5的值设置为更大,如果值设置为1,所有的都会强制走map聚合。
2.分组聚合优化案例
代码:
explain formatted
select
product_id,
count(*)
from order_detail
group by product_id;-- 优化前:
set hive.map.aggr=false;--(2m16s)
下图可以看到,map端接收的所有数据几乎全部都输出到reduce端


-- 优化后:
set hive.map.aggr=true;-- (1m43s) set hive.map.aggr.hash.min.reduction=1;--(1m23s)如果输出的mapreduce>分组字段的行数(product_id=100w),就说明此处发生flush的次数过多。解决办法:1.flush阈值调大
2.map端的总内存调大set mapreduce.map.memery.mb
mapper端的Group By Operator在内存当中维护一个hash表,然后对数据进行聚合;
reduce端对每一个mapper发送过来的部分的部分聚合的结果进行最终的合并。


(三)Join优化
1.JOIN算法概述
(1)Common Join
Common Join通过一个MapReduce Job完成一个join操作。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。
需要注意的是,sql语句中的join操作和执行计划中的Common Join任务并非一对一的关系,一个sql语句中的相邻的且关联字段相同的多个join操作可以合并为一个Common Join任务。
-- 例如:
-- 关联字段相同是一个Common Join任务实现,也就是可通过一个Map Reduce任务实现。
select a.val, b.val, c.val from a join b on (a.key = b.key1) join c on (c.key = b.key1)-- 关联字段各不相同,需要两个Common Join任务实现,也就是可通过两个Map Reduce任务实现。
select a.val, b.val, c.val from a join b on (a.key = b.key1) join c on (c.key = b.key2)如果多表关联的字段是一样的,都是id,那么就启动一个mapreduce,shuffle的时候就按照同一个字段来进行shuffle;如果多表关联的字段不一样,那么不同的mapper分区字段不同,只能先去做一个common join,然后和c表做下一次join操作,这时就会启动两个mapreduce。
(2)Map Join——Map端完成关联操作
适用场景:大表join小表
一个join由map阶段的两个job完成,即在map端完成关联操作
两个job执行流程:
第一个job读取小表数据→将小表只作为hash表→上传至HDFS→
第二个job从HDFS上读取小表数据→缓存在Map Task内存中→扫描大表数据→
完成关联操作
(3)Bucket Map Join
适用场景:大表join大表,大表join小表
核心思想:参与join的表均为分桶表,且关联字段为分桶字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍,就能保证参与join的两张表的分桶之间具有明确的关联关系,所以就可以在两表的分桶间进行Map Join操作了。这样一来,第二个Job的Map端就无需再缓存小表的全表数据了,而只需缓存其所需的分桶即可。
(4)Sort Merge Bucket Map Join(简称SMB Map Join)
SMB Map Join要求,参与join的表均为分桶表,且需保证分桶内的数据是有序的,且分桶字段、排序字段和关联字段为相同字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍。两个分桶之间的join实现原理为Sort Merge Join算法。Sort Merge Join需要在两张按照关联字段排好序的表中进行。
Hive中的SMB Map Join就是对两个分桶的数据按照上述思路进行Join操作。可以看出,SMB Map Join与Bucket Map Join相比,在进行Join操作时,Map端是无需对整个Bucket构建hash table,也无需在Map端缓存整个Bucket数据的,每个Mapper只需按顺序逐个key读取两个分桶的数据进行join即可。
2.Map Join
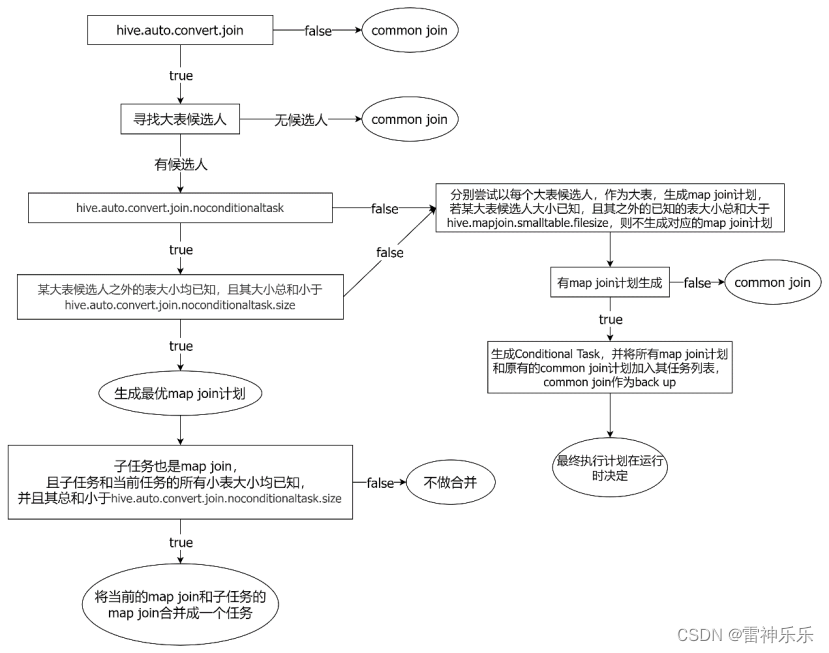
--启动Map Join自动转换
set hive.auto.convert.join=true;一个Common Join operator转为Map Join operator的判断条件,若该Common Join相关的表中,存在n-1张表的已知大小总和<=该值,则生成一个Map Join计划,此时可能存在多种n-1张表的组合均满足该条件,则hive会为每种满足条件的组合均生成一个Map Join计划,同时还会保留原有的Common Join计划作为后备(back up)计划,实际运行时,优先执行Map Join计划,若不能执行成功,则启动Common Join后备计划。
-- 没有条件计划的小表总和的阈值
set hive.mapjoin.smalltable.filesize=250000;--开启无条件转Map Join
set hive.auto.convert.join.noconditionaltask=true;--无条件转Map Join时的小表之和阈值,若一个Common Join operator相关的表中,存在n-1张表的大小总和<=该值,此时hive便不会再为每种n-1张表的组合均生成Map Join计划,同时也不会保留Common Join作为后备计划。而是只生成一个最优的Map Join计划。
-- 有条件计划的小表总和的阈值
set hive.auto.convert.join.noconditionaltask.size=10000000;
判断逻辑:
针对的是执行计划中的Common Join Task,而不是SQL语句中的join语句,SQL中的join与执行计划中的join task不是一一对应,因为join on的字段有可能相同,也有可能不同。
1.总开关:hive.auto.convert.join
false执行common join;
true(默认值)执行自动将common join转换为map join
2.寻找大表候选人:a left join b时,a表是大表候选人;a right join b时,b表时大表候选人;a inner join b时,a表和b表都有可能是大表候选人;a full join b时,走common join。
3.是否不考虑条件任务:hive.auto.convert.join.noconditionaltask
条件任务不是所有场景都需要,如果参与join的表的大小在编译阶段不知道,这时就可以考虑设置条件任务,执行后备的计划;如果参与join的表的大表在编译阶段是知道的,这时条件任务无需考虑。
(1)如果不需要条件任务设置为true:
核心判断逻辑:没有条件任务意味着没有后备计划(即back up计划),此时要保证大表候选人之外的小白的大小均已知,且其小表总和<内存中能够放下的小表总和的阈值(即hive.auto.convert.join.noconditionaltask.size,其作用与hive.mappjoin.smalltable.filesize相同),此时,才会生成最优map join计划(即将三张表进行inner join关联时,将最大的表设置为大表,将最小的两张表设置为小表),此时map端所需内存最小。即使设置了不需要条件任务,但是有些表的大小仍是未知的,也不会生成map join计划,还是会生成Conditional Task。
生成了最优的map join计划之后,还会进行优化:如果多表关联使用的是不同的关联方法,那么就会生成两个map join,例如a left join b,b right join c;a表(大表)和b表会生成一个新的表m,开启一个map join,m表和c表进行关联,也会生成一个map join,且b表和c表的大小是已知的,并且其总和<小表总和的阈值(hive.auto.convert.join.noconditionaltask.size),此时,就会将两个map join合并为一个任务,就能够完成两个common join的任务。如果b表+c表>阈值,两个map join就不会进行合并,还保持原有的map join计划。
(2)如果不需要条件任务设置为false:即开启条件任务
核心的判断逻辑:尝试以每个大表候选人作为大表,生成map join计划,然后利用有限的信息去排除一些一定不能成功的执行计划,判断方法:如果某大表候选人大小已知,且Join的小表总和>设置好的小表总和的阈值(hive.mappjoin.smalltable.filesize),则对应的map join计划就不会生成。如果有map join计划生成,那么就会生成Conditional Task,并将所有map join计划和原油的common join计划加入其任务列表,common join作为back up计划,有back up计划是因为留下来的map join计划也不一定能成功,因为上面只判断了一定不能成功的执行计划。最终执行计划在运行时决定。
案例:
explain formatted select *
from order_detail od
join product_info product on od.product_id = product.id
join province_info province on od.province_id = province.id;优化前:(7min+)
-- 优化前,采用common join -- 总开关关闭 set hive.auto.convert.join=false;-- 优化前的执行计划:两张表进行关联,得到一个新表,然后这个新表和第三张表进行关联,得出结果。
-- 其中一个reduce迟迟不完成,可能是发生了数据倾斜,数据分布不均匀,大量的数据跑到第一个reduce中,该reduce接收的数据很多,处理的时间就会长。
-- reduce的个数是由hive根据数据量估算出来的,没有默认值,也可以设置


优化思路:
必须基于SQL中关联的表的大小来考虑应当采用哪种join算法。
-- 查看表的详细信息语法: desc formatted table_name partition(partition_col='partition'); -- 首先查看order_detail表的信息 desc formatted order_detail;-- 大表 -- 29行:totalSize=1176009934/1024/1024/1024~= 1GB -- product_info表的信息 desc formatted product_info;-- 小表 -- 21行:totalSize=25285707/1024/1024~=25MB -- province_info表的信息 desc formatted province_info;-- 小表 -- 19行:totalSize=369KB
优化方案一:(4min+)
-- 启动map join自动转换 set hive.auto.convert.join=true; -- 不使用无条件转Map Join即开启条件任务对应map join逻辑图的右侧 set hive.auto.convert.join.noconditionaltask=false; -- 调整hive.mapjoin.smalltable.filesize参数,使其>=product_info set hive.mapjoin.smalltable.filesize=25285707;-- 方案一的执行计划十分复杂
只有map没有reduce说明走的是map join,对应上图的stage-8,因为stage-12是本地任务,本地任务是不会把资源提交到yarn上的。
接下来跑的是stage-5:将product_info当成小表,扫描前两个表join的输出结果

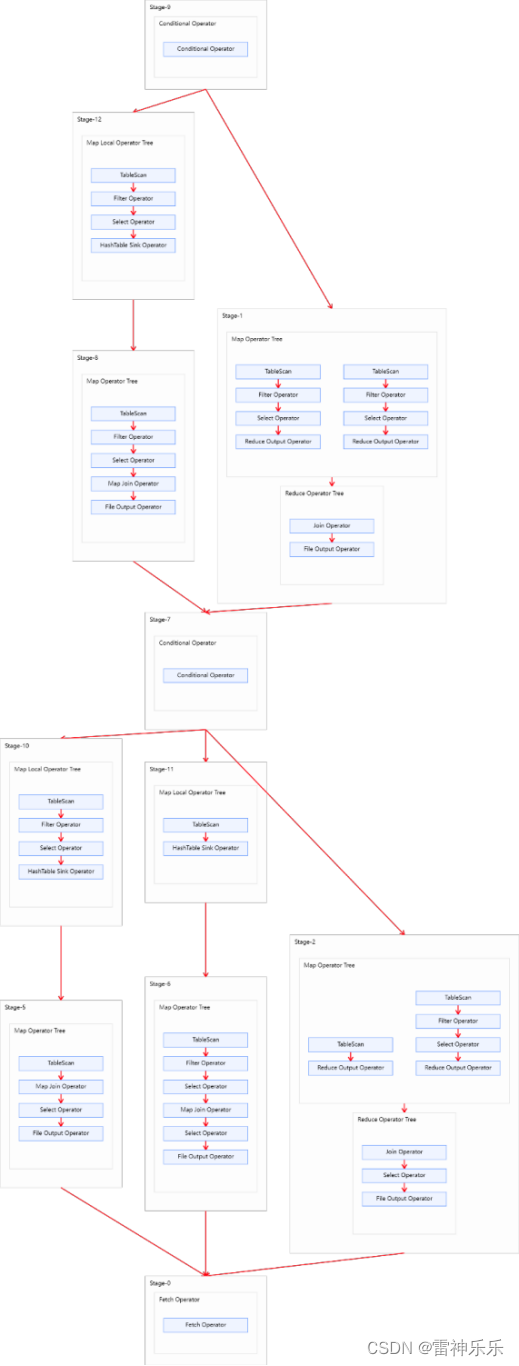



优化方案二:(2min+)——最优执行计划
set hive.auto.convert.join=true; set hive.auto.convert.join.noconditionaltask=true;-- 使用无条件转换 set hive.auto.convert.join.noconditionaltask.size=25286076; -- 调整小表阈值=关联的两张小表之和(product_info+province_info) -- 目的是可以将两个map join进行合并--执行计划:两个map join进行了合并,形成最优map join计划
-- 这个方案计算效率最高,但需要的内存也是最多的。


优化方案三:(4min+)与方案一类似
set hive.auto.convert.join=true; set hive.auto.convert.join.noconditionaltask=true;-- 使用无条件转换 set hive.auto.convert.join.noconditionaltask.size=25285707;-- 设置为小表中较大表(product_info)的大小 -- 这样可直接将两个Common Join operator转为Map Join operator -- 但不会将两个Map Join的任务合并 -- 该方案计算效率比方案二低,但需要的内存也更少。-- 执行计划
province_info和order_info表先做第一次的map join,然后product_info和前两张表join的结果再进行map join,完成输出。


说明:
hive.mapjoin.smalltable.filesize hive.auto.convert.join.noconditionaltask.size这两个参数要根据HDFS存储文件的大小来判断,最终要根据map端的总内存来配置,例如map端的内存设置为4G,阈值设置为1G是不可行的,因为这1G是文件的大小,文件在磁盘中占用的空间和文件加载到内存当中是不一样的,文件加载到内存当中有一个解序列化的过程,也可能是一个个对象,所以文件的大小要远远<文件加载到内存当中的大小。
如果总内存为4G,要拿出1G用来缓存小表,阈值如果也设置为1G,相当于在内存上缓存乘以10的大小,所以,文件大小如果是1G,那么阈值要除以10,即100MB。
3.Bucket Map Join
不支持自动转换
select *
from (
select *
from order_detail
where dt = '2020-06-14'
) od
join(
select *
from payment_detail
where dt = '2020-06-14'
) pd
on od.id = pd.order_detail_id;优化前:
set hive.auto.convert.join=false;-- 执行计划:执行一个普通的common join


优化后:
-- 使用bucket map join,参与join的表必须均为分桶表,且关联字段为分桶字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍
-- 查看两张表的大小 desc formatted order_detail;-- 1G desc formatted payment_detail;-- 320MB+-- 首先需要依据源表创建两个分桶表,order_detail建议分16个bucket,payment_detail建议分8个bucket,注意分桶个数的倍数关系以及分桶字段。
-- 订单表分桶 create table order_detail_bucketed ( id string comment '订单id', user_id string comment '用户id', product_id string comment '商品id', province_id string comment '省份id', create_time string comment '下单时间', product_num int comment '商品件数', total_amount decimal(16, 2) comment '下单金额' ) clustered by (id) into 16 buckets row format delimited fields terminated by '\t'; -- 加载数据 insert overwrite table order_detail_bucketed select id, user_id, product_id, province_id, create_time, product_num, total_amount from order_detail where dt = '2020-06-14'; -- 支付表分桶设置为小表 create table payment_detail_bucketed ( id string comment '支付id', order_detail_id string comment '订单明细id', user_id string comment '用户id', payment_time string comment '支付时间', total_amount decimal(16, 2) comment '支付金额' ) clustered by (order_detail_id) into 8 buckets row format delimited fields terminated by '\t'; -- 加载数据 insert overwrite table payment_detail_bucketed select id, order_detail_id, user_id, payment_time, total_amount from payment_detail where dt = '2020-06-14';-- 然后设置以下参数:
--关闭cbo优化,cbo会导致hint信息被忽略,需将如下参数修改为false set hive.cbo.enable=false; --map join hint默认会被忽略(因为已经过时),需将如下参数修改为false set hive.ignore.mapjoin.hint=false; --启用bucket map join优化功能,默认不启用,需将如下参数修改为true set hive.optimize.bucketmapjoin = true; -- 支付表分桶为小表(320MB+),每个桶都要缓存到map task中,分为8个桶,所以每个桶大概是320MB/8=40MB(文件大小) -- 加载到内存中为40MB*10=400MB,map端内存默认为1024MB,1024>400,所以可以放得下-- 重写sql语句
explain extended select /*+ mapjoin(pd) */ * from order_detail_bucketed od join payment_detail_bucketed pd on od.id = pd.order_detail_id;-- 优化后的执行计划


4.Sort Merge Bucket Map Join
不需要设置小表阈值,也不需要考虑内存的大小
触发Sort Merge Bucket Map Join前提条件:
1.保证参与join的表均为分桶表,且关联字段为分桶字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍;
2.设置以下的参数:
--启动Sort Merge Bucket Map Join优化 set hive.optimize.bucketmapjoin.sortedmerge=true; --使用自动转换SMB Join set hive.auto.convert.sortmerge.join=true;
5.Hive-join优化总结
不需要每个SQL语句都配置参数,通常是全局配置参数。
Map join的配置:大表 join 小表
-- 下面两条要进行全局设置,即在hive-site.xml文件中 set hive.auto.convert.join=true; set hive.auto.convert.join.noconditionaltask=true; -- 下面两条的参数取决于map端的缓存容量,最好是map端总内存的1/2~2/3,记得要除以10 -- 例如map端内存3G,要配置2G来缓存文件,那么下面的参数就要2/10=200MB; set hive.mapjoin.smalltable.filesize=200MB*1024; set hive.auto.convert.join.noconditionaltask.size=200MB*1024;如果只有单条的SQL语句执行时间比其他SQL语句执行时间要长很多,那么就要针对改条SQL语句单独配置参数。
Bucket Map Join的配置:大表 join 大表
考虑分几个桶,也取决于map端的内存
--关闭cbo优化,cbo会导致hint信息被忽略 set hive.cbo.enable=false; --map join hint默认会被忽略(因为已经过时),需将如下参数设置为false set hive.ignore.mapjoin.hint=false; --启用bucket map join优化功能 set hive.optimize.bucketmapjoin = true;SMB Map Join的配置:大表 join 大表
也要分桶,然后设置下面的参数
--启动Sort Merge Bucket Map Join优化 set hive.optimize.bucketmapjoin.sortedmerge=true; --使用自动转换SMB Join set hive.auto.convert.sortmerge.join=true;调研需求,设计架构,开发过程中分析出哪些数据量大,哪些数据量小,提前考虑好数据倾斜的问题,一个reduce能够做完就尽量不要用多个reduce;
设置合理的mapreduce的task数量,在处理数据时测试和监控,基于数据量的大小计算map 、reduce的物理内存,压缩分区,查看是否有数据倾斜的发生,如果有数据倾斜,那么要查看哪些字段的数据会有数据倾斜的发生。
(四)数据倾斜(重要)
1.数据倾斜概述
一条SQL语句的执行需要跑一个map reduce,使用分区字段恰好是分布不均的字段,就会导致在shuffle阶段,大量相同的数据被发往同一个reduce,进而导致该reduce所需的时间远远超过其他reduce,成为整个任务的瓶颈。
业务中不怕数据量大,可以控制并行度,就怕数据倾斜,以为此时并行度即使再大,大量相同的数据仍然会被发往同一个reduce。
2.分组聚合导致的数据倾斜
如果group by分组字段的值分布不均,就可能导致大量相同的key进入同一个reduce,从而导致数据倾斜问题。解决分组聚合导致的数据倾斜问题有以下两种解决思路:
(1)Map-Side聚合
参考(二)1
set hive.map.aggr=true;
set hive.map.aggr.hash.min.reduction=0.5;
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;(2)Skew-GroupBy优化
Skew-GroupBy的原理是启动两个MR任务,第一个MR按照随机数分区,将数据分散发送到Reduce,完成部分聚合,第二个MR按照分组字段分区,完成最终聚合。相关参数如下:
--启用分组聚合数据倾斜优化
set hive.groupby.skewindata=true;
(3)优化案例
-- 查询每个省份的订单数
-- 表中province_id 99%的数据为1,此时就会有数据倾斜
select
province_id,
count(*)
from order_detail
group by province_id;优化前:
set hive.map.aggr=false; set hive.groupby.skewindata=false;
其他的reduce任务都完成,只有一个没有完成,发生了数据倾斜。
方案一在map端维护了hash表,比较耗费内存,如果达到map端的阈值,就会flush一次,当数据量很大,而map端的阈值又相对较小,就会flush很多次。

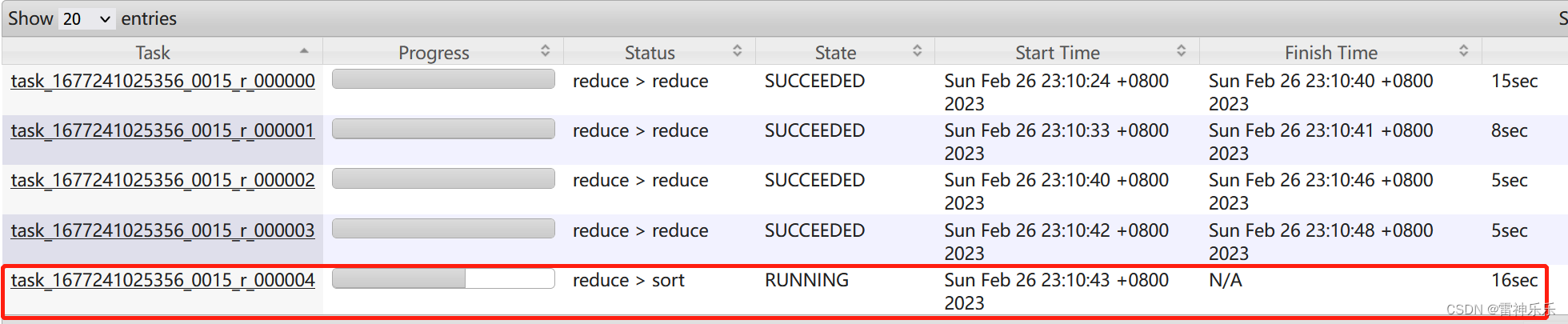
优化后:
-- 方案一:
--启用map-side聚合 set hive.map.aggr=true; --关闭skew-groupby set hive.groupby.skewindata=false;此时每个reduce执行时间是均匀的,没有发生数据倾斜

-- 方案二:
--关闭map-side聚合 set hive.map.aggr=false; --启用skew-groupby set hive.groupby.skewindata=true;此时每个reduce的运行时间相对均匀,但比方案一的时间要长一些
但是方案二比方案一相对好一些,不考虑内存,把数据打散再聚合。

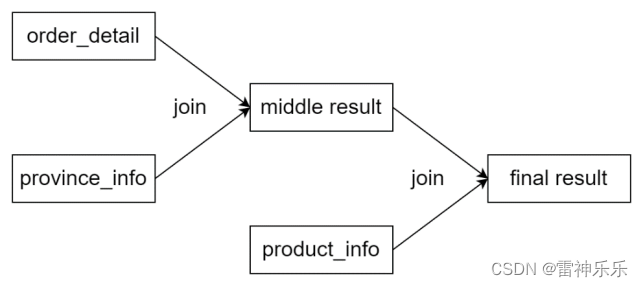
2.Join导致的数据倾斜
前文提到过,未经优化的join操作,默认是使用common join算法,也就是通过一个MapReduce Job完成计算。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。
如果关联字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。由join导致的数据倾斜问题,有如下三种解决方案:
(1)map join——适用于大表 join 小表时存在数据倾斜的场景
使用map join算法,join操作仅在map端就能完成,没有shuffle操作,没有reduce阶段,自然不会产生reduce端的数据倾斜。该方案适用于大表join小表时发生数据倾斜的场景。相关参数如下:参考前文二、(二)
--启动Map Join自动转换
set hive.auto.convert.join=true;
-- 小表阈值
set hive.mapjoin.smalltable.filesize=250000;
--开启无条件转Map Join
set hive.auto.convert.join.noconditionaltask=true;
-- 小表阈值
set hive.auto.convert.join.noconditionaltask.size=10000000;(2)skew join——适用于大表 join 大表时存在数据倾斜的场景
skew join的原理是,为倾斜的大key单独启动一个map join任务进行计算,其余key进行正常的common join。原理图如下:
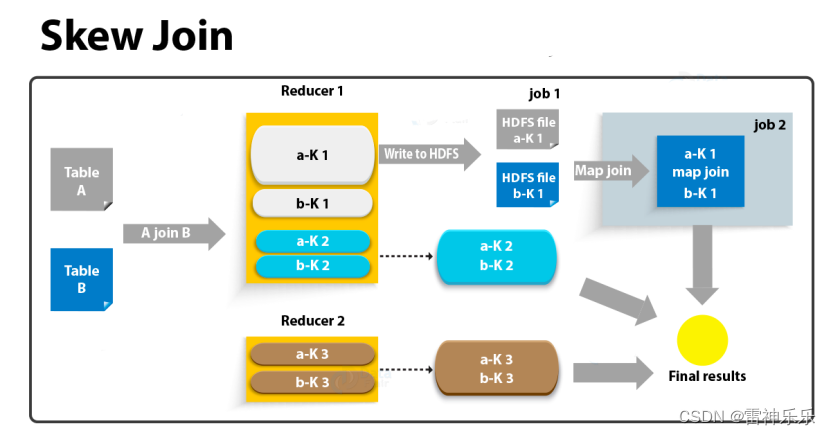
原理解释:
A表joinB表,A表中K1的数据量远大于其他的key,存在数据倾斜,当reduce端检测到数据倾斜的key,就不会完成key的join操作,会将A表中的k1和B表中的k1数据写到HDFS上,此时HDFS中就会产生两个文件:一个是来自A表的k1数据,一个是来自B表的k1数据,两表一大一小,对B表中的k1缓存到每一个map中,A表中的k1均匀地被切片,每一个mapper负责一个切片,就不会有数据倾斜的问题了。
相关参数:
--启用skew join优化
set hive.optimize.skewjoin=true;--触发skew join的阈值,若某个key的行数超过该参数值,则触发
set hive.skewjoin.key=100000;注:这种方案对参与join的源表大小没有要求,但是对两表中倾斜的key的数据量有要求,要求一张表中的倾斜key的数据量比较小(方便走mapjoin)。
(3)调整SQL语句——适用于大表 join 大表时存在数据倾斜的场景
若参与join的两表均为大表,其中一张表的数据是倾斜的,此时也可通过以下方式对SQL语句进行相应的调整。假设原始SQL语句如下:A,B两表均为大表,且其中一张表的数据是倾斜的。
初始化代码:
select
*
from A
join B
on A.id=B.id;优化前:

优化后:
select
*
from(
select --打散操作
concat(id,'_',cast(rand()*2 as int)) id,
-- select cast(rand() * 2 as int);‘
-- 0或1,将倾斜的key分成两部分,一部分id_0,另一部分id_1
value
from A
)ta
join(
select --扩容操作
concat(id,'_',0) id,
value
from B
union all
select
concat(id,'_',1) id,
value
from B
)tb
on ta.id=tb.id;
(4)优化案例
-- 优化前:
set hive.auto.convert.join=false; -- hive中的map join自动转换是默认开启的, -- 若想看到数据倾斜的现象,需要先将hive.auto.convert.join参数设置为false。 set hive.optimize.skewjoin=false; -- skew join也要关闭 select * from order_detail od join province_info pi on od.province_id=pi.id;执行计划:
执行common join,由一个map reduce完成,一个读取order_detail表,一个读取province_info表,在reduce端完成join操作。
这里有一个reduce迟迟未完成,发生了数据倾斜。



-- 优化后:
-- 方案一:map join
set hive.auto.convert.join=true;
只有map,没有reduce,没有发生数据倾斜



-- 方案二:skew join
set hive.auto.convert.join=false;-- 关闭map join set hive.optimize.skewjoin=true;-- 开启skew join执行计划:
该sql在yarn上最终启动了两个mr任务,而且第二个任务只有map没有reduce阶段,说明第二个任务是对倾斜的key进行了map join。



(五)任务并行度
对于一个分布式的计算任务而言,设置一个合适的并行度十分重要。Hive的计算任务由MapReduce完成,故并行度的调整需要分为Map端和Reduce端。
1.Map端并行度——一般不用调
(1)查询的表中存在大量小文件
-- 默认是开启的
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;(2)map端有复杂的查询逻辑
若SQL语句中有正则替换、json解析等复杂耗时的查询逻辑时,map端的计算会相对慢一些。若想加快计算速度,在计算资源充足的情况下,可考虑增大map端的并行度,令map task多一些,每个map task计算的数据少一些。
--一个切片的最大值
set mapreduce.input.fileinputformat.split.maxsize=256000000;2.Reduce端并行度
Reduce端的并行度,也就是Reduce个数。相对来说,更需要关注。Reduce端的并行度,可由用户自己指定,也可由Hive自行根据该MR Job输入的文件大小进行估算。
Reduce端的并行度的相关参数如下:
--指定Reduce端并行度,默认值为-1,表示用户未指定
set mapreduce.job.reduces;--Reduce端并行度最大值
set hive.exec.reducers.max;--单个Reduce Task计算的数据量,用于估算Reduce并行度
set hive.exec.reducers.bytes.per.reducer;
优化案例:
select
province_id,
count(*)
from order_detail
group by province_id;-- 优化前:
刷新所有的参数
开启了5个reduce,5个Reduce端实际一共会接收170(34*5)条记录,理论上Reduce端并行度设置为1就足够了。这种情况下,用户可通过以下参数,自行设置Reduce端并行度为1。


-- 优化后:
--指定Reduce端并行度,默认值为-1,表示用户未指定 set mapreduce.job.reduces=1;
这样,一个reduce就可以接收170条记录,节省资源。


(六)小文件合并
1.Map端输入文件合并
合并Map端输入的小文件,是指将多个小文件划分到一个切片中,进而由一个Map Task去处理。目的是防止为单个小文件启动一个Map Task,浪费计算资源。相关参数为:
--可将多个小文件切片,合并为一个切片,进而由一个map任务处理
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;2.Reduce输出文件合并
合并Reduce端输出的小文件,是指将多个小文件合并成大文件。目的是减少HDFS小文件数量。其原理是根据计算任务输出文件的平均大小进行判断,如果任务输出文件的平均大小<触发小文件合并任务的阈值,就会去进行相应的合并。相关参数为:
--开启合并map,针对只有map的计算输出小文件任务
set hive.merge.mapfiles=true;-- 默认为false--开启合并map reduce任务输出的小文件,如果reduce端输出有小文件就会触发
set hive.merge.mapredfiles=true;-- 默认为false--合并后的文件大小
set hive.merge.size.per.task=256000000;--触发小文件合并任务的阈值,若某计算任务输出的文件平均大小低于该值,则触发合并
set hive.merge.smallfiles.avgsize=16000000;
3.优化案例
-- 优化前:
drop table if exists order_amount_by_province; create table order_amount_by_province ( province_id string comment '省份id', order_amount decimal(16, 2) comment '订单金额' ) location '/order_amount_by_province'; insert overwrite table order_amount_by_province select province_id, sum(total_amount) from order_detail group by province_id;有几个reduce,就会产生几个文件,在并行度设置那一节我们已知select语句会产生5个reduce,因此,会产生5个小文件。

-- 优化后:
-- 方案一:合理设置任务的Reduce端并行度
若将上述计算任务的并行度设置为1,就能保证其输出结果只有一个文件。
set mapreduce.job.reduces=1;-- 方案二:启用Hive合并小文件优化
-- 开启合并map reduce任务输出的小文件 set hive.merge.mapredfiles=true; -- 合并后的文件大小(不进行设置,使用默认值即可) set hive.merge.size.per.task=256000000; -- 触发小文件合并任务的阈值,若某计算任务输出的文件平均大小低于该值,则触发合并 -- (不进行设置,使用默认值即可) set hive.merge.smallfiles.avgsize=16000000;

(七)CBO优化
1.CBO优化说明
CBO是指Cost based Optimizer,即基于计算成本的优化。
在Hive中,计算成本模型考虑到了:数据的行数、CPU、本地IO、HDFS IO、网络IO等方面。Hive会计算同一SQL语句的不同执行计划的计算成本,并选出成本最低的执行计划。目前CBO在hive的MR引擎下主要用于join的优化,例如多表join的join顺序。相关参数为:
--是否启用cbo优化
set hive.cbo.enable=true;
2.优化案例
select
*
from order_detail od
join product_info product on od.product_id=product.id
join province_info province on od.province_id=province.id;-- 优化前:
--关闭cbo优化 set hive.cbo.enable=false; --为了测试效果更加直观,关闭map join自动转换 set hive.auto.convert.join=false;与SQL语句中join的顺序一致
大表(order_info)与大表(product_info)进行join,结果有更大的可能性是一个大表。

-- 优化后:
-- 与SQL语句中join的顺序不一致,先是order_info与province_info进行关联,形成一个新表,然后新表与product_info进行关联。
上面两张图的差异主要体现在middle result的优化。
大表(order_info)与小表(province_info)进行关联,有更大的可能性产生一个小表,从而使整个计算任务的数据量减小,也就是使计算成本变小。
(八)谓词(where过滤)下推
1.谓词下推优化说明
谓词下推(predicate pushdown)是指,尽量将过滤操作前移,以减少后续计算步骤的数据量。相关参数为:
--是否启动谓词下推(predicate pushdown)优化 set hive.optimize.ppd = true;需要注意的是:CBO优化也会完成一部分的谓词下推优化工作,因为在执行计划中,谓词越靠前,整个计划的计算成本就会越低。
2.优化案例
select
*
from order_detail
join province_info
where order_detail.province_id='2';-- 优化前:
--是否启动谓词下推(predicate pushdown)优化
set hive.optimize.ppd = false;
--为了测试效果更加直观,关闭cbo优化
set hive.cbo.enable=false;执行计划:


先对order_info和province_info进行关联,关联后再进行过滤,效率低。
-- 优化后:
-- 方案一:谓词下推
--是否启动谓词下推(predicate pushdown)优化 set hive.optimize.ppd = true; --为了测试效果更加直观,关闭cbo优化 set hive.cbo.enable=false;执行计划:
先将order_detail.province_id='2'的数据过滤出来,形成一个新表,然后再与province_info进行关联。


-- 方案二:修改SQL语句,先过滤,再进行join操作
select * from (select * from order_detail where product_id = '2' ) t1 join province_info;执行计划:与谓词下推差异不大,所以hive中的子查询并不会影响性能。

(九)矢量化(向量化)查询
Hive的矢量化查询优化,依赖于CPU的矢量化计算,可以极大的提高一些典型查询场景(例如scans, filters, aggregates, and joins)下的CPU使用效率。相关参数如下:
-- 只需将其设置为true即可
set hive.vectorized.execution.enabled=true;(十)Fetch抓取
1.Fetch说明
一些简单的查询,例如select * from emp,不需要提交到yarn上进行MapReduce操作,在本地运行即可。在这种情况下,Hive可以简单地读取emp对应的存储目录下的文件,然后输出查询结果到控制台。相关参数如下:
-- 该设置主要是控制哪些查询能够直接转为Fetch抓取任务的,即是否在特定场景转换为fetch 任务
--设置为none表示不转换
--设置为minimal表示支持select *,分区字段过滤,Limit等
--设置为more表示支持select 任意字段,包括函数,过滤,和limit等
set hive.fetch.task.conversion=more;2.优化案例
select * from province_info;
-- 优化前:(51s)
set hive.fetch.task.conversion=none;-- 不转换为Fetch任务
可以看到即使一个很简单的查询也会进行MR计算
-- 优化后:(583ms)
set hive.fetch.task.conversion=minimal;
-- 开启Fetch计算,并且没有提交到yarn
(十一)本地模式
将原来需要提交到yarn上的操作,例如分组聚合、join转为本地任务,在本地的进程当中完成分布式运算。本地模式的前提是数据量不能太大。相关参数如下:
-- framework.name=local这一设置要慎用,它强制将所有的操作都转为本地模式
set mapreduce.framework.name=local;
-- 开启自动转换为本地模式
set hive.exec.mode.local.auto=true;
-- 设置local MapReduce的最大输入数据量,当输入数据量小于这个值时采用local,否则提交到yarn
-- MapReduce的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;-- 尽量<1G
-- 设置local MapReduce的最大输入文件个数,当输入文件个数小于这个值时采用local,否则提交到yarn
-- MapReduce的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=10;(十二)并行执行
set hive.auto.convert.join=false;
select
*
from (
select
user_id,
count(*)
from order_detail
group by user_id
) od
join (
select
user_id,
count(*)
from payment_detail
group by user_id
) pd;-- 优化前:
--关闭并行执行优化 set hive.exec.parallel=false;
yarn端一个mr运行结束之后,才会运行下一个,浪费资源

-- 优化后:
--启用并行执行优化 set hive.exec.parallel=true;
yarn端一同提交两个mr,节省资源

(十三)严格模式——全局配置较多
严格模式主要用来防止一些危险操作:
1.分区表使用分区过滤——防止全表扫描
set hive.strict.checks.no.partition.filter=true;2.使用order by必须有limit过滤——防止全局排序
set hive.strict.checks.orderby.no.limit=true;上面的参数设置好后,使用了order by但是没有使用limit的语句就不会被执行。该参数有时候也会进行全局设置,即配置在hive-site.xml文件中。
案例:
select *
from product_info
order by id
limit 100;order by后面添加limit后,map端输出100行数据:

reduce端也会输入100行数据:

3.限制笛卡尔积查询——防止出现不可控的情况
-- 该参数设置为true,就会限制笛卡尔积的查询。
set hive.strict.checks.cartesian.product=true;















 238
238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









